







def main(args: Array[String]): Unit = {
if(args.length < 2){println(args.length);println(“Please input 2 args, return”); return}
val conf = new SparkConf().setAppName(“spark1”).setAppName(“icy hunter”).setMaster(“local[*]”)
val sc = new SparkContext(conf)
sc.textFile(args(0), 4)
.flatMap(.split(" "))
.map((, 1))
.reduceByKey(+)
.saveAsTextFile(args(1))
sc.stop()
}
}
此时可以测试一下传参效果。
idea调试时,main参数输入:菜单->run->Edit Configurations:
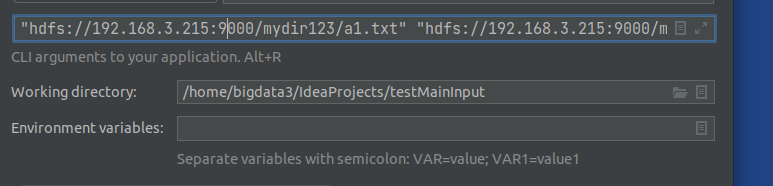
这就是传入的两个参数。
可以调试的时候试试。
## 打包成jar包
首先需要修改代码,将setMaster(“local[\*]”)删了
//包
import org.apache.spark.{SparkContext, SparkConf}
object testMainInput {
def main(args: Array[String]): Unit = {
if(args.length < 2){println(args.length);println(“Please
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 375
375

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









