







0. 前言
项目页
论文页
Hi Robot 可以被称为大脑加强版的π0。
以下是来自项目页的引子:
你上一次做一道新菜是什么时候?你看着食谱,摆好食材,开始动手。脑子里会有个小声音说:“哦,我忘了,要加番茄。”你会认真思考每一步,时不时地再检查一下食谱。也许你的朋友还提醒你一句:“小心,别烧糊了。”
心理学家丹尼尔·卡尼曼(Daniel Kahneman)描述了人类解决问题的两种方式,他称之为“系统1”(System 1)和“系统2”(System 2)。系统1是本能的、自动的;而系统2是深思熟虑的、有意识的。做一道新菜时用的是系统2——那正是你脑中那个“小声音”。当你做某件事已经做了一百遍,那就是系统1的工作:它感觉很自动,你几乎不用思考。
那么,我们能不能让机器人也“思考”得像人一样?当它们面对复杂任务时,脑中也有个“小声音”指引它们该做什么?
我们开发了一个叫做层级交互机器人(Hi Robot)的系统,它能够将视觉-语言-动作(VLA)模型(如 π₀)整合进一个两层的推理过程中。π₀ 就像是本能、反应快速的“系统1”,适用于执行那些已经练得非常熟练的任务。而高层的语义视觉-语言模型(VLM)则扮演“系统2”的角色——它会像人一样“自言自语”地思考,通过语言推理和任务分解来完成复杂目标。这个“系统2”的高层策略确实就像你脑中的那个小声音一样,告诉机器人如何把一个复杂任务拆解成多个中间步骤。
之前写过的双系统VLA的博客:
1. Hi Robot 提出背景
1.1 背景与意义
通用机器人(Generalist Robots)在开放世界环境(Open-World Settings)中执行各种任务时,不仅需要能够推理出完成目标所需的各个步骤,还要能处理复杂指令、提示(Prompts),甚至在执行过程中理解并响应反馈。
复杂指令(例如,“你能给我做一个素食三明治吗?”或“我不喜欢那个”)不仅要求机器人具备完成各个动作的物理能力,还要能将这些复杂命令和反馈与现实环境对齐执行。
作者提出了一个层级结构(Hierarchical Structure)系统,结合视觉-语言模型(Vision-Language Models),先在高层对复杂提示和用户反馈进行推理,确定最合适的下一步,然后再以低层动作(Low-Level Actions)执行该步骤。
老朋友双系统,看来π系列也做了相关的研究,Figuer的Helix,Nvidia的Groot N1也都是这种架构,英雄所见略同,双系统并非偶然
不同于只能执行简单指令(例如“拿起杯子”)的直接跟随型方法,他们的系统能够推理复杂提示,并在执行过程中结合情境反馈(例如“那不是垃圾”)。
如Hi Robot原论文所说的:
- 试想一个更真实的提示:“你能给我做个素食三明治吗?不要番茄。另外,如果有火腿或烤牛肉,能给我朋友单独做一个吗?”
这不仅要求机器人理解语言,还要能将命令与当前环境结合,组合已有技能(例如拿取烤牛肉)来完成新任务。
- 如果机器人还收到纠正和反馈(“不是这样的,你得蹲低点,否则一直会打不到”),也必须在执行过程中动态地整合进来。
这一挑战类似于卡尼曼(Kahneman,2011)所描述的“系统1”和“系统2”认知过程的区别。“自动化”的系统1对应能通过调用预先学习的技能来执行简单命令的策略,而更需深思的系统2则负责对复杂的长序列任务进行推理,理解反馈,并决定合适的行动方案。
机器人通过 VLM 整合复杂提示和语言反馈——VLM 解读当前观测到的场景和用户话语,产生合适的语言回复和原子级指令(如“抓取杯子”),并将其传给低层策略执行。这个低层策略本身也是一个微调过的视觉-语言模型,用于生成机器人动作,通常称作VLA。
VLM的高层次推理+ VLA低层次任务执行
作者预计,用标注了原子命令的机器人演示不足以训练高层次模型以遵循复杂、开放式的提示,因此需要复杂提示遵循的代表性示例
- 为获取这些数据,作者提出对包含机器人观察和动作的数据集进行合成标注,使用可能适合该情境的假设提示和人类插话
- 为此,作者基于一个最先进的VLM模型,输入机器人观察和目标原子命令,并要求其生成可能在该观察和命令之前出现的提示或人类交互,即为不同的结果生成高层次策略提示——即通过将这些合成生成但情境相关的示例纳入高层次策略训练
该论文的主要贡献是提出了一个层级交互式机器人学习系统(Hi Robot),该框架在高层推理和低层任务执行中均使用视觉-语言模型。
作者在三种机器人平台上评估了该系统:单臂、双臂以及双臂移动机器人,并展示了它在清理凌乱餐桌、制作三明治和购物等任务中的表现。
该论文旨在推动机器人智能的发展,使其能够理解并执行各种自然语言命令、反馈和纠正——向着让机器人像人一样推理任务、无缝融合人类反馈、具备类人适应能力的方向迈进。
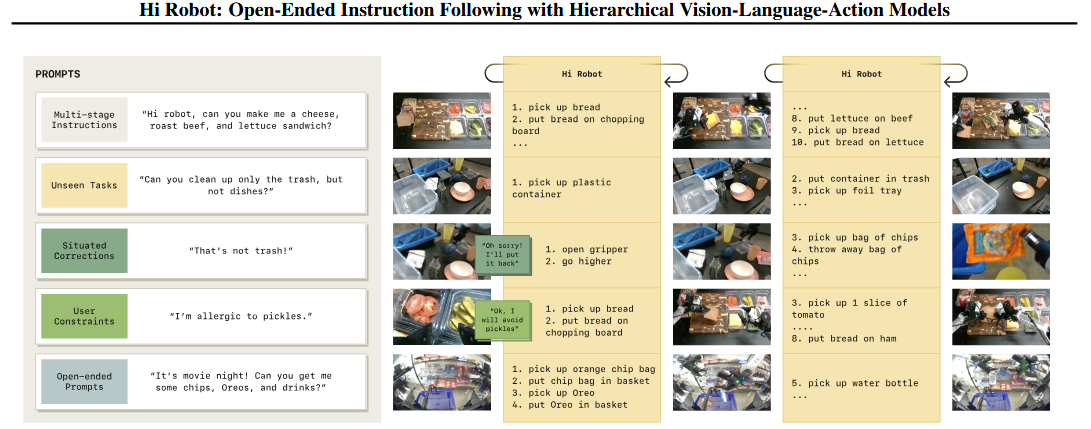
下图展示了该框架让机器人能够处理远比以往端到端指令跟随系统更复杂的提示,并在执行过程中整合反馈(图1)。
1.2 相关工作
用于机器人控制的 VLMs ,可以分为两类:
- 直接微调 VLM 以输出机器人控制指令
在这一类方法中,研究者对 VLM 进行微调,使其能够根据输入的图像和语言指令直接输出机器人控制指令。例如RT-1、TinyVLA、OpenVLA。虽然这些方法在泛化和指令跟随方面表现出色,但它们通常只在相对简单的命令上进行训练(如“把杯子放到盘子上”)。相比之下,作者展示的任务包含复杂提示和人与人的交互,需要情境化推理。
- 将 VLM 直接用于带有预定义技能的机器人系统。
在这一类方法中,许多研究使用大语言模型(LLM)和 VLM 对机器人观测和指令进行推理,并将多阶段任务拆分为低层控制器可执行的简单步骤。较早的此类方法将语言模型与各种学习到的或手工设计的技能相结合,但这些系统在推理过程中很难将复杂的上下文(如图像观测)纳入考虑。
最近,有多项工作使用 VLM 来为预定义的机器人技能输出参数,这些方法可以处理更复杂的指令,并将其置于视觉观察的上下文中,但这些方法表现出有限的物理灵活性以及有限的实时语言交互能力(后文将讨论一些意外)。
相比之下,Hi Robot利用VLMs进行高级推理和低级控制,并在两者之间提供灵活的语言接口。
此外,许多研究致力于实现机器人与用户的语言交互,包括
- 基于模型的方法——解析语言指令和反馈并通过场景的符号表示进行落地
Learning neurosymbolic programs for language guided robot manipulation - 以及更近期的学习型方法——通常采用层级架构直接处理反馈。
Remote multimodal interactions with household robot assistant
Hi Robot基于后一类方法,其中用户反馈通过高层策略进行整合,该策略为低层学习策略提供原子命令。与使用 LLM 修改机器人轨迹的 OLAF 不同,该方法能基于机器人观测整合情境纠正,实时响应这些纠正,并跟随描述精巧操作任务的复杂提示。
虽然 YAY Robot 能处理情境化的实时纠正,但它仅限于单一提示和人工编写数据中的纠正;作者的方案则利用 VLM 和新的数据生成方法,支持多样提示和开放式纠正。
最后,RACER 也能整合情境纠正,但依赖物理模拟器来构建纠正行为;而我们的方法仅使用真实机器人示例(无意扰动或纠正),并适用于开放式提示。
1.3 预备知识和问题陈述
对于学习型策略而言,通过处理观测输入(记为 o t \mathbf{o}_{t} ot)来控制机器人,并输出一个或多个动作 A t = [ a t , a t + 1 , … , a t + H − 1 ] \mathbf{A}_{t}=\left[\mathbf{a}_{t}, \mathbf{a}_{t+1}, \ldots, \mathbf{a}_{t+H-1}\right] At=[at,at+1,…,at+H−1],其中 A t A_t At表示一个动作块,包含接下来要执行的 H H H 步动作,类似ALOHA ACT。
Hi Robot的系统将
- 多台摄像机的图像 I i 1 , … , I i n \mathbf{I}_{i}^{1}, \ldots, \mathbf{I}_{i}^{\mathbf{n}} Ii1,…,Iin
- 机器人的配置(即关节和夹爪位置) q t \mathbf{q}_{t} qt
- 以及语言提示 ℓ t \ell_{t} ℓt作为输入
因此,有给定观测 o t = [ I t 1 , … , I t n , ℓ ℓ , q t ] \mathbf{o}_{t}=\left[\mathbf{I}_{t}^{1}, \ldots, \mathbf{I}_{t}^{\mathbf{n}}, \ell_{\ell}, \mathbf{q}_{t}\right] ot=[It1,…,Itn,ℓℓ,qt],策略表示分布 p ( A t ∣ o t ) p\left(\mathbf{A}_{t} \mid \mathbf{o}_{t}\right) p(At∣ot)
条件分布 p ( A t ∣ o t ) p\left(\mathbf{A}_{t} \mid \mathbf{o}_{t}\right) p(At∣ot):在给定观测 o t \mathbf{o}_{t} ot 下,各个动作块 A t A_t At 出现的概率分布,用于采样或选择最优动作。
先前的研究提出了用于表示和训练此类策略的各种方法,比如ALOHA ACT、Diffusion policy、Octo等等
由于我们致力于解决需要解析复杂提示甚至动态用户反馈的多阶段任务,策略必须能够理解复杂语言,并通过环境观测将其落地。
- 一种处理此类复杂语义的强大方法是使用 VLA 模型,它们利用 VLM 预训练来初始化策略 p ( A t ∣ o t ) p\left(\mathbf{A}_{t} \mid \mathbf{o}_{t}\right) p(At∣ot)。
- VLM 作为一种多模态模型,天然可以处理图像输入,并表示为分布 p ( ℓ ′ ∣ I , ℓ ) p\left(\ell^{\prime} \mid \mathbf{I}, \ell\right) p(ℓ′∣I,ℓ)——即在图像-语言前缀(由图像I 和提示l 组成,例如一个视觉问题)下,语言后缀 ℓ ′ \ell^{\prime} ℓ′(例如一个问题的答案)的概率
最常用的 VLM 通过仅使用自回归解码器的Transformer 模型表示
p
(
ℓ
′
∣
I
,
ℓ
)
p\left(\ell^{\prime} \mid \mathbf{I}, \ell\right)
p(ℓ′∣I,ℓ),将分布分解为自回归token概率的乘积
p
(
x
t
+
1
∣
x
1
,
…
,
x
t
,
I
)
p\left(\mathbf{x}_{t+1} \mid \mathbf{x}_{1}, \ldots, \mathbf{x}_{t}, \mathbf{I}\right)
p(xt+1∣x1,…,xt,I),其中
x
t
\mathbf{x}_{t}
xt表示第t 个token(与物理时间步无关)
并且有
ℓ
=
[
x
1
,
…
,
x
t
p
]
和
ℓ
′
=
[
x
t
p
+
1
,
…
,
x
t
p
+
t
s
]
\ell=\left[\mathbf{x}_{1}, \ldots, \mathbf{x}_{t_{p}}\right]和\ell^{\prime}=\left[\mathbf{x}_{t_{p}+1}, \ldots, \mathbf{x}_{t_{p}+t_{s}}\right]
ℓ=[x1,…,xtp]和ℓ′=[xtp+1,…,xtp+ts],其中
t
p
t_p
tp是前缀的长度,
t
s
t_s
ts是后缀的长度。
类似Paligemma,他们也使用这种基于Transformer 的VLM,且不修改其架构,从而可以使用更简洁的
p
(
ℓ
′
∣
I
,
ℓ
)
p\left(\ell^{\prime} \mid \mathbf{I}, \ell\right)
p(ℓ′∣I,ℓ)符号来表示标准VLM
作者同样采用此类基于 Transformer 的 VLM,但由于我们不修改其架构,自回归细节对本文讨论无关,故统一使用简洁的 p ( ℓ ′ ∣ I , ℓ ) p\left(\ell^{\prime} \mid \mathbf{I}, \ell\right) p(ℓ′∣I,ℓ) 来表示标准 VLM。
一个标准的VLA 是通过微调VLM p ( ℓ ′ ∣ I , ℓ ) p\left(\ell^{\prime} \mid \mathbf{I}, \ell\right) p(ℓ′∣I,ℓ)生成的,使得动作 A t A_t At 由后缀 ℓ ′ \ell^{\prime} ℓ′中的token表示,通常通过离散化对动作进行tokenizing化
以 π0 VLA 为基础,它不仅支持多路图像和连续状态观测 q t q_t qt,还通过流匹配(flow-matching)方法使 VLM 输出连续动作块分布,但其高层原理与标准 VLA 相同。
2. Hi Robot
在图2中给出了方法的总体概览。Hi Robot将策略
p
(
A
t
∣
o
t
)
p\left(\mathbf{A}_{t} \mid \mathbf{o}_{t}\right)
p(At∣ot)分解为低级执行和高级推理过程,其中:

- 低级策略包括一个VLA,它根据更简单的低级语言指令生成动作块 A t \mathbf{A}_{t} At
- 高级策略包括一个VLM,它处理开放式任务提示,并为低级推理过程输出这些低级语言指令
这两个过程以不同的速率运行:低级过程以高频率生成动作块,而高级过程调用频率较低,可能是在设定时间之后或收到新的语言反馈时。因此,高级过程本质上是与低级过程” 对话”,将复杂的提示和交互 分解为可以转换为动作的小型指令。
2.1 高层VLM推理、低层VLA执行
在形式上:
- 高层策略
p
h
i
(
ℓ
^
t
∣
I
t
1
,
…
,
I
t
n
,
ℓ
t
)
p^{\mathrm{hi}}\left(\hat{\ell}_{t} \mid \mathbf{I}_{t}^{1}, \ldots, \mathbf{I}_{t}^{\mathrm{n}}, \ell_{t}\right)
phi(ℓ^t∣It1,…,Itn,ℓt)接收多路图像观测,和一个开放式提示
ℓ
t
\ell_{t}
ℓt,并生成一个「相对更有可执行性」的中间语言指令
ℓ
^
t
\hat{\ell}_{t}
ℓ^t
进一步,高级策略由一个VLM表示,该VLM使用图像和 ℓ t \ell_{t} ℓt作为前缀,并生成 ℓ ^ t \hat{\ell}_{t} ℓ^t作为后缀 - 低层策略 p l o ( A t ∣ I t 1 , … , I t n , ℓ ^ t , q t ) p^{\mathrm{lo}}\left(\mathbf{A}_{t} \mid \mathbf{I}_{t}^{1}, \ldots, \mathbf{I}_{t}^{n}, \hat{\ell}_{t}, \mathbf{q}_{t}\right) plo(At∣It1,…,Itn,ℓ^t,qt)接收与上节中描述的标准VLA 相同类型的观测——即因为有 o t = [ I t 1 , … , I t n , ℓ ℓ , q t ] \mathbf{o}_{t}=\left[\mathbf{I}_{t}^{1}, \ldots, \mathbf{I}_{t}^{\mathbf{n}}, \ell_{\ell}, \mathbf{q}_{t}\right] ot=[It1,…,Itn,ℓℓ,qt],故策略表示分布为 p ( A t ∣ o t ) p\left(\mathbf{A}_{t} \mid \mathbf{o}_{t}\right) p(At∣ot),注意:语言指令 ℓ t \ell_{t} ℓt被高层策略的输出 ℓ ^ t \hat{\ell}_{t} ℓ^t替代
因此,按照 系统1/系统2 的类比,高层策略的任务是接收整体任务提示 ℓ t \ell_{t} ℓt 及相关上下文(以图像和用户交互的形式),并将其转换为一个适合机器人当前执行的任务,由 ℓ ^ t \hat{\ell}_{t} ℓ^t表示,这样的低层策略更容易被理解并让机器人执行。
当然,对于简单且低层策略已直接训练过的任务,这一步并非必需——只需令 ℓ ^ t = ℓ ^ t \hat{\ell}_{t}=\hat{\ell}_{t} ℓ^t=ℓ^t,即可像以往研究中那样直接执行。
层级推理的优势体现在以下场景:提示 ℓ t \ell_{t} ℓt对低层策略而言过于复杂;或在机器人训练数据中不常见;亦或需要与用户进行复杂交互。
由于高层推理较慢但对环境的快速变化不太敏感,因此可在较低频率下运行。可以使用多种策略来实现这一点,包括智能策略,例如系统在推断下一个合适的命令之前检测到命令 ℓ ^ t \hat{\ell}_{t} ℓ^t已完成的情况。
在他们的实现中,他们发现一种非常简单的策略 效果很好:当经过一秒钟或发生新的用户交互时,重新运行高层推理并重新计算 ℓ ^ t \hat{\ell}_{t} ℓ^t。这在用户提供反馈或修正时提供了反应性行为,同时保持了简单性。
2.2 怎样与用户交互
用户可以在策略执行的任何时刻进行干预,提供额外信息和反馈,甚至完全改变任务。在Hi Robot的原型中,这些干预以文本命令或口语(随后被转录为文本)的形式出现。
- 当系统接收到用户干预时,会立即触发高层推理,重新计算中间指令 ℓ ^ t \hat{\ell}_{t} ℓ^t,高层策略可以在生成的中间指令 ℓ ^ t \hat{\ell}_{t} ℓ^t中包含一段口头话语 u t u_{t} ut,用于机器人对用户的确认或澄清。
- 如果包含了 u t u_{t} ut ,再次使用文本转语音系统将该表达播放给用户,并在将 ℓ ^ t \hat{\ell}_{t} ℓ^t传递给低层策略之前,从 ℓ ^ t \hat{\ell}_{t} ℓ^t中移除它。
提升人机对话体验,低层策略仅需纯粹的执行指令,不要带有“确认”成分。
当机器人执行了用户的插话(如“别碰它”)后,用户可以发出信号,让机器人切回先前的指令并继续任务执行。值得注意的是,高级策略的response是具有上下文性的,因为它不仅观察提示 ℓ t \ell_{t} ℓt,还观察当前的图像观测。因此,它可以正确地理解诸如“那不是垃圾”这样的反馈。
2.3 数据集和训练 Hi Robot
为了以可扩展的方式训练 Hi Robot,作者结合人工标注和合成生成的交互数据,如图3所示。

- 首先,通过遥操作收集机器人演示数据 D d e m o D_{demo} Ddemo 。这会生成带有整体目标和粗略的语言注释的轨迹(例如,制作一个三明治)。
- 然后,将这些完整的演示片段分割成短技能
ℓ
^
t
\widehat{\ell}_{t}
ℓ
t,例如拿起一片生菜,这些技能通常持续一到三秒。
且还通过启发式方法从原始机器人动作中提取基本的运动原语(例如,小的校正动作),如将右臂移动到左侧
每一小段都对应机器人正在进行的一个动作或任务。作者会给这些小段加上自然语言的标注,描述“机器人此刻正在做什么” 比如在数据中有一段是“把这块巧克力拿起来”,作者就会给这一段加上相应的标签
由此得到的数据集 D labeled \mathcal{D}_{\text {labeled }} Dlabeled 包含一组 ( ℓ ^ t , I i 1 , … , I t n ) \left(\widehat{\ell}_{t}, \mathbf{I}_{i}^{1}, \ldots, \mathbf{I}_{t}^{n}\right) (ℓ t,Ii1,…,Itn)元组,用于描述机器人的技能。
- 接下来,使用一个大型VLM
p
gen
p^{\text {gen }}
pgen 来生成合成的用户提示和插话
ℓ
t
\ell_{t}
ℓt,以及对应的机器人语句
u
t
u_{t}
ut。具体来说:
1.在已有 D labeled \mathcal{D}_{\text {labeled }} Dlabeled 的基础上,我们将视觉上下文 I i 1 , … , I i n \mathbf{I}_{i}^{1}, \ldots, \mathbf{I}_{i}^{\mathbf{n}} Ii1,…,Iin和技能标签 ℓ ^ t \hat{\ell}_{t} ℓ^t(例如,拿起生菜)一起作为提示输入给 p gen p^{\text {gen }} pgen 。
2. p gen p^{\text {gen }} pgen 会模拟在真实场景中可能出现的互动:生成可能的用户提示 ℓ t \ell_{t} ℓt(如“能给我加点生菜吗?”),以及机器人的口头回复或澄清 u t u_{t} ut。合成数据集 Dsyn 的具体生成方法详见附录A。 - 那怎么检测VLM生成的对不对呢?
他们使用交叉熵损失进行下一个token预测,将高层策略 p h i ( ℓ ^ t ∣ I t 1 , … , I t n , ℓ t ) p^{\mathrm{hi}}\left(\hat{\ell}_{t} \mid \mathbf{I}_{t}^{1}, \ldots, \mathbf{I}_{t}^{n}, \ell_{t}\right) phi(ℓ^t∣It1,…,Itn,ℓt)在 D syn ∪ D labeled \mathcal{D}_{\text {syn }} \cup \mathcal{D}_{\text {labeled }} Dsyn ∪Dlabeled 上进行训练。
相当于将前面采集的数据、标注的数据,以及生成的合成数据(synthetic data)全部汇总,用来训练一个 high-level policy,也就是 Hi Robot 中负责“思考”的部分
训练的输入包括图片和用户可能发出的指令;训练的目标是让模型预测两个输出:机器人该如何回应用户的指令;机器人该实际执行什么动作
为了训练低层策略 p l 0 ( A t ∣ I t 1 , … , I t n , ℓ ^ t , q t ) p^{l_{0}}\left(\mathbf{A}_{t} \mid \mathbf{I}_{t}^{1}, \ldots, \mathbf{I}_{t}^{n}, \hat{\ell}_{t}, \mathbf{q}_{t}\right) pl0(At∣It1,…,Itn,ℓ^t,qt),使用 D labeled ∪ D demo \mathcal{D}_{\text {labeled }} \cup \mathcal{D}_{\text {demo }} Dlabeled ∪Ddemo ,并采用流匹配目标,参考Black 等人。
2.4 模型架构与实现
在他们的实现中,低级策略和高级策略使用相同的基础VLM 作为起点,即PaliGemma-3B VLM。
低层策略是 π0 VLA,在 PaliGemma-3B 基础上增加流匹配“动作专家”微调而得,用于生成连续动作。
而高层策略则在上节所述的图像—语言元组上微调,用于预测中间指令。
这两个VLM 具有几乎相同的架构,唯一的区别是低级策略使用流匹配来输出动作。虽然在实验中使用了 π0,但这个框架本质上是模块化的,可根据需要集成其他基于语言的策略。
3. 实验
他们研究了一系列具有挑战性的物理交互与复杂的人机交互相结合的问题,包括多阶段指令、任务中实时的用户反馈,以及描述新颖任务变化的提示。
将所提的完整方法与之前的相关方法进行对比,并与使用其他高层策略训练方法的替代设计进行比较。
实验的目标是:
- 评估这个方法在跟随各种复杂文本提示(textual prompts)与实时用户反馈(live user feedback)方面的能力。
- 将完整方法与之前那些训练扁平化指令跟随 VLA 策略(flat instruction-following VLA policy)或直接使用基础模型进行高层推理的做法进行比较。
- 评估合成数据(synthetic data)和层级结构(hierarchy)对任务执行效果与语言跟随能力的重要性。
3.1 任务与基准方法
在实验中,作者使用了三个复杂的问题领域,如下各图所示。
3.1.1 餐桌清理

餐桌清理包括清理桌面,将碟子和餐具放入回收箱,将垃圾放入垃圾桶。训练数据由完整的餐桌清理场景(episodes)构成。
这个任务在物理操作上具有挑战性,因为有些物品需要细微的抓取策略(例如:需要从盘子边缘去抓),机器人必须拾取并将不同物品分离(不让它们粘在一起),并且在某些情况下甚至需要用一个物体来操作另一个物体(例如:先把装着垃圾的盘子抓起,然后倾斜盘子把垃圾倒进垃圾桶)。
在他们的评估中,机器人会收到那些实质性改变任务目标的提示,比如“你能只清理垃圾,而不碰餐具吗?”,“你能只收拾餐具,而不管垃圾吗?”,以及“把所有偏黄色的东西都撤到回收箱里”。
这要求高层模型去推理整个任务与每个物体的类别(例如:要知道可重复使用的塑料杯是餐具,而纸杯是垃圾),然后在此基础上调整机器人“默认”的“把所有东西都放好”的行为。这不仅包括要理解该做什么,还要理解该不做什么。
3.1.2 制作三明治

要求机器人制作一个三明治,可以使用多达六种配料,以及面包。
这个任务在物理操作上很困难,因为机器人需要操作可变形且易损的配料,这些配料必须小心地被抓取并精确地放置。数据里包含了不同类型三明治的示例,并附有分段标签(例如,“拿一片面包”)。
使用这个任务来评估复杂提示,比如“你好机器人,你能给我做一个带奶酪、烤牛肉和生菜的三明治吗?”或者“你能给我做一个素食三明治吗?我对泡菜过敏”,以及实时纠正,比如“就这样,不要再加了”。
3.1.3 购物装袋

包括从货架上取下用户指定的一系列商品,将它们放入购物篮,然后把购物篮放到附近的桌子上。
这个任务需要控制双臂移动操作机器人,并理解那些涉及不定数量物体的细微语义。
示例提示包括“嘿机器人,你能帮我拿些薯片吗?我要准备看电影用的”、“你能帮我拿点甜的东西吗?”,“你能帮我拿点饮料吗?”,“嘿机器人,你能帮我拿些 Twix 和 Skittles 吗?”,以及类似“我还想要一些 Kitkat”这样的插话。
3.1.4 对比和消融实验
对比实验评估了我们的完整方法以及若干替代方法,这些替代方法要么采用不同类型的高层策略,要么不使用层级结构。包括:
- 人类专家高级水平:这个基线方法使用了一位人类专家代替高级模型,他们手动输入低级行为的语言指令,这些指令是他们认为最有可能完成任务的。
这让我们了解在高层给出理想指令的情况下,低层策略的表现会受到多大限制。
- GPT-4o 高层模型:该方法与 Hi Robot 一样采用高层/低层分离架构,但在高层部分调用基于 GPT-4o 的 API 模型,而低层策略保持一致。
GPT-4o 是一个比作者使用的 VLM 体量更大的模型,但它并没有使用真实与合成的数据集进行微调。
其实,这个4o类似于π0中所用的SayCan的一个高级版本,后者使用开箱即用的LLM作为高层次策略
为了让 GPT-4o 与机器人的可执行能力(affordances)保持一致,作者精心设计了对应的 prompt,在提示里加入低层策略能够执行的任务相关指令——这些指令是通过对人类标注数据集中最常见的技能标签进行排序得出的——然后让 GPT-4o 从中进行选择。
- Flat VLA:此比较直接使用与Hi Robot中相同的π0低级策略,但没有任何高级或合成数据,代表了一种用于指令跟随的最先进方法。
- 包含合成数据的Flat VLA:此消融实验仅使用π0低级策略本身,没有高级模型,但在低级策略的训练数据中包含了合成数据,以便它仍然可以处理评估中使用的复杂提示。(这里是去掉高层模型,以评估该模块的重要性)
- 没有合成数据的Hi Robot:此消融实验对应于作者的方法且不用合成训练数据,评估在训练中包括多样化的合成生成提示的重要性。此消融实验可以被视为YAY Robot 的高级VLM版本,这是一种先前的系统,使用高级模型为低级模型预测语言指令。
3.2 指标与评估流程
作者报告了两个指标,两个指标关注模型表现的不同方面,互相补充,这些指标由一位对所运行方法一无所知的人工评估者来测量。
每个评估包含每种任务和每种方法各20次试验。
3.2.1 指令准确率
这个分数衡量高层策略所预测的指令与人类意图的契合度,需要多模态地理解当前环境和提示。
如果高层模型的预测既符合用户的指令,又与当前观察到的环境一致,评估者就会标记为“正确”;否则就标为“错误”。一次试验的指令准确率就等于“正确预测次数”除以“预测总次数”。
对于没有可解释语言预测的扁平化基准模型(flat baselines),评分则基于评估者对该模型行为意图的理解来判断是否符合人类意图。
3.2.2 任务进度
因为作者评估的所有任务都很复杂且具有长远规划,所以需要记录任务进度,以提供对任务完成情况的细致观察。任务进度量化了机器人与预期目标的匹配程度,其计算方式是“成功放到正确位置或正确状态的物品数量”除以“总物品数”。
3.3 核心结果
展示了他们的系统与两个关键基准方法的结果:一个是 GPT-4o 策略,另一个是Flat VLA 方法。定量和定性结果见图5和图6:

- Hi Robot 在开放式指令执行方面表现出色。在所有任务中,与 GPT-4o 和 Flat 基线相比,HiRobot 显示出显著更高的指令准确性和任务进展性。它能够正确识别、拾取并放置正确的物品——即使在提示仅处理某些对象或省略某些成分时(例如,“我对泡菜过敏”)
相比之下,一旦开始物理交互,GPT-4o 往往会丢失上下文,发出无意义的指令(例如“拿起百慕大三角形”),或者有时把所有东西都标记为“盘子”或“勺子”,从而打乱长远规划。
- Hi Robot 展现了强大的情境推理能力和对反馈的适应能力。当用户在任务中途修改请求(例如,“留着剩下的”,“我还想要一个KitKat”)时,Hi Robot 会相应地更新低级命令
然而,GPT-4o 经常无法保持连贯的内部状态,导致发出类似“当机械爪还在拿着东西时,再去拿新物品”或者“过早切换任务”的指令。另一方面,扁平基准不会对实时反馈做出反应。
- Hi Robot 在多样化任务、不同类型机器人和用户约束条件下都表现出色。在单臂、双臂和可移动双臂平台上,Hi Robot 能够处理各种不同物体(从易碎的奶酪片到高高的瓶子),同时遵守动态约束(例如“只撤黄色物品”、“别加番茄”)。
相比之下,当任务中途提示发生变化时,扁平化基准和 GPT-4o 往往会回到默认行为(例如看到什么物品就全拿,或者三明治里几乎把所有配料都放进去)。

从上图可以看出 GPT-4o 经常 错误识别对象, 跳过子任务,或 忽略用户意图。Hi Robot 始终生成与机器人当前操作和用户请求一致的指令;在没有合成数据的情况下,高级策略与图像观察很好地对齐,但忽略了用户约束。
- 专家人类指导展示了低层策略的优点,但也凸显了高层推理的必要性。在有人类提供高层指令的情况下,低层策略几乎可以完美执行,这表明失败更多是因为推理问题,而非执行问题。然而,仅仅依赖人类输入并不可扩展应用。
Hi Robot 通过一个高层视觉语言模型(VLM)来弥补这一鸿沟,让它既能对齐用户提示,也能结合实时观察;而 GPT-4o 缺乏对物理环境的理解,扁平基准又缺少高层推理,都会阻碍它们的表现
3.4 消融研究
作者行了两个关键的消融实验,以分别分析:1) 合成数据对高层次推理的贡献,2) 分层分解与单一“平面”策略的对比
3.4.1 合成数据对开放式指令跟随至关重要
将 Hi Robot(在人工标注 + 合成数据上训练)与仅在人工标注数据上训练的版本进行对比,结果表明合成交互显著提升了语言的灵活性(见下图7)。

没有这些合成数据时,被消融的模型会忽略澄清信息(例如“这不是垃圾”),或仍然把被禁用的物品(例如泡菜)纳入处理;而 Hi Robot 因为合成数据覆盖了更多“组合式”语言表达,能够平稳地对这类反馈作出适应。
3.4.2 分层结构优于Flat策略
接下来将 Hi Robot 与一个在相同合成数据上训练但没有单独推理步骤的扁平化策略进行对比(见图8)。
扁平化模型在接到“要做什么”这个文本提示后,直接算出下一个动作,不经过“先输出一句语言指令再让低层去执行”的流程

扁平模型常常回到“把所有物品都清理掉”的默认行为,或无法处理“只撤黄色物品”这类部分指令;而 Hi Robot 会在每个高层步骤重新检查提示,并能连贯地对任务中途的更新做出响应。
这表明将高层推理和低层控制分开,有利于多步任务的连贯性,以及对动态用户输入的快速适应。
4. 讨论与未来工作
作者提出了 Hi Robot,这个系统在一个层级结构中使用 VLM ,首先对复杂提示、用户反馈和语言交互进行推理,从而推断出最合适的下一步来完成任务,然后通过直接输出低层动作指令来执行该步骤。这个系统可以被视为基于VLM的双系统架构。
“系统2”层表现为高层视觉-语言模型策略,这个策略利用来自大规模网络预训练的语义和视觉知识,对复杂提示和用户交互进行推理。
物理的、反应式的“系统1”层同样也是一个视觉-语言模型,它经过训练,能够对描述原子行为的简单命令直接输出机器人动作。
这两个视觉-语言模型的架构几乎相同,唯一的区别是低层策略使用流匹配(flow matching)来输出具体动作。
实际上,在模型层面将高层与低层分开并不是这个设计的根本要求:未来工作的一个自然方向是把这两个系统合并成一个模型,并在推理阶段再去区分“系统1”和“系统2”。
指合并后可以在同一个网络内部,根据输入类型和上下文动态决定使用快速模式(System 1)还是慢速、深度推理模式(System
2),而不是训练时就强制把两个模块拆开。
尽管我们展示了高层策略能够经常将复杂指令拆解为机器人可以物理执行的低层步骤,但该高层模型的训练过程在一定程度上依赖于提示词工程,以生成能促发这种行为的合成训练示例。
现在高层模型只知道“我需要输出一个能被低层理解的文字指令”,低层只知道“收到这个文字指令后怎么去执行”,彼此并未在训练时共享内部状态或相互检验。更直接地将这两层耦合,例如让高层策略能够更清楚地了解低层策略每次命令完成的成功度,将会是未来研究的一个令人兴奋的方向。

















 875
875

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









