






 本文介绍了倾向性得分在研究中的重要性,包括其定义、影响因素的选择、匹配方法(精确匹配、近邻匹配等),以及在Stata中的具体操作。作者还展示了Probit模型和Logit模型在计算中的应用,以及如何通过PSM进行因果推断。
本文介绍了倾向性得分在研究中的重要性,包括其定义、影响因素的选择、匹配方法(精确匹配、近邻匹配等),以及在Stata中的具体操作。作者还展示了Probit模型和Logit模型在计算中的应用,以及如何通过PSM进行因果推断。
倾向性得分主要操作及分析
- 计算倾向性得分(pscore)
- 根据倾向性得分进行处理组与控制组的匹配
- 实验组与匹配对象进行对比
- 求平均处理效应(ATE)、处理组平均处理效应(ATT)、控制组平均处理效应(ATU)
- PSM匹配数据进行回归
一、倾向性得分定义
在已知协变量后,个体选择接受处理行为的概率
原理:
- 构造假想实验不需要所有维度一一匹配,倾向性得分这一个维度匹配即可
二、 如何选择影响因素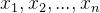 ?
?
- 选择既影响个体选择接受处理行为概率,又影响特征值(
)

在已知协变量后,个体选择接受处理行为的概率
原理:
 1万+
1万+
1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言




 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章























