







节前,我们星球组织了一场算法岗技术&面试讨论会,邀请了一些互联网大厂朋友、参加社招和校招面试的同学。
针对算法岗技术趋势、大模型落地项目经验分享、新手如何入门算法岗、该如何准备、面试常考点分享等热门话题进行了深入的讨论。
合集:
AIGC生图需要进行质量评估以确保满足一定标准。这一评估过程非常重要,因其关系到内容的专业性、商业价值以及顾客的满意度。
然而,传统的手动评估方式既耗时又耗力,且容易受到主观偏差的影响,导致评估成本高昂而效果不佳。目前对基模型的优化效果的全面评测,包含了十多个维度,全部标注需要2~4个人日。如果涉及模型整体效果的迭代,则需要更多的人力投入。
鉴于此,自动化的质量评估方法成为一种迫切需求。通过采用算法和机器学习模型,自动化评估可以快速、准确地执行质量检查,不仅节省了大量人力资源,还提高了评估的一致性和准确性。自动化评估工具还能实现实时监控和即时反馈,从而提升整个生产流程的效率和内容的质量。
总之,自动化质量评估在提高AIGC生图质量与生产效率方面发挥着不可替代的作用。本文将分享几项最新的研究进展,希望能给大家带来帮助~
APDD
主要内容
计算视觉美学是计算机视觉领域中一个非常重要的研究领域,主要涉及大型数据集训练以及神经网络模型优化,使模型能够提供对美学质量的评估。因此,构建图像美学质量评估(IAQA)基准数据集已成为推进这一方向研究的关键前提。然而,现有的数据主要关注图像的总审美得分,而对图像类别和审美属性的研究探索有限。此外,大多数现有的数据集都是在摄影领域创建的,在艺术图像领域研究不足。
本项目主要对艺术图像进行美学评估,虽然没有使用文生图模型生成的图像,但是对于图像的美学质量评估提供了一套完整的处理思路。本项目提出了一个清晰的框架来量化艺术图像中的美学分数;构建了艺术领域的多属性、多类别绘画数据集,即绘画美学数据集(APDD);提出了一种绘画图像评估网络(AANSPS),该模型在大多数指标上取得了令人满意的结果,为本方法的有效性进行了验证。
美学评分标准
根据不同的绘画门类(油画、素描、国画)、艺术风格(象征主义、古典主义、浪漫主义、工笔、写意),题材(风景、静物、肖像、花卉和鸟类、山脉和水),我们将APDD数据集分为 24 个不同的艺术类别。

对于每张图进行审美属性的打分,审美属性的来源考虑了如下几个方面:
-
艺术创作者的一般思维过程。
-
艺术观察者如何进行分层观察。
-
评价者的评分方法。
最终定义了艺术图像的10个审美属性。注:并非所有的艺术类别都包含了本文提出的10个审美属性。

APDD数据集
绘画美学数据集(APDD)概况:
-
得到了全球28位专业艺术家和数十名美术生的积极参与。
-
数据集包括24个不同的艺术类别和10个不同的审美属性。
-
收集了4985幅画作,其中注释计数超过31100个条目。
数据集的收集:
-
精心挑选了几个专业的艺术网站和机构作为数据来源,以确保艺术图像的广度和多样性。
-
从艺术学生的作业中挑选了一些审美质量较低的艺术作品。艺术家作品与学生作品比例为3:1。
-
收集了4985幅画作,涵盖了24个类别,每个类别至少包含200幅图片。作品包括著名艺术家作品和学生作品。该图像数据集的结构旨在为后续的评分注释提供足够的代表性和多样性。
图像标注:
-
评分团队根据所选的基准图像,开发了一个一致的、客观的评分系统,确保后续的评分工作能够遵循统一的标准。
-
第一阶段由专家评分,耗时15天,为评分活动提供了坚实的理论基础。
-
第二阶段由24名来自油画、素描和中国画专业的高学历学生评分。第二阶段进展得更快,总共在7天内完成。
-
将任务分配给对应的评分者,指定艺术类别和所涉及的图像数量,确保APDD数据集中的每个图像至少由6个个体进行评估。
-
在对所有评分进行综合评估后,我们根据所有注释者的评估计算平均分,最终收集每种属性的总分和单个属性分。
APDD数据集包含10个美学属性,分别为:主题逻辑、创造力、布局与构图、空间与视角、秩序感、光与影、色彩、细节和质感、整体和情绪。部分数据,如图所示:

AANSPS模型
本项目提出了一种绘画图像评估网络AANSPS,并在APDD数据集上训练。

该模型先通过EfficientNet-B4网络提取图像表征。然后将图像特征输入Efficient Channel Attention (ECA) 模块,使用global average pooling (GAP)进行处理。之后进入回归网络,该部分由一个GAP层和三个线性层组成。最后输出美学得分。loss函数使用mse函数。

训练集和验证集的比例为9:1。在训练过程中,将预训练模型加载到总美学评分分支中,并基于APDD的训练集对该分支网络进行训练,得到第一个评分模型。然后,使用第一个评分模型作为新的预训练模型,并分别训练每个属性的评分分支网络。在训练其他属性分支网络时,需要冻结其他评分分支网络的参数。在每个分支网络经过训练后,它将包括之前训练过的属性分支网络。如果连续两轮的loss没有减少,则学习率乘以0.5。一旦所有的属性分支网络都完成了训练,我们就得到了最终的评分模型。
模型评估
本文利用均方误差(MSE)、平均绝对误差(MAE)和斯皮尔曼的秩阶相关系数(SROCC)来评价性能。

本项目的一些局限性:
-
需要进一步扩大审美分类和属性,更全面地评价审美质量。
-
增加APDD数据集中的图像数量。
-
以更详细的语言为美学属性提供注释,增加数据集的易用性。
HPS v2
主要内容
最近的文生图模型可以从文本输入中生成高保真的图像,但这些生成的图像的质量不能通过现有的评价指标进行准确的评估。Inception Score (IS) and Fréchet Inception Distance (FID)被广泛用于生图模型的评估,但是这两个指标并不能很好的反映生成图片是否符合人类偏好。人类的偏好评估是文生图模型中一个重要但有待推进的研究领域。
本项目构建了一个用人类偏好进行注释的大规模数据集,即Human Preference Dataset v2(HPD v2)。同时还在HPD v2上训练了一个基于偏好预测模型的benchmark,Human Preference Score v2(HPS v2),以测量生成式算法的发展。HPS v2在各种图像分布上比之前的指标评估性能更好,并可用于文生图模型的改进,使其成为一个更好的评估这些模型的方法。
HPD v2数据集
Human Preference Dataset v2(HPD v2)概况:
-
雇用了50个标注人员和7个质量控制检查人员,对数据进行注释。
-
构建了一个大规模的、注释清晰的数据集,其中包含了人类对从文本提示中生成的图像的偏好。
-
HPD v2包含了43.4w个图像对、79.8w个人类偏好选择,使其成为同类数据中最大的数据集。
-
每对图像包含由不同的模型使用相同的prompt生成的两个图像,并对应一组人类偏好选择。
-
用于生成图片的prompt,按照风格分类为:动画、概念艺术、绘画和照片。
该数据集解决了在以前的数据集中出现的偏差问题:
-
数据集多样性:HPD v2包含了从9个最近的模型中生成的图像,以及来自COCO数据集的真实图像。
-
清洗prompt:用户编写的prompt,通常遵循一个特定的描述结构加上几个风格词。其中风格词经常包含自相矛盾的内容,使用户很难理解,风格词也有高度的偏见。为了解决这种偏差,本文使用ChatGPT来去除风格词,并将prompt重写成一个更清晰的句子。
HPD v2的prompt来自于COCO Captions、LAION、DiffusionDB三个数据集,其中DiffusionDB的prompt被chatgpt进行了清洗。效果如下:

图像来源:
-
使用不同的模型和相同的prompt来生成图像。
-
除了生成的图像,还添加了COCO数据集中对应的真实图像。
-
训练集包含来自4个模型的生成图片以及COCO数据集的真实图像。
-
测试集包含9个模型的生成图像以及COCO数据集的真实图像。这5个另加的模型使我们能够验证评估模型的泛化能力。
HPD v2的处理流程如下。首先收集HPD v2,然后在其上训练一个偏好预测模型,即Human Preference Score v2(HPS v2):

HPS v2 数据集
CLIP是一个将图像和文本对齐到相同的embedding空间的模型。它有一个图像编码器来将一个图像编码成一个视觉特征,和一个文本编码器来将一个caption编码成一个文本特征。视觉特征和文本特征之间的余弦相似度反映了输入图像和caption之间的对齐程度。然而,原生的CLIP并不能很好地反映人类偏好。
通过使用HPD v2微调CLIP,获得了Human Preference Score v2(HPS v2),这是一种可以更准确地预测人类对生成图像的偏好的评分模型。HPS v2在各种图像分布上比以前的指标评估性能更好,并可用于文生图模型的改进,使其成为一个更好的评估这些模型的方法。
训练集的每一组信息,包含prompt、一对图像,以及人类对于两张图的偏好(一张为0,一张为1)。CLIP模型主要来计算图像和prmpt之间的相似度:

HPS v2计算的偏好得分,分母为分别选择其中一张图对应的相似度得分,分子为其中一张图像对应的相似度得分。这个计算的目的是对于结果做一个归一化:

loss函数使用KL散度,计算预测打标的得分,与真实打标的得分,二者之间的差异:

模型训练:使用OpenCLIP训练的ViT-H/14作为预训练模型,对其进行微调。由于在有限的数据集上微调预训练模型,所以常规操作是freeze前面几层网络或者减少其学习率。本项目训练了CLIP的图像编码器的后20层,以及文本编码器的后11层。
模型评估
分别在 ImageReward、HPD v2两个数据集上进行精度评估,HPS v2实现SOTA:

评估方法:计算生成图像x和prompt的相似度:

本项目的一些局限性:
-
需要包含更多的主题。
-
依然可能有的标注偏差:chatgpt可能带来偏差;人工标注带来偏差。
-
未考虑图像分辨率的影响,因为图像分辨率很影响人类的偏好。
Pick-a-Pic
主要内容
对于文生图模型,反映人类偏好的大型数据集,很少有公开的。为了解决这个问题,本项目创建了一个web应用程序,允许文生图模型的用户生成图像并指定他们的偏好。使用这个web应用程序,构建了一个大型的、开放的文生图数据集,并且标注有用户偏好。部分数据集如下:

利用这个数据集,可以训练一个基于clip的评分函数,即PickScore,它在预测人类偏好的任务上展示了很好的性能。PickScore可以对于多张生成图像进行偏好排序,以此比较不同文生图模型的效果、以及相同模型在不同参数下的效果。
Pick-a-Pic数据集
Pick-a-Pic数据集概况:
-
包含超过50w组信息和3.5w个不同的prompt。
-
每组信息包含一个prompt、两张图、以及偏好标签。
-
偏好标签有三种情况:喜欢第一张图,喜欢第二张图,两幅图都差不多。
-
对一个图片的选择是由文生图任务的爱好者参与的,而不是完全无生图模型使用经验的人员。
如何通过web应用程序收集数据:
-
用户首先写一个prompt,然后收到两张图片。
-
用户做出偏好判断,选择其中一张偏好的图片。
-
之后会呈现一个新的图像的图像来替代被拒绝的图像,用户会在这张新图和刚才喜欢的图像里做偏好选择。
-
该流程会一直重复,直到用户改变prompt。
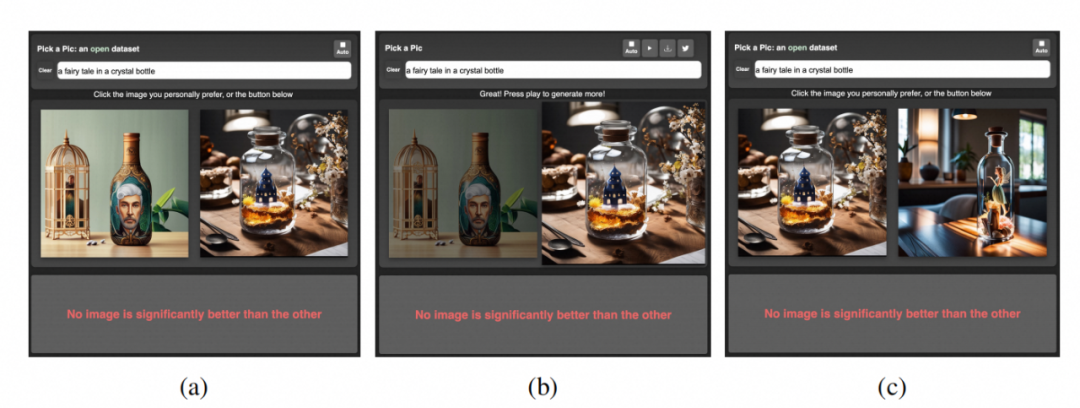
数据集中的图像是通过采用多个模型生成的,即Stable Diffusion 2.1、Dreamlike Photoreal2.0, 以及使用不同CFG值的Stable Diffusion XL模型。同时,作者将减少数据集中包含的NSFW示例的数量,并将定期上传最新版本的数据集。在处理收集到的交互时,作者过滤了NSFW短语,并且禁止一些非法用户。每一次收集,将数据集划分为训练、验证集和测试集:
-
采样1000个prompt,确保每个prompt都是唯一的。
-
将这些prompt随机分成大小相同的两组,来创建验证集和测试集。
-
每个prompt采样一组信息。
-
确保训练集和这两个子集之间没有重复的prompt。
PickScore模型
为了训练评分函数,本项目使用人类偏好数据和类似于InstructGPT的reward模型,来微调CLIP-H。PickScore在预测用户偏好的任务中取得了SOTA表现,PickScore准确率为70.5%,人类志愿者准确率为68.0%,而原生CLIP-H为60.8%。人类偏好与PickScore有很强的相关性(0.917),而与FID指标则呈负相关(-0.900)。
PickScore遵循CLIP的架构:给定一个prompt x和一个图像y,评分函数s通过使用两个编码器计算文本和图像的相似度。

计算对于两张图的偏好得分:分别计算两张图与prompt的相似度,计算函数的分母为两张图与prompt的相似度,分子为其中一张图与prompt的相似度,这个函数的目的是做归一化计算。

计算loss函数:拿到模型的偏好得分后,计算与人工打分的KL散度,表示预测结果与真实结果的差距。训练过程中,通过调整模型参数来最小化KL散度。

由于许多图像对来自于相同的prompt,通过对于这些图像对进行加权平均,来减轻过拟合的风险。具体来说,每个图像的权重,与它在数据集中的出现频率成反比。
模型评估
对于模型推理,如果两张图的偏好得分的差值的绝对值,小于一个超参t,即

则认为这两张图偏好一致。该超参,对于不同模型效果不一样,作者采取了一个最合适的值,来用于不同模型的评估。
使用Spearman方法来计算预测得分与人类预测结果的相似度:

相关效果,对于每两列,左侧为CLIP-H偏好的图像,右侧为PickScore偏好的图像,绿色框选中的图像为人类偏好的图像,可以看到,PickScore偏好和人类偏好更加接近,PickScore通常选择更美观和与prompt更一致的图像。

偏好打分模型:可以对于一组生成图像,进行打分排序,并选择得分最高的那一张。PickScore优于其他评估方法。

本项目的一些局限性:
-
一些图像和提示可能包含NSFW内容,这可能会使数据产生偏差。
-
用户的偏好可能可能反映在所收集的数据中。
总结与讨论
在AIGC生图过程中,进行图像质量的自动化评估,能快速进行打分、节省人工成本,更准确的进行模型效果比较,以促进模型迭代。对于特定场景的自动化评估,则需要建立对应的评估体系,包括评分准则、特定数据集、打分模型。我们团队正在进行家装行业AIGC的相关研发,以提高家装AI模型的效果。我们希望与对此方向感兴趣的同学一起探讨和交流。
参考文献
-
《Paintings and Drawings Aesthetics Assessment with Rich Attributes for Various Artistic Categories》
https://arxiv.org/abs/2405.02982
-
《Human Preference Score v2: A Solid Benchmark for Evaluating Human Preferences of Text-to-Image Synthesis》
https://arxiv.org/abs/2306.09341
-
《Pick-a-Pic: An Open Dataset of User Preferences for Text-to-Image Generation》
https://arxiv.org/abs/2305.01569


















 1011
1011

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









