







目录
随着深度学习的发展,在大模型的训练上都是在一些较大数据集上进行训练的,比如Imagenet-1k,Imagenet-11k,甚至是ImageNet-21k等。但我们在实际应用中,我们的数据集可能比较小,只有几千张照片,这时从头训练具有几千万参数的大型神经网络是不现实的,因为越大的模型对数据量的要求越高,过拟合无法避免。
因为试用于ImageNet数据集的复杂模型,在一些小的数据集上可能会过拟合,同时因为数据量有限,最终训练得到的模型的精度也可能达不到实用要求。
解决上述问题的方法:
- 收集更多数据集,当然这对于研究成本会大大增加。
- 应用迁移学习,从源数据集中学到知识迁移到目标数据集上。迁移学习的一大应用场景就是模型微调,简单的来说就是把在别人训练好的基础上,换成自己的数据集继续训练,来调整参数。Pytorch中提供很多预训练模型,学习如何进行模型微调,可以大大提升自己任务的质量和速度。
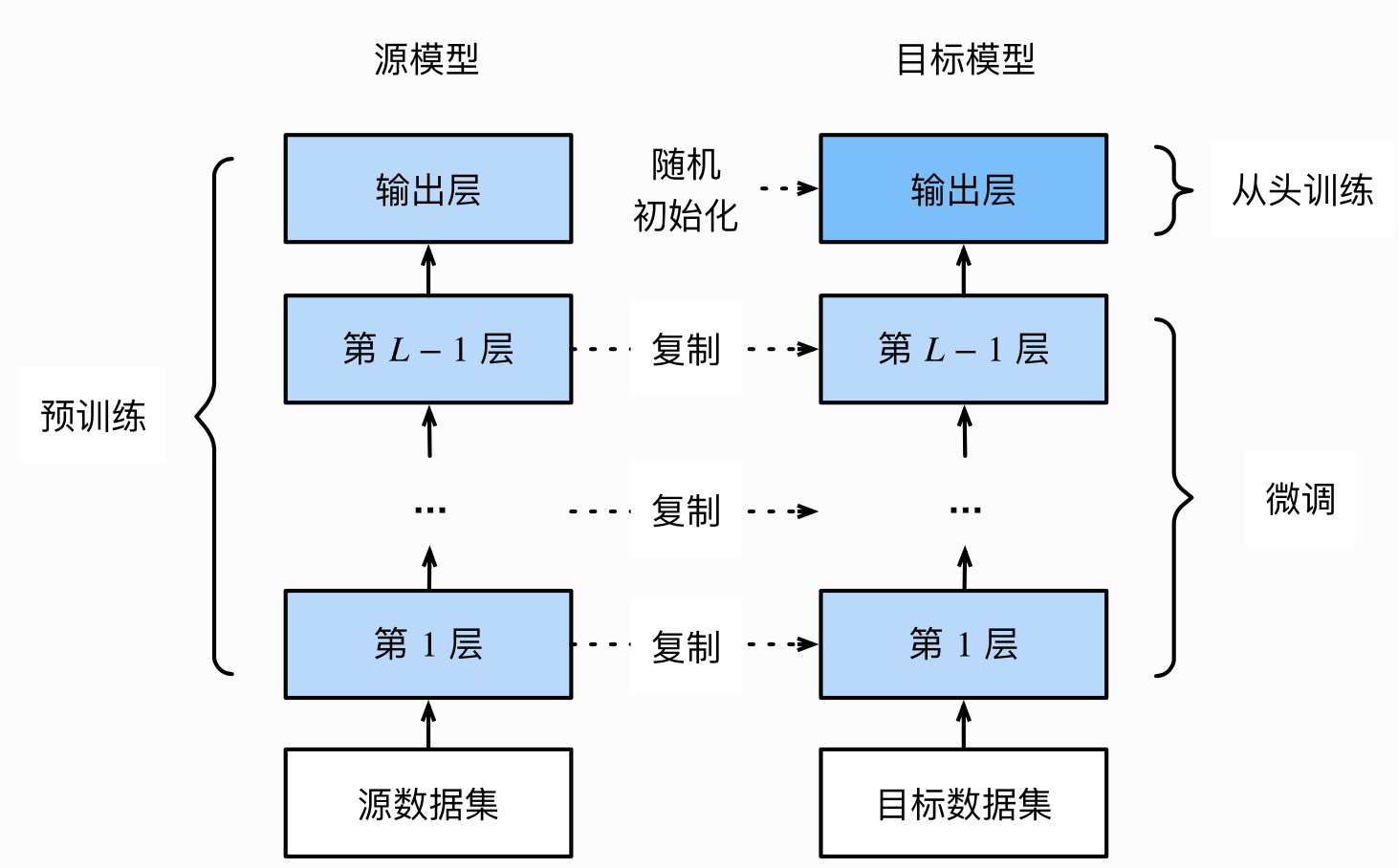
一、模型微调的流程
1.1 在源数据集上预训练一个神经网络模型,即源模型。
1.2 创建一个新的神经网络模型,即目标模型。他复制了源模型上除了输出层外的所有模型设计及其参数。我们假设这些模型参数包含了源数据集上学习到的知识,且这些知识同样试用于目标数据集,我们还假设源模型的输出层跟源数据集的标签紧密相关,因此输出层在目标模型上可以采用。
1.3 为目标模型添加一个输出大小为目标数据集类别个数的输出层,并随机初始化该层的模型参数。
1.4 在目标数据集上训练目标模型,我们将从头训练输出层,而其余层的参数都是基于源模型的参数微调得到的。
**二、使用已经有的模型结构
2.1 实例化网络
| 1 | import torchvision.models as models |
| 2 | resnet18 = models.resnet18() |
| 3 | # resnet18 = models.resnet18(pretrained=False) 等价于与上面的表达式 |
| 4 | alexnet = models.alexnet() |
| 5 | vgg16 = models.vgg16() |
| 6 | squeezenet = models.squeezenet1_0() |
| 7 | densenet = models.densenet161() |
| 8 | inception = models.inception_v3() |
| 9 | googlenet = models.googlenet() |
| 10 | shufflenet = models.shufflenet_v2_x1_0() |
| 11 | mobilenet_v2 = models.mobilenet_v2() |
| 12 | mobilenet_v3_large = models.mobilenet_v3_large() |
| 13 | mobilenet_v3_small = models.mobilenet_v3_small() |
| 14 | resnext50_32x4d = models.resnext50_32x4d() |
| 15 | wide_resnet50_2 = models.wide_resnet50_2() |
| 16 | mnasnet = models.mnasnet1_0() |
2.2 传递pretrained参数
通过True或者False来决定是否使用预训练好的权重,在默认情况下(不写参数的情况下)pretrained = False,意味着我们不适用预训练得到的权重,当pretrained = True ,意味着我们将使用一些数据集上预训练得到的权重。
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数Linux运维工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年Linux运维全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。

既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上Linux运维知识点,真正体系化!
由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新
如果你觉得这些内容对你有帮助,可以添加VX:vip1024b (备注Linux运维获取)

后续会持续更新**
如果你觉得这些内容对你有帮助,可以添加VX:vip1024b (备注Linux运维获取)
[外链图片转存中…(img-i44XokLk-1712714346455)]















 959
959

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









