







节前,我们星球组织了一场算法岗技术&面试讨论会,邀请了一些互联网大厂朋友、参加社招和校招面试的同学。
针对算法岗技术趋势、大模型落地项目经验分享、新手如何入门算法岗、该如何准备、面试常考点分享等热门话题进行了深入的讨论。
合集:
从零开始构建 Stable Diffusion,这对于面试或者理解模型的原理,特别有用。
在本文中,我将尝试从零开始创建一个小规模的稳定扩散模型。
我们将使用小数据集 MNIST,你可能听说过这个数据集。选择这个数据集的原因是训练过程不应该花费太多时间。
前提条件
为了实现快速训练,使用 GPU 是必不可少的。
请确保你对面向对象编程 (OOP) 和神经网络 (NN) 有基本的理解。熟悉 PyTorch 也将有助于编码。如果没有 GPU,可以在代码中出现的地方将设备值修改为 ‘cpu’。
Stable Diffusion 是如何工作的?
作为一种扩散模型,Stable Diffusion 的运作方式与许多其他图像生成模型不同。简而言之,扩散模型使用模糊噪声对图像进行编码。然后,它们使用噪声预测器和反向扩散过程将图像重新组装。
除了扩散模型的技术差异,Stable Diffusion 的独特之处在于它不使用图像的像素空间,而是使用简化的潜在空间。
这一选择是基于以下事实:分辨率为 512x512 的彩色图像具有巨大的潜在值数量。
相比之下,Stable Diffusion 使用的是压缩图像,其大小减少了 48 倍,包含的值也更少。这种处理需求的显著减少使得在具有 8 GB RAM 的 NVIDIA GPU 的台式计算机上使用 Stable Diffusion 成为可能。
较小的潜在空间的有效性基于自然图像遵循模式而非随机性的理念。Stable Diffusion 使用变分自编码器 (VAE) 文件在解码器中捕捉复杂细节,例如眼睛。
Stable Diffusion V1 使用了由 LAION 从 Common Crawl 编译的三个数据集进行训练。这包括 LAION-Aesthetics v2.6 数据集,该数据集包含美学评分为 6 或更高的图像。

Stable Diffusion 的架构
Stable Diffusion 使用几个主要的架构组件,在本文中,我们将构建这些组件:
-
变分自编码器:
- 包含编码器和解码器。
- 编码器将 512x512 像素的图像压缩到潜在空间中的 64x64 模型。
- 解码器将模型从潜在空间恢复到全尺寸的 512x512 像素图像。
-
正向扩散:
- 逐步向图像添加高斯噪声,直到只剩下随机噪声。
- 在训练期间使用,除了图像到图像转换外,不用于其他任务。
-
反向扩散:
- 逐步撤销正向扩散。
- 使用提示在数十亿张图像上进行训练,以创建独特的图像。
-
噪声预测器 (U-Net):
- 使用 U-Net 模型对图像进行去噪。
- U-Net 模型是卷积神经网络,Stable Diffusion 使用残差神经网络 (ResNet) 模型。
-
文本条件:
- 文本提示是常见的条件形式。
- CLIP tokenizer 分析文本提示中的每个词,并将数据嵌入到一个 768 值的向量中。
- 提示中最多可使用 75 个令牌。
- 文本提示从文本编码器传递到 U-Net 噪声预测器,使用文本转换器。
- 将种子设置为随机数生成器,可以在潜在空间中生成不同的图像。
这些组件协同工作,使 Stable Diffusion 能够以独特且受控的方式创建和操作图像。
理解我们的数据集
我们将使用 torchvision 模块中的 MNIST 数据集,该数据集包含手写数字 0-9 的小型 28x28 图像。如前所述,我们希望使用一个小数据集,这样训练不会花费太长时间。让我们来看看我们的数据集是什么样的。
# 导入所需的库
import torch
import torchvision
from torchvision import transforms
import matplotlib.pyplot as plt
# 定义一个变换来标准化数据
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.5,), (0.5,))])
# 下载并加载训练数据集
train_dataset = torchvision.datasets.MNIST(root='./data', train=True, transform=transform, download=True)
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=64, shuffle=True)
# 提取一批独特的图像
unique_images, unique_labels = next(iter(train_loader))
unique_images = unique_images.numpy()
# 显示独特图像的网格
fig, axes = plt.subplots(4, 16, figsize=(16, 4), sharex=True, sharey=True) # 创建一个 4x16 的子图网格,设置较宽的图形
for i in range(4): # 循环行
for j in range(16): # 循环列
index = i * 16 + j # 计算批次中的索引
axes[i, j].imshow(unique_images[index].squeeze(), cmap='gray') # 使用灰度颜色图显示图像
axes[i, j].axis('off') # 关闭坐标轴标签和刻度
plt.show() # 显示图形

我们的数据集包含60,000张正方形图像,展示了手绘的数字,范围从0到9。我们将构建稳定扩散(Stable Diffusion)架构并使用这些图像训练我们的模型。在训练过程中,我们会尝试各种参数值。一旦模型训练完成,我们将给它一个数字,比如5,它会为我们生成一个手绘数字5的图像。
设置环境
在整个项目中,我们将使用一系列的Python库,因此让我们先导入它们:
# 导入用于张量操作的PyTorch库。
import torch
# 从PyTorch导入神经网络模块。
import torch.nn as nn
# 从PyTorch导入功能操作。
import torch.nn.functional as F
# 导入用于数值运算的'numpy'库。
import numpy as np
# 导入用于高阶函数的'functools'模块。
import functools
# 从PyTorch导入Adam优化器。
from torch.optim import Adam
# 从PyTorch导入DataLoader类以处理数据集。
from torch.utils.data import DataLoader
# 从torchvision导入数据变换函数。
import torchvision.transforms as transforms
# 从torchvision导入MNIST数据集。
from torchvision.datasets import MNIST
# 导入用于在训练过程中创建进度条的'tqdm'库。
import tqdm
# 特别为笔记本兼容性导入'trange'和'tqdm'。
from tqdm.notebook import trange, tqdm
# 从PyTorch导入学习率调度器。
from torch.optim.lr_scheduler import MultiplicativeLR, LambdaLR
# 导入用于绘制图形的'matplotlib.pyplot'库。
import matplotlib.pyplot as plt
# 从torchvision.utils导入'make_grid'函数以可视化图像网格。
from torchvision.utils import make_grid
# 从'einops'库导入'rearrange'函数。
from einops import rearrange
# 导入'math'模块以进行数学运算。
import math
确保安装这些库以避免任何错误:
# 安装'einops'库以便轻松操作张量
pip install einops
# 安装'lpips'库以计算图像之间的感知相似性
pip install lpips
导入必要的库后,让我们继续创建稳定扩散架构的第一个组件。
创建基本的前向扩散
让我们从前向扩散开始。简单来说,扩散方程是:

这里,σ(t)>0是噪声强度,Δt是步长,r∼N(0,1)是标准正态随机变量。简单来说,我们不断向样本添加服从正态分布的噪声。通常,噪声强度σ(t)随着时间增加而增大(随着t变大)。
# 一维情况下进行N步前向扩散
def forward_diffusion_1D(x0, noise_strength_fn, t0, nsteps, dt):
"""
参数:
- x0: 初始样本值(标量)
- noise_strength_fn: 噪声强度函数,随时间变化,输出标量噪声强度
- t0: 初始时间
- nsteps: 扩散步数
- dt: 时间步长
返回:
- x: 样本值随时间的轨迹
- t: 轨迹对应的时间点
"""
# 初始化轨迹数组
x = np.zeros(nsteps + 1)
# 设置初始样本值
x[0] = x0
# 生成轨迹的时间点
t = t0 + np.arange(nsteps + 1) * dt
# 执行Euler-Maruyama时间步进行扩散模拟
for i in range(nsteps):
# 获取当前时间的噪声强度
noise_strength = noise_strength_fn(t[i])
# 生成一个随机正态变量
random_normal = np.random.randn()
# 使用Euler-Maruyama方法更新轨迹
x[i + 1] = x[i] + random_normal * noise_strength
# 返回轨迹和对应的时间点
return x, t
# 噪声强度函数始终等于1的示例
def noise_strength_constant(t):
"""
示例噪声强度函数,返回一个常数值(1)。
参数:
- t: 时间参数(在此示例中未使用)
返回:
- 常数噪声强度(1)
"""
return 1
# 我们已经定义了前向扩散组件,现在让我们检查它在不同试验中的工作情况。
# 扩散步数
nsteps = 100
# 初始时间
t0 = 0
# 时间步长
dt = 0.1
# 噪声强度函数
noise_strength_fn = noise_strength_constant
# 初始样本值
x0 = 0
# 可视化的试验次数
num_tries = 5
# 设置图的宽度较大,高度较小
plt.figure(figsize=(15, 5))
# 多次试验循环
for i in range(num_tries):
# 模拟前向扩散
x, t = forward_diffusion_1D(x0, noise_strength_fn, t0, nsteps, dt)
# 绘制轨迹
plt.plot(t, x, label=f'试验 {i+1}') # 为每次试验添加标签
# 给图形添加标签
plt.xlabel('时间', fontsize=20)
plt.ylabel('样本值 ($x$)', fontsize=20)
# 图的标题
plt.title('前向扩散可视化', fontsize=20)
# 添加图例以区分每次试验
plt.legend()
# 显示图形
plt.show()
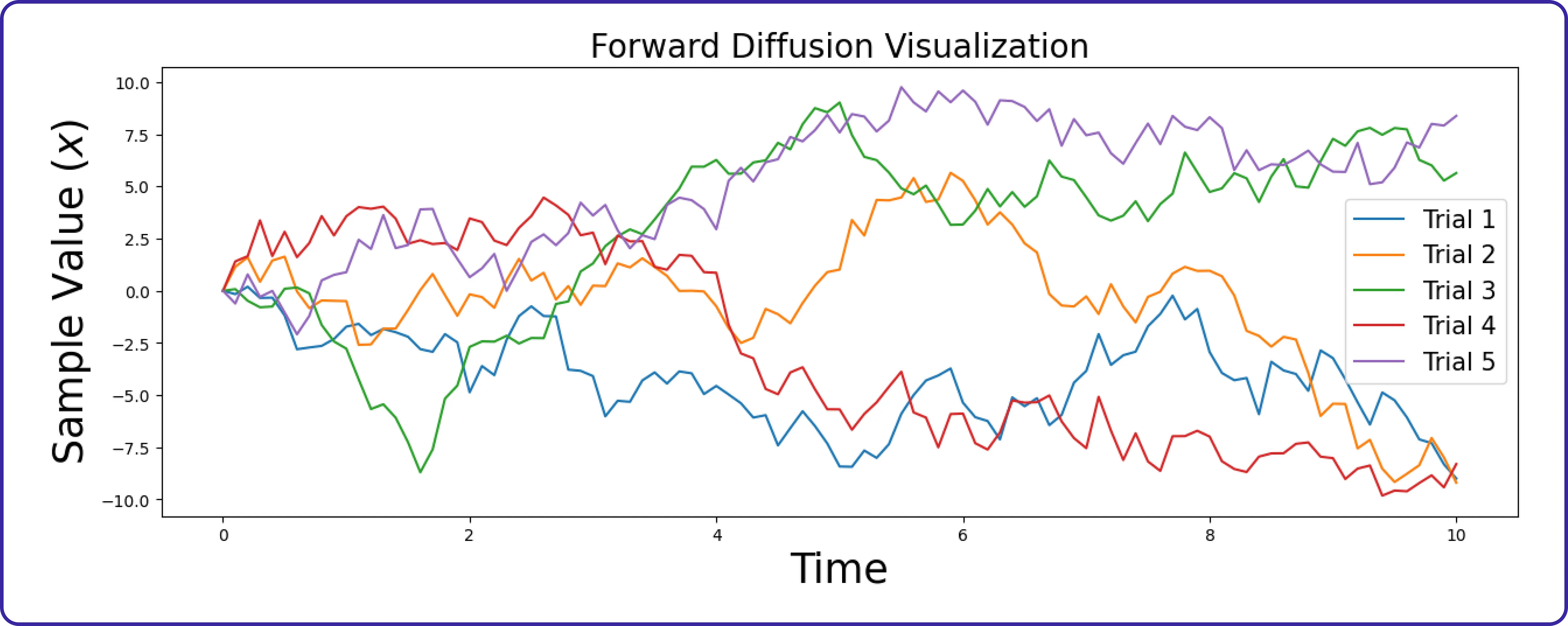
此图展示了前向扩散过程,可以理解为逐渐向起始样本引入噪声。随着扩散过程的进行,这会产生各种样本,如图所示。
创建基本的反向扩散
要逆转这一扩散过程,我们使用类似的更新规则:
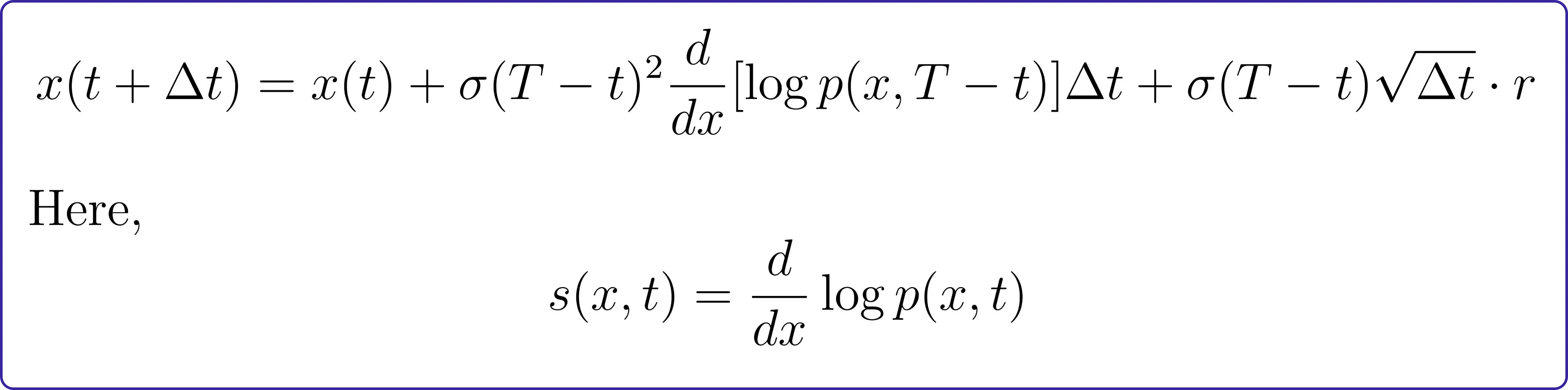
( s(x,t) ) 被称为评分函数。知道该函数可以让我们逆转前向扩散,将噪声转换回初始状态。
如果我们的起点总是位于 ( x_0 = 0 ) 处,并且噪声强度是恒定的,那么评分函数正好等于

既然我们已经知道了数学方程式,首先编写一维反扩散函数的代码。
# 一维反扩散N步。
def reverse_diffusion_1D(x0, noise_strength_fn, score_fn, T, nsteps, dt):
"""
参数:
- x0: 初始样本值(标量)
- noise_strength_fn: 时间的函数,输出标量噪声强度
- score_fn: 分数函数
- T: 最终时间
- nsteps: 扩散步数
- dt: 时间步长
返回值:
- x: 样本值随时间变化的轨迹
- t: 轨迹对应的时间点
"""
# 初始化轨迹数组
x = np.zeros(nsteps + 1)
# 设置初始样本值
x[0] = x0
# 生成轨迹的时间点
t = np.arange(nsteps + 1) * dt
# 进行反扩散模拟的Euler-Maruyama时间步长
for i in range(nsteps):
# 计算当前时间的噪声强度
noise_strength = noise_strength_fn(T - t[i])
# 使用分数函数计算分数
score = score_fn(x[i], 0, noise_strength, T - t[i])
# 生成一个随机正态变量
random_normal = np.random.randn()
# 使用反向Euler-Maruyama方法更新轨迹
x[i + 1] = x[i] + score * noise_strength**2 * dt + noise_strength * random_normal * np.sqrt(dt)
# 返回轨迹和对应的时间点
return x, t
现在,我们将编写一个非常简单的分数函数,总是等于1。
# 示例分数函数: 总是等于1
def score_simple(x, x0, noise_strength, t):
"""
参数:
- x: 当前样本值(标量)
- x0: 初始样本值(标量)
- noise_strength: 当前时间的标量噪声强度
- t: 当前时间
返回值:
- score: 根据提供的公式计算的分数
"""
# 使用提供的公式计算分数
score = - (x - x0) / ((noise_strength**2) * t)
# 返回计算的分数
return score
如同我们绘制正向扩散函数以检查其是否正常工作一样,我们也将绘制反扩散函数的图表。
# 反扩散步数
nsteps = 100
# 反扩散的初始时间
t0 = 0
# 反扩散的时间步长
dt = 0.1
# 定义常数噪声强度的函数用于反扩散
noise_strength_fn = noise_strength_constant
# 反扩散的示例分数函数
score_fn = score_simple
# 反扩散的初始样本值
x0 = 0
# 反扩散的最终时间
T = 11
# 可视化的尝试次数
num_tries = 5
# 设置较宽的图形宽度和较小的高度
plt.figure(figsize=(15, 5))
# 多次尝试的循环
for i in range(num_tries):
# 从噪声分布中抽取,该分布是噪声强度为1时扩散时间为T的分布
x0 = np.random.normal(loc=0, scale=T)
# 模拟反扩散
x, t = reverse_diffusion_1D(x0, noise_strength_fn, score_fn, T, nsteps, dt)
# 绘制轨迹
plt.plot(t, x, label=f'Trial {i+1}') # 为每次尝试添加标签
# 图表标签
plt.xlabel('时间', fontsize=20)
plt.ylabel('样本值 ($x$)', fontsize=20)
# 图表标题
plt.title('反扩散可视化', fontsize=20)
# 添加图例以标识每次尝试
plt.legend()
# 显示图表
plt.show()
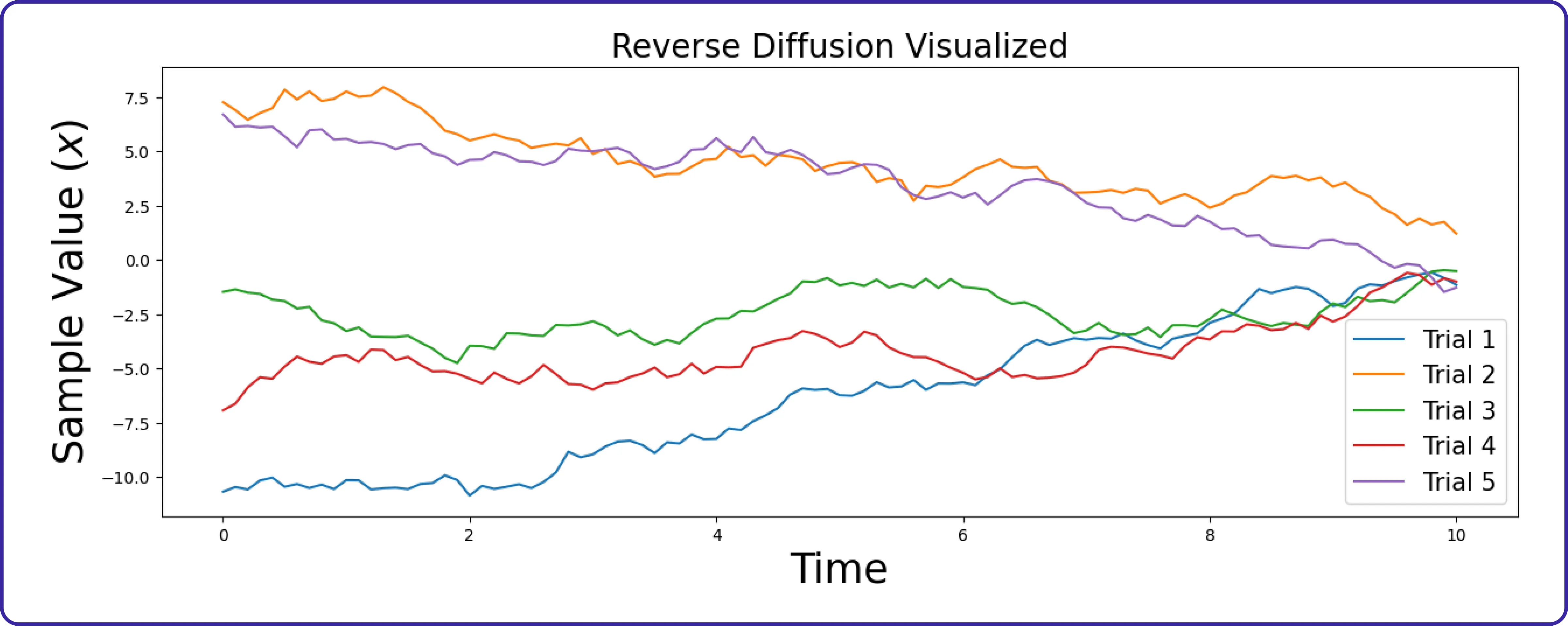
该可视化图表显示,在前向扩散过程从复杂的数据分布中创建样本后(如前一个前向扩散可视化所示),反向扩散过程通过一系列逆变换将其映射回简单分布。
学习评分函数
在现实世界场景中,我们一开始并不了解评分函数,我们的目标是学习它。一种方法是通过去噪目标训练神经网络来“去噪”样本:

这里,p0(x0) 代表我们的目标分布(例如,汽车和猫的图像),而 x(noised) 表示经过一步前向扩散后的目标分布 x0 的样本。简单来说,[ x(noised) − x0 ] 本质上是一个正态分布的随机变量。
用更接近实际实现的方式表达相同的想法:
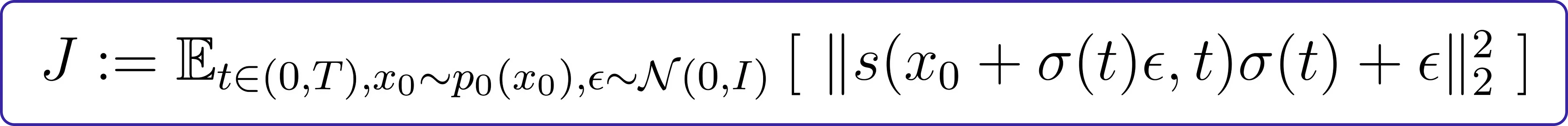
我们需要理解的一个重要概念是:在扩散过程中,我们的目标是在每个时间点t和原始分布中的每个样本 x0 上,准确地预测添加到样本每一部分的噪声量(例如,汽车、猫等)。
在这些表达式中:
- J 代表去噪目标。
- E 表示期望值。
- t 代表时间参数。
- x0 是目标分布 p0(x0) 的样本。
- x(noised) 表示在一次前向扩散步骤后目标分布的样本 x0。
- s(⋅,⋅) 代表评分函数。
- σ(t) 是时间的函数。
- ϵ 是正态分布的随机变量。
到目前为止,我们已经介绍了前向和后向扩散的基本原理,并探讨了如何学习我们的评分函数。
时间嵌入用于神经网络
学习评分函数就像将随机噪声转化为有意义的东西。为此,我们使用神经网络来近似评分函数。当处理图像时,我们希望我们的神经网络能很好地配合图像,由于评分函数依赖于时间,因此我们需要一种方法确保我们的神经网络能准确响应时间的变化。为此,我们可以使用时间嵌入。
与仅仅提供给网络一个时间值不同,我们通过多种正弦特征来表示当前时间。通过提供多种时间表示,我们旨在增强网络适应时间变化的能力。这种方法使我们能够有效地学习时间相关的评分函数 s(x,t)。
为了让我们的神经网络与时间交互,我们需要创建两个模块。
# 定义一个用于编码时间步长的高斯随机特征模块
class GaussianFourierProjection(nn.Module):
def __init__(self, embed_dim, scale=30.):
"""
参数:
- embed_dim:嵌入的维度(输出维度)
- scale:随机权重(频率)的缩放因子
"""
super().__init__()
# 在初始化期间随机采样权重(频率)。这些权重(频率)在优化过程中是固定的,不可训练。
self.W = nn.Parameter(torch.randn(embed_dim // 2) * scale, requires_grad=False)
def forward(self, x):
"""
参数:
- x:表示时间步的输入张量
"""
# 计算余弦和正弦投影:Cosine(2 pi freq x), Sine(2 pi freq x)
x_proj = x[:, None] * self.W[None, :] * 2 * np.pi
# 在最后一个维度上连接正弦和余弦投影
return torch.cat([torch.sin(x_proj), torch.cos(x_proj)], dim=-1)
GaussianFourierProjection函数设计用于创建生成高斯随机特征的模块,这些特征将用于表示我们的时间步长。当我们使用这个模块时,它会生成在优化过程中保持不变的随机频率。一旦我们将输入张量 x 提供给模块,它就会通过将 x 与这些预定义的随机频率相乘来计算正弦和余弦投影。然后这些投影会被连接起来形成输入的特征表示,有效地捕捉时间模式。这个模块在我们的任务中非常有价值,我们的目标是将时间相关信息整合到神经网络中。
# 定义一个用于将输出重塑为特征图的全连接层模块
class Dense(nn.Module):
def __init__(self, input_dim, output_dim):
"""
参数:
- input_dim:输入特征的维度
- output_dim:输出特征的维度
"""
super().__init__()
# 定义一个全连接层
self.dense = nn.Linear(input_dim, output_dim)
def forward(self, x):
"""
参数:
- x:输入张量
返回:
- 经过全连接层并重塑为4D张量(特征图)后的输出张量
"""
# 应用全连接层并将输出重塑为4D张量
return self.dense(x)[..., None, None]
# 这将2D张量广播到4D张量,在空间上添加相同的值。
Dense模块用于将全连接层的输出重塑为4D张量,有效地将其转换为特征图。该模块接受输入特征的维度(input_dim)和所需输出特征的维度(output_dim)。在前向传递过程中,输入张量 x 通过全连接层(self.dense(x))处理,并通过在末尾添加两个单一维度([…, None, None])将输出重塑为4D张量。这种重塑操作有效地将输出转换为适合进一步在卷积层中处理的特征图。这种操作通过在空间维度上添加相同的值来广播2D张量到4D张量。
现在我们已经建立了两个用于将时间交互整合到神经网络中的模块,是时候继续编码主要的神经网络了。
编码具有连接操作的U-Net架构
在处理图像时,我们的神经网络需要与图像无缝配合,并捕捉与图像相关的固有特征。
我们选择了U-Net架构,该架构结合了CNN结构与下采样/上采样操作。这种组合有助于网络在不同空间尺度上关注图像特征。
# 定义一个基于U-Net架构的时间依赖评分模型
class UNet(nn.Module):
def __init__(self, marginal_prob_std, channels=[32, 64, 128, 256], embed_dim=256):
"""
初始化一个时间依赖的评分网络。
参数:
- marginal_prob_std:一个函数,接受时间t并给出扰动核p_{0t}(x(t) | x(0))的标准差。
- channels:每个分辨率的特征图通道数。
- embed_dim:高斯随机特征嵌入的维度。
"""
super().__init__()
# 时间的高斯随机特征嵌入层
self.time_embed = nn.Sequential(
GaussianFourierProjection(embed_dim=embed_dim),
nn.Linear(embed_dim, embed_dim)
)
# 分辨率降低的编码层
self.conv1 = nn.Conv2d(1, channels[0], 3, stride=1, bias=False)
self.dense1 = Dense(embed_dim, channels[0])
self.gnorm1 = nn.GroupNorm(4, num_channels=channels[0])
self.conv2 = nn.Conv2d(channels[0], channels[1], 3, stride=2, bias=False)
self.dense2 = Dense(embed_dim, channels[1])
self.gnorm2 = nn.GroupNorm(32, num_channels=channels[1])
# 额外的编码层
self.conv3 = nn.Conv2d(channels[1], channels[2], 3, stride=2, bias=False)
self.dense3 = Dense(embed_dim, channels[2])
self.gnorm3 = nn.GroupNorm(32, num_channels=channels[2])
self.conv4 = nn.Conv2d(channels[2], channels[3], 3, stride=2, bias=False)
self.dense4 = Dense(embed_dim, channels[3])
self.gnorm4 = nn.GroupNorm(32, num_channels=channels[3])
# 分辨率增加的解码层
self.tconv4 = nn.ConvTranspose2d(channels[3], channels[2], 3, stride=2, bias=False)
self.dense5 = Dense(embed_dim, channels[2])
self.tgnorm4 = nn.GroupNorm(32, num_channels=channels[2])
self.tconv3 = nn.ConvTranspose2d(channels[2] + channels[2], channels[1], 3, stride=2, bias=False, output_padding=1)
self.dense6 = Dense(embed_dim, channels[1])
self.tgnorm3 = nn.GroupNorm(32, num_channels=channels[1])
self.tconv2 = nn.ConvTranspose2d(channels[1] + channels[1], channels[0], 3, stride=2, bias=False, output_padding=1)
self.dense7 = Dense(embed_dim, channels[0])
self.tgnorm2 = nn.GroupNorm(32, num_channels=channels[0])
self.tconv1 = nn.ConvTranspose2d(channels[0] + channels[0], 1, 3, stride=1)
# Swish激活函数
self.act = lambda x: x * torch.sigmoid(x)
self.marginal_prob_std = marginal_prob_std
def forward(self, x, t, y=None):
"""
参数:
- x:输入张量
- t:时间张量
- y:目标张量(在此前向传递中未使用)
返回:
- h:经过U-Net架构处理后的输出张量
"""
# 获取时间t的高斯随机特征嵌入
embed = self.act(self.time_embed(t))
# 编码路径
h1 = self.conv1(x) + self.dense1(embed)
h1 = self.act(self.gnorm1(h1))
h2 = self.conv2(h1) + self.dense2(embed)
h2 = self.act(self.gnorm2(h2))
# 额外的编码路径层
h3 = self.conv3(h2) + self.dense3(embed)
h3 = self.act(self.gnorm3(h3))
h4 = self.conv4(h3) + self.dense4(embed)
h4 = self.act(self.gnorm4(h4))
# 解码路径
h = self.tconv4(h4)
h += self.dense5(embed)
h = self.act(self.tgnorm4(h))
h = self.tconv3(torch.cat([h, h3], dim=1))
h += self.dense6(embed)
h = self.act(self.tgnorm3(h))
h = self.tconv2(torch.cat([h, h2], dim=1))
h += self.dense7(embed)
h = self.act(self.tgnorm2(h))
h = self.tconv1(torch.cat([h, h1], dim=1))
# 归一化输出
h = h / self.marginal_prob_std(t)[:, None, None, None]
return h
我们创建了一个理解事物随时间变化的模型。它使用了一种称为U-Net的特殊架构。想象一下,你有一个起始图像,并且你想看到它在不同时间点上的变换。模型从这些变换中学习模式和细节。代码定义了这种学习是如何发生的,使用了各种层和计算。它确保输出或生成的图像根据时间信息进行适当调整。它就像一个理解和预测视觉上事物演变的智能工具。
在U-Net模型的架构中,张量的形状在信息经过编码和解码路径时不断变化。在编码路径中,涉及下采样,张量随着每个卷积层(h1, h2, h3, h4)依次减少形状。在解码路径中,转置卷积层开始恢复空间信息。张量 h 开始恢复原始的空间维度,并在每一步(从 h4 到 h1)中添加来自早期层的特征,以促进上采样。最后一层 h 产生输出,并通过归一化步骤确保生成图像的适当缩放。张量形状的具体细节取决于卷积层中使用的滤波器大小、步幅和填充,这些都塑造了模型捕捉和重建细节的能力。
编码具有加法操作的U-Net架构
扩散模型可以与各种架构选择一起很好地工作。在我们构建的前一个模型中,我们使用连接操作将下采样块的张量结合起来作为跳跃连接。在即将编码的模型中,我们将简单地将下采样块的张量相加作为跳跃连接。
# 定义一个基于U-Net架构的时间依赖评分模型
class UNet_res(nn.Module):
def __init__(self, marginal_prob_std, channels=[32, 64, 128, 256], embed_dim=256):
"""
参数:
- marginal_prob_std:一个函数,接受时间t并给出扰动核p_{0t}(x(t) | x(0))的标准差。
- channels:每个分辨率的特征图通道数。
- embed_dim:高斯随机特征嵌入的维度。
"""
super().__init__()
# 时间的高斯随机特征嵌入层
self.time_embed = nn.Sequential(
GaussianFourierProjection(embed_dim=embed_dim),
nn.Linear(embed_dim, embed_dim)
)
# 分辨率降低的编码层
self.conv1 = nn.Conv2d(1, channels[0], 3, stride=1, bias=False)
self.dense1 = Dense(embed_dim, channels[0])
self.gnorm1 = nn.GroupNorm(4, num_channels=channels[0])
self.conv2 = nn.Conv2d(channels[0], channels[1], 3, stride=2, bias=False)
self.dense2 = Dense(embed_dim, channels[1])
self.gnorm2 = nn.GroupNorm(32, num_channels=channels[1])
self.conv3 = nn.Conv2d(channels[1], channels[2], 3, stride=2, bias=False)
self.dense3 = Dense(embed_dim, channels[2])
self.gnorm3 = nn.GroupNorm(32, num_channels=channels[2])
self.conv4 = nn.Conv2d(channels[2], channels[3], 3, stride=2, bias=False)
self.dense4 = Dense(embed_dim, channels[3])
self.gnorm4 = nn.GroupNorm(32, num_channels=channels[3])
# 分辨率增加的解码层
self.tconv4 = nn.ConvTranspose2d(channels[3], channels[2], 3, stride=2, bias=False)
self.dense5 = Dense(embed_dim, channels[2])
self.tgnorm4 = nn.GroupNorm(32, num_channels=channels[2])
self.tconv3 = nn.ConvTranspose2d(channels[2], channels[1], 3, stride=2, bias=False, output_padding=1)
self.dense6 = Dense(embed_dim, channels[1])
self.tgnorm3 = nn.GroupNorm(32, num_channels=channels[1])
self.tconv2 = nn.ConvTranspose2d(channels[1], channels[0], 3, stride=2, bias=False, output_padding=1)
self.dense7 = Dense(embed_dim, channels[0])
self.tgnorm2 = nn.GroupNorm(32, num_channels=channels[0])
self.tconv1 = nn.ConvTranspose2d(channels[0], 1, 3, stride=1)
# Swish激活函数
self.act = lambda x: x * torch.sigmoid(x)
self.marginal_prob_std = marginal_prob_std
def forward(self, x, t, y=None):
"""
参数:
- x:输入张量
- t:时间张量
- y:目标张量(在此前向传递中未使用)
返回:
- h:经过U-Net架构处理后的输出张量
"""
# 获取时间t的高斯随机特征嵌入
embed = self.act(self.time_embed(t))
# 编码路径
h1 = self.conv1(x) + self.dense1(embed)
h1 = self.act(self.gnorm1(h1))
h2 = self.conv2(h1) + self.dense2(embed)
h2 = self.act(self.gnorm2(h2))
h3 = self.conv3(h2) + self.dense3(embed)
h3 = self.act(self.gnorm3(h3))
h4 = self.conv4(h3) + self.dense4(embed)
h4 = self.act(self.gnorm4(h4))
# 解码路径
h = self.tconv4(h4)
h += self.dense5(embed)
h = self.act(self.tgnorm4(h))
h = self.tconv3(h + h3)
h += self.dense6(embed)
h = self.act(self.tgnorm3(h))
h = self.tconv2(h + h2)
h += self.dense7(embed)
h = self.act(self.tgnorm2(h))
h = self.tconv1(h + h1)
# 归一化输出
h = h / self.marginal_prob_std(t)[:, None, None, None]
return h
我们刚刚编码的UNet_res模型是标准UNet模型的一个变体。虽然两个模型都遵循U-Net架构,但关键区别在于跳跃连接的实现。在原始UNet模型中,跳跃连接通过将编码路径中的张量与解码路径中的张量连接起来实现。然而,在UNet_res模型中,跳跃连接通过直接将编码路径中的张量添加到解码路径中的相应张量实现。这种跳跃连接策略的变化可以影响不同分辨率级别之间的信息流和相互作用,可能会影响模型捕捉数据中的特征和依赖关系的能力。
指数噪声的前向扩散过程
我们将定义特定的前向扩散过程:

这个公式表示一个动态系统,其中变量 x 随着时间 (t) 的变化而变化,并引入了噪声 (dw)。噪声水平由参数 σ 决定,并且随着时间的推移呈指数增长。
给定这个过程和初始值 x(0),我们可以找到 x(t) 的解析解:

在此上下文中,σ(t) 被称为边际标准差。本质上,它表示给定初始值 x(0) 时 x(t) 分布的变异性。
对于我们的具体情况,边际标准差计算如下:

该公式提供了对噪声水平(σ)随时间演变的详细理解,影响了系统的可变性。
# 使用GPU
device = "cuda"
# 边际概率标准差函数
def marginal_prob_std(t, sigma):
"""
计算 $p_{0t}(x(t) | x(0))$ 的均值和标准差。
参数:
- t: 时间步向量。
- sigma: SDE 中的 $\sigma$。
返回:
- 标准差。
"""
# 将时间步转换为PyTorch张量
t = torch.tensor(t, device=device)
# 根据给定公式计算并返回标准差
return torch.sqrt((sigma**(2 * t) - 1.) / 2. / np.log(sigma))
现在我们已经编写了边际概率标准差的函数,我们可以类似地编写扩散系数。
# 使用GPU
device = "cuda"
def diffusion_coeff(t, sigma):
"""
计算SDE的扩散系数。
参数:
- t: 时间步向量。
- sigma: SDE 中的 $\sigma$。
返回:
- 扩散系数向量。
"""
# 根据给定公式计算并返回扩散系数
return torch.tensor(sigma**t, device=device)
现在我们以sigma为25初始化边际概率标准差和扩散系数
# Sigma值
sigma = 25.0
# 边际概率标准差
marginal_prob_std_fn = functools.partial(marginal_prob_std, sigma=sigma)
# 扩散系数
diffusion_coeff_fn = functools.partial(diffusion_coeff, sigma=sigma)
在编码完两个模块后,是时候为我们的稳定扩散架构开发损失函数了。
编写损失函数
现在,我们将把之前制作的U-Net与学习得分函数的方法结合起来。我们将创建一个损失函数并训练神经网络。
def loss_fn(model, x, marginal_prob_std, eps=1e-5):
"""
用于训练基于得分的生成模型的损失函数。
参数:
- model: 表示时间相关的基于得分的模型的PyTorch模型实例。
- x: 训练数据的小批量。
- marginal_prob_std: 提供扰动核的标准差的函数。
- eps: 数值稳定性的容差值。
"""
# 在范围(eps, 1-eps)内均匀采样时间
random_t = torch.rand(x.shape[0], device=x.device) * (1. - 2 * eps) + eps
# 在采样时间`t`找到噪声标准差
std = marginal_prob_std(random_t)
# 生成正态分布的噪声
z = torch.randn_like(x)
# 使用生成的噪声扰动输入数据
perturbed_x = x + z * std[:, None, None, None]
# 使用扰动数据和时间从模型获取得分
score = model(perturbed_x, random_t)
# 基于得分和噪声计算损失
loss = torch.mean(torch.sum((score * std[:, None, None, None] + z)**2, dim=(1, 2, 3)))
return loss
这个损失函数在训练过程中确定模型的误差。它涉及选择随机时间,获取噪声水平,将该噪声添加到数据中,然后检查模型的预测与实际情况的偏差。目标是在训练过程中减少这个误差。
编写采样器
稳定扩散通过从完全随机的图像开始创建图像。然后,噪声预测器猜测图像的噪声程度,并从图像中移除该猜测的噪声。这个循环重复多次,最终产生一个干净的图像。
这种清理过程被称为“采样”,因为稳定扩散在每个步骤中都会生成一个新的图像样本。创建这些样本的方法称为“采样器”或“采样方法”。
稳定扩散有多种创建图像样本的方法,我们将使用的一种方法是Euler–Maruyama方法,也称为Euler方法。
# 采样步骤数
num_steps = 500
def Euler_Maruyama_sampler(score_model,
marginal_prob_std,
diffusion_coeff,
batch_size=64,
x_shape=(1, 28, 28),
num_steps=num_steps,
device='cuda',
eps=1e-3, y=None):
"""
使用Euler-Maruyama求解器从基于得分的模型生成样本。
参数:
- score_model: 表示时间相关的基于得分的模型的PyTorch模型。
- marginal_prob_std: 提供扰动核的标准差的函数。
- diffusion_coeff: 提供SDE的扩散系数的函数。
- batch_size: 每次调用该函数生成的采样数。
- x_shape: 样本的形状。
- num_steps: 采样步骤数,相当于离散化的时间步数。
- device: 'cuda'表示在GPU上运行,'cpu'表示在CPU上运行。
- eps: 数值稳定性的最小时间步。
- y: 目标张量(在此函数中未使用)。
返回:
- 样本。
"""
# 初始化时间和初始样本
t = torch.ones(batch_size, device=device)
init_x = torch.randn(batch_size, *x_shape, device=device) * marginal_prob_std(t)[:, None, None, None]
# 生成时间步
time_steps = torch.linspace(1., eps, num_steps, device=device)
step_size = time_steps[0] - time_steps[1]
x = init_x
# 使用Euler-Maruyama方法采样
with torch.no_grad():
for time_step in tqdm(time_steps):
batch_time_step = torch.ones(batch_size, device=device) * time_step
g = diffusion_coeff(batch_time_step)
mean_x = x + (g**2)[:, None, None, None] * score_model(x, batch_time_step, y=y) * step_size
x = mean_x + torch.sqrt(step_size) * g[:, None, None, None] * torch.randn_like(x)
# 最后的采样步骤中不包含任何噪声。
return mean_x
此函数使用Euler-Maruyama方法生成图像样本,结合基于得分的模型、噪声标准差函数和扩散系数函数。它在指定的步骤数上迭代应用该方法,返回最终生成的样本集。
训练基于U-Net拼接架构
我们已经开发了两种U-Net架构:一种利用加法,另一种利用拼接。为了开始训练,我们将使用基于拼接的U-Net架构,并采用以下超参数:训练50个epoch,小批量大小为2048,学习率为5e-4。训练将在MNIST数据集上进行。
# 定义基于得分的模型并将其移动到指定设备
score_model = torch.nn.DataParallel(UNet(marginal_prob_std=marginal_prob_std_fn))
score_model = score_model.to(device)
# 训练epoch数
n_epochs = 50
# 小批量大小
batch_size = 2048
# 学习率
lr = 5e-4
# 加载MNIST数据集并创建数据加载器
dataset = MNIST('.', train=True, transform=transforms.ToTensor(), download=True)
data_loader = DataLoader(dataset, batch_size=batch_size, shuffle=True, num_workers=4)
# 定义Adam优化器来训练模型
optimizer = Adam(score_model.parameters(), lr=lr)
# epoch的进度条
tqdm_epoch = trange(n_epochs)
for epoch in tqdm_epoch:
avg_loss = 0.
num_items = 0
# 迭代数据加载器中的小批量数据
for x, y in tqdm(data_loader):
x = x.to(device)
# 计算损失并执行反向传播
loss = loss_fn(score_model, x, marginal_prob_std_fn)
optimizer.zero_grad()
loss.backward()
optimizer.step()
avg_loss += loss.item() * x.shape[0]
num_items += x.shape[0]
# 打印当前epoch的平均训练损失
tqdm_epoch.set_description('Average Loss: {:5f}'.format(avg_loss / num_items))
# 在每个训练epoch后保存模型检查点
torch.save(score_model.state_dict(), 'ckpt.pth')
在执行训练代码后,预计每个epoch的整个训练过程将大约需要7分钟。跨epoch观察到的平均损失为34.128,训练好的模型将以文件名“ckpt.pth”保存在当前目录中。
让我们可视化基于拼接的U-Net架构的结果。重要的是要注意,我们还没有开始开发传递提示以生成特定结果的系统。目前的可视化仅基于随机输入。
#从磁盘加载预训练的检查点。
device = 'cuda'
# 加载预训练的模型检查点
ckpt = torch.load('ckpt.pth', map_location=device)
score_model.load_state_dict(ckpt)
# 设置采样批量大小和步骤数
sample_batch_size = 64
num_steps = 500
# 选择Euler-Maruyama采样器
sampler = Euler_Maruyama_sampler
# 使用指定的采样器生成样本
samples = sampler(score_model,
marginal_prob_std_fn,
diffusion_coeff_fn,
sample_batch_size,
num_steps=num_steps,
device=device,
y=None)
# 将样本裁剪到范围[0, 1]
samples = samples.clamp(0.0, 1.0)
# 可视化生成的样本
%matplotlib inline
import matplotlib.pyplot as plt
sample_grid = make_grid(samples, nrow=int(np.sqrt(sample_batch_size)))
# 绘制样本网格
plt.figure(figsize=(6, 6))
plt.axis('off')
plt.imshow(sample_grid.permute(1, 2, 0).cpu(), vmin=0., vmax=1.)
plt.show()

基于加法的U-Net架构相比于基于拼接的架构表现更好。它可以更清晰地识别图像中的数字,并且在训练过程中使用这种架构时,损失值始终在下降。
到目前为止,我们的架构生成了随机的图像样本。然而,目标是使我们的稳定扩散模型能够在提供输入时手绘指定的数字。
构建注意力层
在创建注意力模型时,我们通常有三个主要部分:
- 交叉注意力:处理序列的自注意力和交叉注意力。
- Transformer块:将注意力与神经网络结合以进行处理。
- 空间变换器:在U-net中将空间张量转换为序列形式,反之亦然。
让我们以更简单的方式分解注意力模型背后的数学。在QKV(查询-键-值)注意力中,我们将查询、键和值表示为向量。这些向量帮助我们在翻译任务的两端连接单词或图像。
这些向量(q, k, v)与编码器的隐藏状态向量(e)和解码器的隐藏状态向量(h)线性相关:

为了决定要“关注”什么,我们计算每个键(k)和查询(q)的内积(相似度)。为了确保这些值是合理的,我们通过查询向量(qi)的长度对它们进行归一化。
最终的注意力分布是通过对这些值应用softmax函数获得的:

这种注意力分布有助于挑选出相关的特征组合。例如,当把短语“This is cool”从英语翻译成法语时,正确的答案(“c’est cool”)涉及同时关注两个词,而不是单独翻译每个词。从数学上讲,我们使用注意力分布对值(vj)进行加权:
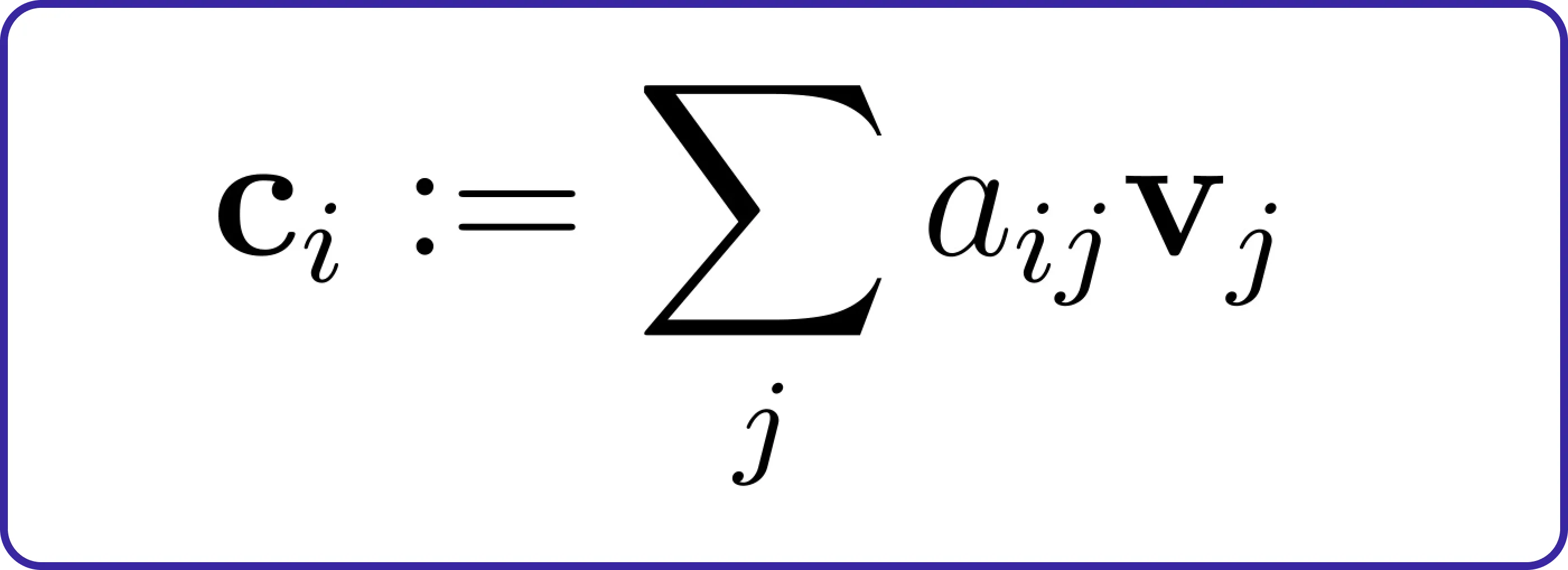
现在我们了解了注意力机制的基础以及需要构建的三个注意力模块,让我们开始编写它们的代码。
我们先从编写第一个注意力层——交叉注意力(CrossAttention)开始。
class CrossAttention(nn.Module):
def __init__(self, embed_dim, hidden_dim, context_dim=None, num_heads=1):
"""
初始化 CrossAttention 模块。
参数:
- embed_dim: 输出嵌入的维度。
- hidden_dim: 隐藏表示的维度。
- context_dim: 上下文表示的维度(如果不是自注意力)。
- num_heads: 注意力头的数量(目前支持1个头)。
注意: 为了简化实现,假设使用1头注意力。
可以通过复杂的张量操作实现多头注意力。
"""
super(CrossAttention, self).__init__()
self.hidden_dim = hidden_dim
self.context_dim = context_dim
self.embed_dim = embed_dim
# 查询投影的线性层
self.query = nn.Linear(hidden_dim, embed_dim, bias=False)
# 判断是自注意力还是交叉注意力
if context_dim is None:
self.self_attn = True
self.key = nn.Linear(hidden_dim, embed_dim, bias=False)
self.value = nn.Linear(hidden_dim, hidden_dim, bias=False)
else:
self.self_attn = False
self.key = nn.Linear(context_dim, embed_dim, bias=False)
self.value = nn.Linear(context_dim, hidden_dim, bias=False)
def forward(self, tokens, context=None):
"""
CrossAttention 模块的前向传播。
参数:
- tokens: 输入的 tokens,形状为 [batch, sequence_len, hidden_dim]。
- context: 上下文信息,形状为 [batch, context_seq_len, context_dim]。
如果 self_attn 为 True,则忽略 context。
返回:
- ctx_vecs: 注意力后的上下文向量,形状为 [batch, sequence_len, embed_dim]。
"""
if self.self_attn:
# 自注意力情况
Q = self.query(tokens)
K = self.key(tokens)
V = self.value(tokens)
else:
# 交叉注意力情况
Q = self.query(tokens)
K = self.key(context)
V = self.value(context)
# 计算分数矩阵、注意力矩阵和上下文向量
scoremats = torch.einsum("BTH,BSH->BTS", Q, K) # Q 和 K 的内积
attnmats = F.softmax(scoremats / math.sqrt(self.embed_dim), dim=-1) # scoremats 的 softmax
ctx_vecs = torch.einsum("BTS,BSH->BTH", attnmats, V) # 使用 attnmats 加权平均 V 向量
return ctx_vecs
CrossAttention 类是一个用于处理神经网络中注意力机制的模块。它接收输入 tokens 和(可选的)上下文信息。如果用于自注意力,则专注于输入 tokens 之间的关系;在交叉注意力的情况下,考虑输入 tokens 和上下文信息之间的交互。该模块使用线性投影进行查询、键和值的转换。它计算分数矩阵、应用 softmax 得到注意力权重,并通过结合加权的值计算上下文向量。前向方法实现了这些操作,返回注意力后的上下文向量。
让我们继续编写第二个注意力层,称为 TransformerBlock。
class TransformerBlock(nn.Module):
"""结合自注意力、交叉注意力和前馈神经网络的 Transformer 块"""
def __init__(self, hidden_dim, context_dim):
"""
初始化 TransformerBlock。
参数:
- hidden_dim: 隐藏状态的维度。
- context_dim: 上下文张量的维度。
注意: 为了简化,自注意力和交叉注意力使用相同的 hidden_dim。
"""
super(TransformerBlock, self).__init__()
# 自注意力模块
self.attn_self = CrossAttention(hidden_dim, hidden_dim)
# 交叉注意力模块
self.attn_cross = CrossAttention(hidden_dim, hidden_dim, context_dim)
# 层归一化模块
self.norm1 = nn.LayerNorm(hidden_dim)
self.norm2 = nn.LayerNorm(hidden_dim)
self.norm3 = nn.LayerNorm(hidden_dim)
# 实现一个具有 3 * hidden_dim 隐藏单元的 2 层 MLP,使用 nn.GELU 激活函数
self.ffn = nn.Sequential(
nn.Linear(hidden_dim, 3 * hidden_dim),
nn.GELU(),
nn.Linear(3 * hidden_dim, hidden_dim)
)
def forward(self, x, context=None):
"""
TransformerBlock 的前向传播。
参数:
- x: 输入张量,形状为 [batch, sequence_len, hidden_dim]。
- context: 上下文张量,形状为 [batch, context_seq_len, context_dim]。
返回:
- x: 经过 TransformerBlock 后的输出张量。
"""
# 使用层归一化和残差连接应用自注意力
x = self.attn_self(self.norm1(x)) + x
# 使用层归一化和残余连接应用交叉注意力
x = self.attn_cross(self.norm2(x), context=context) + x
# 使用层归一化和残余连接应用前馈神经网络
x = self.ffn(self.norm3(x)) + x
return x
TransformerBlock 类表示 transformer 模型中的一个构建块,结合了自注意力、交叉注意力和前馈神经网络。它接收形状为 [batch, sequence_len, hidden_dim] 的输入张量,以及(可选的)形状为 [batch, context_seq_len, context_dim] 的上下文张量。自注意力和交叉注意力模块后接层归一化和残差连接。此外,该块还包含一个具有 GELU 非线性激活函数的两层 MLP,用于进一步的非线性变换。输出是通过 TransformerBlock 后得到的张量。
让我们继续编写最后一个注意力层,称为 SpatialTransformer。
class SpatialTransformer(nn.Module):
def __init__(self, hidden_dim, context_dim):
"""
初始化 SpatialTransformer。
参数:
- hidden_dim: 隐藏状态的维度。
- context_dim: 上下文张量的维度。
"""
super(SpatialTransformer, self).__init__()
# 用于空间变换的 TransformerBlock
self.transformer = TransformerBlock(hidden_dim, context_dim)
def forward(self, x, context=None):
"""
SpatialTransformer 的前向传播。
参数:
- x: 输入张量,形状为 [batch, channels, height, width]。
- context: 上下文张量,形状为 [batch, context_seq_len, context_dim]。
返回:
- x: 经过空间变换后的输出张量。
"""
b, c, h, w = x.shape
x_in = x
# 合并空间维度并将通道维度移动到最后
x = rearrange(x, "b c h w -> b (h w) c")
# 应用序列 transformer
x = self.transformer(x, context)
# 逆向过程
x = rearrange(x, 'b (h w) c -> b c h w', h=h, w=w)
# 残差连接
return x + x_in
现在,可以将 SpatialTransformer 层合并到我们的 U-Net 架构中。
使用空间变换器编码 U-Net 架构
我们将使用上一步创建的注意力层来编码 U-Net 架构。
class UNet_Tranformer(nn.Module):
"""基于 U-Net 架构构建的时间依赖性得分模型。"""
def __init__(self, marginal_prob_std, channels=[32, 64, 128, 256], embed_dim=256,
text_dim=256, nClass=10):
"""
初始化一个时间依赖的得分模型。
参数:
- marginal_prob_std: 一个函数,输入时间 t 并返回扰动核 p_{0t}(x(t) | x(0)) 的标准差。
- channels: 每个分辨率的特征图通道数。
- embed_dim: 时间的高斯随机特征嵌入维度。
- text_dim: 文本/数字的嵌入维度。
- nClass: 要建模的类数。
"""
super().__init__()
# 时间的高斯随机特征嵌入层
self.time_embed = nn.Sequential(
GaussianFourierProjection(embed_dim=embed_dim),
nn.Linear(embed_dim, embed_dim)
)
# 分辨率减小的编码层
self.conv1 = nn.Conv2d(1, channels[0], 3, stride=1
, bias=False)
self.dense1 = Dense(embed_dim, channels[0])
self.gnorm1 = nn.GroupNorm(4, num_channels=channels[0])
self.conv2 = nn.Conv2d(channels[0], channels[1], 3, stride=2, bias=False)
self.dense2 = Dense(embed_dim, channels[1])
self.gnorm2 = nn.GroupNorm(32, num_channels=channels[1])
self.conv3 = nn.Conv2d(channels[1], channels[2], 3, stride=2, bias=False)
self.dense3 = Dense(embed_dim, channels[2])
self.gnorm3 = nn.GroupNorm(32, num_channels=channels[2])
self.attn3 = SpatialTransformer(channels[2], text_dim)
self.conv4 = nn.Conv2d(channels[2], channels[3], 3, stride=2, bias=False)
self.dense4 = Dense(embed_dim, channels[3])
self.gnorm4 = nn.GroupNorm(32, num_channels=channels[3])
self.attn4 = SpatialTransformer(channels[3], text_dim)
# 分辨率增加的解码层
self.tconv4 = nn.ConvTranspose2d(channels[3], channels[2], 3, stride=2, bias=False)
self.dense5 = Dense(embed_dim, channels[2])
self.tgnorm4 = nn.GroupNorm(32, num_channels=channels[2])
self.tconv3 = nn.ConvTranspose2d(channels[2], channels[1], 3, stride=2, bias=False, output_padding=1)
self.dense6 = Dense(embed_dim, channels[1])
self.tgnorm3 = nn.GroupNorm(32, num_channels=channels[1])
self.tconv2 = nn.ConvTranspose2d(channels[1], channels[0], 3, stride=2, bias=False, output_padding=1)
self.dense7 = Dense(embed_dim, channels[0])
self.tgnorm2 = nn.GroupNorm(32, num_channels=channels[0])
self.tconv1 = nn.ConvTranspose2d(channels[0], 1, 3, stride=1)
# 使用 swish 激活函数
self.act = nn.SiLU()
self.marginal_prob_std = marginal_prob_std
self.cond_embed = nn.Embedding(nClass, text_dim)
def forward(self, x, t, y=None):
"""
UNet_Transformer 模型的前向传播。
参数:
- x: 输入张量。
- t: 时间张量。
- y: 目标张量。
返回:
- h: 经过 UNet_Transformer 架构后的输出张量。
"""
# 获取时间的高斯随机特征嵌入
embed = self.act(self.time_embed(t))
y_embed = self.cond_embed(y).unsqueeze(1)
# 编码路径
h1 = self.conv1(x) + self.dense1(embed)
h1 = self.act(self.gnorm1(h1))
h2 = self.conv2(h1) + self.dense2(embed)
h2 = self.act(self.gnorm2(h2))
h3 = self.conv3(h2) + self.dense3(embed)
h3 = self.act(self.gnorm3(h3))
h3 = self.attn3(h3, y_embed)
h4 = self.conv4(h3) + self.dense4(embed)
h4 = self.act(self.gnorm4(h4))
h4 = self.attn4(h4, y_embed)
# 解码路径
h = self.tconv4(h4) + self.dense5(embed)
h = self.act(self.tgnorm4(h))
h = self.tconv3(h + h3) + self.dense6(embed)
h = self.act(self.tgnorm3(h))
h = self.tconv2(h + h2) + self.dense7(embed)
h = self.act(self.tgnorm2(h))
h = self.tconv1(h + h1)
# 归一化输出
h = h / self.marginal_prob_std(t)[:, None, None, None]
return h
现在我们已经实现了带有注意力层的 U-Net 架构,是时候更新我们的损失函数了。
使用去噪条件更新 U-Net 损失
让我们通过在训练期间加入 y 信息来更新损失函数。
def loss_fn_cond(model, x, y, marginal_prob_std, eps=1e-5):
"""使用条件信息训练得分生成模型的损失函数。
参数:
- model: 表示时间依赖得分模型的 PyTorch 模型实例。
- x: 一小批训练数据。
- y: 条件信息(目标张量)。
- marginal_prob_std: 一个函数,返回扰动核的标准差。
- eps: 数值稳定性的容差值。
返回:
- loss: 计算出的损失。
"""
# 在范围 [eps, 1-eps] 内均匀采样时间
random_t = torch.rand(x.shape[0], device=x.device) * (1. - eps) + eps
# 生成与输入形状相同的随机噪声
z = torch.randn_like(x)
# 计算采样时间下扰动核的标准差
std = marginal_prob_std(random_t)
# 用生成的噪声和标准差扰动输入数据
perturbed_x = x + z * std[:, None, None, None]
# 获取模型对扰动输入的得分,考虑条件信息
score = model(perturbed_x, random_t, y=y)
# 使用得分和扰动计算损失
loss = torch.mean(torch.sum((score * std[:, None, None, None] + z)**2, dim=(1, 2, 3)))
return loss
这个更新的损失函数计算带有附加条件的生成模型的损失。它包括采样时间、生成噪声、扰动输入数据,并基于模型的得分和扰动计算损失。
训练带有注意力层的 U-Net 架构
基于注意力层训练 U-Net 架构的优势在于,一旦训练完成,我们可以为我们的稳定扩散模型提供一个特定的数字进行绘制。让我们使用以下超参数启动训练过程:100 个 epoch,1024 的小批量大小,和 10e-3 的学习率。训练将使用 MNIST 数据集进行。
# 指定是否继续训练或初始化新模型
continue_training = False # 设置为 True 或 False
if not continue_training:
# 初始化一个新的带 Transformer 的 UNet 模型
score_model = torch.nn.DataParallel(UNet_Tranformer(marginal_prob_std=marginal_prob_std_fn))
score_model = score_model.to(device)
# 设置训练超参数
n_epochs = 100 # {'type':'integer'}
batch_size = 1024 # {'type':'integer'}
lr = 10e-4 # {'type':'number'}
# 加载 MNIST 数据集并创建数据加载器
dataset = MNIST('.', train=True, transform=transforms.ToTensor(), download=True)
data_loader = DataLoader(dataset, batch_size=batch_size, shuffle=True, num_workers=4)
# 定义优化器和学习率调度器
optimizer = Adam(score_model.parameters(), lr=lr)
scheduler = LambdaLR(optimizer, lr_lambda=lambda epoch: max(0.2, 0.98 ** epoch))
# 使用 tqdm 显示 epoch 的进度条
tqdm_epoch = trange(n_epochs)
for epoch in tqdm_epoch:
avg_loss = 0.
num_items = 0
# 遍历数据加载器中的批次
for x, y in tqdm(data_loader):
x = x.to(device)
# 使用条件得分模型计算损失
loss = loss_fn_cond(score_model, x, y, marginal_prob_std_fn)
optimizer.zero_grad()
loss.backward()
optimizer.step()
avg_loss += loss.item() * x.shape[0]
num_items += x.shape[0]
# 使用调度器调整学习率
scheduler.step()
lr_current = scheduler.get_last_lr()[0]
# 打印 epoch 信息,包括平均损失和当前学习率
print('{} Average Loss: {:5f} lr {:.1e}'.format(epoch, avg_loss / num_items, lr_current))
tqdm_epoch.set_description('Average Loss: {:5f}'.format(avg_loss / num_items))
# 在每个 epoch 结束后保存模型检查点
torch.save(score_model.state_dict(), 'ckpt_transformer.pth')
执行训练代码后,整个训练过程预计将在大约 20 分钟内完成。跨 epoch 的平均损失为 21.413,训练后的模型将保存在当前目录中,文件名为 “ckpt_transformer.pth”。
生成图像
现在,通过注意力层添加条件生成,我们可以指示我们的稳定扩散模型绘制任何数字。让我们看看模型在绘制数字 9 时的表现
# 从磁盘加载预训练的检查点。
# device = 'cuda' #@param ['cuda', 'cpu'] {'type':'string'}
ckpt = torch.load('ckpt_transformer.pth', map_location=device)
score_model.load_state_dict(ckpt)
#指定生成样本的数字
###########
digit = 9 #@param {'type':'integer'}
# 设置生成样本的批量大小
sample_batch_size = 64 #@param {'type':'integer'}
# 设置Euler-Maruyama采样器的步数
num_steps = 250 #@param {'type':'integer'}
# 选择采样器类型(Euler-Maruyama, pc_sampler, ode_sampler)
sampler = Euler_Maruyama_sampler #@param ['Euler_Maruyama_sampler', 'pc_sampler', 'ode_sampler'] {'type': 'raw'}
# score_model.eval()
## 使用指定的采样器生成样本。
samples = sampler(score_model,
marginal_prob_std_fn,
diffusion_coeff_fn,
sample_batch_size,
num_steps=num_steps,
device=device,
y=digit*torch.ones(sample_batch_size, dtype=torch.long))
## 样本可视化。
samples = samples.clamp(0.0, 1.0)
%matplotlib inline
import matplotlib.pyplot as plt
# 创建样本网格以便可视化
sample_grid = make_grid(samples, nrow=int(np.sqrt(sample_batch_size)))
# 绘制生成的样本
plt.figure(figsize=(6,6))
plt.axis('off')
plt.imshow(sample_grid.permute(1, 2, 0).cpu(), vmin=0., vmax=1.)
plt.show()

以下是由我们的稳定扩散架构生成的所有数字的可视化结果。

下一步
我们在 MNIST 数据集上训练了稳定扩散架构,该数据集相对较小。
你可以尝试在CelebA数据集上进行训练,只需稍作修改。我尝试过,但它导致Colab GPU崩溃,这表明即使是一个适度的稳定扩散模型也需要大量的计算能力。或者,你可以探索微调现有的开源稳定扩散版本。
















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









