




在使用transformer构建模型的过程当中,不可避免的需要弄清楚每层的参数shape,以及输入输出的参数shape,以及参数的含义。本文将详细讲解使用transformer构建模型的过程所有层的输出参数及其参数的含义。
一)inputs 和 attention_mask
inputs 和 attention_mask的形状一般是 torch.size(batch_size, seq_length)。如下图所示(是实际构建模型过程中输出的 inputs 和 attention_mask)。
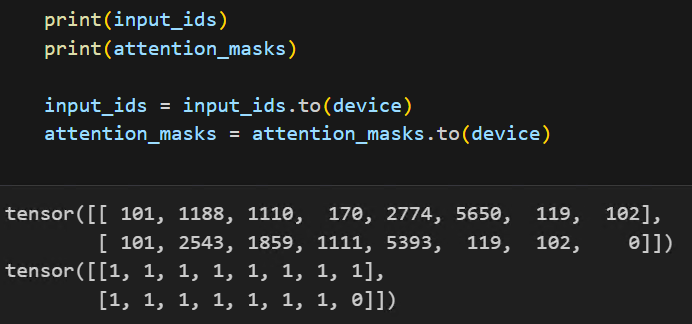
可以看见其实际的待输入数据为两条,每条长度是10个token。
# 示例:
# 两条数据,数据长度10
input_ids = ([[101, 1188, 1100, 170, 345, 222, 1234, 102],
[101, 1160, 100, 1170, 335, 6772, 1002, 0]])
# 数据的有效长度
attention_masks = ([[1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 0]])
二)Embedding 层
Embedding 就是将输入的数据进行维度扩展( Embedding 实际意义是贴语义标签),Embedding后的数据形状是 torch.size(batch_size, seq_length)。
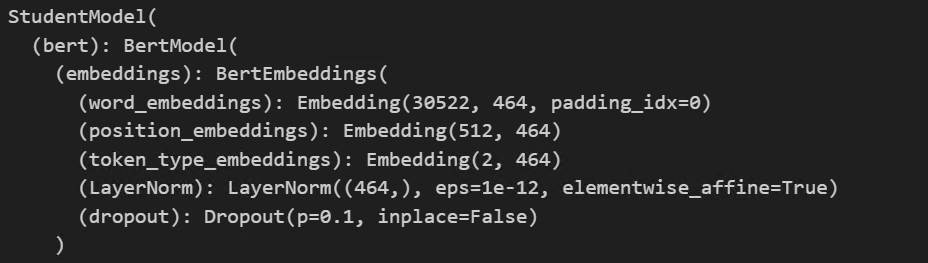
如上图所示是实际构建模型的结构,其嵌入层维度是464,词汇表大小是30522。
# 示例:
# 输入数据经过embedding后,数据中的每个token被嵌入为464维度
embedding_output = ([
([
[
[-9.9599e-01, 3.0937e-01, -9.3208e-02, ..., 1.3036e+00, 6.0473e-01], # 101
[-1.4179e-01, 6.1687e-01, -1.9269e-02, ..., 1.1588e+00, 1.9160e-01], # 1188
[-4.1764e-02, 1.6819e+00, -9.0685e-01, ..., -5.5879e-02, -7.2969e-01], # 1100
[ 2.7978e-02, -1.1223e+00, -2.6143e-01, ..., 1.1060e+00, 2.8671e-01], # 170
[-6.5458e-01, 1.3831e+00, -5.5879e-01, ..., -7.1652e-02, -1.0914e-04], # 345
[-1.7898e-01, -9.1221e-01, -2.8951e-01, ..., -8.2054e-01, -2.9035e+00], # 222
[-9.5735e-01, 5.0956e-01, -4.6034e-01, ..., 1.5868e+00, 9.3698e-01], # 1234
[-2.2354e-01, -1.5808e-01, -1.4068e+00, ..., -4.7152e-01, 7.5580e-01] # 102
],
[
[-9.9599e-01, 3.0937e-01, -9.3208e-02, ..., 1.3036e+00, 6.0473e-01],
[-1.4179e-01, 6.1687e-01, -1.9269e-02, ..., 1.1588e+00, 1.9160e-01],
[-4.1764e-02, 1.6819e+00, -9.0685e-01, ..., -5.5879e-02, -7.2969e-01],
[ 2.7978e-02, -1.1223e+00, -2.6143e-01, ..., 1.1060e+00, 2.8671e-01],
[-6.5458e-01, 1.3831e+00, -5.5879e-01, ..., -7.1652e-02, -1.0914e-04],
[-1.7898e-01, -9.1221e-01, -2.8951e-01, ..., -8.2054e-01, -2.9035e+00],
[-9.5735e-01, 5.0956e-01, -4.6034e-01, ..., 1.5868e+00, 9.3698e-01],
[-2.2354e-01, -1.5808e-01, -1.4068e+00, ..., -4.7152e-01, 7.5580e-01]
]
])
经过 Embedding 后,其每个 token 都是使用 464 维度的一维向量来表示。当然了这里举的例子是用 464 维来嵌入,也可以选择其他的维度来嵌入。其数据形状是 torch.size(2, 10, 464)。
三)transformer 层
输入数据经过 Embedding 后,就可以将数据输入 transformer 层进行信息捕捉。
# 示例:
# embedding后的数据经过transformer后,数据中的维度不变
embedding_output =
([
[
[-1.9599e-01, 4.0967e-01, -9.3648e-02, ..., 1.5036e+00, 6.0693e-01], # 101
[-2.4179e-01, 8.6789e-01, -1.6709e-02, ..., 1.9846e+00, 8.7160e-01], # 1188
[-3.1764e-02, 7.6859e+00, -9.7844e-01, ..., -5.5879e-02, -7.2969e-01], # 1100
[ 4.7978e-02, -5.1223e+00, -2.6143e-01, ..., 1.1060e+00, 2.8671e-01], # 170
[-6.5458e-01, 4.3851e+00, -5.5479e-01, ..., -7.1652e-02, -1.0914e-04], # 345
[-1.7898e-01, -8.1241e-01, -2.8941e-01, ..., -8.2054e-01, -2.9435e+00], # 222
[-9.5735e-01, 5.0956e-01, -7.8934e-01, ..., 1.5868e+00, 9.3698e-01], # 1234
[-2.2354e-01, -1.5808e-01, -4.4068e+00, ..., -4.7152e-01, 7.5580e-01] # 102
],
[
[-6.9156e-01, 3.0931e-01, -7.3208e-02, ..., 4.3836e+00, 6.0814e-01],
[-1.3512e-01, 6.1681e-01, -4.9269e-02, ..., 1.8548e+00, 1.9160e-01],
[-6.1109e-02, 1.6819e+00, -7.4485e-01, ..., -5.5879e-02, -7.1969e-01],
[ 7.7918e-02, -1.1123e+00, -3.6543e-01, ..., 4.1048e+00, 2.8611e-01],
[-2.5418e-01, 1.3131e+00, -5.5447e-01, ..., -7.1642e-02, -1.1914e-04],
[-1.6718e-01, -9.1221e-01, -2.8951e-01, ..., -8.2054e-01, -2.1035e+00],
[-5.8735e-01, 5.0156e-01, -4.6434e-01, ..., 4.5864e+00, 9.3648e-01],
[-6.8154e-01, -1.5819e-01, -1.4878e+00, ..., -4.7152e-01, 7.1480e-01]
]
])
transformer 层对于输入的数据进行信息捕捉后,其输出会保持输入输出数据维度不变、但实际输出数据已经被带上了各种信息。
深入看看 Embedding 后的数据是怎么进入 transformer 层并进行数学运算的。其中embedding后的数据形状是 torch.size(2, 10, 464) ,其中表示(batch_size, sequence_length, 词嵌入维度)。
所以对于本次输入来说,batch_size是2,一次输入是2条数据,但是这两条数据的处理是并行的进行的,所以我们只看其中一个数据的处理过程,即(10,464)。
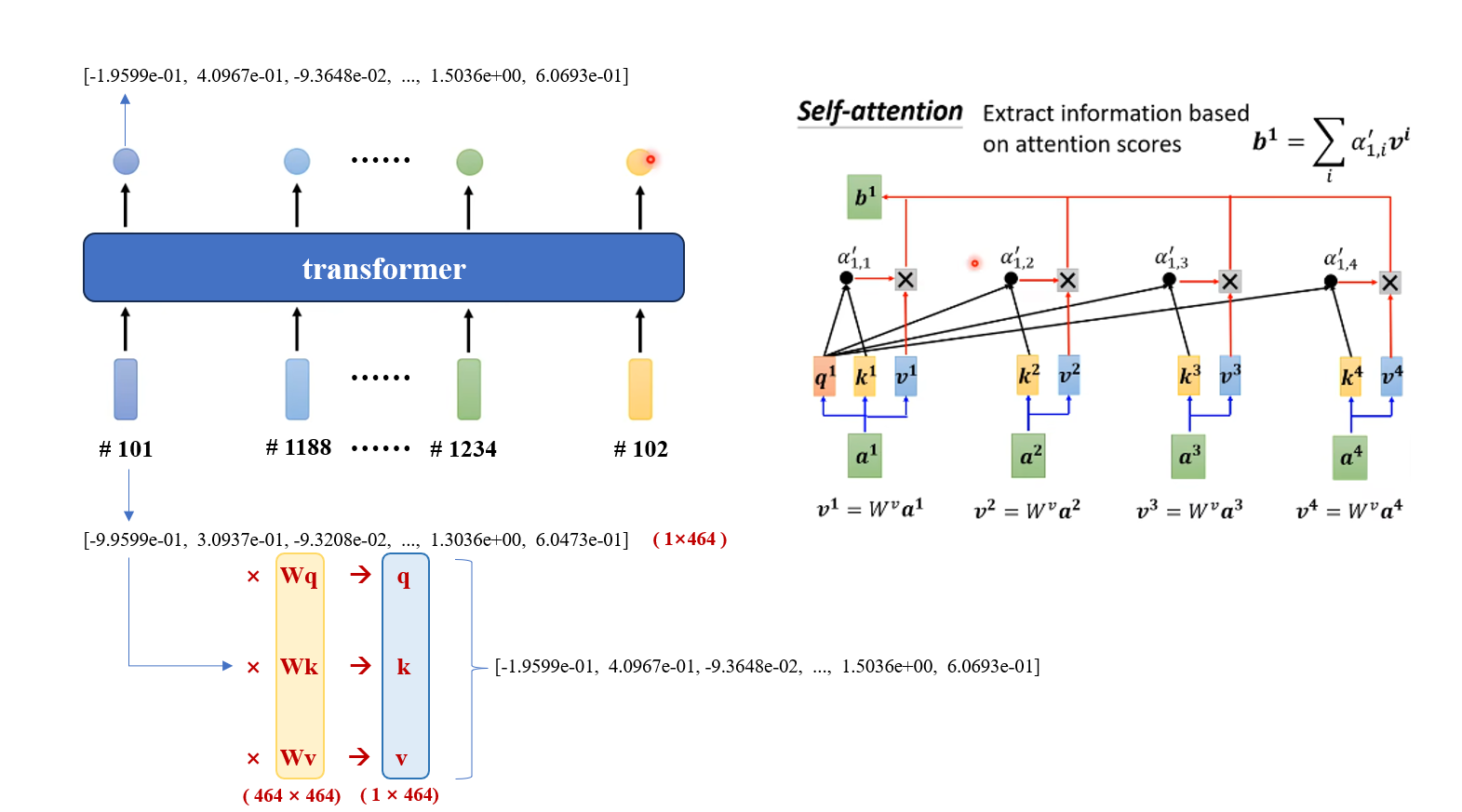
一句话(10,464),每个token对应输入,每个token的维度是464;输入后,会进行自注意力的计算,得到最后融合了其他信息的数据,最后得到维度不变的输出。(这里就不详细讲解qkv的计算了)
四)全连接层
由于本次实验使用的模型是基于bert的,通过bert构建自己的小型bert模型进行语言5分类。在分类任务上,数据被 transformer 加工后会最后被送入全连接层进行分类,而在bert中,只取输出的第一个token送入全连接层进行分类,因为第一个token包含了全局信息。第一个token的形状就是(1,464)。
假设全连接层是 nn.Linear(464, 5),就是将其变为一个五维度的向量,每个维度代表在其类别上的概率。
# 全连接层
# 全连接层的输入
[-1.9599e-01, 4.0967e-01, -9.3648e-02, ..., 1.5036e+00, 6.0693e-01] #(1, 464)
# 全连接层的输出
[-3.4599e-01, 3.0632e-01, -1.3428e-02, 2.5055e+00, 1.0567e-01] #(1, 5)

















 728
728

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









