







网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
因此,如果我们选择将质心与后续帧之间的最小距离相关联,我们可以构建我们的对象跟踪器。
在上图中,可以看到质心跟踪器算法如何选择关联质心以最小化它们各自的欧几里得距离。
但是左下角的孤独点呢?
它没有与任何东西相关联——我们如何处理它?
步骤4:注册新对象
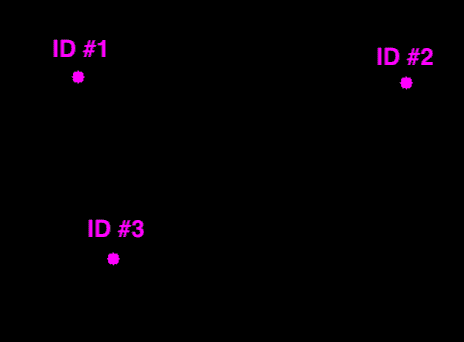
如果输入检测比跟踪的现有对象多,我们需要注册新对象。 “注册”仅仅意味着我们通过以下方式将新对象添加到我们的跟踪对象列表中:
为其分配一个新的对象 ID
存储该对象的边界框坐标的质心
然后我们可以返回到步骤2,重复执行。
上图演示了使用最小欧几里得距离关联现有对象 ID,然后注册新对象的过程。
步骤5:注销旧对象
当旧的对象超出范围时,注销旧对象、
===============================================================
ObjectTracking
├── Model
│ ├── init.py
│ └── centroidtracker.py
├── object_tracker.py
├── deploy.prototxt
└──res10_300x300_ssd_iter_140000_fp16.caffemodel
===========================================================================
新建 centroidtracker.py,写入代码:
import the necessary packages
from scipy.spatial import distance as dist
from collections import OrderedDict
import numpy as np
class CentroidTracker():
def init(self, maxDisappeared=50):
self.nextObjectID = 0
self.objects = OrderedDict()
self.disappeared = OrderedDict()
存储给定对象被允许标记为“消失”的最大连续帧数,直到我们需要从跟踪中注销该对象
self.maxDisappeared = maxDisappeared
导入了所需的包和模块:distance 、 OrderedDict 和 numpy 。
定义类 CentroidTracker 。构造函数接受一个参数maxDisappeared,即给定对象必须丢失/消失的最大连续帧数,如果超过这个数值就将这个对象删除。
四个类变量:
-
nextObjectID :用于为每个对象分配唯一 ID 的计数器。如果一个对象离开帧并且没有返回 maxDisappeared 帧,则将分配一个新的(下一个)对象 ID。
-
objects :使用对象 ID 作为键和质心 (x, y) 坐标作为值的字典。
-
disappeared:保持特定对象 ID(键)已被标记为“丢失”的连续帧数(值)。
-
maxDisappeared :在我们取消注册对象之前,允许将对象标记为“丢失/消失”的连续帧数。
让我们定义负责向我们的跟踪器添加新对象的 register 方法:
def register(self, centroid):
注册对象时,我们使用下一个可用的对象ID来存储质心
self.objects[self.nextObjectID] = centroid
self.disappeared[self.nextObjectID] = 0
self.nextObjectID += 1
def deregister(self, objectID):
要注销注册对象ID,我们从两个字典中都删除了该对象ID
del self.objects[objectID]
del self.disappeared[objectID]
register 方法接受一个质心,然后使用下一个可用的对象 ID 将其添加到对象字典中。
对象消失的次数在消失字典中初始化为 0。
最后,我们增加 nextObjectID,这样如果一个新对象进入视野,它将与一个唯一的 ID 相关联。
与我们的注册方法类似,我们也需要一个注销方法。
deregister 方法分别删除对象和消失字典中的 objectID。
质心跟踪器实现的核心位于update方法中
def update(self, rects):
检查输入边界框矩形的列表是否为空
if len(rects) == 0:
遍历任何现有的跟踪对象并将其标记为消失
for objectID in list(self.disappeared.keys()):
self.disappeared[objectID] += 1
如果达到给定对象被标记为丢失的最大连续帧数,请取消注册
if self.disappeared[objectID] > self.maxDisappeared:
self.deregister(objectID)
由于没有质心或跟踪信息要更新,请尽早返回
return self.objects
初始化当前帧的输入质心数组
inputCentroids = np.zeros((len(rects), 2), dtype=“int”)
在边界框矩形上循环
for (i, (startX, startY, endX, endY)) in enumerate(rects):
use the bounding box coordinates to derive the centroid
cX = int((startX + endX) / 2.0)
cY = int((startY + endY) / 2.0)
inputCentroids[i] = (cX, cY)
如果我们当前未跟踪任何对象,请输入输入质心并注册每个质心
if len(self.objects) == 0:
for i in range(0, len(inputCentroids)):
self.register(inputCentroids[i])
否则,当前正在跟踪对象,因此我们需要尝试将输入质心与现有对象质心进行匹配
else:
抓取一组对象ID和相应的质心
objectIDs = list(self.objects.keys())
objectCentroids = list(self.objects.values())
分别计算每对对象质心和输入质心之间的距离-我们的目标是将输入质心与现有对象质心匹配
D = dist.cdist(np.array(objectCentroids), inputCentroids)
为了执行此匹配,我们必须(1)在每行中找到最小值,然后(2)根据行索引的最小值对行索引进行排序,以使具有最小值的行位于索引列表的* front *处
rows = D.min(axis=1).argsort()
接下来,我们在列上执行类似的过程,方法是在每一列中找到最小值,然后使用先前计算的行索引列表进行排序
cols = D.argmin(axis=1)[rows]
为了确定是否需要更新,注册或注销对象,我们需要跟踪已经检查过的行索引和列索引
usedRows = set()
usedCols = set()
循环遍历(行,列)索引元组的组合
for (row, col) in zip(rows, cols):
如果我们之前已经检查过行或列的值,请忽略它
if row in usedRows or col in usedCols:
continue
否则,获取当前行的对象ID,设置其新的质心,然后重置消失的计数器
objectID = objectIDs[row]
self.objects[objectID] = inputCentroids[col]
self.disappeared[objectID] = 0
表示我们已经分别检查了行索引和列索引
usedRows.add(row)
usedCols.add(col)
计算我们尚未检查的行和列索引
unusedRows = set(range(0, D.shape[0])).difference(usedRows)
unusedCols = set(range(0, D.shape[1])).difference(usedCols)
如果对象质心的数量等于或大于输入质心的数量
我们需要检查一下其中的某些对象是否已潜在消失
if D.shape[0] >= D.shape[1]:
loop over the unused row indexes
for row in unusedRows:
抓取相应行索引的对象ID并增加消失的计数器
objectID = objectIDs[row]
self.disappeared[objectID] += 1
检查是否已将该对象标记为“消失”的连续帧数以用于注销该对象的手令
if self.disappeared[objectID] > self.maxDisappeared:
self.deregister(objectID)
否则,如果输入质心的数量大于现有对象质心的数量,我们需要将每个新的输入质心注册为可跟踪对象
else:
for col in unusedCols:
self.register(inputCentroids[col])
return the set of trackable objects
return self.objects
update方法接受边界框矩形列表。 rects 参数的格式假定为具有以下结构的元组: (startX, startY, endX, endY) 。
如果没有检测到,我们将遍历所有对象 ID 并增加它们的消失计数。 我们还将检查是否已达到给定对象被标记为丢失的最大连续帧数。 如果是,我们需要将其从我们的跟踪系统中删除。 由于没有要更新的跟踪信息,我们将提前返回。
否则,我们将初始化一个 NumPy 数组来存储每个 rect 的质心。 然后,我们遍历边界框矩形并计算质心并将其存储在 inputCentroids 列表中。 如果没有我们正在跟踪的对象,我们将注册每个新对象。
否则,我们需要根据最小化它们之间的欧几里得距离的质心位置更新任何现有对象 (x, y) 坐标。
接下来我们在else中计算所有 objectCentroids 和 inputCentroids 对之间的欧几里德距离:
获取 objectID 和 objectCentroid 值。
计算每对现有对象质心和新输入质心之间的距离。距离图 D 的输出 NumPy 数组形状将是 (# of object centroids, # of input centroids) 。要执行匹配,我们必须 (1) 找到每行中的最小值,以及 (2) 根据最小值对行索引进行排序。我们对列执行非常相似的过程,在每列中找到最小值,然后根据已排序的行对它们进行排序。我们的目标是在列表的前面具有最小对应距离的索引值。
下一步是使用距离来查看是否可以关联对象 ID:
初始化两个集合以确定我们已经使用了哪些行和列索引。
然后遍历 (row, col) 索引元组的组合以更新我们的对象质心:
如果我们已经使用了此行或列索引,请忽略它并继续循环。
否则,我们找到了一个输入质心:
- 到现有质心的欧几里得距离最小
- 并且没有与任何其他对象匹配
- 在这种情况下,我们更新对象质心(第 113-115 行)并确保将 row 和 col 添加到它们各自的 usedRows 和 usedCols 集合中。
在我们的 usedRows + usedCols 集合中可能有我们尚未检查的索引:
所以我们必须确定哪些质心索引我们还没有检查过,并将它们存储在两个新的方便集合(unusedRows 和 usedCols)中。
最终检查会处理任何丢失或可能消失的对象:
如果对象质心的数量大于或等于输入质心的数量:
我们需要循环遍历未使用的行索引来验证这些对象是否丢失或消失。
在循环中,我们将:
- 增加他们在字典中消失的次数。
- 检查消失计数是否超过 maxDisappeared 阈值,如果是,我们将注销该对象。
否则,输入质心的数量大于现有对象质心的数量,我们有新的对象要注册和跟踪.
循环遍历未使用的Cols 索引并注册每个新质心。 最后,我们将可跟踪对象集返回给调用方法。
=======================================================================
已经实现了 CentroidTracker 类,让我们将其与对象跟踪驱动程序脚本一起使用。
驱动程序脚本是您可以使用自己喜欢的对象检测器的地方,前提是它会生成一组边界框。 这可能是 Haar Cascade、HOG + 线性 SVM、YOLO、SSD、Faster R-CNN 等。
在这个脚本中,需要实现的功能:
1、使用实时 VideoStream 对象从网络摄像头中抓取帧
2、加载并使用 OpenCV 的深度学习人脸检测器
3、实例化 CentroidTracker 并使用它来跟踪视频流中的人脸对象并显示结果。
做了那么多年开发,自学了很多门编程语言,我很明白学习资源对于学一门新语言的重要性,这些年也收藏了不少的Python干货,对我来说这些东西确实已经用不到了,但对于准备自学Python的人来说,或许它就是一个宝藏,可以给你省去很多的时间和精力。
别在网上瞎学了,我最近也做了一些资源的更新,只要你是我的粉丝,这期福利你都可拿走。
我先来介绍一下这些东西怎么用,文末抱走。
(1)Python所有方向的学习路线(新版)
这是我花了几天的时间去把Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
最近我才对这些路线做了一下新的更新,知识体系更全面了。

(2)Python学习视频
包含了Python入门、爬虫、数据分析和web开发的学习视频,总共100多个,虽然没有那么全面,但是对于入门来说是没问题的,学完这些之后,你可以按照我上面的学习路线去网上找其他的知识资源进行进阶。

(3)100多个练手项目
我们在看视频学习的时候,不能光动眼动脑不动手,比较科学的学习方法是在理解之后运用它们,这时候练手项目就很适合了,只是里面的项目比较多,水平也是参差不齐,大家可以挑自己能做的项目去练练。

(4)200多本电子书
这些年我也收藏了很多电子书,大概200多本,有时候带实体书不方便的话,我就会去打开电子书看看,书籍可不一定比视频教程差,尤其是权威的技术书籍。
基本上主流的和经典的都有,这里我就不放图了,版权问题,个人看看是没有问题的。
(5)Python知识点汇总
知识点汇总有点像学习路线,但与学习路线不同的点就在于,知识点汇总更为细致,里面包含了对具体知识点的简单说明,而我们的学习路线则更为抽象和简单,只是为了方便大家只是某个领域你应该学习哪些技术栈。

(6)其他资料
还有其他的一些东西,比如说我自己出的Python入门图文类教程,没有电脑的时候用手机也可以学习知识,学会了理论之后再去敲代码实践验证,还有Python中文版的库资料、MySQL和HTML标签大全等等,这些都是可以送给粉丝们的东西。

这些都不是什么非常值钱的东西,但对于没有资源或者资源不是很好的学习者来说确实很不错,你要是用得到的话都可以直接抱走,关注过我的人都知道,这些都是可以拿到的。
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 5939
5939

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









