






 本文介绍了如何使用Python的jieba库进行中文分词,生成词云图,并针对词云字体路径的调整提供详细步骤,以STCAIYUN.TTF和STKAITI.TTF为例。
本文介绍了如何使用Python的jieba库进行中文分词,生成词云图,并针对词云字体路径的调整提供详细步骤,以STCAIYUN.TTF和STKAITI.TTF为例。
目录
Step1:选中我们需要的字体(字体默认在C盘->Windows->Fonts文件夹里面),右键打开,选择属性:
Step2:字体的路径有两部分构成:第一部分是"位置",第二部分是"字体文件"
一.源代码:
import jieba
from wordcloud import WordCloud, STOPWORDS, ImageColorGenerator
import numpy as np
from PIL import Image
excludes = {"什么", "一个", "我们", "那里", "你们", "如今",
"说道", "知道", "老太太", "起来", "姑娘", "这里",
"出来", "他们", "众人", "自己", "一面", "太太",
"只见", "怎么", "奶奶", "两个", "没有", "不是",
"不知", "这个", "听见", "咱们", "就是", "进来", "东西"}
f = open(r"红楼梦.txt", "r", encoding='utf-8')
txt = f.read()
f.close()
words = jieba.lcut(txt) # 中文分词函教,用于精确模式,即将字符串分割成等量的中文词组,返回结果是列表类型
counts = {}
for word in words:
if len(word) == 1: # 排除单个字符的分词结果
continue
else:
counts[word] = counts.get(word, 0) + 1 # get方法,键存在则返回相应信,否则返回
for word in excludes:
del (counts[word]) # 如果含有excludes里的单词,删掉
items = list(counts.items()) # items返回所有的词频统计结果
items.sort(key=lambda x: x[1], reverse=True) # 按照词频的多少进行排序
for i in range(11):
if (i == 7) or (i == 8) or (i == 9):
continue
else:
word, count = items[i]
print(f"{word}:{count}")
# 生成词云图
newtxt = ''.join(words)
background_image = np.array(Image.open('BackGround.png')) # 增加背景图片
wordcloud = WordCloud(background_color='white',
width=800,
height=800,
font_path=r'C:\windows\Fonts\STCAIYUN.TTF',# 修改词云字体
max_words=300,
max_font_size=100,
stopwords=excludes,
mask=background_image
).generate(newtxt)
background_image = np.array(Image.open('BackGround.png'))
wordcloud = WordCloud(background_color='white',
width=800,
height=800,
font_path=r'C:\windows\Fonts\STKAITI.TTF',
max_words=300,
max_font_size=100,
stopwords=excludes,
mask=background_image, # 设置背景图片
).generate(newtxt)
image_colors = ImageColorGenerator(background_image)# 设置字体颜色,让其根据图片颜色的改变而改变
wordcloud.recolor(color_func=image_colors)
# 设置背景图片
wordcloud.to_file(r'红楼梦.png')二.运行结果图

三. 关于词云字体的调整
在词云图的构建时,会找不到字体的路径的问题,如下所示: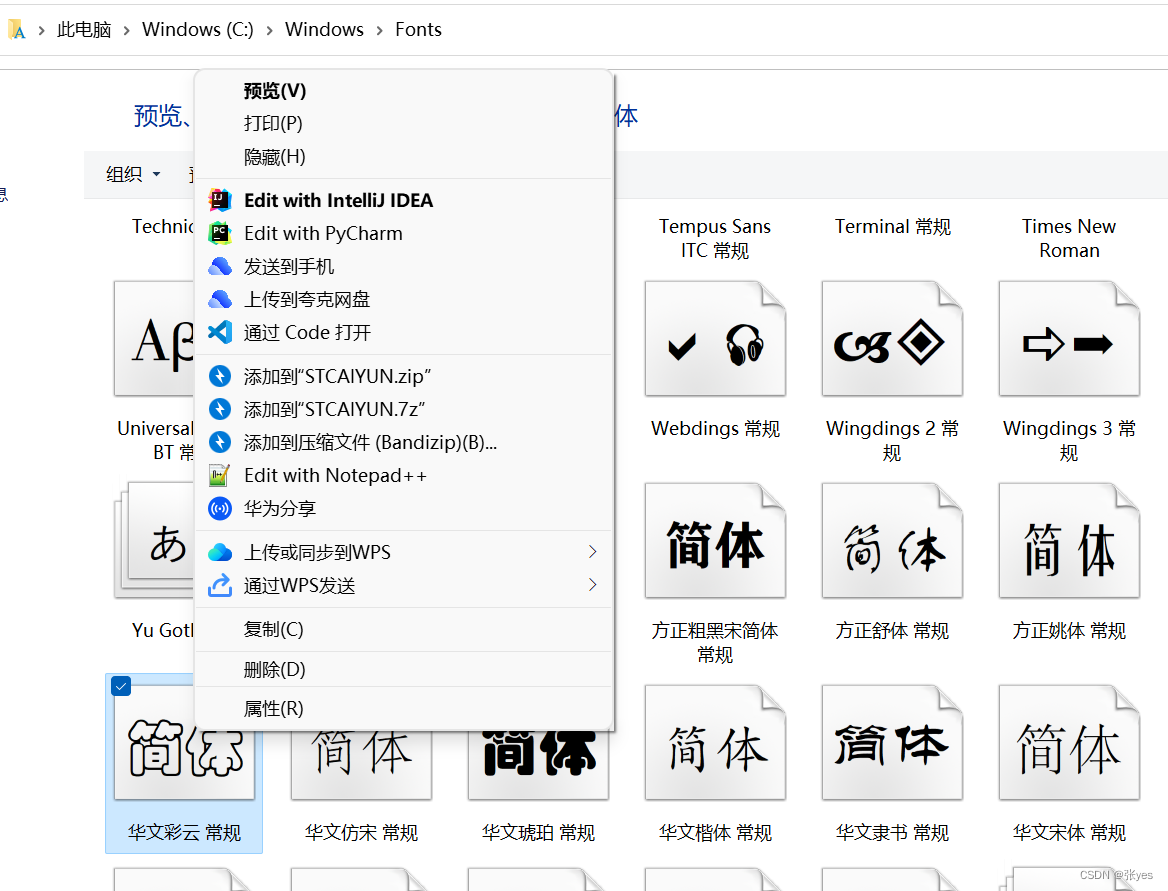
可以发现,这里没有"复制文件地址"的选项,这是就需要我们手动去拼接,具体步骤如下:
Step1:选中我们需要的字体(字体默认在C盘->Windows->Fonts文件夹里面),右键打开,选择属性:
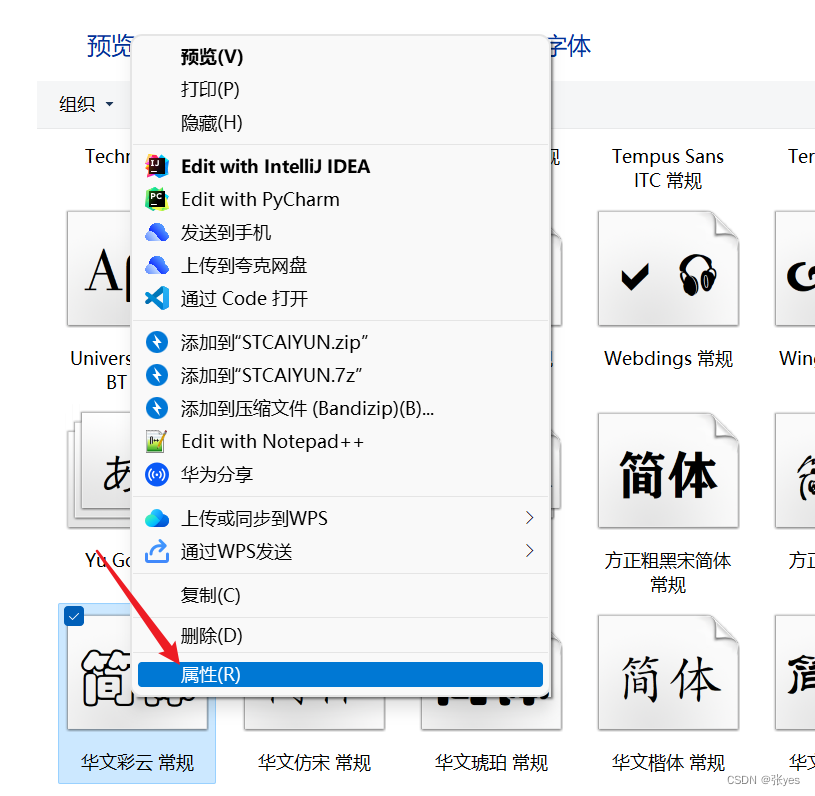
Step2:字体的路径有两部分构成:第一部分是"位置",第二部分是"字体文件"
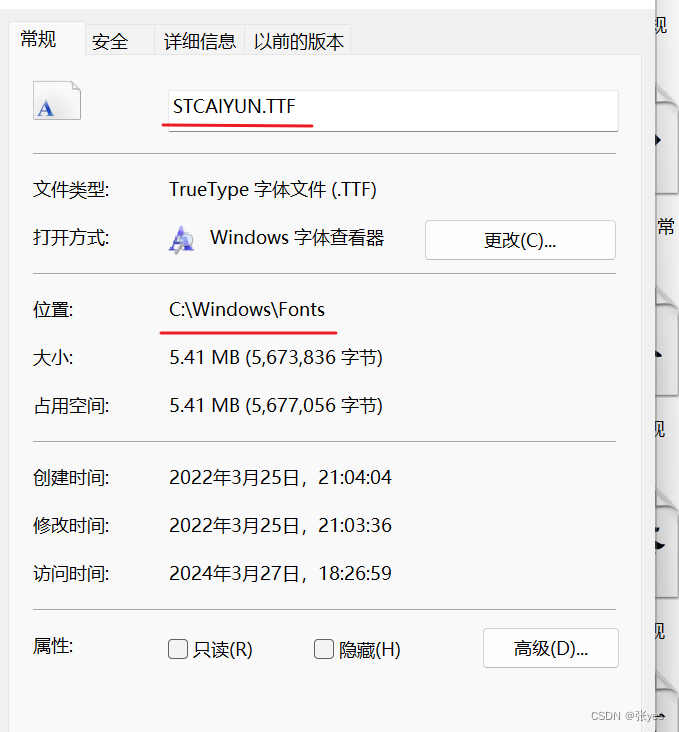
如 STCAIYUN.TTF 字体,路径就可以拼接为:"C:/Windows/Fonts/STCAIYUN.TTF"
基于以上的操作,我们的字体路径就设置完毕.是不是还挺简单的?















 772
772











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









