







先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前阿里P7
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新Web前端全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。




既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上前端开发知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
如果你需要这些资料,可以添加V获取:vip1024c (备注前端)

正文
安装完毕效果

2、配置中文插件操作步骤
按照下图操作,其中步骤3是在没有看到zh_CN的情况下刷新一下。

3、Reload UI后效果
刷新后能看到中文的显示状态。刚才我们在扩展中安装了中文的插件,在设置中配置了中文插件。

页面说明,这个图给的描述很详细。

数据示例:
| 参数名 | 描述 | 值 |
|---|---|---|
| 提示词 | 主要描述图像,包括内容风格等信息,原始的webui会对这个地方有字数的限制,可以安装一些插件突破字数的限制 | a pretty cat,cyberpunk art,kerem beyit,very cute robot zen,Playful,Independent,beeple |
| 反向提示词 | 为了提供给模型,我们不需要的风格 | (deformed,distorted,disfigured:1.0),poorly drawn,bad anatomy,wrong anatomy,extra limb,missing limb,floating limbs,(mutated hands and fingers:1.5),disconnected limbs,mutation,mutated,ugly,disgusting,blurry,amputation,flowers,human,man,woman |
| 提示词相关性(CFG scale) | 分类器自由引导尺度——图像与提示符的一致程度——越低的值产生的结果越有创意,数值越大成图越贴近描述文本。一般设置为7 | 7 |
| 采样方法(Sampling method) | 采样模式,即扩散算法的去噪声采样模式会影响其效果,不同的采样模式的结果会有很大差异,一般是默认选择euler,具体效果我也在逐步尝试中。 | Euler a |
| 采样迭代步数(Sampling steps) | 在使用扩散模型生成图片时所进行的迭代步骤。每经过一次迭代,AI就有更多的机会去比对prompt和当前结果,并作出相应的调整。需要注意的是,更高的迭代步数会消耗更多的计算时间和成本,但并不意味着一定会得到更好的结果。然而,如果迭代步数过少,一般不少于50,则图像质量肯定会下降 | 80 |
| 随机种子(Seed) | 随机数种子,生成每张图片时的随机种子,这个种子是用来作为确定扩散初始状态的基础。不懂的话,用随机的即可 | 127361827368 |
随机种子也可以自己添加,下面的实验我用-1和
实验效果:

随机种子实验效果

**五、**stable Diffusion——AI绘图技巧(特色功能)
在stable Diffusion中会有正向提示词&反向提示词,这个是很独特的一个功能,这里深入的测试一下。
提示词(prompt)由多个词缀构成,分为正向提示词(positive prompt)和反向提示词(negative prompt),用来告诉AI哪些需要,哪些不需要。
注:词缀的权重默认值都是1,从左到右依次减弱,权重会影响画面生成结果。 比如景色Tag在前,人物就会小,相反的人物会变大或半身。 选择正确的顺序、语法来使用提示词,将更好、更快、更有效率地展现所想所愿的画面。
逗号(,):分割词缀,有一定权重排序功能,逗号前权重高,逗号后权重低,因而建议排序:
综述(图像质量+画风+镜头效果+光照效果+主题+构图)
主体(人物&对象+姿势+服装+道具)
细节(场景+环境+饰品+特征)
权重示例:
冒号(😃:自定义权重数值 格式:左圆括号 + 词缀 + 冒号 + 数字 + 右圆括号
单人女孩词缀,权重为0.75 (1girl:0.75)()仅圆括号:增加权重0.1 大部分情况用圆括号即可。
权重乘以1.1 (1girl){}花括号:增加权重0.05
权重乘以1.05 {1girl}[] 方括号:减少权重0.1,也有说是减弱0.05的 方括号中无法自定义权重数值,自定义权重只能使用(x:0.5)形式。
权重除以1.1 [1girl](())、{{}}、[[]]复用括号:叠加权重
权重乘以1.1*1.1,即权重为1.21 ((1girl))
提示词:
hanfu,tang style outfits,pink upper shan, blue chest po skirt, purple with white waistband, light green pibo, 1girl, blue eyes, gray hair, dusk, over the sea, HDR,UHD,8K, best quality, masterpiece, Highly detailed, Studio lighting, ultra-fine painting, sharp focus, physically-based rendering, extreme detail description, Professional, Vivid Colors, close-up view
反向(负面)提示词:
nsfw,logo,text,badhandv4,EasyNegative,ng_deepnegative_v1_75t,rev2-badprompt,verybadimagenegative_v1.3,negative_hand-neg,mutated hands and fingers,poorly drawn face,extra limb,missing limb,disconnected limbs,malformed hands,ugly

可以直接生成,效果还是不错的,就是时间较长,这里建议使用高一些配置的服务,能快一些。
提示词我们还可以加以修饰一下效果会更好。
1girl, aqua eyes, lipstick, brown hair, asymmetrical bangs, light smile, in summer, bamboo forest, flower sea, HDR,UHD,8K, best quality, masterpiece, Highly detailed, ultra-fine painting, sharp focus, physically-based rendering, extreme detail description, Professional, Vivid Colors, close-up view, looking at viewer, hanfu, tang style outfits,<lora:hanfuTang_v32:0.5>, red upper shan, blue chest po skirt, orange waistband, light green pibo
我生成了几张图片,这是使用的词语
a young female holding a sign that says “I Love CSDN”, highlights in hair, sitting outside restaurant, brown eyes, wearing a dress, side light,[the: (painting cartoon:1.9): 0.3]
反向词语
painting, cartoon
我生成了6张,可以看看。






六、jupyter_lab操作步骤
1、进入jupyter_lab操作页面

操作页面效果

2、面板功能介绍

3、启动服务
命令如下,直接复制并【ctrl+v】即可
cd /root/stable-diffusion-webui
python launch.py --nowebui --xformers --opt-split-attention --listen --port 7862
命令参数描述:
| 命令 | 描述 |
|---|---|
| –nowebui | 以 API 模式启动 |
| –xformers | 使用xformers库。极大地改善了内存消耗和速度。 |
| –opt-split-attention | Cross attention layer optimization 优化显着减少了内存使用,几乎没有成本(一些报告改进了性能)。黑魔法。默认情况下torch.cuda,包括 NVidia 和 AMD 卡。 |
| –listen | 默认启动绑定的 ip 是 127.0.0.1,只能是你自己电脑可以访问 webui,如果你想让同个局域网的人都可以访问的话,可以配置该参数(会自动绑定 0.0.0.0 ip)。 |
| –port | 默认端口是 7860,如果想换个端口,可以配置该参数,例如:–port 7862 |
| –gradio-auth username:password | 如果你希望给 webui 设置登录密码,可以配置该参数,例如:–gradio-auth GitLqr:123456。 |
本地启动效果(不支持公网访问,可以看到是127.0.0.1:7862)

启动效果(支持公网访问,可以看到是0.0.0.0:7862)

4、添加7862端口规则
操作1、进入模型操作面板

添加7862端口号码

添加端口操作

3、访问swagger接口
访问地址:ip:7862端口

七、python接口解析生成AI图片
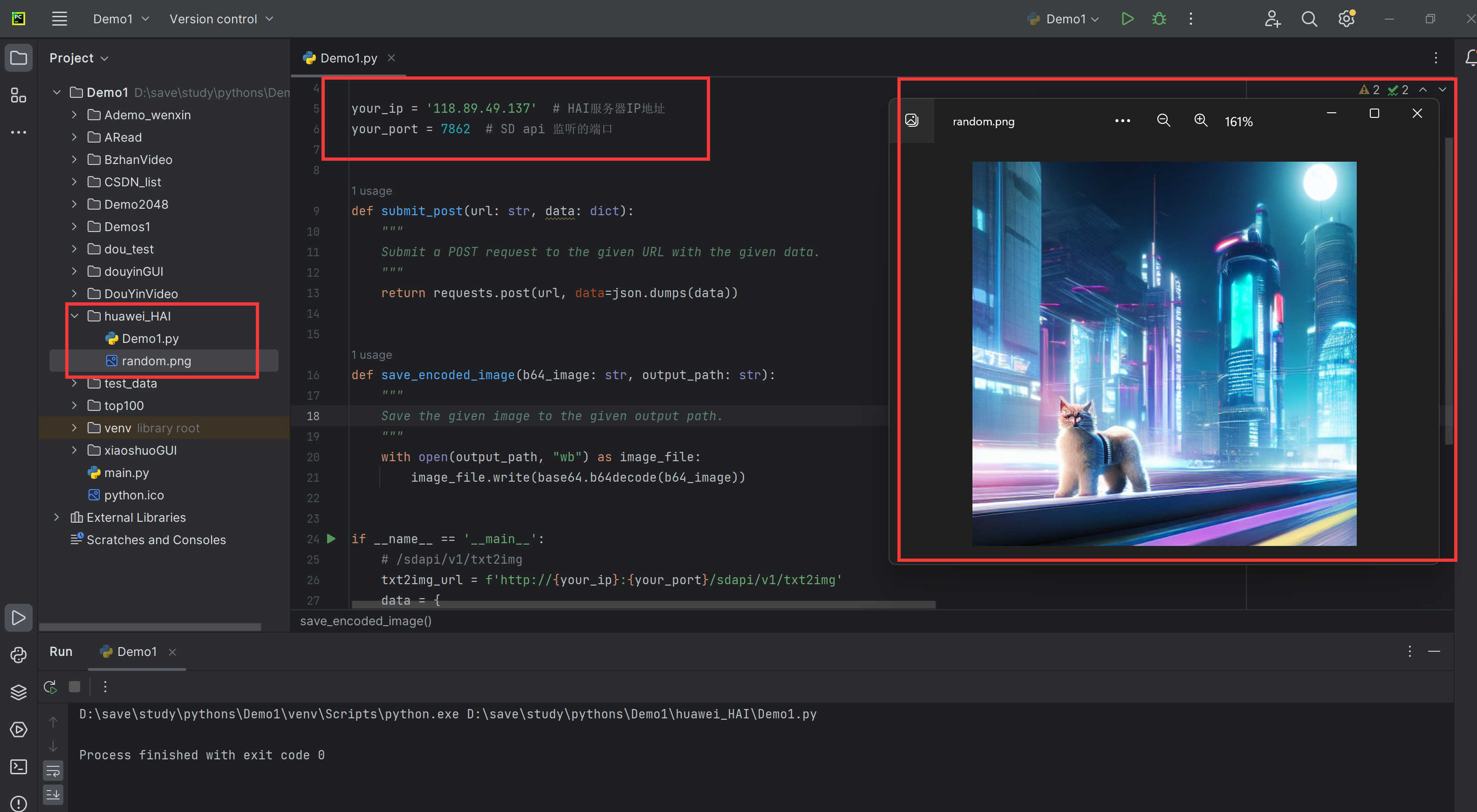
1、打开python开发工具
我们使用的是【PyCharm Community Edition 2023.1.4】版本。

2、创建py文件并输入以下代码
注:这里一定要修改服务的IP,也就是公网的那个IP
import json
import base64
import requests
your_ip = '0.0.0.0' # HAI服务器IP地址
your_port = 7862 # SD api 监听的端口
def submit_post(url: str,data: dict):
"""
Submit a POST request to the given URL with the given data.
"""
return requests.post(url,data=json.dumps(data))
def save_encoded_image(b64_image: str,output_path: str):
"""
Save the given image to the given output path.
"""
with open(output_path,"wb") as image_file:
image_file.write(base64.b64decode(b64_image))
if __name__ == '__main__':
# /sdapi/v1/txt2img
txt2img_url = f'http://{your_ip}:{your_port}/sdapi/v1/txt2img'
data = {
'prompt': 'a pretty cat,cyberpunk art,kerem beyit,very cute robot zen,Playful,Independent,beeple |',
'negative_prompt':'(deformed,distorted,disfigured:1.0),poorly drawn,bad anatomy,wrong anatomy,extra limb,missing limb,floating limbs,(mutated hands and fingers:1.5),disconnected limbs,mutation,mutated,ugly,disgusting,blurry,amputation,flowers,human,man,woman',
'Steps':50,
'Seed':127361827368
}
response = submit_post(txt2img_url,data)
save_encoded_image(response.json()['images'][0],'cat.png')
参数说明
| 名称 | 说明 |
|---|---|
| prompt | 提示词 |
| negative_prompt | 反向提示词 |
| seed | 种子,随机数 |
| batch_size | 每次张数 |
| n_iter | 生成批次 |
| steps | 生成步数 |
| cfg_scale | 关键词相关性 |
| width | 宽度 |
| height | 高度 |
| restore_faces | 脸部修复 |
| tiling | 可平铺 |
| sampler_index | 采样方法 |
3、运行效果
可以看到生成的图片就在对应的文件夹内,我们还可以改很多参数。
Stable Diffusion模型总结
图片生成,还是用处非常多的,而且价格也比较划算,使用和配置都很方便,效率也好高,可以自己搭建尝试一下,很棒的。
自行搭建ChatGL M26BAI模型服务用于AI对话
单独访问效果:

vscode内运行效果:
我们使用腾讯云来创建,有完整的操作流程,很方便我们搭建使用。
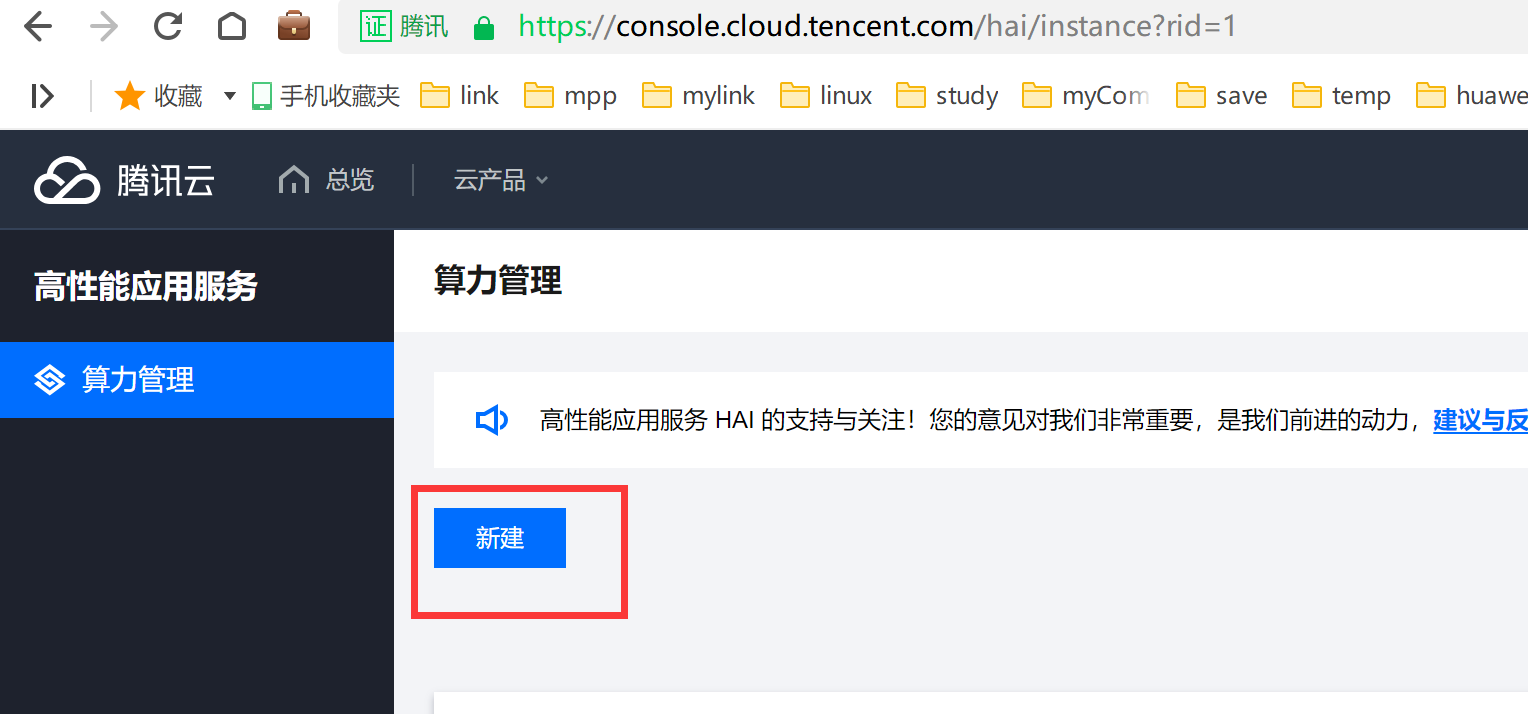
一、服务创建
创建效果:

新建服务
服务选择:(这里可以下拉选择大一些的硬盘)


剩余的时间需要等待。
创建完毕效果:

二、操作面板介绍

1、chatglm_gradio:
我们可以直接通过这个网址进行对话操作。

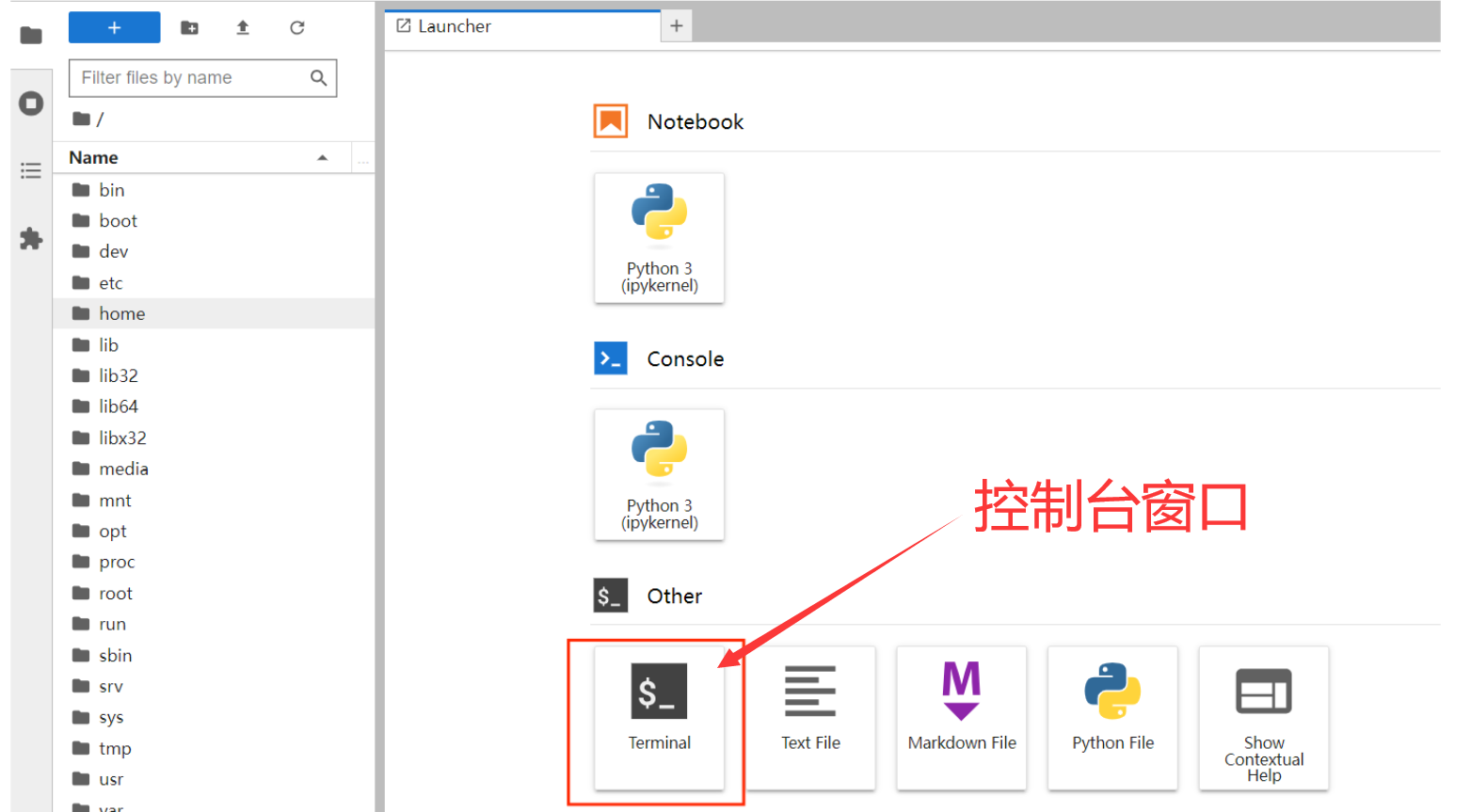
2、jupyter_lab:
创建控制台窗口,可以在这里进行具体的代码编辑与运行。
三、基础服务示例(jupyter_lab操作)
1、进入并启动服务
cd /root/ChatGLM2-6B/
python api.py
运行起来能看到有信息提示。

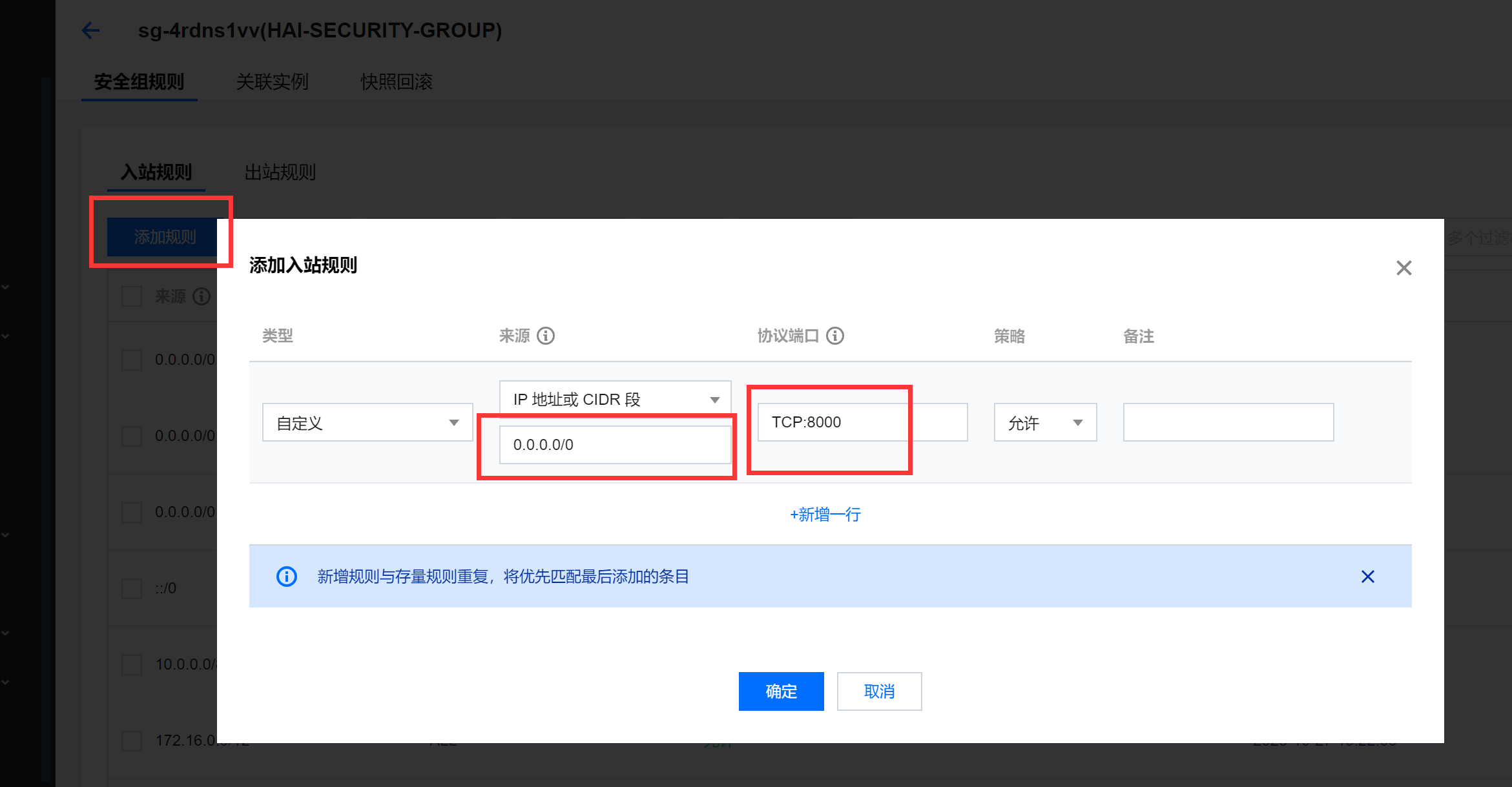
2、启动后开启访问端口(8000)
进入到服务详情。

添加防火墙可通过的端口号。
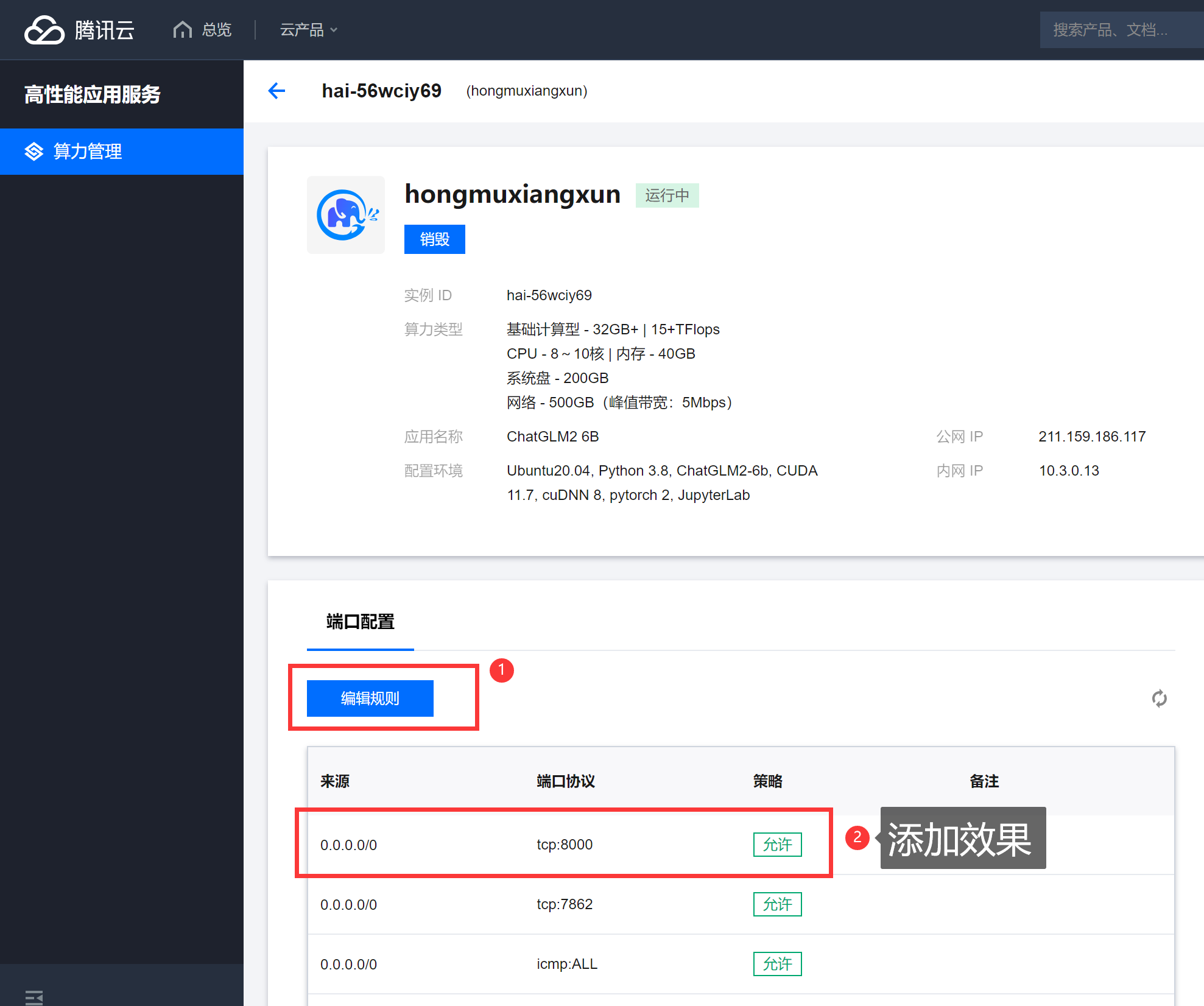
添加效果:
3、Python接口访问效果
添加后即可访问:http://你的公网IP:8000/ 的这个接口,具体服务参数如下列代码:
import requests
# 定义测试数据,以及FastAPI服务器的地址和端口
server_url = "http://0.0.0.0:8000" # 请确保将地址和端口更改为您的API服务器的实际地址和端口
test_data = {
"prompt": "'电影雨人讲的是什么?'",
"history": [],
"max_length": 50,
"top_p": 0.7,
"temperature": 0.95
}
# 发送HTTP POST请求
response = requests.post(server_url, json=test_data)
# 处理响应
if response.status_code == 200:
result = response.json()
print("Response:", result["response"])
print("History:", result["history"])
print("Status:", result["status"])
print("Time:", result["time"])
else:
print("Failed to get a valid response. Status code:", response.status_code)
访问效果:

四、正式服务代码
1、修改【openai**-api.py**】文件
使用以下代码覆盖原有的代码:
# coding=utf-8
# Implements API for ChatGLM2-6B in OpenAI's format. (https://platform.openai.com/docs/api-reference/chat)
# Usage: python openai_api.py
# Visit http://localhost:8000/docs for documents.
import time
import torch
import uvicorn
from pydantic import BaseModel, Field
from fastapi import FastAPI, HTTPException
from fastapi.middleware.cors import CORSMiddleware
from contextlib import asynccontextmanager
from typing import Any, Dict, List, Literal, Optional, Union
from transformers import AutoTokenizer, AutoModel
from sse_starlette.sse import ServerSentEvent, EventSourceResponse
@asynccontextmanager
async def lifespan(app: FastAPI): # collects GPU memory
yield
if torch.cuda.is_available():
torch.cuda.empty_cache()
torch.cuda.ipc_collect()
app = FastAPI(lifespan=lifespan)
app.add_middleware(
CORSMiddleware,
allow_origins=["*"],
allow_credentials=True,
allow_methods=["*"],
allow_headers=["*"],
)
class ModelCard(BaseModel):
id: str
object: str = "model"
created: int = Field(default_factory=lambda: int(time.time()))
owned_by: str = "owner"
root: Optional[str] = None
parent: Optional[str] = None
permission: Optional[list] = None
class ModelList(BaseModel):
object: str = "list"
data: List[ModelCard] = []
class ChatMessage(BaseModel):
role: Literal["user", "assistant", "system"]
content: str
class DeltaMessage(BaseModel):
role: Optional[Literal["user", "assistant", "system"]] = None
content: Optional[str] = None
class ChatCompletionRequest(BaseModel):
model: str
messages: List[ChatMessage]
temperature: Optional[float] = None
top_p: Optional[float] = None
max_length: Optional[int] = None
stream: Optional[bool] = False
class ChatCompletionResponseChoice(BaseModel):
index: int
message: ChatMessage
finish_reason: Literal["stop", "length"]
class ChatCompletionResponseStreamChoice(BaseModel):
index: int
delta: DeltaMessage
finish_reason: Optional[Literal["stop", "length"]]
class ChatCompletionResponse(BaseModel):
model: str
object: Literal["chat.completion", "chat.completion.chunk"]
choices: List[Union[ChatCompletionResponseChoice, ChatCompletionResponseStreamChoice]]
created: Optional[int] = Field(default_factory=lambda: int(time.time()))
@app.get("/v1/models", response_model=ModelList)
async def list_models():
global model_args
model_card = ModelCard(id="gpt-3.5-turbo")
return ModelList(data=[model_card])
@app.post("/v1/chat/completions", response_model=ChatCompletionResponse)
async def create_chat_completion(request: ChatCompletionRequest):
global model, tokenizer
if request.messages[-1].role != "user":
raise HTTPException(status_code=400, detail="Invalid request")
query = request.messages[-1].content
prev_messages = request.messages[:-1]
if len(prev_messages) > 0 and prev_messages[0].role == "system":
query = prev_messages.pop(0).content + query
history = []
if len(prev_messages) % 2 == 0:
for i in range(0, len(prev_messages), 2):
if prev_messages[i].role == "user" and prev_messages[i+1].role == "assistant":
history.append([prev_messages[i].content, prev_messages[i+1].content])
if request.stream:
generate = predict(query, history, request.model)
return EventSourceResponse(generate, media_type="text/event-stream")
response, _ = model.chat(tokenizer, query, history=history)
choice_data = ChatCompletionResponseChoice(
index=0,
message=ChatMessage(role="assistant", content=response),
finish_reason="stop"
)
return ChatCompletionResponse(model=request.model, choices=[choice_data], object="chat.completion")
async def predict(query: str, history: List[List[str]], model_id: str):
global model, tokenizer
choice_data = ChatCompletionResponseStreamChoice(
index=0,
delta=DeltaMessage(role="assistant"),
finish_reason=None
)
chunk = ChatCompletionResponse(model=model_id, choices=[choice_data], object="chat.completion.chunk")
#yield "{}".format(chunk.json(exclude_unset=True, ensure_ascii=False))
yield "{}".format(chunk.model_dump_json(exclude_unset=True))
current_length = 0
for new_response, _ in model.stream_chat(tokenizer, query, history):
if len(new_response) == current_length:
continue
new_text = new_response[current_length:]
current_length = len(new_response)
choice_data = ChatCompletionResponseStreamChoice(
index=0,
delta=DeltaMessage(content=new_text),
finish_reason=None
)
chunk = ChatCompletionResponse(model=model_id, choices=[choice_data], object="chat.completion.chunk")
#yield "{}".format(chunk.json(exclude_unset=True, ensure_ascii=False))
yield "{}".format(chunk.model_dump_json(exclude_unset=True))
choice_data = ChatCompletionResponseStreamChoice(
index=0,
delta=DeltaMessage(),
finish_reason="stop"
)
chunk = ChatCompletionResponse(model=model_id, choices=[choice_data], object="chat.completion.chunk")
#yield "{}".format(chunk.json(exclude_unset=True, ensure_ascii=False))
yield "{}".format(chunk.model_dump_json(exclude_unset=True))
yield '[DONE]'
if __name__ == "__main__":
tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm2-6b", revision="v1.0", trust_remote_code=True)
model = AutoModel.from_pretrained("THUDM/chatglm2-6b", revision="v1.0", trust_remote_code=True).cuda()
# 多显卡支持,使用下面两行代替上面一行,将num_gpus改为你实际的显卡数量
# from utils import load_model_on_gpus
# model = load_model_on_gpus("THUDM/chatglm2-6b", num_gpus=2)
model.eval()
uvicorn.run(app, host='0.0.0.0', port=8000, workers=1)
2、运行【openai-api.py】文件,服务端开启服务
在控制台直接输入python openai-api.py即可运行

五、可视化页面搭建
1、在创建cloud Studio的时候选择【应用推荐】
选择【ChatGPT Next Web】

2、Fork项目

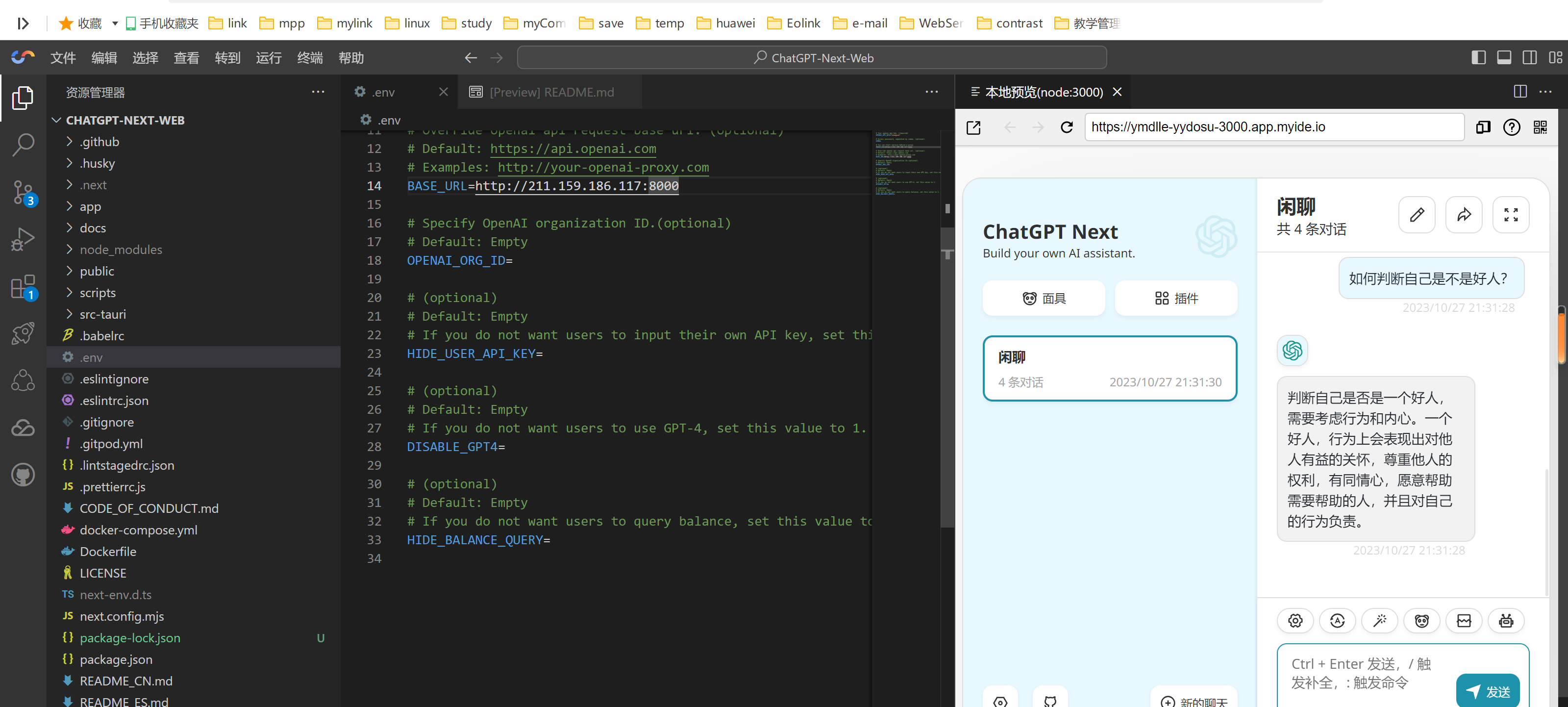
3、修改【.env.template】文件
直接替换我下面的就行,但是需要替换一下你服务的IP。
# Your openai api key. (required)
OPENAI_API_KEY="hongMuXiangXun"
# Access passsword, separated by comma. (optional)
CODE=
# You can start service behind a proxy
PROXY_URL=http://你的IP:8000
# Override openai api request base url. (optional)
# Default: https://api.openai.com
# Examples: http://your-openai-proxy.com
BASE_URL=http://你的IP:8000
# Specify OpenAI organization ID.(optional)
# Default: Empty
OPENAI_ORG_ID=
# (optional)
# Default: Empty
# If you do not want users to input their own API key, set this value to 1.
HIDE_USER_API_KEY=
# (optional)
# Default: Empty
# If you do not want users to use GPT-4, set this value to 1.
DISABLE_GPT4=
# (optional)
# Default: Empty
# If you do not want users to query balance, set this value to 1.
HIDE_BALANCE_QUERY=
4、修改【.env.template】为【.env】文件
鼠标右键,重命名即可。

六、运行可视化操作页面
1、新建终端
2、运行服务
先运行npm的安装,在通过【yarn dev】启动。
npm install
yarn dev
安装时间较长,别急,等一会。

运行yarn dev效果:

3、选择打开方式
这里需要选择到端口处进行具体的选择,选择方式如下图。

我觉得这个页面设计的还是不错的。

内部访问效果也OK:

到此,恭喜你,创建完毕了。
ChatGL M26BAI模型总结、
整体上六个大步骤,没有消耗多长时间,我是搞了一遍之后开始写的这篇文章,故而看着时间长一些,其实熟练操作也就分分钟的事情,应该是适合绝大多数的程序员来操作的。
操作不复杂,基本都有提示,希望对大家都能有所帮助,下面我单独问了一个问题,就是我们程序员未来发展之路,未遂没有一个具体解答,但是还是很中肯的,那就是学无止境。

Pytorch2.0 AI框架视频处理
一、框架选择
1、这里选择【Pytorch2.0】框架办版本。

创建完就是等待的时间,这个还是比较快的,我们主要使用【jupyter_lab】。


二、使用 JupyterLab 体验完整的机器学习工作流程
这里主要使用的是 FashionMNIST 数据集。
1、Terminal操作
使用的是清华大学的镜像加载本地数据集
mkdir dataset-fashion-mnist #创建文件夹 dataset-fashion-mnist
cd dataset-fashion-mnist
wget https://mirror.tuna.tsinghua.edu.cn/raspberry-pi-os/raspbian/pool/main/d/dataset-fashion-mnist/dataset-fashion-mnist_0.0~git20200523.55506a9.orig.tar.xz #下载数据集
tar -xf dataset-fashion-mnist_0.0~git20200523.55506a9.orig.tar.xz --strip-components=1
cd data && mkdir FashionMNIST && mkdir FashionMNIST/raw
2、打开root/dataset-fashion-mnist/data/fashion文件夹

复制文件至【root/dataset-fashion-mnist/data/FashionMNIST/raw/】文件夹

3、创建【Notebook】

运行以下代码:
import torch
from torch import nn
from torch.utils.data import DataLoader
from torchvision import datasets
from torchvision.transforms import ToTensor
# 加载本地训练数据
training_data = datasets.FashionMNIST(
root="/root/dataset-fashion-mnist/data",
train=True,
download=True,
transform=ToTensor(),
)
# 加载本地测试数据
test_data = datasets.FashionMNIST(
root="/root/dataset-fashion-mnist/data",
train=False,
download=True,
transform=ToTensor(),
)
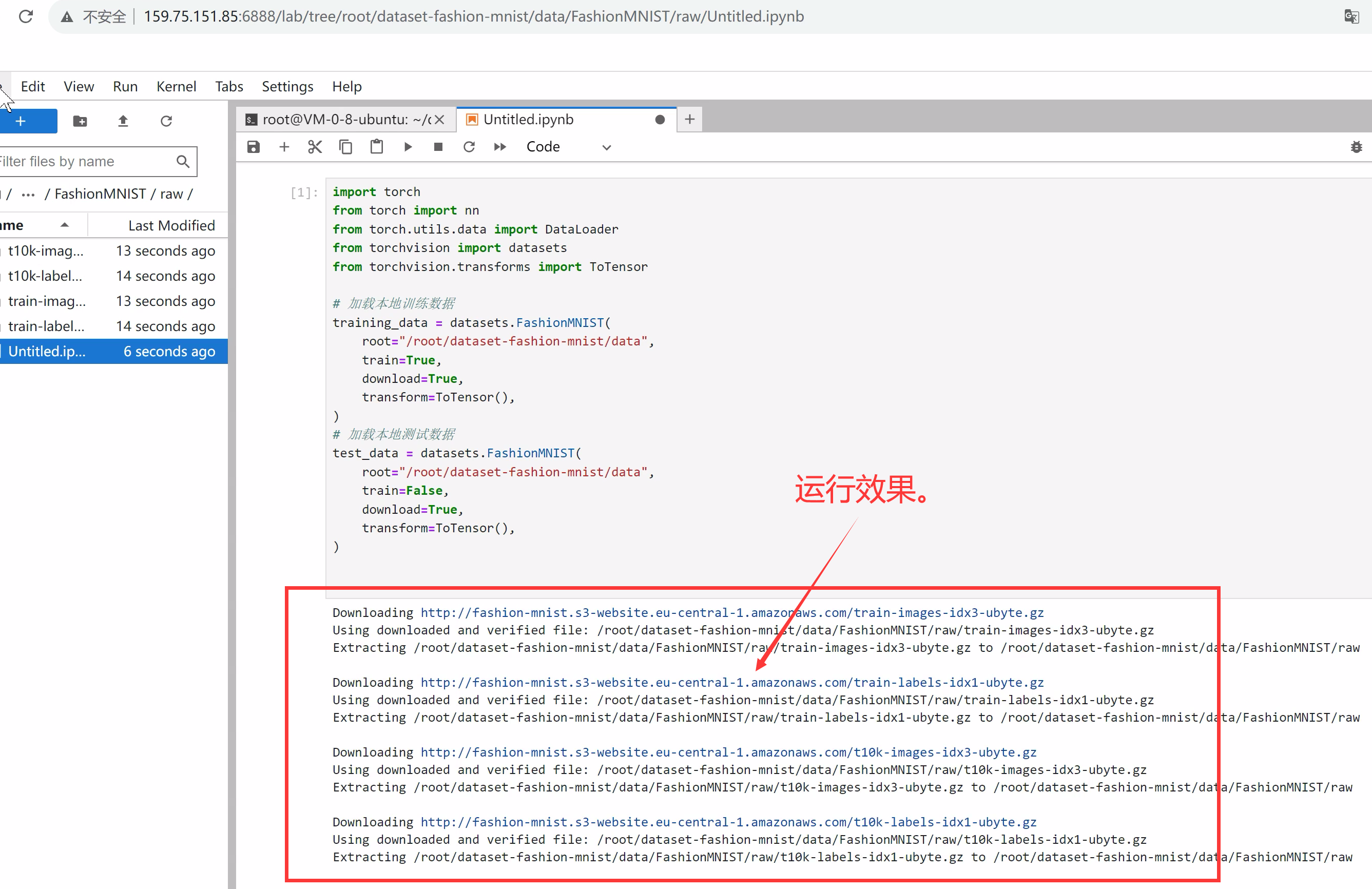
4、运行方法
注意看下图:


运行效果:
5、修改pip环境配置
pip config set global.index-url http://mirrors.cloud.tencent.com/pypi/simple
pip config set global.trusted-host mirrors.cloud.tencent.com

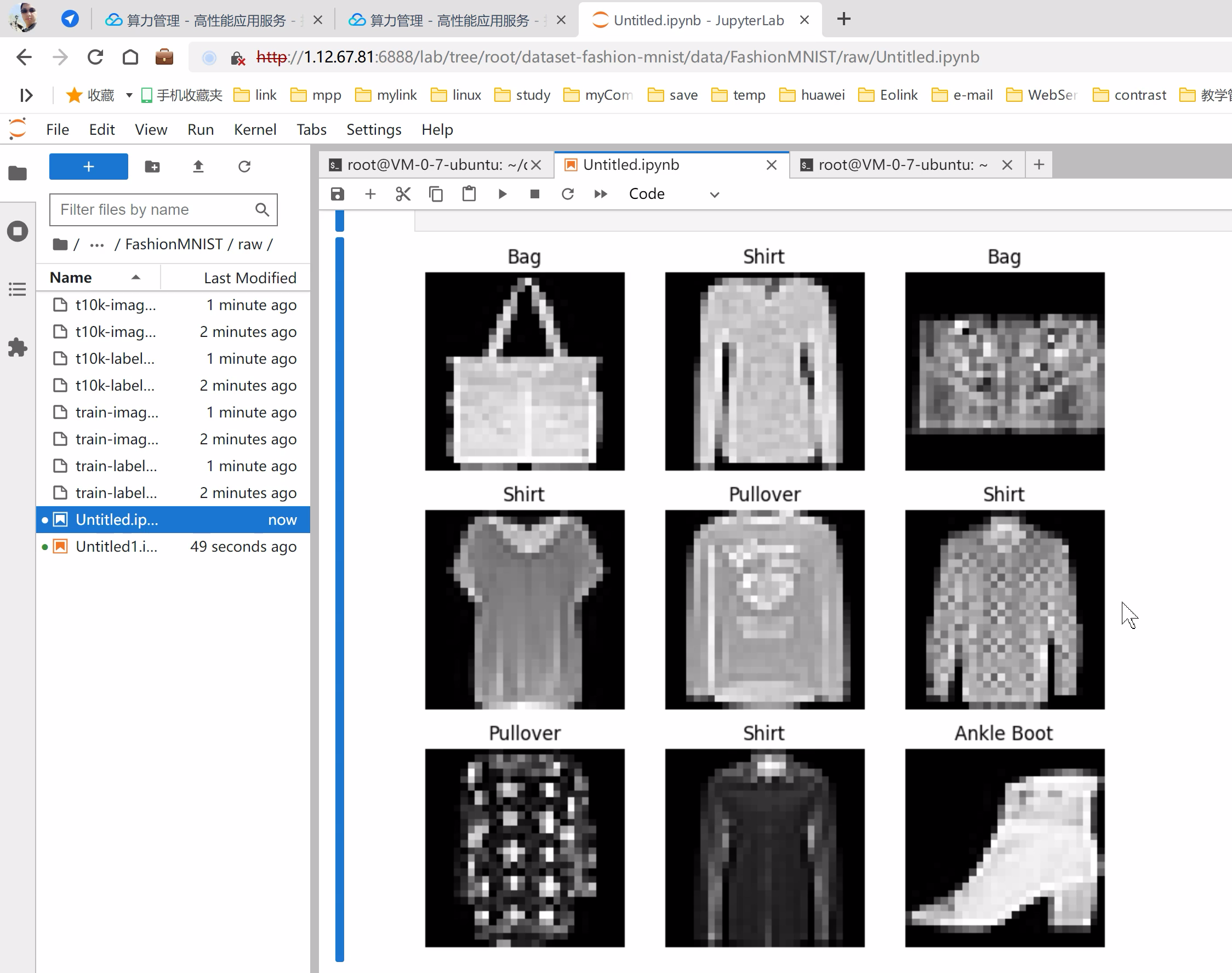
6、创建Terminal持续运行以下代码
import matplotlib.pyplot as plt
labels_map = {
0: "T-Shirt",
1: "Trouser",
2: "Pullover",
3: "Dress",
4: "Coat",
5: "Sandal",
6: "Shirt",
7: "Sneaker",
8: "Bag",
9: "Ankle Boot",
}
figure = plt.figure(figsize=(8, 8))
cols, rows = 3, 3
for i in range(1, cols * rows + 1):
sample_idx = torch.randint(len(training_data), size=(1,)).item()
img, label = training_data[sample_idx]
figure.add_subplot(rows, cols, i)
plt.title(labels_map[label])
plt.axis("off")
plt.imshow(img.squeeze(), cmap="gray")
plt.show()
运行效果:
batch_size = 64
# 创建 dataloader
train_dataloader = DataLoader(training_data, batch_size=batch_size)
test_dataloader = DataLoader(test_data, batch_size=batch_size)
for X, y in test_dataloader:
print(f"Shape of X [N, C, H, W]: {X.shape}")
print(f"Shape of y: {y.shape} {y.dtype}")
break
# 获取用于训练的 cpu 或 gpu 设备
device = "cuda" if torch.cuda.is_available() else "mps" if torch.backends.mps.is_available() else "cpu"
print(f"Using {device} device")
# 定义模型
class NeuralNetwork(nn.Module):
def __init__(self):
super().__init__()
self.flatten = nn.Flatten()
self.linear_relu_stack = nn.Sequential(
nn.Linear(28*28, 512),
nn.ReLU(),
nn.Linear(512, 512),
nn.ReLU(),
nn.Linear(512, 10)
)
def forward(self, x):
x = self.flatten(x)
logits = self.linear_relu_stack(x)
return logits
model = NeuralNetwork().to(device)
print(model)
loss_fn = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=1e-3)
def train(dataloader, model, loss_fn, optimizer):
size = len(dataloader.dataset)
model.train()
for batch, (X, y) in enumerate(dataloader):
X, y = X.to(device), y.to(device)
# 计算预测误差
pred = model(X)
loss = loss_fn(pred, y)
# 反向传播
optimizer.zero_grad()
loss.backward()
optimizer.step()
if batch % 100 == 0:
loss, current = loss.item(), (batch + 1) * len(X)
print(f"loss: {loss:>7f} [{current:>5d}/{size:>5d}]")
def test(dataloader, model, loss_fn):
size = len(dataloader.dataset)
num_batches = len(dataloader)
model.eval()
test_loss, correct = 0, 0
with torch.no_grad():
for X, y in dataloader:
X, y = X.to(device), y.to(device)
pred = model(X)
test_loss += loss_fn(pred, y).item()
correct += (pred.argmax(1) == y).type(torch.float).sum().item()
test_loss /= num_batches
correct /= size
print(f"Test Error: \n Accuracy: {(100*correct):>0.1f}%, Avg loss: {test_loss:>8f} \n")
这里是第7步,这里需要等一会,一直等到出现【Done!】才结束。这里等一会。
epochs = 5
for t in range(epochs):
print(f"Epoch {t+1}\n-------------------------------")
train(train_dataloader, model, loss_fn, optimizer)
test(test_dataloader, model, loss_fn)
print("Done!")
7、保存模型
torch.save(model.state_dict(), "/root/model.pth")
print("Saved PyTorch Model State to model.pth")

8、加载模型并预测
model = NeuralNetwork()
model.load_state_dict(torch.load("/root/model.pth"))

9、预测模型
classes = [
"包",
"上衣",
"套头衫",
"连衣裙",
"外套",
"凉鞋",
"衬衫",
"运动鞋",
"包",
"短靴",
] #定义了一个包含类别标签的 classes 列表
model.eval() #将 PyTorch 模型设置为评估模式
x, y = test_data[1][0], test_data[1][1]#测试数据 test_data 中获取样本 分别为图像数据和其真实标签
with torch.no_grad():
pred = model(x)
predicted, actual = classes[pred[0].argmax(0)], classes[y]#选择具有最高概率的类别索引
print(f'Predicted: "{predicted}", Actual: "{actual}"') #模型的预测结果 predicted 与真实标签 actual 进行比较,并使用 print 函数输出这两个值。
#输出图片信息
# 将 x 转换回图像格式
image = x.numpy().transpose(1, 2, 0)
# 显示图像
plt.figure(figsize=(4, 4))
plt.imshow(image)
# 设置中文标题
print('预测结果: "{predicted}", 实际结果: "{actual}"'.format(predicted=predicted, actual=actual))
plt.axis('off')
plt.show()
预测结果:

三、使用 JupyterLab 体验使用字符级循环神经网络(RNN) 生成姓名
1、数据准备
新建一个命令窗口,输入以下命令,下载资源包并解压
cd /root
wget https://gitee.com/mmliujc/tencent_gpu/raw/master/data.zip
unzip data
2、新建一个 Notebook 页面,选择 Python 3
持续运行以下代码到步骤8。
from __future__ import unicode_literals, print_function, division
from io import open
import glob
import os
import unicodedata
import string
all_letters = string.ascii_letters + " .,;'-"
n_letters = len(all_letters) + 1 # Plus EOS marker
def findFiles(path): return glob.glob(path)
# Turn a Unicode string to plain ASCII, thanks to https://stackoverflow.com/a/518232/2809427
def unicodeToAscii(s):
return ''.join(
c for c in unicodedata.normalize('NFD', s)
if unicodedata.category(c) != 'Mn'
and c in all_letters
)
# Read a file and split into lines
def readLines(filename):
with open(filename, encoding='utf-8') as some_file:
return [unicodeToAscii(line.strip()) for line in some_file]
# Build the category_lines dictionary, a list of lines per category
category_lines = {}
all_categories = []
for filename in findFiles('/root/data/names/*.txt'):
category = os.path.splitext(os.path.basename(filename))[0]
all_categories.append(category)
lines = readLines(filename)
category_lines[category] = lines
n_categories = len(all_categories)
if n_categories == 0:
raise RuntimeError('Data not found. Make sure that you downloaded data '
'from https://download.pytorch.org/tutorial/data.zip and extract it to '
'the current directory.')
print('# categories:', n_categories, all_categories)
print(unicodeToAscii("O'Néàl"))
创建网络
import torch
import torch.nn as nn
class RNN(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(RNN, self).__init__()
self.hidden_size = hidden_size
self.i2h = nn.Linear(n_categories + input_size + hidden_size, hidden_size)
self.i2o = nn.Linear(n_categories + input_size + hidden_size, output_size)
self.o2o = nn.Linear(hidden_size + output_size, output_size)
self.dropout = nn.Dropout(0.1)
self.softmax = nn.LogSoftmax(dim=1)
def forward(self, category, input, hidden):
input_combined = torch.cat((category, input, hidden), 1)
hidden = self.i2h(input_combined)
output = self.i2o(input_combined)
output_combined = torch.cat((hidden, output), 1)
output = self.o2o(output_combined)
output = self.dropout(output)
output = self.softmax(output)
return output, hidden
def initHidden(self):
return torch.zeros(1, self.hidden_size)
训练网络
import random
# Random item from a list
def randomChoice(l):
return l[random.randint(0, len(l) - 1)]
# Get a random category and random line from that category
def randomTrainingPair():
category = randomChoice(all_categories)
line = randomChoice(category_lines[category])
return category, line
# One-hot vector for category
def categoryTensor(category):
##### 数据结构与算法
这一块在笔试、面试的代码题中考核较多,其中常考的数据结构主要有:**数组、链表、队列、栈、Set、Map、哈希表等**,不同数据结构有不同的方法以及储存原理,这些算是技术岗的必备知识。**算法部分主要分为两大块,排序算法与一些其他算法题**。
排序算法根据考频高低主要有:快速排序、归并排序、堆排序、冒泡排序、插入排序、选择排序、希尔排序、桶排序、基数排序、Timsort这十种,这类考核点要么是算法的时间、空间复杂度、稳定度,要么是直接手写代码,故在理解算法原理的同时,对JS语言版的排序算法代码也要加强记忆。
- 二叉树层序遍历
- B 树的特性,B 树和 B+树的区别
- 尾递归
- 如何写一个大数阶乘?递归的方法会出现什么问题?
- 把多维数组变成一维数组的方法
- 知道的排序算法 说一下冒泡快排的原理
- Heap 排序方法的原理?复杂度?
- 几种常见的排序算法,手写
- 数组的去重,尽可能写出多个方法
- 如果有一个大的数组,都是整型,怎么找出最大的前 10 个数
- 知道数据结构里面的常见的数据结构
- 找出数组中第 k 大的数组出现多少次,比如数组【1,2, 4,4,3,5】第二大的数字是 4,出现两次,所以返回 2
- 合并两个有序数组
- 给一个数,去一个已经排好序的数组中寻找这个数的位 置(通过快速查找,二分查找)

**网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。**
**需要这份系统化的资料的朋友,可以添加V获取:vip1024c (备注前端)**

**一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**
return torch.zeros(1, self.hidden_size)
训练网络
import random
# Random item from a list
def randomChoice(l):
return l[random.randint(0, len(l) - 1)]
# Get a random category and random line from that category
def randomTrainingPair():
category = randomChoice(all_categories)
line = randomChoice(category_lines[category])
return category, line
# One-hot vector for category
def categoryTensor(category):
##### 数据结构与算法
这一块在笔试、面试的代码题中考核较多,其中常考的数据结构主要有:**数组、链表、队列、栈、Set、Map、哈希表等**,不同数据结构有不同的方法以及储存原理,这些算是技术岗的必备知识。**算法部分主要分为两大块,排序算法与一些其他算法题**。
排序算法根据考频高低主要有:快速排序、归并排序、堆排序、冒泡排序、插入排序、选择排序、希尔排序、桶排序、基数排序、Timsort这十种,这类考核点要么是算法的时间、空间复杂度、稳定度,要么是直接手写代码,故在理解算法原理的同时,对JS语言版的排序算法代码也要加强记忆。
- 二叉树层序遍历
- B 树的特性,B 树和 B+树的区别
- 尾递归
- 如何写一个大数阶乘?递归的方法会出现什么问题?
- 把多维数组变成一维数组的方法
- 知道的排序算法 说一下冒泡快排的原理
- Heap 排序方法的原理?复杂度?
- 几种常见的排序算法,手写
- 数组的去重,尽可能写出多个方法
- 如果有一个大的数组,都是整型,怎么找出最大的前 10 个数
- 知道数据结构里面的常见的数据结构
- 找出数组中第 k 大的数组出现多少次,比如数组【1,2, 4,4,3,5】第二大的数字是 4,出现两次,所以返回 2
- 合并两个有序数组
- 给一个数,去一个已经排好序的数组中寻找这个数的位 置(通过快速查找,二分查找)
[外链图片转存中...(img-V6dh42ar-1713438667705)]
**网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。**
**需要这份系统化的资料的朋友,可以添加V获取:vip1024c (备注前端)**
[外链图片转存中...(img-2wimC0Hu-1713438667705)]
**一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**















 7万+
7万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









