







UNet作为一种基于卷积神经网络(CNN-based)的模型,面临卷积操作固有局部性,限制了它理解明确的全局和长距离语义信息交互的能力。一些研究尝试通过扩张卷积层,自我注意力机制和图像金字塔来缓解这个问题但在建模长距离依赖方面仍表现出限制。且近期研究探讨了整合Transformer架构,利用自注意力机制将图像视为一系列连续的Patch来捕获全局信息,但由于子注意力机制导致了图像尺寸的二次复杂度,特别对于需要密集预测的任务(如医疗图像分割),带来了相当大计算开销。所以仍然存在一个问题:“如何在不增加额外参数和计算负担的情况下,赋予UNet容纳长距离依赖的能力?”
近期,由于状态空间模型(SSMs)不仅能建立长距离依赖关系,而且还有输入规模的线性复杂性。于是一些尝试如U-Mamba【14】,提出了一个混合的CNN-SSM块,结合了卷积层的局部特征提取能力与SSM在捕捉纵向依赖关系方面的专长但其引入了大量参数和计算负载,带来了相当大计算开销。在这项研究,引入了LightM-UNet,一个基于MAmba的轻量级U形分割模型,显著降低参数和计算成本的同时实现了最先进的性能。(如下图)
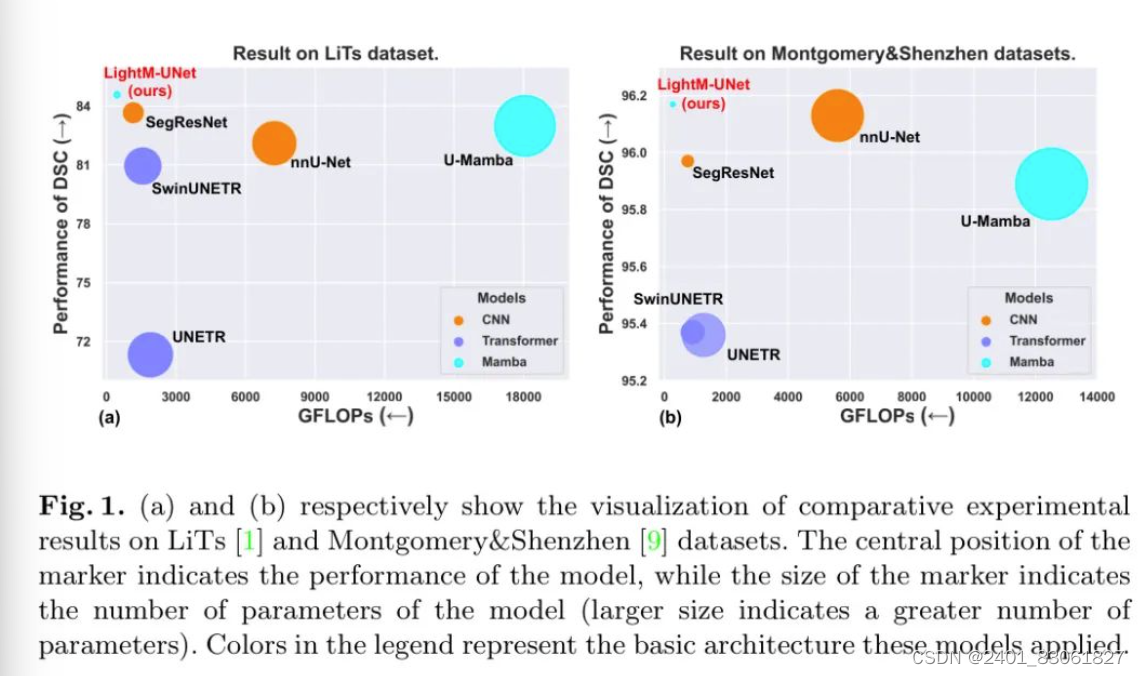
LightM-UNet是UNet与Mamba的轻量级融合,超越了现有的最先进模型。在技术方面,提出了残差视觉曼巴层(RVM层)”以纯曼巴方式从图像中提取深层特征。在引入的新参数和计算开销最小的情况下,作者通过使用“残差连接”和“调整因子”进一步增强了SSM对视觉图像中长距离空间依赖关系建模的能力。
方法论
LightM-UNet的总体架构如图2所示。
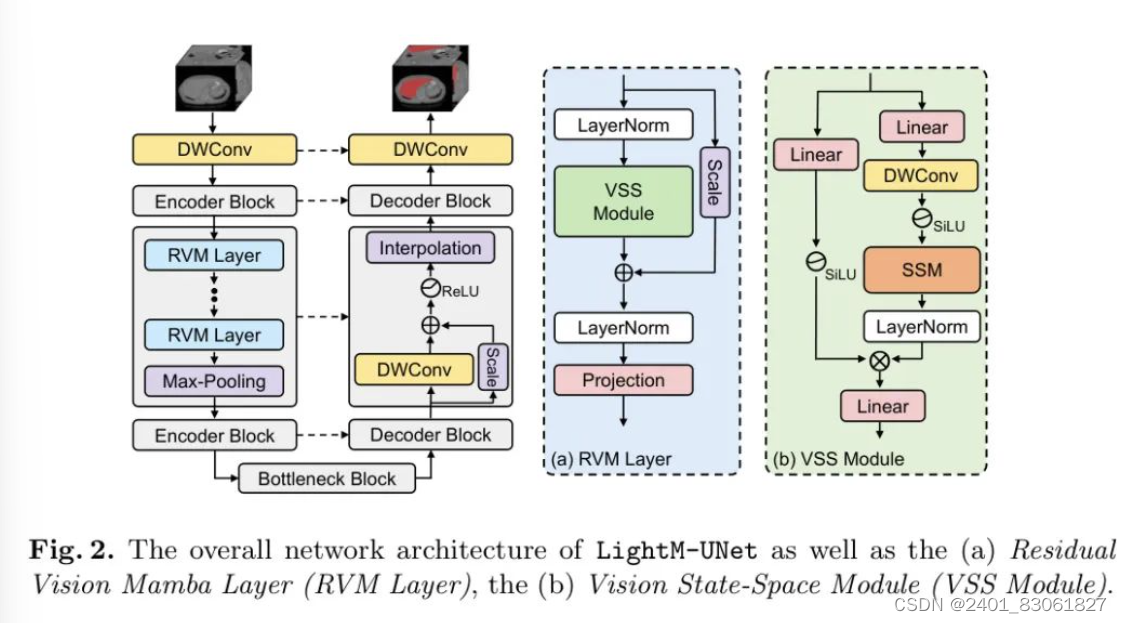
给定一个输入图像 ,其中C 、H、W和D分别表示3D医疗图像的通道数、高度、宽度和切片数。LightM-UNet首先使用深度可分卷积(DWConv)层进行浅层特征提取,生成浅层特征图![]() 其中32表示固定的滤波器数量。随后,LightM-UNet结合三个连续的编码器块(Encoder Blocks)从图像中提取深层特征。在每个编码器块之后,特征图中的通道数翻倍,而分辨率减半。在-th编码器块处,LightM-UNet提取深层特征
其中32表示固定的滤波器数量。随后,LightM-UNet结合三个连续的编码器块(Encoder Blocks)从图像中提取深层特征。在每个编码器块之后,特征图中的通道数翻倍,而分辨率减半。在-th编码器块处,LightM-UNet提取深层特征![]()
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1939
1939

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









