






银行对中小微企业的信贷决策分析
摘要
本文研究银行如何根据中小微企业的实力、信誉对其信贷风险做出评估,然后依据信贷风险等因素来确定是否放贷及贷款额度、利率和期限等信贷策略。
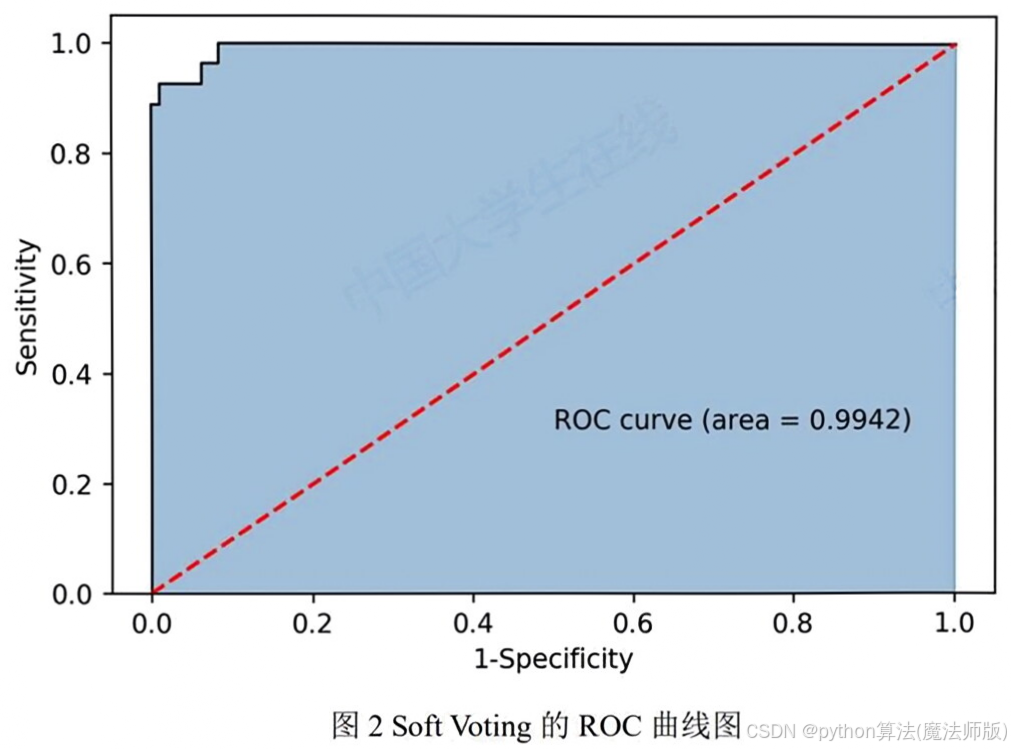
针对问题一,对附件1中的数据进行特征提取,综合考虑了企业实力、发展潜力、上下游供求关系、企业抗风险能力四类指标,共提取出20个特征来衡量企业的信贷风险。本文以 Logistic 回归、Adaboost、GBDT、SVM和随机森林为基分类器, 建立 Soft Voting 集成学习算法,计算企业的违约风险。 Soft Voting在整个数据集上的综合准确率为97.6%, ROC 曲线覆盖面积(AUC值)达到99.42%, 接近完美模型, 计算出的概率可信度高。根据附件1给出的信誉评级和得出的违约风险,根据银行的行为,建立一个利润最高,风险和潜在损失最小的多目标规划模型,求解得出本问的银行信贷策略。
针对问题二,由于本问为无信贷记录企业,银行需要需要根据贷款企业的已知信息和有信贷记录的信息对贷款企业进行信誉评级和违约风险判断。对附件2的数据做与附件1一样的处理,根据提取特征,使用问题一训练的 Soft Voting模型对附件2企业进行违约风险预测。将违约风险加入已有特征,用有信贷记录的企业相关数据训练XGBoost模型,实现对信誉评级的多分类预测。XGBoost在训练集上综合准确率为87.8%。完成信誉评级和违约风险判断后,就可以进行多目标规划模型求解,得出银行的信贷策略。
针对问题三,本文以新冠疫情这个突发事件为例,综合考虑企业的信贷风险和疫情对不同企业的不同影响。从企业在疫情中面临的系统性风险和非系统性风险的角度,本文在附件2中提取行业风险、企业经营状况、利润同比增长率、废票占比变动率和交易企业数量变动率5个特征,反应新冠疫情对企业的综合影响。运用系统聚类将企业聚成3类,不同类别的企业具有不同的风险乘数Q;,风险乘数描述了疫情对不同类别企业的违约风险的放大作用。将信誉评级与聚类结果综合考虑,银行将对企业建立新的评价分级体系,将风险乘数Q₁代入得到调整之后的多目标规划模型,求解可得出银行问题三情景下的信贷策略。
关键词:特征工程; 集成学习算法; 多目标规划; XGBoost; 系统聚类
一、 问题重述
1.1 问题背景
在实践中,由于中小企业规模相对较小,无较多抵押资产,银行通常根据信贷政策、企业交易票据信息以及上下游企业的影响力,向实力雄厚、供需关系稳定的企业提供贷款,对信誉好且信用风险底的企业可以给予优惠利率。银行首先根据中小企业的实力和信誉对其信用风险进行评估,然后根据信用风险等因素确定是否进行放贷和贷款额度、利率、期限等信贷策略。
1.2 问题提出
某银行对确定要放贷企业的贷款额度为10-100万元; 年利率为4%~15%;贷款期限为1年。该银行请你们团队根据2019 年统计的有无信贷记录相关企业数据和贷款利率与客户流失率关系,通过建立数学模型,解决下列问题:
(1) 请对有信贷记录的公司的信贷风险进行量化分析,给出信贷总额固定情况下的信贷策略。
(2) 试对无信贷记录的公司的信贷风险进行量化分析,给出信贷总额为1亿元时的信贷策略。
(3)综合考虑无信贷公司的信贷风险与突发因素对企业的影响,给出信贷总额为1亿元时信贷策略的调整。
二、 问题分析
2.1问题一分析
本问要求对123家企业的信贷风险进行量化分析,并在信贷总额固定时,给出相应信贷策略。由于信贷策略主要包括是否放贷,贷款额度,利率和期限四个方面,且期限为一年已经由题目中给出,因此我们主要是从对不同信誉等级的企业提供相应的贷款额度、利率与是否放贷来制定策略。首先本文就企业实力、对上下游企业的影响能力、发展潜力、抗风险能力等四类指标先对数据进行特征提取,共提取出20个相关的特征。通过运用 Voting集成学习算法,对提取出的特征进行训练,得到每个企业的违约风险值。之后,利用题目给出的信誉评级,算出每个等级的平均违约风险,以此代表该等级企业的违约风险。最后建立以银行利润最高,银行风险最低,潜在流失客户率最小为目标的多目标非线性规划模型。求解得出银行年度信贷总额为固定金额(以5000万为例) 银行对于不同信誉等级的企业发放的相应的贷款额度与利率。
2.2问题二分析
本问要求对附件2的302家企业进行信贷风险分析,并给出信贷策略。本问与问题一的主要差别在于本问的企业无信贷记录,即无信誉评级和是否违约的数据,需要银行通过附件2给出的数据进行自行判断。首先运用第一问训练出的的 Voting集成学习算法,求出302家企业的违约风险,对违约风险大于50%的企业不予放贷。要确定企业的信誉评级是一个多分类问题,将企业的违约概率这一特征与之前提取20个特征组成新的21个特征,运用 Xgboost模型,用附件1所提取的特征训练模型,然后使用
附件2数据对302家企业进行信誉评级,得出分类结果。最后求解多目标非线性规划模型,解出银行信贷总额为1亿元时对不同信誉等级的企业发放的相应贷款额度与利率。
2.3问题三分析
本问考虑的突发事件以新冠疫情为例,不仅要考虑企业本身的信贷风险,还要考虑的疫情对企业的影响所导致企业经营困难,造成的“还贷难”问题。简而言之,新冠疫情扩大了企业的违约风险,具体的扩大倍数本文以风险乘数进行度量。考虑新冠疫情期间企业的所遭受的系统性风险和非系统性风险,在附件2中提取出行业风险、企业状况、利润同比增长率、废票占比变动率、交易企业数量变动率5个特征,反映新冠疫情对企业的影响。本文依据疫情对企业的影响程度对302家企业进行聚类分析,配合问题二所做出的信誉评级,建立一个新的综合分类评级。不同类别的企业具有不同的风险乘数 Qi。在之前的多目标规划模型中,加入风险乘数 Qi,对银行的风险目标进行修改,得到调整后的多目标规划模型,解出模型后得到银行在当期情况下的信贷策略。
三、模型假设
1、同一信誉评级下,本文认为所有企业的信贷风险一致。银行将给予相同信誉评级企业相同的贷款额度与年利率。
2、针对有信贷记录的企业,银行根据以往的信誉评级给贷款。若该企业之前就有违约记录,则今年不予以贷款。
3、针对无信贷记录的企业,银行根据已有信贷记录企业的数据对于无信贷记录企业进行信誉评级之后再考虑是否贷款。
4、银行给予贷款的目标为,所得利息收益最大,承受的风险与客户流失率最小,银行根据此目标对贷款企业发放贷款额度和给予利率优惠。
5、附件1、2所给交易票据数据为企业在所给时间内所有商业交易的总数据,不存在遗漏票据,可以反映企业在所给时间段内的所有可开票的商业交易活动。
6、附件中所给出的企业均为请求银行贷款的企业,并非潜在客户,即不论利率多高附件内企业都不会放弃贷款。
四、符号说明
| 符号 | 含义 |
| π | 企业利润 |
| Mi | 总金额,i=1时代表进项, i=2时代表销项 |
| F₂ | 票据数量,i=1时代表进项, i=2时代表销项 |
| Tali | 税额,i=1时代表进项, i=2时代表销项 |
| Tax | 企业应交增值税 |
| Numij | 与某企业有j(j=1,…,4)年交易关系的企业数 |
| 量。i=1时表示进项交易(上游企业) ,i=2时 | |
| 表示销项交易(下游企业)。 | |
| GUi | 当i=1时, 表示进项发票中作废发票的比例; |
| 当i=2时, 表示销项发票中作废发票的比例。 | |
| An | 企业利润增加的绝对数 (除2020 年数据) |
| Rn | 企业利润增长的相对数(比例) (除2020 年数 |
| 据) | |
| ToPro | 企业是否扭亏为盈, 是为1, 不是则为0 |
| ToLoss | 企业是否变盈为亏, 是为1, 不是则为0 |
| Under | 企业是否为其他企业的下属部门, 是为1, 不是则 |
| 为0 | |
| Controlled | 企业是否为其他企业的分公司或子公司, 是为1, |
| 不是则为0 | |
| Independent | 企业是否为独立公司, 是为1, 不是则为0 |
| Individual | 企业是否为个体经营, 是为1, 不是则为0 |
| Grade | 企业信誉评级, 分A,B,C,D四个等级分别为 |
| 1,2,3,4 四个值 | |
| Break | 企业是否违约, 是为1, 不是则为0 |
| Accuracyi | 第i个基分类器的综合准确率 |
| Wi | 第i个基分类器投票所占权重 |
| -σi | 第i类企业的平均风险 |
| Ii | i类企业的利率, i=1,...,3 |
| Pi | i类企业的贷款额度, i=1,...,3 |
| Ci | i类企业的数量, i=1,...,3 |
| Lost( Ii) | 利率I₁下的i类企业的潜在客户流失率 |
| Coni | 第i个企业在2020年1至2月的盈利状况, 若盈 |
| 利则为1, 无交易为0, 亏损为-1, i=1,...,302 | |
| YGi | 第i个企业的利润在2020年1至2月的同比增长 |
| 率,i=1,...,302 | |
| 第i个企业2020年1至2月较2019年同期进项/销 | |
| Errorij | 项作废和负数票据所占比例的变动率, |
| i=1,...,302, j=1,2 | |
| 第i个企业2020年1至2月较2019年同期进项/销 | |
| Tpij | 项交易对象数量的变动率,i=1,...,302, |
| j=1,2 | |
| Ir; | 第i个企业所在行业的受疫情打击的程度, |
| i=1,...,302 | |
| CCij | 第i个企业进项/销项交易的交易对象数量 |
| Qi | 第i类企业的风险乘数 |
五、问题一建模与求解
5.1数据预处理
我们对于附件1的数据,运用 Python的 pandas库,找出缺失值。若有缺失值,
可删除有缺失值的样本或特征,或对缺失值进行填补。检查数据是否存在缺失值或者NAN 现象,通过简单的查看可知该题数据不存在缺失,无需进行缺失值处理。
5.2数据特征提取
根据附件一所给出的数据,结合相关文献和题目,本文认为银行放贷额度与利润率的选择主要受企业自身实力、发展前景和对上下游企业的影响力这三个方面进行评估。根据附件一所给信息,本文就四个方面总共提取了20个特征,用以衡量银行对企业信誉等级的评判,以此来衡量企业贷款的信贷风险。
5.2.1 企业实力
由前文假设可知,附件所给数据完整,保护所给日期内企业所有的交易事项,故根据进项和销项发票的金额,我们可以得出企业在所给日期之内所得利润总额π。公式如下:
π=M₂-M₁![]()
利润总额越高,企业盈利能力越强,银行可提供贷款额度可相应提升,利率应该相应降低;根据有效进项与销项发票的税额,我们可以得出企业在所给日期之内的增值税 Tax, 公式如下:
Tax=Tal₂-Tal₁![]()
此处我们对增值税为负的情况置零; 根据每个公司与上下游企业的无效票据与有效票据,我们可以得出在所给日期内的作废票据比( GUᵢi=12,![]() 公式如下:
公式如下:
GU1=F1F1+F2![]()
GU2=F2F1+F2![]()
作废票据比越高,即银行信贷风险越高,因此需要适当降低公司信誉等级,减少信贷额度,提高利率。
5.2.2企业对上下游企业的影响力
根据附件1所给的开票日期判断各个企业与其上下游企业合作的时间长度由此来判断供应链的强度。强度与粘性越大,即代表企业对于上下游企业的影响力越大。对于这种企业银行可适当提高贷款额度,降低利率。据此,我们用 Numᵢⱼ![]() 对其进行衡量, 其中i=1,2, j=1,2,3,4。 当i=1时, 表示该企业与上游企业的进项交易,i=2时,表示该企业与下游企业的销项交易,j表示与该企业有j年合作关系的企业数量。
对其进行衡量, 其中i=1,2, j=1,2,3,4。 当i=1时, 表示该企业与上游企业的进项交易,i=2时,表示该企业与下游企业的销项交易,j表示与该企业有j年合作关系的企业数量。
5.2.3 企业的发展潜力
对于企业的未来发展潜力,本文根据题目所提供的数据,分别求出每个企业的利润绝对数的变化 An和相对数的变化 Rn。因为考虑到2020年的数据并不为全年数据,所以在计算这两个指标的时候剔除了2020年的票据数据。
An=π第一年—π最后一年
Rn=π2-4底π棱锥侧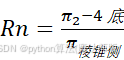
综合 An和Rn两者可得出企业的经营是否发生最大变化,即得出企业是否扭亏为盈或者由盈转亏。当Rn小于0时,则代表企业利润发生了正负转变,这时候需要观察 An。当An大于0时, 说明企业最近年份利润为正而最早年份利润为负, 企业扭亏为盈,即ToPro为1,反之为0; 当An小于0时,说明企业最近年份利润为负而最早年份利润正,企业由盈转亏,即ToLoss为1,反之为0。针对扭亏为盈的企业,银行可适当提高贷款额度与降低利率,针对扭赢为亏的企业,银行可适当降低贷款额度与提高利率。
5.2.4企业的抗风险能力
根据附件1所给数据可以明显看出不同企业可分为本身母公司,公司旗下子公司,下属部门与个体经营。每个不同企业的抗风险能力都不尽相同。因此我们将这四种情况分别作为四种特征值,将所有企业划分为四种情况内。当公司为独立公司时, Independent为1, 当公司为个体经营, Individual为1, 当公司为子公司时, Controlled为1, 当公司为下属部门, Under为1。
5.3信贷风险评分模型
5.3.1 模型选择
信用风险的度量方法主要有传统信用风险度量方法和现代信用度量方法,因为现代信用风险度量方法运用了大量财务数据,受本题条件所限,本文主要参考传统信用评分方法中的多元非线性回归模型。传统的风险测度中,一般使用 Logistics回归或 Probit回归计算企业的违约概率, 以此来度量企业信贷风险[1][2]。经过查询文献,亦有文献使用神经网络和机器学习的其他算法进行风险测量[3],所以本文拟采取集成多个机器学习算法的方式,对附件1中的123家企业进行信贷风险度量。
5.3.2 数据选择与处理
将企业的信誉评级数据进行数据编码,若信誉评级为A,则Grade=1; 若信誉评级为B, 则 Grade=2; 若信誉评级为C, 则 Grade=3;若信誉评级为D, 则 Grade=4。
模型将使用前文从附件一中提取出20个特征,共123个样本进行训练。使用 Python将数据随机切分为训练集和测试集, 并以原数据为标准,对训练集和测试集数据进行标准化,将数据处理至0到1之间。
5.3.3模型建立
投票( voting)是在分类算法中广泛运用的集成学习算法之一。投票主要有硬投票( Hard voting)和软投票( Soft voting)两种。硬投票是一种特殊的软投票, 即各基分类器权重相同的投票,其原理为多数投票原则:如果基分类器的某一分类结果超过半数,则集成算法选择该结果; 若无半数结果则无输出。软投票的原理也为多数投票,但是各基分类器投票所占的权重可自己定义。当各基分类器分类效果差异比较大时,应当选择软投票,给予分类性能更好的基分类器更大的权重,以此优化分类结果。
本文所选择的5个基分类器分别为 Logistic回归, Adaboost, GBDT, SVM 和随机森林。Logistic回归为传统信贷风险评级中常用的模型,该模型的核心为 Logit函数,即: gz=11+e-z,![]() 通过极大似然估计求解对应参数,将分类问题转化为概率问题映射至(0,1)区间。在传统的信用风险评分中, Logistic 回归的准确率能达到54%—92%。
通过极大似然估计求解对应参数,将分类问题转化为概率问题映射至(0,1)区间。在传统的信用风险评分中, Logistic 回归的准确率能达到54%—92%。
Adaboost, GBDT 和随机森林都是基于 boosting算法的分类器, 分类结果较为理想,模型具有较强的泛化能力。Adaboost首先赋予n个训练样本相同的权重,从而训练出一个基分类器,之后进行预先设置的T次迭代,每次迭代将前一次分类器中分错的样本加大权重,使得在下一次迭代中更加关注这些样本,从而调整权重改善分类器,经过T次迭代得到T个基分类器,最终将这些基分类器线性组合得到最终分类器模型。[4]GBDT 分类首先初始化一个弱分类器,计算损失函数的负梯度值值,再利用数据集拟合下一轮模型,重复计算负梯度值和拟合过程,利用m个基础模型,构建梯度提升树。[5]随机森林则选取了大量的决策树模型,各决策树独立的做出学习并进行分类,最后将分类结合为一个最终的结果,其优于单个决策树做出的分类结果。
SVM 是较为强大的传统机器学习算法。它将低维线性不可分的空间转换为高维线性可分的空间。本文主要应用非线性的SVM模型,其目标函数为:
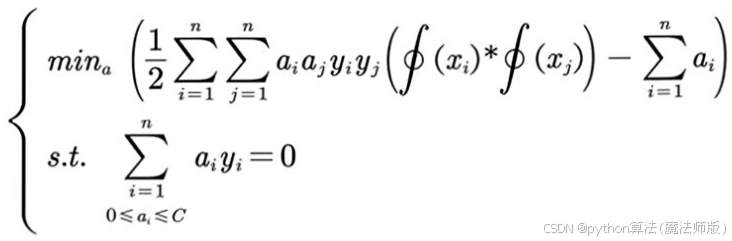
将内积 ∮xi*∮xj![]() 使用核函数替换,计算最优的aᵢ,可以得出超平面的ω和b值。
使用核函数替换,计算最优的aᵢ,可以得出超平面的ω和b值。
5.3.4模型求解
首先对5个基分类进行数据拟合和调参,选取较优参数,得出5个基分类器在改数据集上表现,如下表所示:
表1基分类器分类效果
| 分类器 | 测试集准确率 | 训练集准确率 | 综合准确率 | AUC 值 |
| Logistic回归 | 0.839 | 0.902 | 0.886 | 0.754 |
| Adaboost | 0.903 | 0.913 | 0.911 | 0.822 |
| GBDT | 0.806 | 1 | 0.951 | 0.942 |
| SVM | 0.871 | 0.978 | 0.951 | 0.889 |
| 随机森林 | 0.871 | 1 | 0.967 | 0.953 |
从表1可以看出,训练集和测试集效果最接近的为 Adaboost,其余的分类器有程度不一样的过拟合现象。在整体上,Logistic回归明显略逊一筹,后三个分类器的结果较为接近,主要是三个分类器在训练集上都有良好的表现,而训练集数据占到了整体数据的7成。
然而仅从准确率的角度判断分类模型的结果是有失偏颇的,并且本文的目的是,所以本文加入了AUC 值进行参考。AUC 值为ROC 曲线覆盖的面积,其含义可以综合的考虑召回率( recall), 精确率( precision)和准确率( accuracy)多种指标,一般AUC 值达到0.8以上分类模型可以接受,从这个角度来看,Logistic回归不符合要求。
因为各个基分类器的分类效果不一样,所以本文选择软投票,依据分类器在整体数据上的综合准确率来判断各基分类器的权重,公式为:
(1) Wi=Acuracyi∑i=15Accuracyi![]()
软投票分类结果如下表,
表2 软投票结果
分类器 测试集准确率 训练集准确率 综合准确率 AUC值
Soft Voting 0.903 1 0.976 0.994
可以看出,SoftVoting在分类上的表现十分完美,非常接近完美分类器,说明集成学习算法在此数据集上有着优秀的表现。
Voting模型不仅可以判断出企业是否户违约,并且可以给出企业违约的概率,本文将在后文以此作为对企业的信贷风险的度量。依据信誉评级分类,对不同类别企业的违约风险进行描述性统计分析,表格如下:
表3 不同信誉评级下违约风险的描述性统计分析
| 信誉评级 | Count | Mean | Std | Min | Max |
| A | 27 | 0.145 | 0.068 | 0.079 | 0.435 |
| B | 38 | 0.182 | 0.108 | 0.101 | 0.757 |
| C | 34 | 0.209 | 0.147 | 0.088 | 0.638 |
| D | 24 | 0.710 | 0.170 | 0.237 | 0.882 |
5.4信贷策略多目标规划模型
5.4.1 模型分析
根据假设2,银行将对信誉评级在C及其以上并且之前没有违约记录的的企业发放贷款,即符合条件的企业共有96家,其中A级企业27家,B级企业37家和C级企业32家。银行的放贷决策需要考虑自身利益,即综合的考虑收益和风险,决定对各级企业的放贷额度和利率优惠,这将自然转化为一个多目标规划问题。
首先,由假设1可知银行认为同种信誉评级下的企业的违约风险一直,且在前文
中已经求出了每种类别的平均违约风险 σi,![]() 故由每类企业的 σi
故由每类企业的 σi![]() 代表该类信誉评级下企业的违约风险。
代表该类信誉评级下企业的违约风险。
5.4.2 模型建立与求解
收益目标:银行的目标之一为收益最大化,银行给予企业贷款得到的收益是利息收益,即
max∑i=13Ci*Ii*Pi![]() (2)
(2)
风险目标:银行的目标之一为风险最小,如果企业违约,即银行不仅收不回利息,也收不回本金,所以银行希望最小化损失,即
min∑i=13Ci*σi*Pi*1+Ii![]() (3)
(3)
潜在损失目标:银行会因为调高利率,而流失潜在客户,这些流失的客户也对银行造成了潜在损失,银行也希望吸引更多的企业来贷款,可以获得更多的利息收益。由假设6可知,已知附件来贷款的企业的数量,通过利率可以算出流失的潜在客户数,即 Ci*LostIi1-LostIi。![]() 若流失了一个潜在客户,则银行就失去了贷款从而获得利息的机会,银行希望这笔损失最小,即
若流失了一个潜在客户,则银行就失去了贷款从而获得利息的机会,银行希望这笔损失最小,即
min∑i=13Ci*LostIiLostIi*Ii*Pi![]() (4)
(4)
查阅资料,我们发现银行有对贷款额度进行分级的实践,不同信用等级的企业能贷的最大贷款和最低利率不同,所以银行应该对信用等级高的企业优先给予贷款,且提供数额较大,利率较低的贷款,以满足银行对收益和风险的追求。本文因此对不同信誉评级的企业贷款的额度和利率的上下限做出规定,以此来规范贷款行为,具体规则如下:
表4 不同信誉等级下的贷款限制
| 信誉评级 | 利率下限 | 贷款额度上限 |
| A | 4% | 100 |
| B | 7.5% | 70 |
| C | 11% | 40 |
综上所述,银行在贷款额度为固定数额的约束下(本问定为5000万),要使得满足上述三个目标,将上述三个目标转化为单一目标,列式可得:
min∑i=13Ci*σi*Pi*1+Ii+Ii*Pi*Ci*LostIi1-LostIi-Ci*Ii*Pi![]()
|
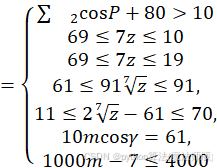
运用 MATLAB 求解可得:
I₁=0.0585,I₂=0.075,I₃=0.11![]()
P₁=999905,P₂=535178,P₃=100030![]()
故对于附件一中队123家企业,银行的信贷策略是,对D级企业和有违约经历的企业拒绝提供贷款; 剩下的企业中,对A级企业提供利率为5.85%,额度为999905元的贷款; 对B级企业提供利率为7.5%,额度为535178元的贷款; 对C级企业提供利率为11%, 额度为100030元的贷款.
六、问题二建模与求解
6.1数据处理与编码
对附件2进行和附件1一样的数据处理方式,提取出问题一所列的20个特征。
将企业的信誉评级数据进行编码,若信誉评级为A,则Grade=1; 若信誉评级为
B, 则 Grade=2; 若信誉评级为C, 则 Grade=3;若信誉评级为D, 则 Grade=4。
6.2 模型建立
6.2.1 违约风险预测
根据问题一所训练的 Voting模型,运用附件2中所提取的20个特征进行预测附件2 中302家企业的违约风险,判断企业是否会违约。
最终得到302个违约风险中,有34家企业的违约风险超过了50%,即认为会违约,银行将不会向他们提供贷款。
6.2.2 信誉评级鉴定
在问题一中,我们已知123家企业的信誉评级并以此来确定贷款的发放,但本问的企业由于没有信贷记录,所以没有信誉评级。依据假设3,银行将通过附件提供数据对企业进行信誉评级,然后据此做出信贷策略。基于XGBoost的在分类问题上的良好
表现,本问将使用XGBoost模型进行对企业进行信誉评级。
XGBoost是一种 Boosting型的树集成模型,在梯度提升决策树GBDT基础上扩展,能够进行多线程并行计算,通过迭代生成新树,即可将多个分类性能较低的弱学习器组合为一个准确率较高的强学习器。XGBoost采用随机森林对字段抽样,将正则项引入损失函数中,从而防止模型过拟合,并降低模型计算量。具体算法步骤如下:
1、优化目标。假设模型具有k个决策树,即:
yi=∑i=1kfkxi,fk∈F![]()
上式中,x₁是第i个输入样本; y₁为经过映射关系fₖ计算出的预测值; F为所有映射关系集合。优化目标以及损失函数为:
Lt=∑i=1nlyiyt-1i+ftxi+Ωft![]()
上式中,L(t)为第t次迭代时目标函数,n为样本数量,I为损失函数,y(t-1);为第t-1次迭代时模型的预测值, fₜ(xᵢ)为新加入的函数, Ω(fᵢ)为正则项。
2、对L(t)进行二阶泰勒展开和移除常数项操作后可得:
Lt≅∑j=1r∑icI,diwj+12∑i∈I,gi+λwj2+γN![]()
上式中, d₁为l对y(t-1);的一阶导数; g₂为对y(t-1);的二阶导数, N为叶子节点个数,Ij为每个叶子结点上样本集合,w²ⱼ为每个叶子结点分数的L₂模的平方,λ和γ则为比重系数,防止产生过拟合[3]。
调用 Python的 xgboost库, 对21个特征(附件2 提取出的20个特征加上是否违约)进行训练。XGBoost在附件1上的综合准确率为0.878,在多分类问题中表现较好。
将信誉评级的分类结果和违约风险的分类结果进行比较验证,发现所有的D级企业均为预测会违约企业,除此之外只有两个C级企业预测会违约。两个不同模型训练的结果较为相近,进一步验证了本问分类的精确性。
详细分类结果见附录。
6.3信贷策略目标规划
根据 Xgboost算法对302家企业进行的信誉分类以及假设2,银行将对符合标准的268家企业进行贷款发放。其中A类企业有63家,B类企业有103家,C 类企业有102家。本问仍然使用问题一中对不同信誉评级的贷款限制,调整后的信贷策略目标规划模型如下:
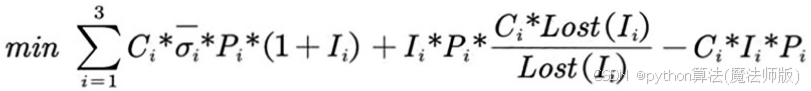
(6)
|
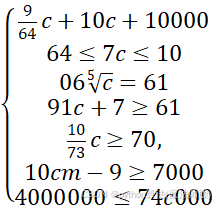
运用 MATLAB 求解可得:
I₁=0.0705,I₂=0.0752,I₃=0.1101![]()
P₁=999717,P₂=260320,P₃=100048![]()
故对于附件二中的302家企业,银行的信贷策略是:对D级企业和有违约经历的企业拒绝提供贷款; 剩下的企业中,对A级企业提供利率为 7.05%,额度为999717元的贷款; 对B级企业提供利率为7.52%,额度为260320元的贷款; 对C级企业提供利率为11.01%, 额度为100048元的贷款.
七、问题三建模与求解
7.1风险及其传导机制
本问加入了突发因素,需要考虑突发因素对企业的影响。根据题目所给数据,本问的突发事件确定为新冠疫情。本问需要综合考虑企业之前的信贷风险和新冠疫情对企业的冲击。
本文认为新冠疫情的爆发会影响企业的违约风险。新冠疫情首先对不同行业的企业有不同程度的影响,这属于系统风险的一种,是企业如果所处其行业必然会受到的影响,即疫情对行业的打击程度。
但是企业自身的特殊性,可能同一行业的不同企业在疫情期间有不同的境遇,这属于非系统性风险,是由企业本身的特殊性所决定的,在数据上可以反映为企业在疫情期间的利润状况、较去年同期的同比增长率、废票所占比增长率和上下游供求企业数量的变化等等。
本文根据企业所受系统性风险(行业风险)和非系统性风险(自身表现)对企业
的进行聚类分析,同一类别的企业拥有相同的风险乘数Q₃,代表该类企业的违约风险较疫情未发生时增大的多少。银行将风险乘数加入信贷策略的目标规划模型,重新制定信贷策略。
7.2数据处理和特征提取
7.2.1 企业状况
由于我们考虑疫情对企业的影响,因此我们主要对企业2020年1、2月份的盈利进行评估。用2020年1、2月份的销项金额减去进项金额即为盈利情况π。
当π>0时, 公司盈利,令 Con,为1; 当π=0时, 则公司没有在2020年进行交易, 令 Coni为0; 当π<0时, 公司亏损, 令 Coni为-1。
7.2.2 利润同比增长率
通过计算2020年1,2月份的企业利润π与2019年1,2月份的企业利润π,可以得出企业2020年1,2月份的利润同比增长率 YGii=1302。![]() 公式如下:
公式如下:
YGi=πi,2020-πi,2019πi,2019![]()
7.2.3 废票占比变动率
废票指的时公司所开的无效票据与负数票据之和。由于负数票据是对冲掉企业之前已经入账的票据,一张负数票据其实代表了至少有两张票据是作废票据。废票占比变动率 Errory(i=1,…,302,j=1,2)即为2020年1, 2月份的企业废票与总票据比例较2019年1,2月份企业废票与总票据比例的变动率,公式如下:
Errorij=GUi,2019-GUi,2019GUi,2019![]()
7.2.4交易企业数量变动率
交易企业数量变动率 Tpij(i=1,...,302,j=1,2)是指的公司在受疫情影响情况下,与公司交易企业数量的变动程度。公式如下:
Tpij=CCij,2020-CCij,2019CCij,2019![]()
7.2.5行业风险
通过国家对于行业的标准化分类方法,本文通过观察企业名称将302家企业一共分为了13个行业。针对其中12个行业,我们通过查询同花顺上的行业股票数据,得到了12个行业股票指数2020年2个月的增长率,用以衡量行业打击程度大小。额外的一个行业中的企业均为为个体经营企业,根据第一财经发布的调研报告[6],个体经营企业预期降幅约为1/3,本文以此数据作为对行业风险的度量。Iri计算公式如下:
Iri= 2020年2月底股票额--2020年1月初股票额
2020年1月初股票额
7.3 聚类模型
本文将上面计算的5种特征,作为系统聚类的依据。系统聚类首先将每一个样本都分为一类,然后不断计算子类与子类之间的距离,逐渐将所有的子类合并为一个大类。系统聚类算法的流程如下图所示。
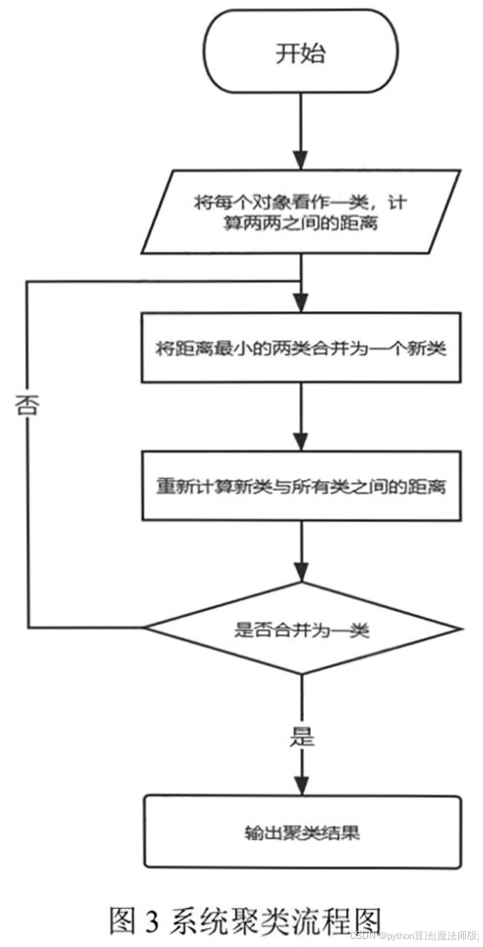
将数据代入SPSS,进行系统聚类,为了确定聚类类别K,画出聚类系数的折线图如下。
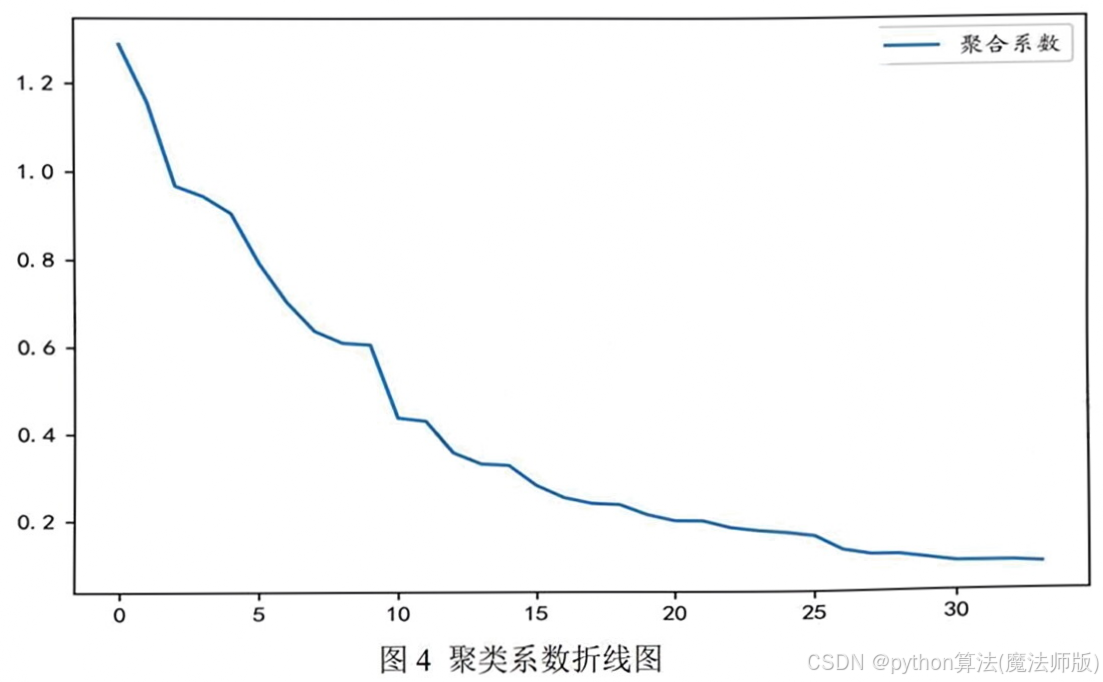
根据聚合系数折线图,可以看出,令K=3,聚类效果最好。得出聚类结果后,对聚类的结果分别进行描述性统计分析,可得下面三表。
表5类别1企业特征描述性统计分析
| 指标 | Coni | YGi | Erroril | Erroril | TPi1 | Tpi2 | Iri |
| count | 239 | 239 | 239 | 239 | 239 | 239 | 239 |
| mean | 0.996 | -1.539 | 0.031 | 0.115 | 3.987 | 7.130 | -0.120 |
| min | 0 | -159.795 | 0 | 0 | -1 | -1 | -0.33 |
| max | 1 | 33.787 | 0.25 | 0.839 | 116 | 101 | 0.126 |
表6类别2 企业特征描述性统计分析
| 指标 | Coni | YGi | Erroril | Erroril | Tpil | TPi2 | Iri |
| count | 59 | 59 | 59 | 59 | 59 | 59 | 59 |
| mean | -0.932 | 0.301 | 0.033 | 0.116 | 1.458 | 6.677 | -0.09 |
| min | -1 | -3.586 | 0 | 0 | -1 | -1 | -0.33 |
| max | 0 | 9.020 | 0.125 | 0.734 | 27 | 93 | 0.126 |
表7类别3 企业特征描述性统计分析
| 指标 | Coni | YGi | Erroril | Erroril | Tpil | Tpi2 | Ir; |
| count | 4 | 4 | 4 | 4 | 4 | 4 | 4 |
| mean | -1 | 1 | 0.047 | 0.934 | -1 | -1 | -0.33 |
| min | -1 | 1 | 0.019 | 0.909 | -1 | -1 | -0.33 |
-1 -0.33
综合上三表数据,类别1的企业大部分为2020年依然盈利或者不盈不亏; 平均Errori₁较小,Tpij大部分为正且数值较大,说明该类企业在疫情期间虽然盈利少于之前,但是供求关系仍然稳定甚至订单数较去年同期更多; 类别2的企业大部分为亏损状态,Errori₁和Tp₃j的表现差于类别1的企业; 类别3的企业只有4个,且全为高风险,差表现的个体经营企业。
根据以上聚类出的三类行业的表现,本文设置其对应的风险乘数为:
Q₁=1.2,Q₂=1.5,Q₃=2![]()
7.4信贷策略
在问题二中本文将企业依据信誉评级分为4类,本问中根据疫情对企业的影响将企业分为3类,理论来说企业被分为了 12类。但在银行的信贷策略中,对认为将违约和D级企业不放贷款且聚类结果的类别3全为D即企业,对数据进行观察可知,数据被分为6类,银行也将根据信誉评级和聚类结果,建立一个新的评价分级体系,记为A₁,A₂,B₁,B₂,C₁,C₂。将风险乘数Q₂加入信贷目标规划模型,调整企业风险,例如对于A₁类企业,其风险为( 1+Q1*σA。![]() 建立调整后的多目标规划模型如下:
建立调整后的多目标规划模型如下:
min∑i=13∑jCi*1+Qjσi*Pi*1+Ii+Ii*Pi*Ci*LostIi1-LcostIi-Ci*Ii*Pi![]()
∑C₁*P₁=10000000
0.04≤I₁≤0.15
0.058≤I₂≤0.15
0.076≤I₃≤0.15
0.094≤I₄≤0.15 (7)
s. t. 0.112≤I₅≤0.15
0.13≤I₆≤0.15
100000≤P₁≤1000000
100000≤P₂≤850000
100000≤P₁≤700000
100000≤P₄≤550000
100000≤P₅≤400000
100000≤P₆≤250000
使用MATLAB 的 fmincon函数解出答案。银行在综合考虑企业信贷风险和疫情对企业影响后的信贷策略如下表:
表8 银行信贷调整策略
| 企业类别 | 企业数量 | 贷款利率 | 贷款金额 |
| A₁ | 54 | 7.60% | 999988 |
| A₂ | 9 | 6.25% | 849863 |
| B₁ | 82 | 11.20% | 317698 |
| B₂ | 21 | 9.40% | 100017 |
| C₁ | 87 | 11.20% | 100002 |
| C₁ | 15 | 13% | 100006 |
八、模型评价
8.1 模型优点
1、数据特征提取时,考虑到企业实力、对上下游企业的影响能力、发展潜力、抗风险能力,较为全面;
2、使用强分类器,构建 Voting集成学习算法,AUC 值接近完美模型,得到的违约风险可信度高;
3、多目标规划不仅考虑了常见的风险和收益,也考虑了潜在客户流失所造成的损失。
4、考虑疫情对企业影响时,综合考虑了系统风险和非系统风险的影响。
8.2 模型缺点
1、对于客户流失率选择的时候,一段区间内的贷款年利率用的是一个客户流失率,没有考虑小范围年利率变化时的客户流失率。
2、特征提取过多,有些变量互相有相关性。
8.3模型改进方向
1、可以使用函数对附件3的数据进行拟合,将离散的客户流失率连续化,多目标规划的结果会更精确。
2、在不对分类效果有较大影响的前提下,可以考虑使用因子分析简化特征数量。
九、参考文献
[1] 王晓燕.上市民营企业信用风险度量方法研究[D].山东大学,2020.
[2] 刘琪.小额贷款公司个人贷款信用风险评估研究[D].扬州大学,2011.
[3] 顾洲一.基于 XGBoost模型的银行信贷高风险客户识别研究——以我国 Y 银行
[4] 孟叶,于忠清,周强.基于集成学习的股票指数预测方法[J].现代电子技术,2019,42(19):115-118. DOI:10.16652/j. issn.1004-373x.2019.19.027.
[5] 王金柱,王翔.从零开始学 Python数据分析与挖掘[M].北京:清华大学出版社,2018.
[6] 祝嫣然,计亚. 疫情影响调研报告:个体户、 民企受影响最为严重.https://m.yicai.com/news/100570014.html.2020.9.13
代码
feixianxing. m
1. %27 37 32
2. %分级之后的规划
3. clc; clear;
4. load data. mat
5.
6. x0=[0.10,0.10,0.10,50,50,50];
7. Aeq=[0,0,0,27,37,32];
8. beq=[5000];
9. lb=[0.04;0.075;0.11;10;10;10];
10. ub=[0.15;0.15;0.15;100;70;40];
11. % ub=[0.075;0.11;0.15;100;70;40];
12. [x, fval, ex]= fmincon(@ fun,x0,[],[], Aeq, beq, lb, ub)
13.
14. 27*x(4)+37*x(5)+32*x(6)
15.
16.
17. 27+37+32
18.
19.
20. %%第二问
21. %总计63 103 104 32
22. clc; clear;
23. load data. mat
24.
25. %63+103+102 %不违约
26.
27.
28. x0=[0.10,0.10,0.10,50,50,50];
29. Aeq=[0,0,0,63,103,102];
30. beq=[10000];
31. lb=[0.04;0.075;0.11;10;10;10];
32. ub=[0.15;0.15;0.15;100;70;40];
33. % ub=[0.075;0.11;0.15;100;70;40];
34. [x, fval, ex]= fmincon(@fun1,x0,[],[], Aeq, beq, lb, ub)
35.
36. %%第三问
37. clc; clear;
38. load data. mat
39. fprintf("不违约的企业数:%d",54+9+82+21+87+15)
40. x0=[0.04,0.04,0.04,0.04,0.04,0.04,10,10,10,10,10,10];
41. Aeq=[0,0,0,0,0,0,54,9,82,21,87,15];
42. beq=[10000];
43. lb=[0.04;0.058;0.076;0.094;0.112;0.13;10;10;10;10;10;10];
44. ub=[0.15;0.15;0.15;0.15;0.15;0.15;100;85;70;55;40;25];
45. [x, fval, exitflag]= fmincon(@ bbb,x0,[],[], Aeq, beq, lb, ub)
bbb. m
1. function f= bbb(x)
2. load data. mat
3. a1=0.14506157936837127;a2=0.1816959402725437;a3=0.2085706859586268;
4. q1=1.2;q2=1.5;
5.t1=54*x(1)*x(7)+9*x(2)*x(8)+82*x(3)*x(9)+21*x(4)*x(10)+87*x(5)*x(11)+15*x(6)*x(12);
6.t2=54*a1*q1*x(7)+9*a1*q2*x(8)+82*a2*q1*x(9)+21*a2*q2*x(10)+87*a3*q1*x(11)+15*a3*q2*x(12);
7.
8. for i=1: length( data)
9. ifx(1)> data(i,1) && x(1)<= data(i+1,1)
10. m1=i;
11. break;
12. end
13. end
14. for j=1: length( data)
15. if x(2)> data(j,1)&& x(2)<= data(j+1,1)
16. m2=j;
17. break;
18. end
19. end
20. for k=1: length( data)
21. ifx(3)> data(k,1) && x(3)<= data(k+1,1)
22. m3=k;
23. break;
24. end
25. end
26. for l=1: length( data)
27. ifx(4)> data(l,1)&& x(4)<= data(l+1,1)
28. m4=l;
29. break;
30. end
31. end
32. for m=1: length( data)
33. ifx(5)> data(m,1) && x(5)<= data(m+1,1)
34. m5=m;
35. break;
36. end
37. end
38. for n=1: length( data)
39. ifx(6)> data(n,1)&& x(6)<= data(n+1,1)
40. m6=n;
41. break;
42. end
43. end
44. t3=( data(m1,2)*54*x(1)*x(7))/(1- data(m1,2))+( data(m2,2)*9*x(2)*x(8))/(1- data(m2,2))+( data(m3,3)*82*x(3)*x(9))/〔1- data(m3,3))+( data(m4,3)*21*x(4)*x(10))/(1- data(m4,3))+( data(m5,4)*87*x(5)*x(11))/(1- data(m5,4))+( data(m6,4)*15*x(6)*x(12))/(1- data(m6,4));
45.
46. f=t2+t3-t1;
47. end
fun. m
1. function f= fun(x)
2. load data. mat
3. a1=0.14506157936837127;a2=0.1816959402725437;a3=0.2085706859586268;
4. t1=27*x(1)*x(4)+37*x(2)*x(5)+32*x(3)*x(6);
5![]()
6.
7. for i=1: length( data)
8. if x(1)> data(i,1) && x(1)<= data(i+1,1)
9. m1=i;
10. break;
11. end
12. end
13. for j=1: length( data)
14. if x(2)> data(j,1)&& x(2)<= data(j+1,1)
15. m2=j;
16. break;
17. end
18. end
19. for k=1: length( data)
20. if x(3)> data(k,1) && x(3)<= data(k+1,1)
21. m3=k;
22. break;
23. end
24. end
25. t3=( data(m1,2)*27*x(1)*x(4))/(1- data(m1,2))+( data(m2,3)*37*x(2)*x(5))/(1- data(m2,3))+( data(m3,4)*32*x(3)*x(6))/(1- data(m3,4));
26.
27. f=t2-t1+t3;
28. end
funl. m
1. function f=fun1(x)
2. %63+103+102
3. load data. mat
4. q1=1.2;q2=1.5;
5. a1=0.14506157936837127;a2=0.1816959402725437;a3=0.2085706859586268;
6.t1=63*x1*x4+103*x2*x5+102*x3*x6;![]()
7 .t2=63*a1*x4*1+x1+103*a2*x5*1+x2+102*a3*x6⋅(1+x3![]() );
);
8.
9. for i=1: length( data)
10. ifx(1)> data(i,1) && x(1)<= data(i+1,1)
11. m1=i;
12. break;
13. end
14. end
15. for j=1: length( data)
16. if x(2)> data(j,1)&& x(2)<= data(j+1,1)
17. m2=j;
18. break;
19. end
20. end
21. for k=1: length( data)
22. ifx(3)> data(k,1) && x(3)<= data(k+1,1)
23. m3=k;
24. break;
25. end
26. end
27. t3=( data(m1,2)*63*x(1)*x(4))/(1- data(m1,2))+( data(m2,3)*103*x(2)*x(5))/(1- data(m2,3))+( data(m3,4)*102*x(3)*x(6))/(1- data(m3,4));
28.
29. f=t2-t1+t3;
30. end
Python代码
第一问
1. # 第一问集成学习
2. data = pd. read csv('第一问所有特征. csv', encoding=' gbk', index col='企业代号')
3. for i in range( len( data)):
4. a='E'+ str(i+1)
5. if data. loc[a,'是否违约']=='否':
6. data. loc[a,'违约']=0
7. else :
8. data. loc[a,'违约']=1
9.
10. x = data. iloc[:,:-3]. values
11. y = data. iloc[:,-1]. values
12.
13. from sklearn. linear model import LogisticRegression
14. from sklearn. model selection import train test split
15. from sklearn. preprocessing import StandardScaler
16. from sklearn. model selection import GridSearchCV
17. from sklearn import metrics
18. from sklearn. ensemble import AdaBoostClassifier as ada
19. from sklearn. ensemble import GradientBoostingClassifier
20. from sklearn. svm import SVC
21. from sklearn. ensemble import RandomForestClassifier as RF
22. from sklearn. model selection import cross val score
23. from sklearn. metrics import roc auc score
24. from sklearn. ensemble import VotingClassifier
25.
26.
27. x train,x test,y train,y test= train test split(x,y, random state=30)
28.
29. tranfer = StandardScaler()
30. x = tranfer. fit transform(x)
31. x train = tranfer. transform(x train)
32. x test = tranfer. transform(x test)
33.
34. LR = LogisticRegression(C=0.1, class weight= None, dual= False, fit intercept= True,
35. intercept scaling=1, 11 ratio= None, max iter=100,
36. multi class=' auto', n jobs= None, penalty='12',
37. random state= None, solver=' newton- cg', tol=0.0001, verbose=0,
38. warm start= False)
39. Ada = ada( algorithm='SAMME', base estimator= None, learning rate=0.1,
40. n estimators=100, random state=30)
41. GBDT = GradientBoostingClassifier( ccp alpha=0.0, criterion=' friedman mse', init= None
42. learning rate=0.7, loss=' exponential', max depth=3,


















 2752
2752

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











