







 超级会员免费看
超级会员免费看
大模型系列——基于 StarRocks 的向量检索探索
AI 和大模型无疑是当前的热门话题,作为从事数据工作的我们,也希望能够紧跟这一趋势,探索如何与 AI 实现更紧密的结合。这正是我们最初的诉求。随着大模型的兴起,推动了公司在这一背景下对向量检索场景的深入探索,也为我们进一步拓展在 StarRocks 上的应用提供了新的机遇。
向量检索技术浅析
什么是向量检索
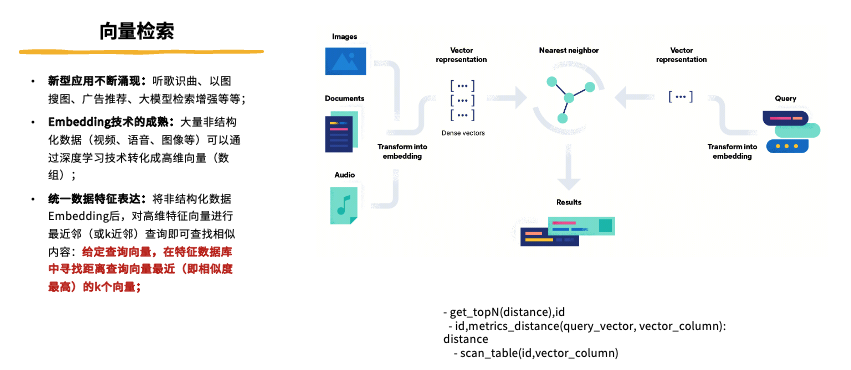
什么是向量检索呢?简单来说,向量检索是**通过给定一个查询向量,在特征数据库中找到与之距离最近的 k 个向量。**举个例子,如果我们把今天会场的所有人作为特征向量,那么向量检索的任务就是找到与我最相似的 10 个人。用通俗的语言来说,它其实就是一个 Top N 查询。虽然本质上,向量检索就是一个 Top N 查询,但由于深度学习中几乎所有内容都用向量表示,所以我们将其称为“向量检索”。
近似最近邻查询
之所以在向量检索中进行 Top N 查询显得如此复杂,主要原因在于向量本身的维度通常非常高。这导致了计算的复杂性,每次计算都需要

 订阅专栏 解锁全文
订阅专栏 解锁全文


















 19
19

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









