






fourierft
https://github.com/Chaos96/fourierft
Parameter-Efficient Fine-Tuning with Discrete Fourier Transform
原理
lora引入两个低秩矩阵A和B来表示权重变化。
而FourierFT将权重变化∆W视为空间域中的矩阵,并只学习其一小部分频谱系数。通过训练得到的频谱系数,实现逆离散傅立叶变换来恢复∆W。
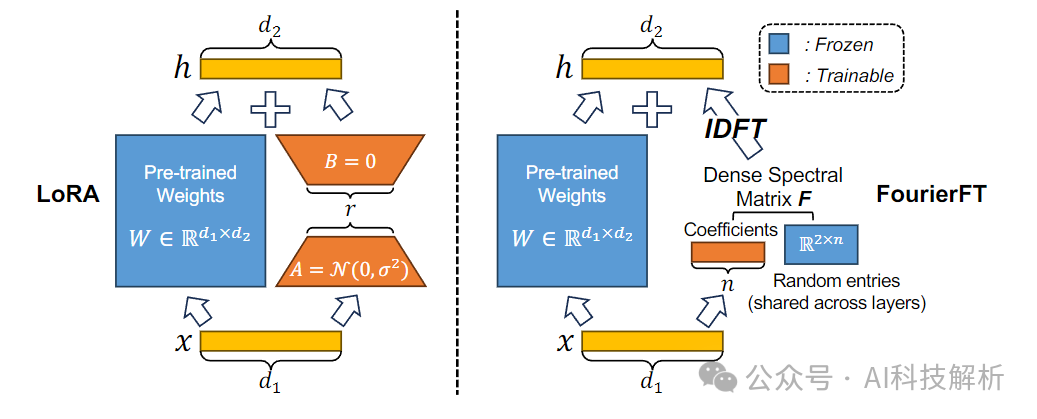
参数更少,性能堪比lora。公式如下
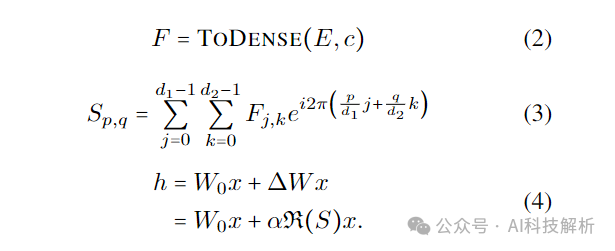
FourierLinear代码如下,在原始权重的基础上增加了傅里叶变化的权重估计。

效果
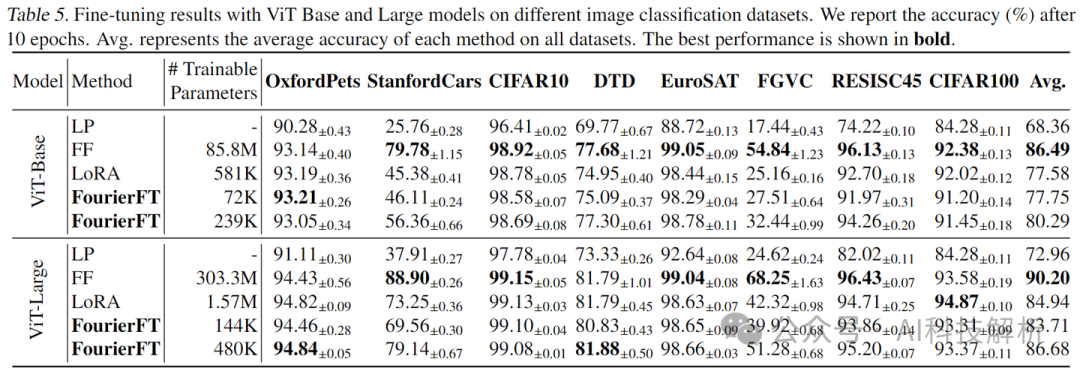
性能方面。使用 LoRA 参数数量的10%左右即可获得匹配的性能。当 FourierFT 的参数数量增加到 LoRA 的 41.1%时,它的性能可以优于LoRA。
MoRA
https://github.com/kongds/MoRA
MoRA: High-Rank Updating for Parameter-Efficient Fine-Tuning
原理
LoRA低秩更新矩阵 ΔW 很难估计 FFT 中的满秩更新,特别是在内存密集型任务中,例如需要记住特定领域知识的持续预训练(学得慢忘的也慢),微调性能低于FFT。
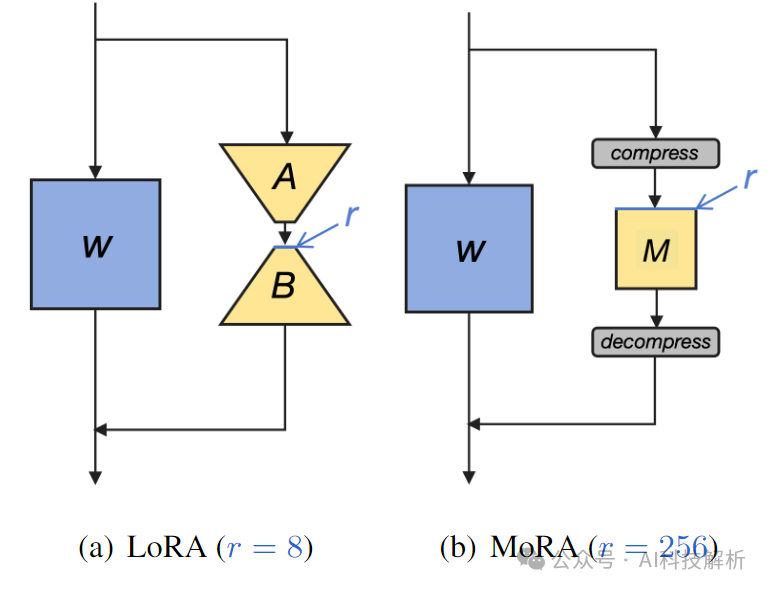
MoRA使用方阵而非低秩矩阵来实现高秩更新,同时保持相同数量的可训练参数。MoRA引入了相应的非参数化算子来减少输入维度和增加输出维度,确保权重可以像LoRA一样被合并回LLMs。代码如下:https://github.com/kongds/MoRA/blob/main/peft-mora/src/peft/tuners/lora/layer.py
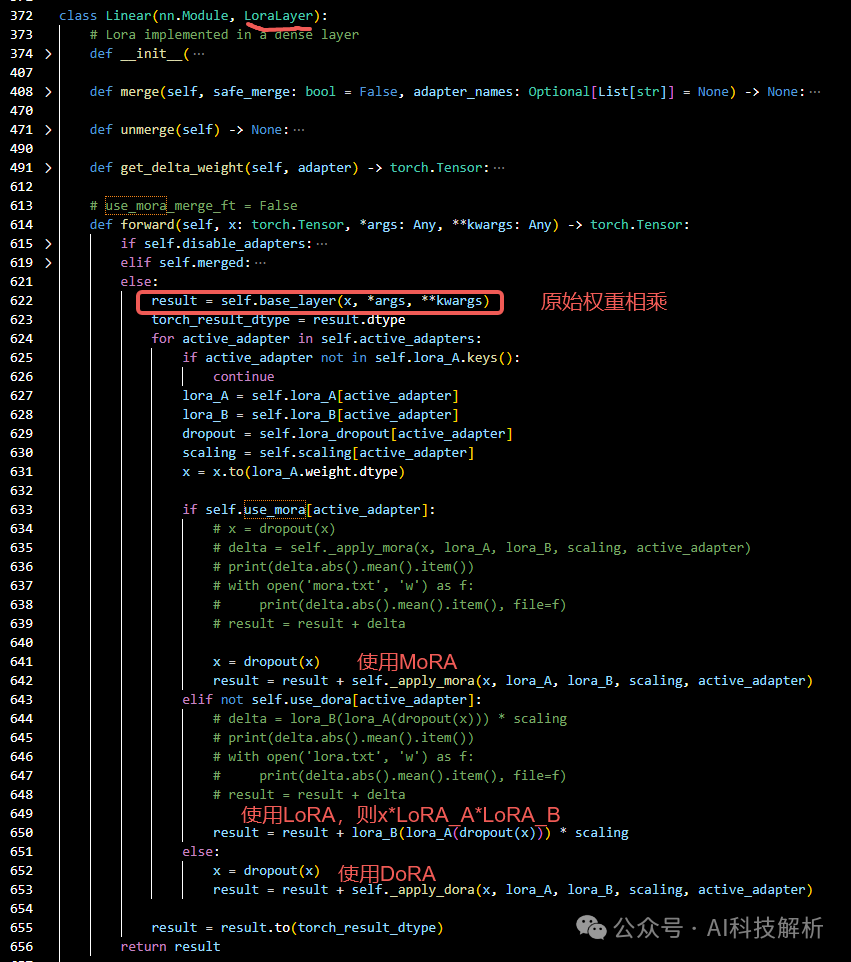
MoRA代码如下
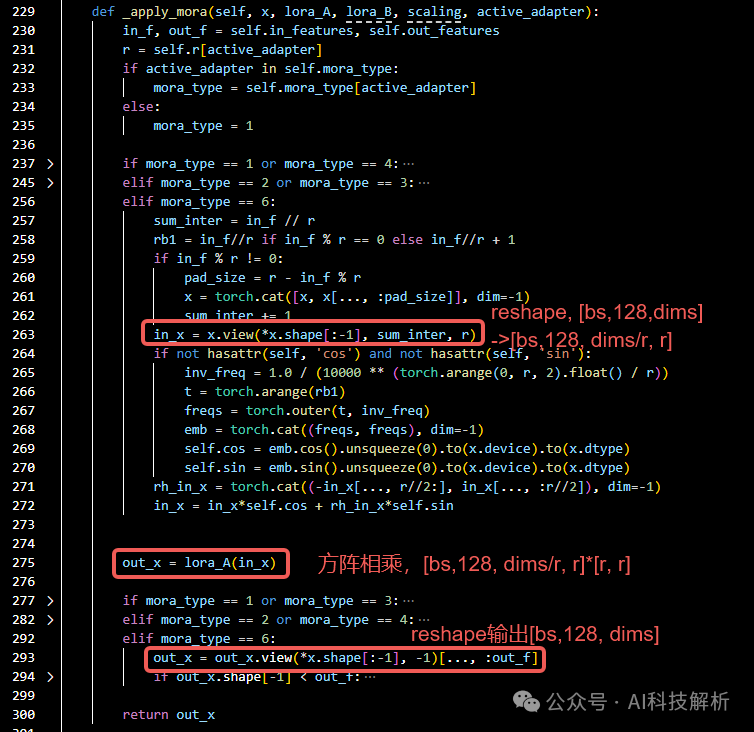
DoRA代码如下
效果
MoRA微调的loss比LoRA更低。
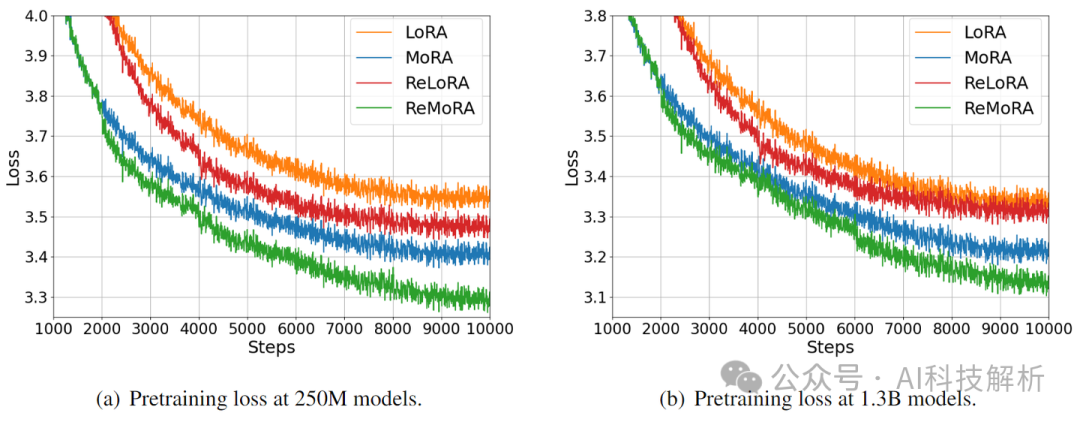
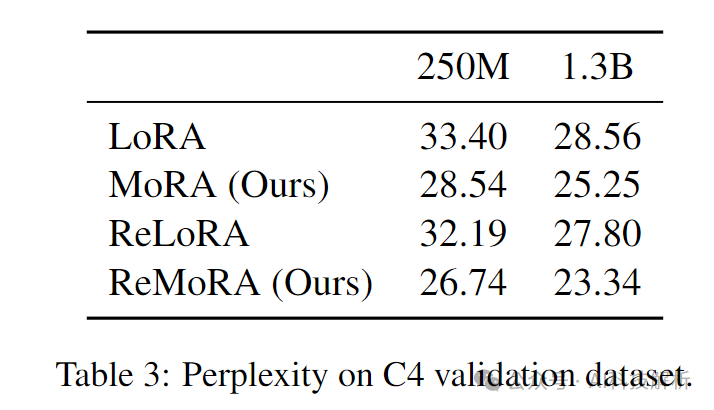
MoRA的PPL也更低。
MoSLoRA
https://github.com/wutaiqiang/MoSLoRA/tree/main
Mixture-of-Subspaces in Low-Rank Adaptation
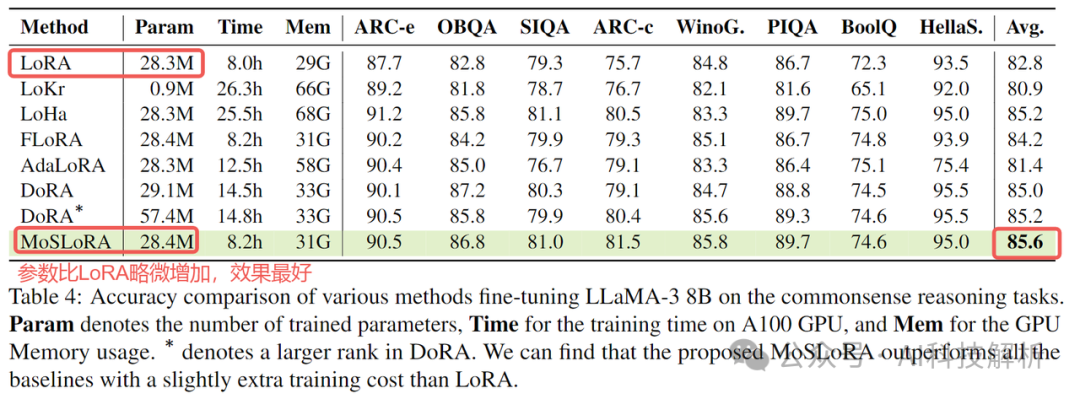
介于LoRA是x*LoRA_A*LoRA_B的样式,测试发现:若能够简单地混合,可以提高性能。
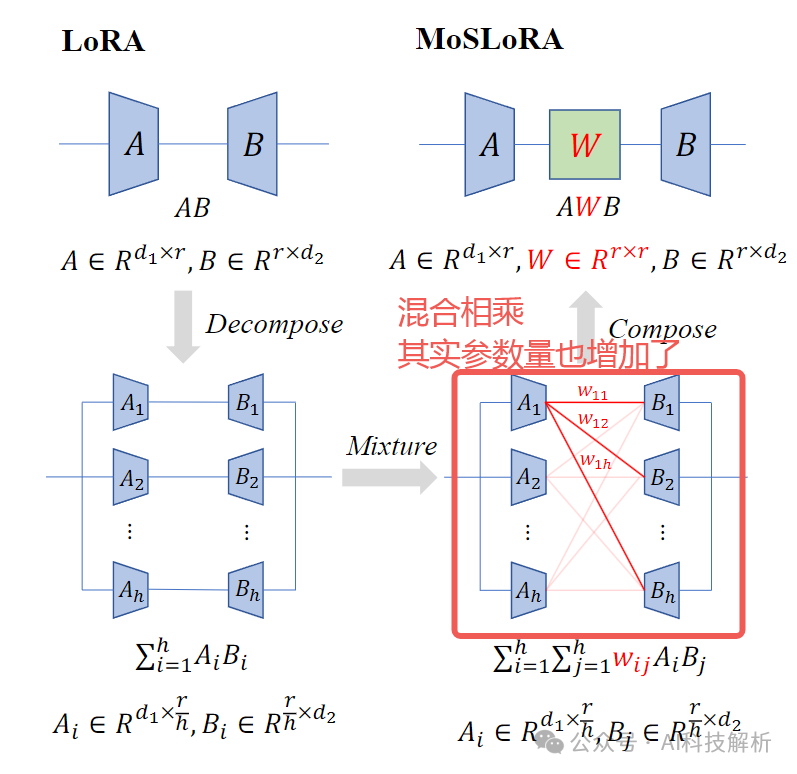
原理
设置多个LoRA_A和LoRA_B
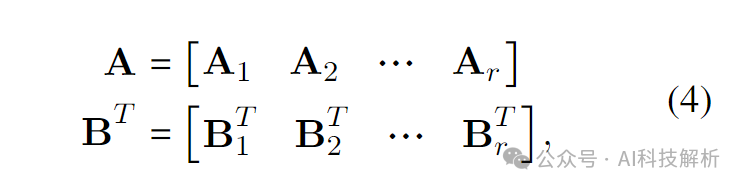
那么LoRA_A和LoRA_B的累成可以写为
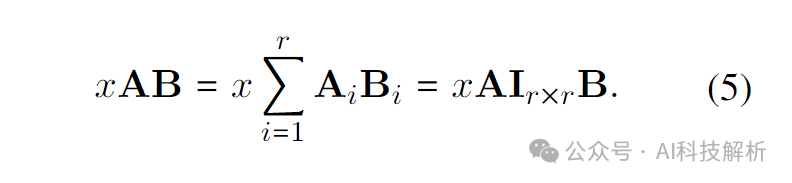
拆解可以得到矩阵相乘的形式
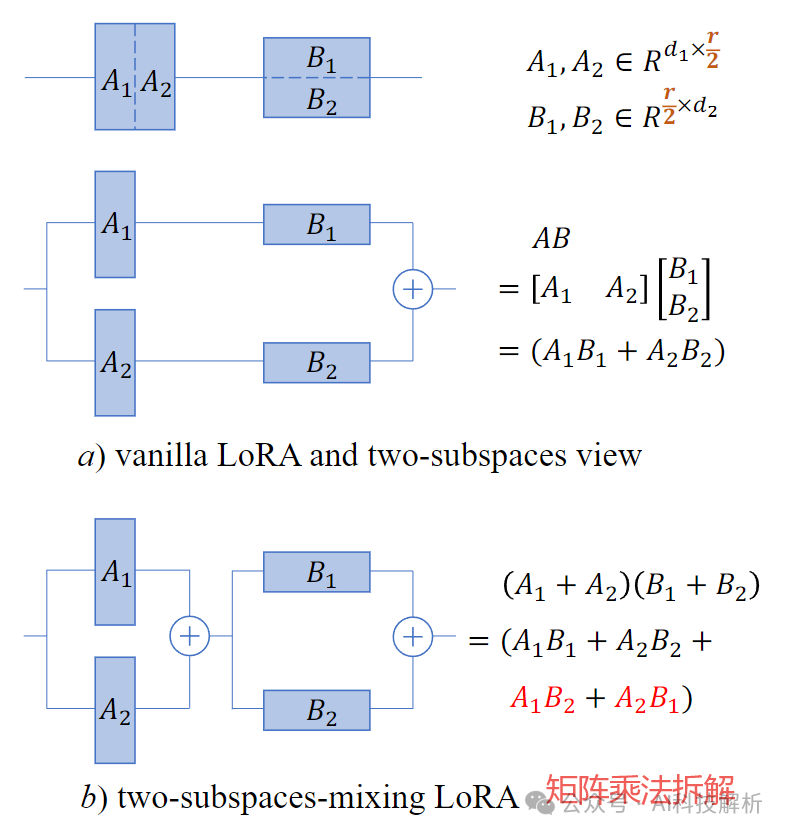

因此最终的实现极为在LoRA_A和LoRA_B之间增加一个LoRA_AB矩阵。
https://github.com/wutaiqiang/MoSLoRA/blob/main/commonsense_reasoning/peft/src/peft/tuners/lora.py
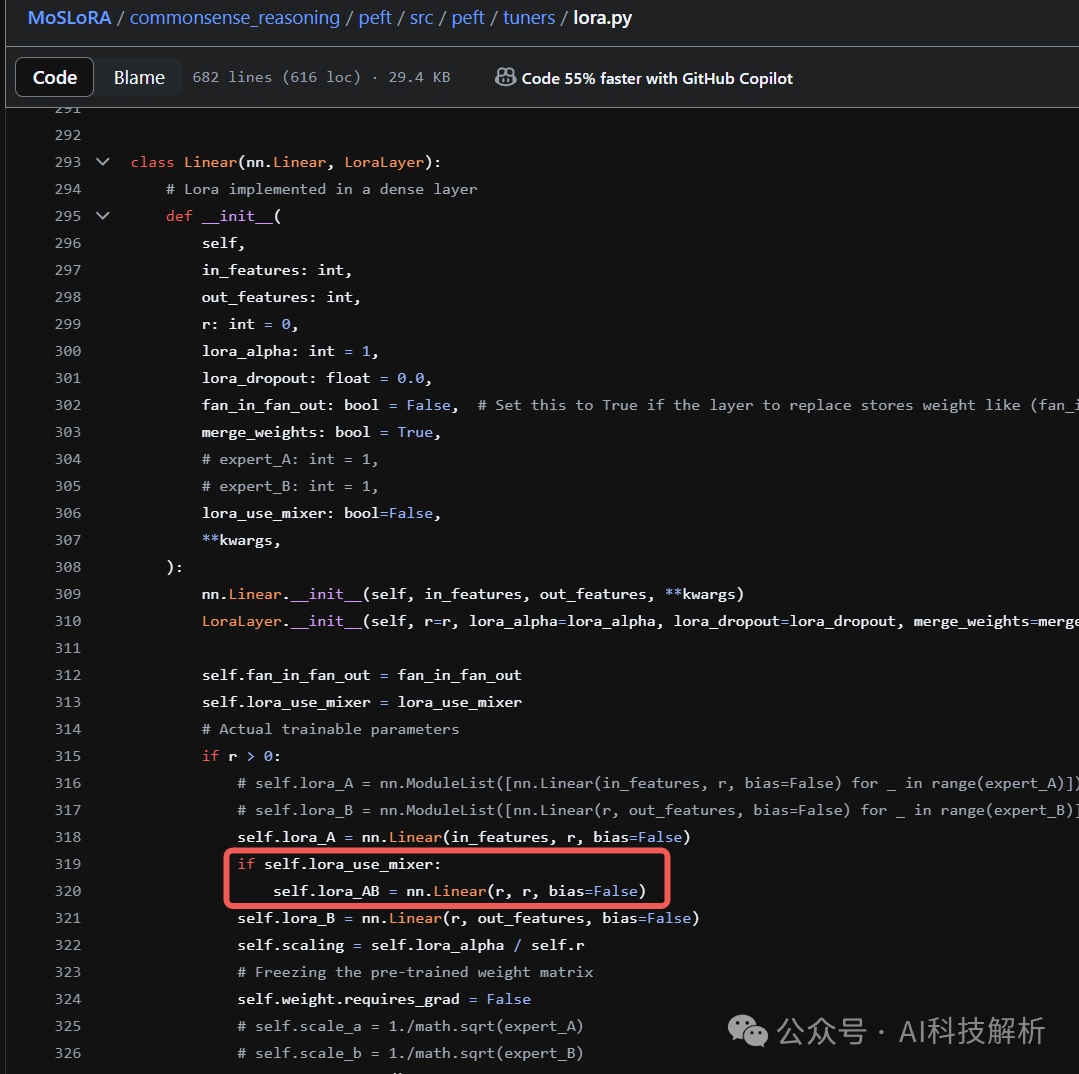
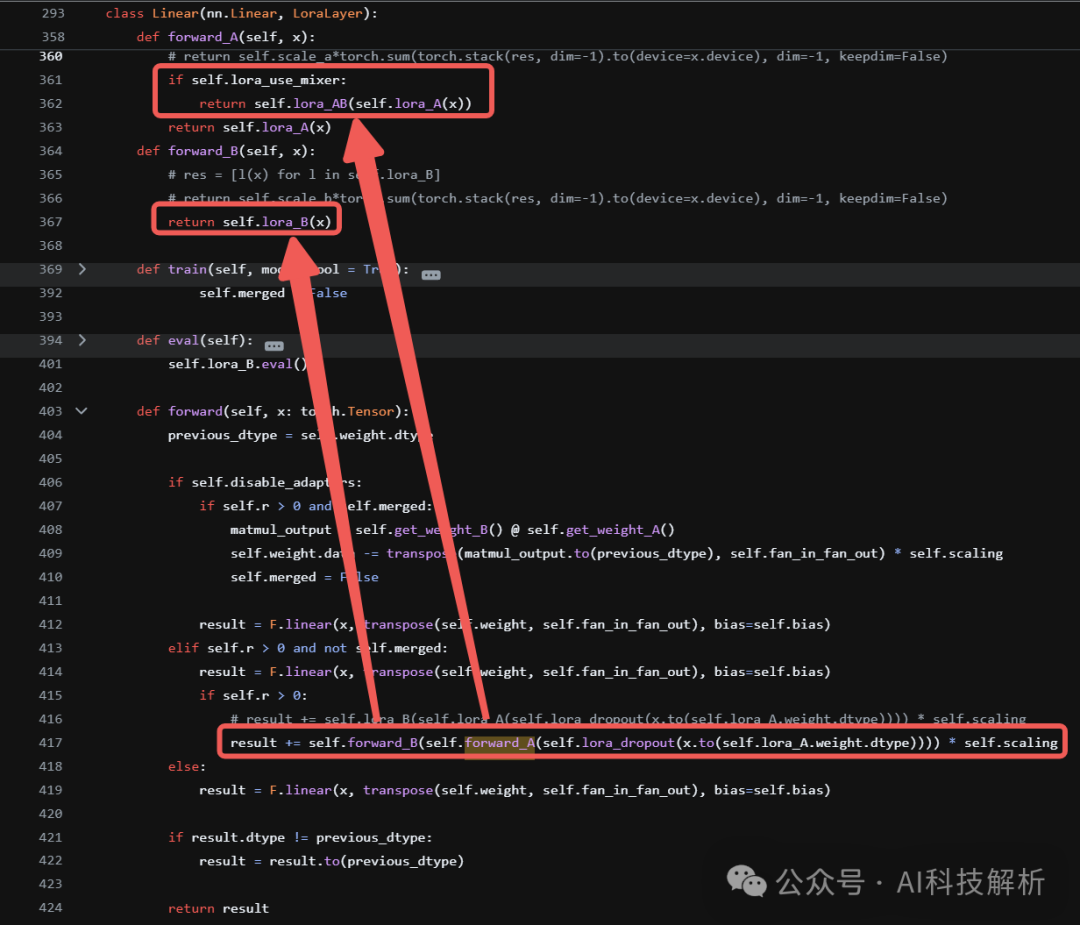
在前向推理时逐个累乘即可(x*LoRA_A*LoRA_AB*LoRA_B)。
效果
Skywork-MoE
https://github.com/SkyworkAI/Skywork-MoE
Skywork-MoE: A Deep Dive into Training Techniques for Mixture-of-Experts Language Models
昆仑万维开源的Skywork-MoE 是一个高性能的专家混合(MoE)模型,拥有1460亿参数、16个专家和220亿激活参数。该模型是基于Skywork-13B模型的Dense检查点初始化的。
引入了两项创新技术:Gating Logit Normalization,增强专家多样性;Adaptive Auxiliary Loss Coefficients,允许对辅助损失系数进行层级调整。
Auxiliary Loss
为了确保专家之间的负载均衡,并防止单个专家占据主导地位,Switch Transformer采用了辅助损耗函数,鼓励在专家之间均匀分配令牌。
设Pj是分配给专家j的令牌的比例。如果对于所有j=1,Pj=k/n,则在专家之间均衡负载loss是实际分配概率和理论分配概率之差的平方累加。
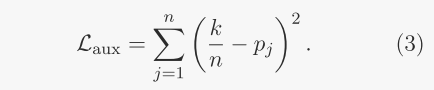
然而理论分配概率pj无法进行反向传播。因此假设pj
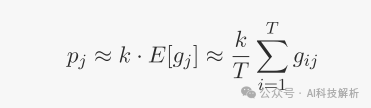
那么loss有
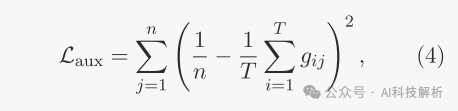
模型总loss为
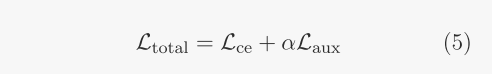
Gating Logit Normalization
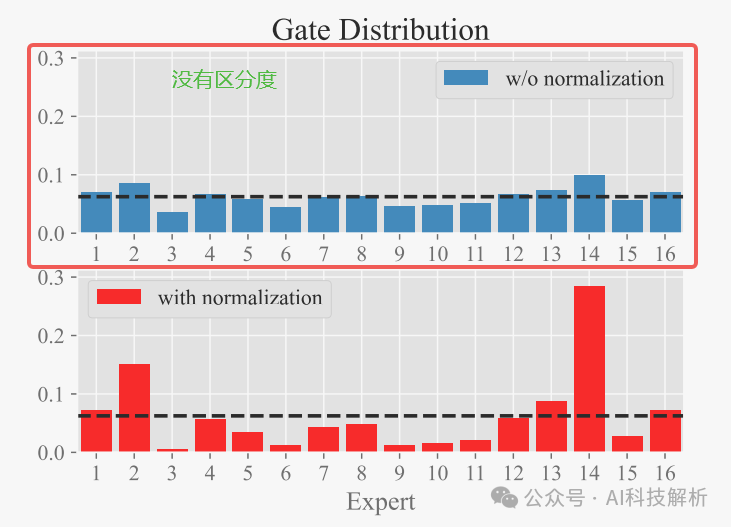
在MOE模型的训练过程中,经常观察到的一个现象是,它的gate层有时会产生高熵的分布,即被选中的专家的TOPK概率仅略大于未被选中的专家的TOPK概率(表明每个专家得分都差不多,没有区分度)。
因此,MOE层的输出近似如下,output实际上是选定专家产出的简单平均值,而不是加权平均值。
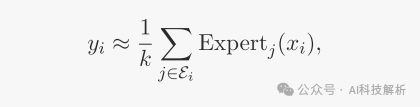
补救措施涉及在选通层中的Softmax函数之前引入归一化步骤,以确保更独特的栅极输出分布。
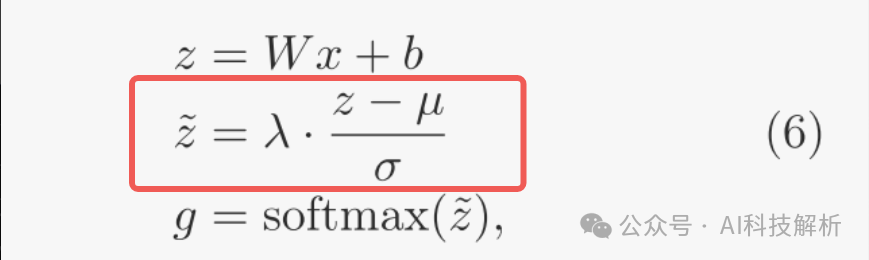
在这个修订的公式中,首先通过减去其平均值µ并除以其标准差σ来归一化向量z。然后,通过超参数λ对其进行缩放,从而得到具有零均值和由λ控制的标准偏差的变换后的向量λz。
参数λ适当地缩放输出向量˜z。具体地说,较高的λ值会导致更尖锐、更集中的分布。可以增强模型有效区分不同专家贡献的能力,从而潜在地改进教育部模型的整体性能。实验比较了使用门控Logit归一化和不使用门控Logit归一化训练的模型,并改变了超参数λ。结果表明使用门控Logit归一化训练的模型的门的输出分布比没有训练的模型明显更尖锐。然而,由于λ=1和λ=2的训练损失是相当有效的,我们选择在我们的SkyWork-MOE模型的训练中实现λ=1。
Adaptive Auxiliary Loss Coefficients
首先,由于每个选通层具有其独立的辅助损耗,因此对应于这些损耗的系数不必相同。在这方面,总损失(5)的更明确形式应为
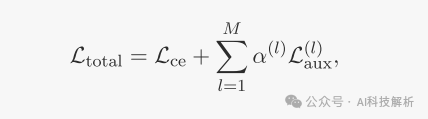
其次,如果在训练过程中已经在专家之间实现了负载均衡,则建议减小辅助损失系数以减轻负载均衡的正则化。相反,在专家之间的负载分配严重不平衡的情况下,增加系数将强制执行更严格的负载平衡规则。调整这些系数的基本原理主要是为了优先优化下一个单词预测的交叉损失,同时将负载平衡调整作为次要的、可能适得其反的目标。
基于观察到的令牌丢失率自适应地更新用于后续迭代的系数。丢失系数的更新被设计为与令牌丢失率正相关。
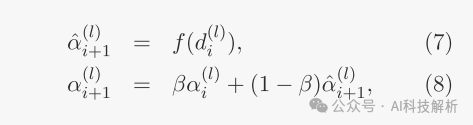
其中:f是将当前观察到的令牌丢失率d(L)i映射到下一迭代的估计辅助损耗ˆα(L)i+1的递增函数。·α(L)i+1表示ˆα(L)i+1的移动平均值,作为下一次迭代的实际辅助损耗系数。这种移动平均方法减轻了正则化强度的突变。·β是一个在(0,1)范围内的参数,它平衡了现有移动平均值和新估计值之间的权重。在我们的具体实现中,我们定义f(D)=ξd用于某个ξ>;0,其约束是f(D)不超过最大值Cmax。这会产生分段线性函数:
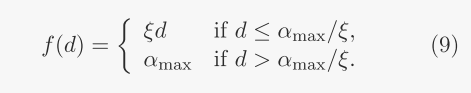
超参数ξ调节损失系数对令牌丢失率的敏感度。在Skywork MoE模型的训练过程中,我们设置了ξ=1/5、αmax=0.01和β=0.99。这种配置有效地将令牌丢失率和辅助损失系数都保持在所需的水平。
效果评估
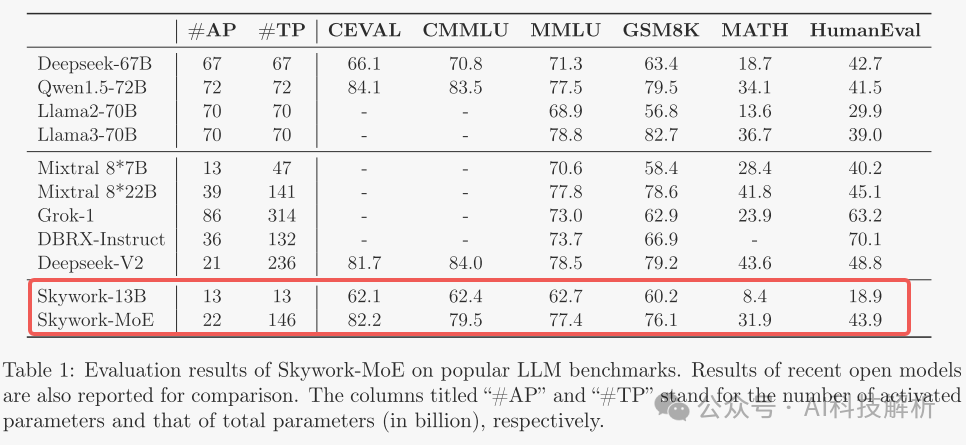
效果不错,得分都很高。
Yuan2.0-M32
Yuan 2.0-M32: Mixture of Experts with Attention Router
https://github.com/IEIT-Yuan/Yuan2.0-M32
浪潮信息开源的“源2.0 M32”大模型。采用稀疏混合专家架构(MoE),以Yuan2.0-2B模型作为基底模型,通过创新的门控网络(Attention Router)实现32个专家间(Experts*32)的协同工作与任务调度,在显著降低模型推理算力需求的情况下,带来了更强的模型精度表现与推理性能。
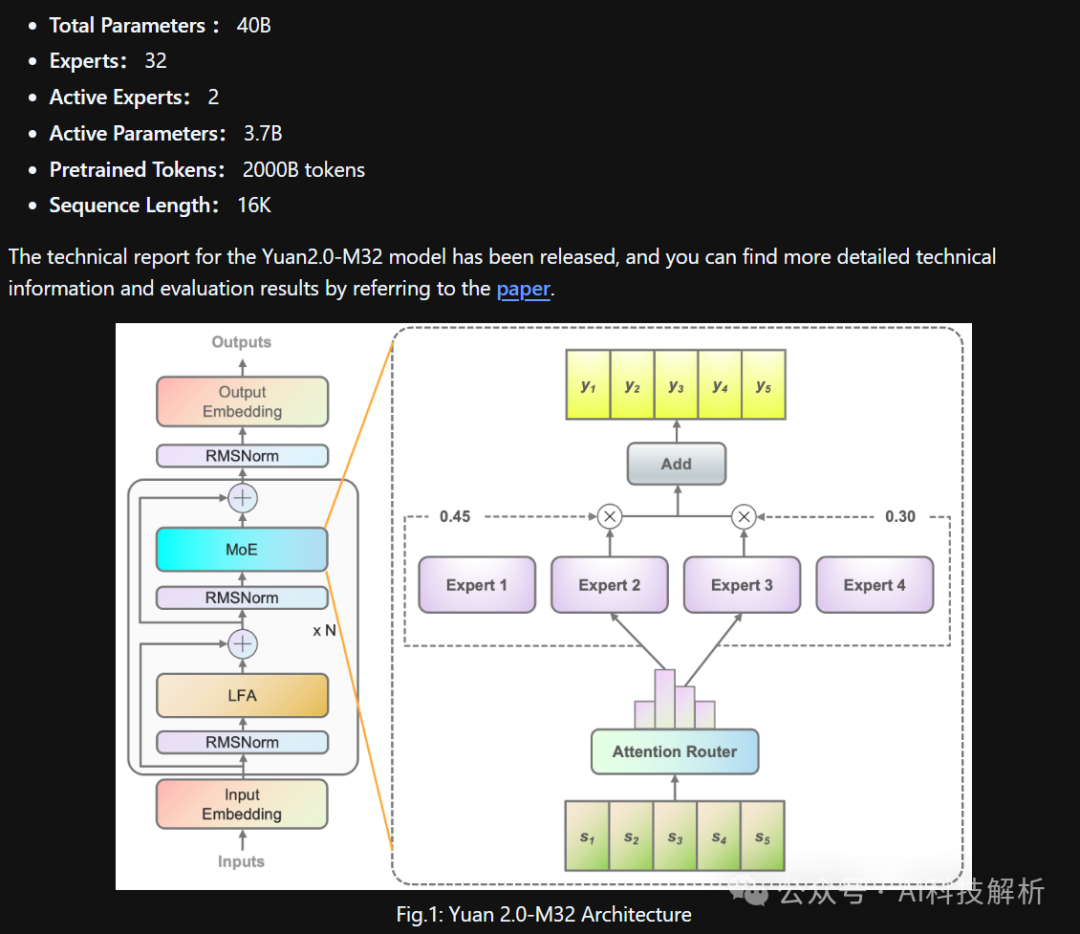
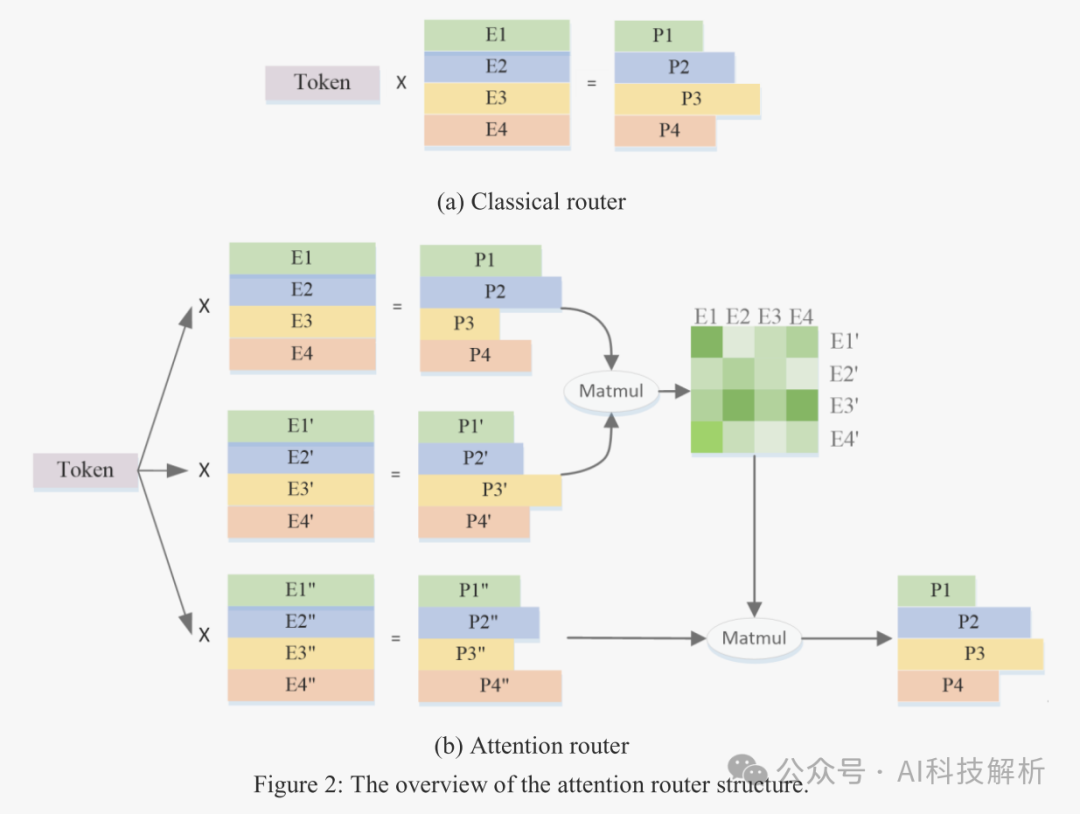
Classical router、Shared Expert router和Attention router对比
Classical router网络的结构如下所示。每个专家的特征向量相互独立,在计算概率时忽略了专家之间的相关性。通常会选择两个或两个以上的专家参与后续计算,这自然会带来专家之间的强相关性。专家间相关性的考虑无疑将有助于提高准确率。
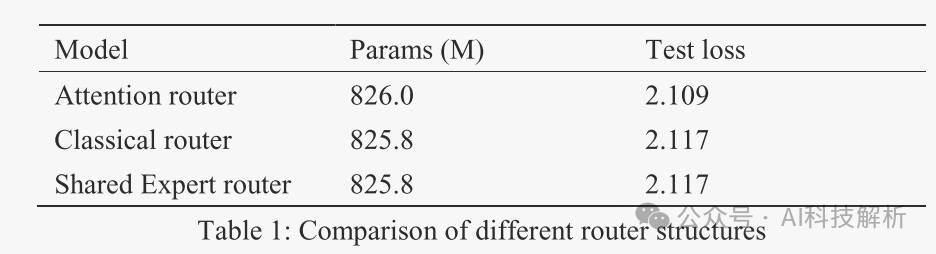
Classical router和Shared Expert router的测试结果,发现后者的测试损失完全相同,而训练时间增加了7.35%。Shared Expert的计算效率相对较低,与经典的MOE策略相比,并没有带来更好的训练精度。因此,在我们的模型中,我们采用Classical router,没有任何共享的专家。与经典的Attention router网络相比,测试损耗提高了3.8%。
Expert数量测试
增加专家数量和固定每个专家的参数大小来测试模型的可扩展性,激活专家数目不变。
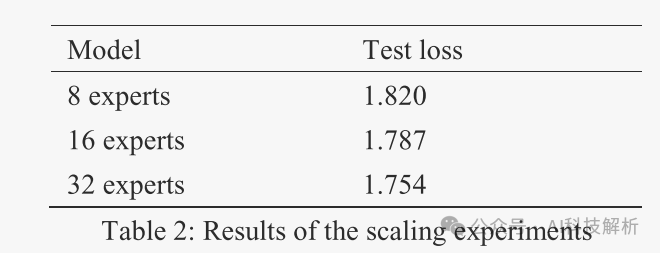
专家数目越多,模型loss越低(毕竟数据不变,参数量增加了,模型质量也会变高)。但专家数目增加会增加训练成本。
训练和微调
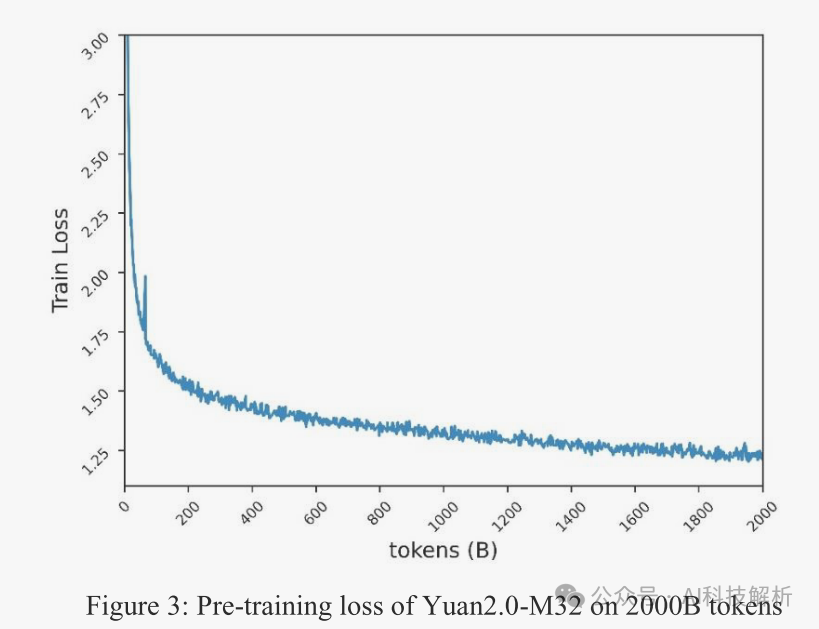
预训练数据

在微调过程中,将序列长度延长到16384。重置了旋转位置嵌入(ROPE)频率的基值,以避免较长序列的注意力分数下降。不是简单地将基值从1000增加到一个更大的值,而是使用NTK感知计算新的基数,即𝑏‘=𝑏∙𝑠|𝐷||𝐷|−2。其中,𝑏是原始基准值(b=10000)。𝑠是从原始上下文长度到扩展上下文长度的扩展次数。当我们将上下文长度从4096扩展到16384时,S等于4。|𝐷|在我们的设置中是128。因此,新的基本𝑏‘被计算为40890。
/>
/> 微调数据集

效果评估
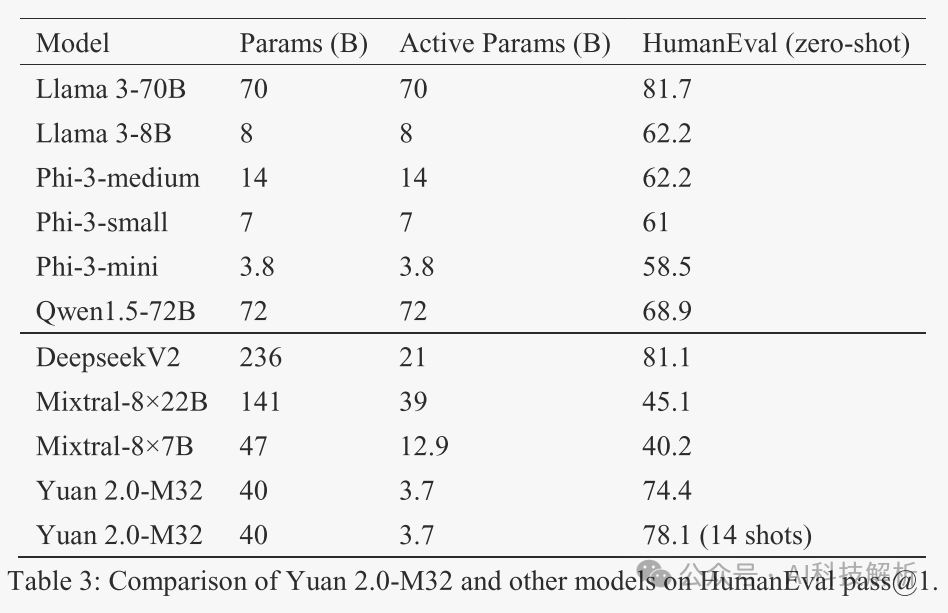
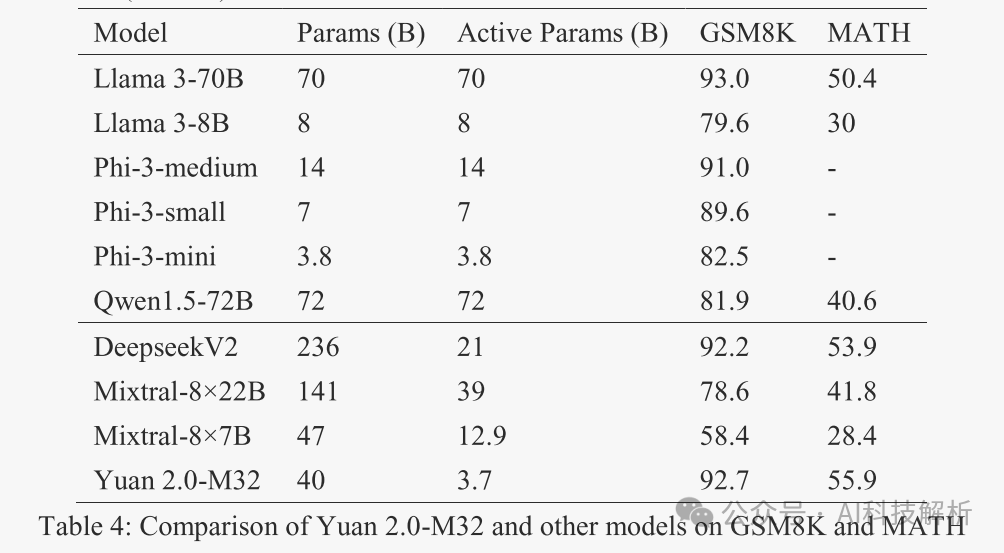
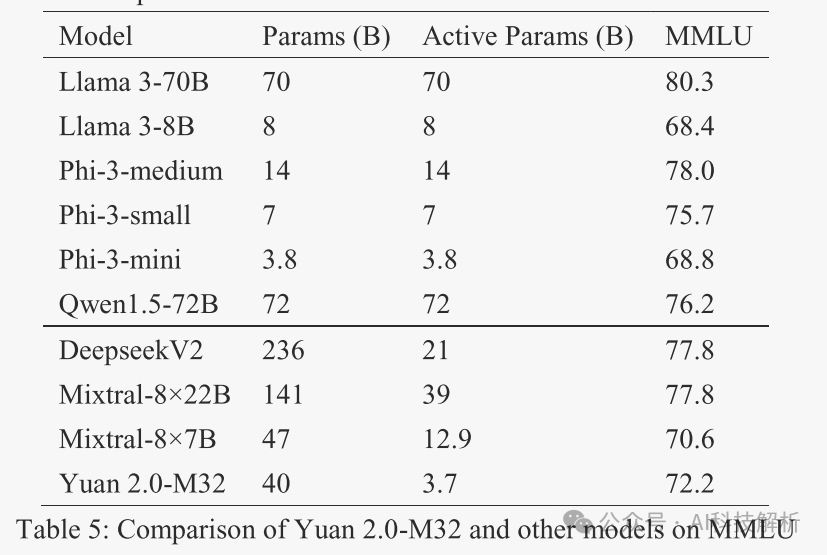
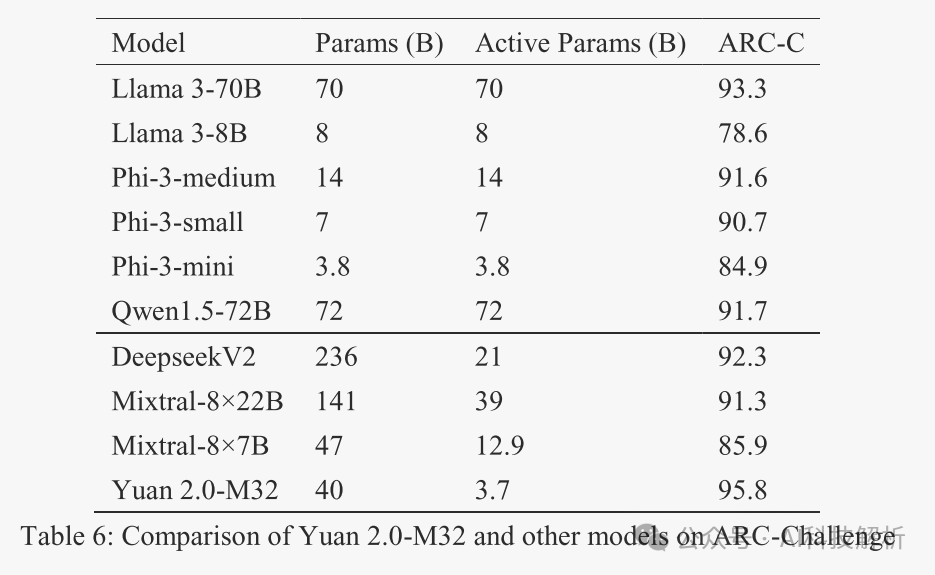
性价比超高。使用了1/10不到的激活量(3.7B),大部分榜单可以媲美70B的Llama-3。
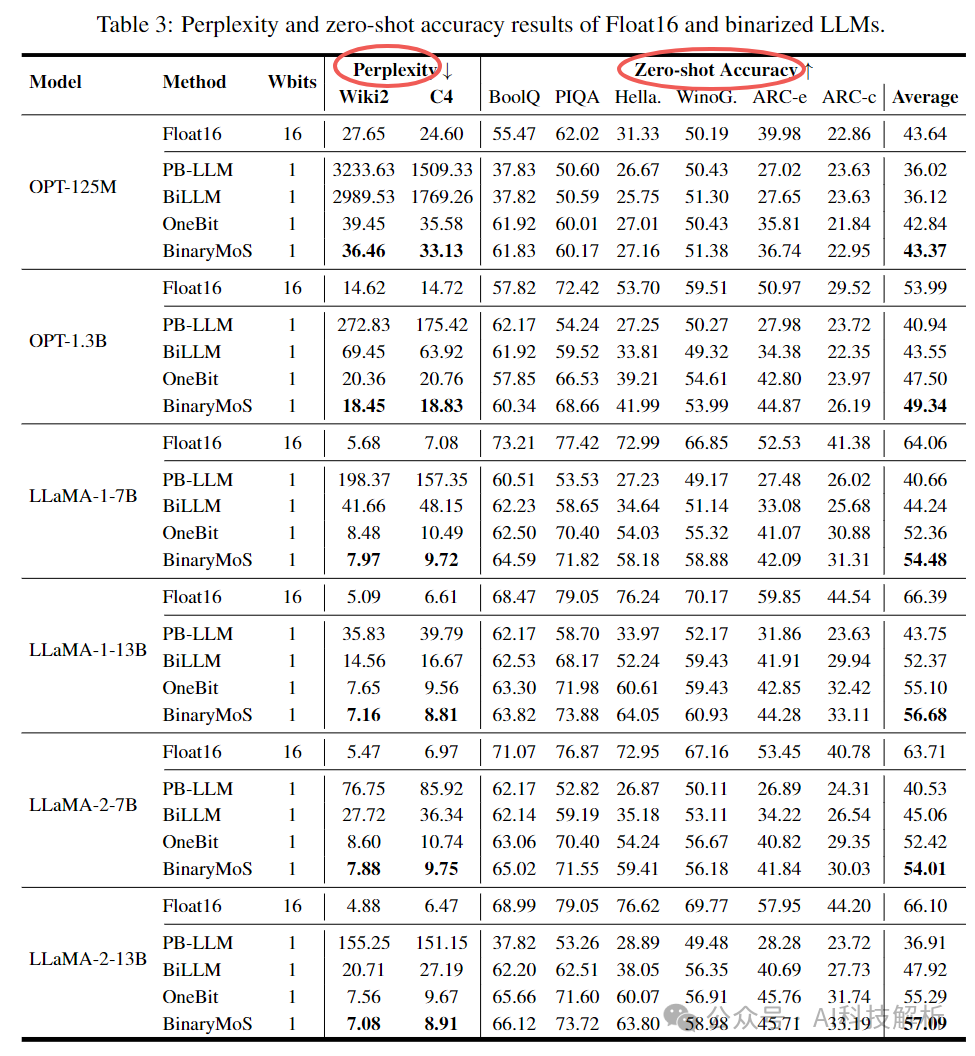
BinaryMoS
Mixture of Scales: Memory-Efficient Token-Adaptive Binarization for Large Language Models
OneBit
OneBit: Towards Extremely Low-bit Large Language Models
https://github.com/xuyuzhuang11/OneBit
https://zhuanlan.zhihu.com/p/686468702
将W矩阵拆分成两个一维线性层和二值权重,在大幅降低参数量的基础上,减少了精度损失。
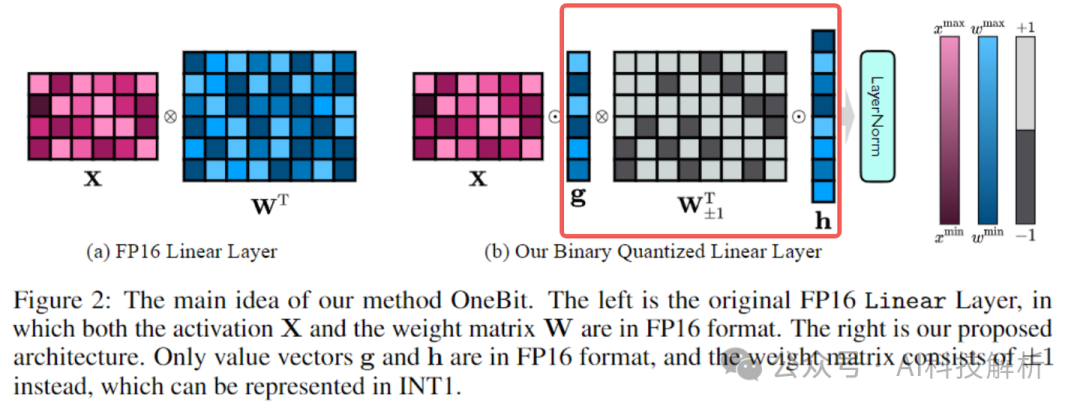
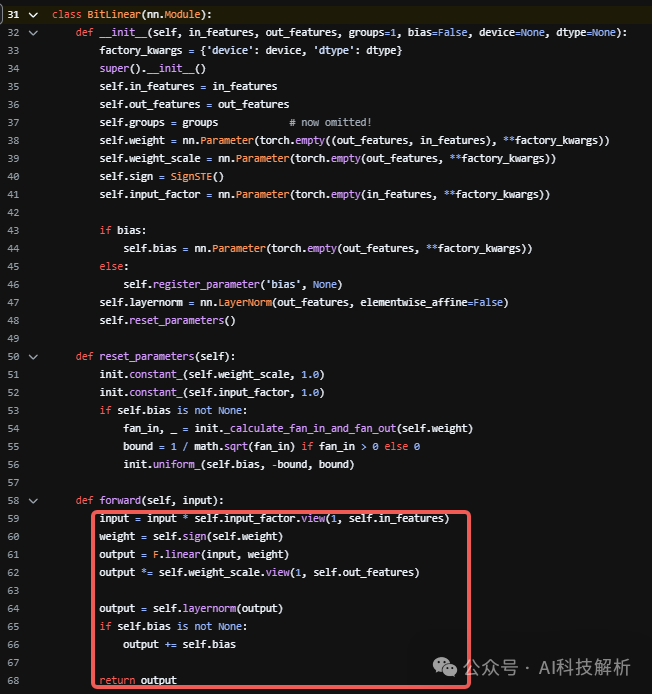
代码实现如下
BinaryMoS=OneBit+MOE
BinaryMoS是在OneBit的基础上,结合了MOE的特点,将单个的一维线形层改成了多个,并通过Router机制进行选择。
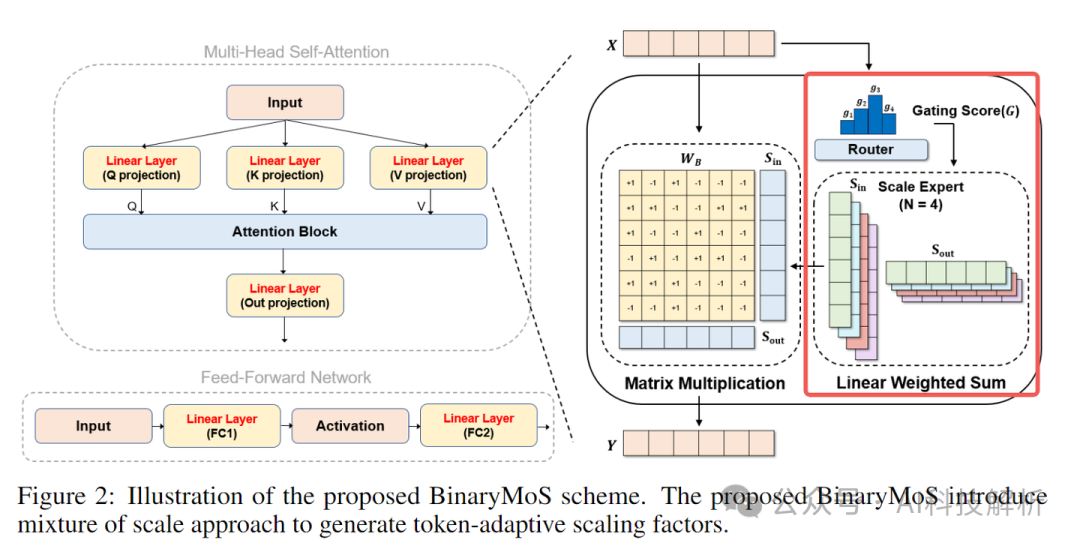
在仅增加少量参数的情况下,实现了更低的PPL效果和更高的精度。
Abacus Embedding
Transformers Can Do Arithmetic with the Right Embeddings
https://github.com/mcleish7/arithmetic
提出了一种新的位置嵌入,称为Abacus Embeddings,以更好地捕捉每个数字的重要性,优化大模型的数学计算问题。
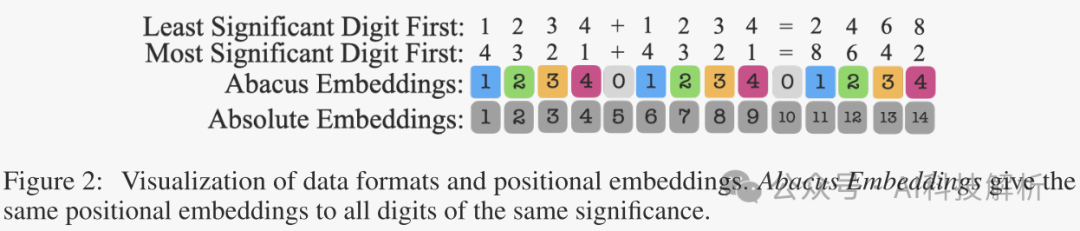
由于加法对位数比较敏感,因此以前有提出在加法的输入和输出中提出明确的索引提示,例如a6b7c5 + a1b6c3 = a7b3c9,结果表示在这种提供信息场景,加法执行得更好。但是增加了token长度,增加了内存消耗和计算量。我们设计了一个专门构建的位置嵌入,它对每个数字相对于当前数字开头的位置进行编码。我们称之为算盘嵌入。对数字中的每个数字进行给予连续的位置嵌入,例如,如果输入是123,则位置编码是β,β + 1,β + 2。
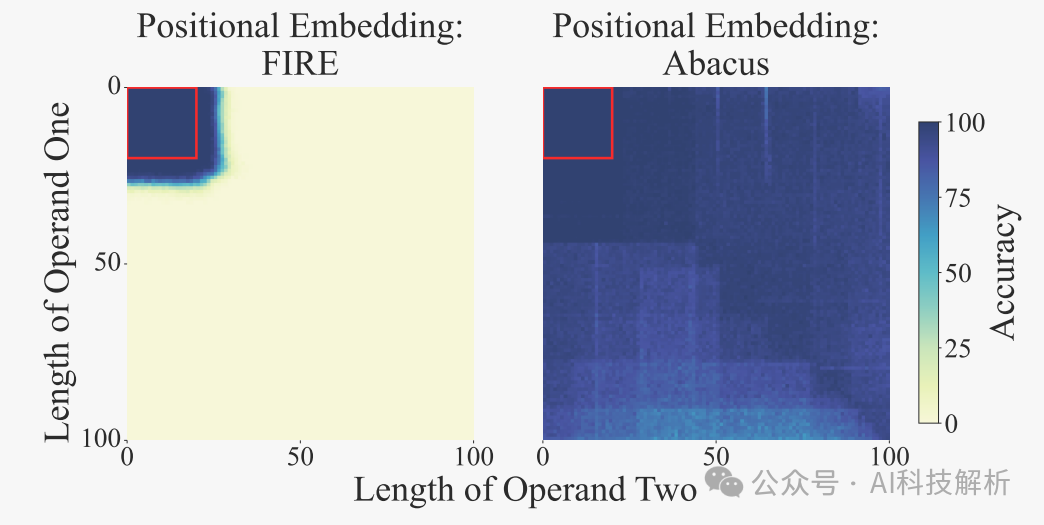
原理
https://github.com/mcleish7/arithmetic/blob/main/abacus.py
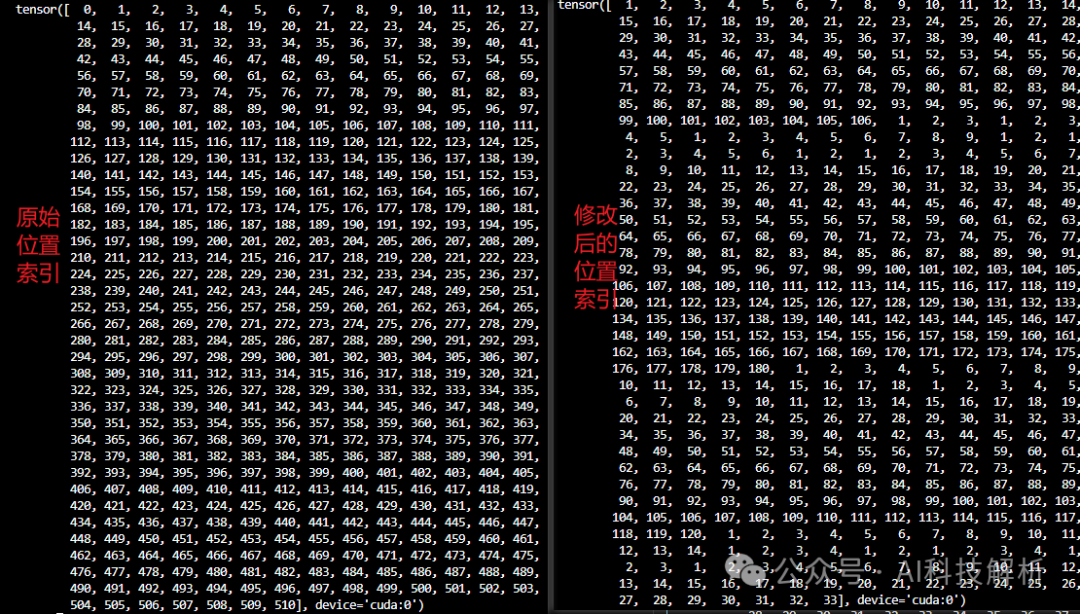
1、首先根据torch.isin函数判断token中是否包含0-9数字 2、然后获取数字的起始位置,设为True。
shifted_mask = torch.cat([torch.zeros((mask_shape[0], 1), device=device, dtype=mask.dtype), mask[:, :-1]], dim=1)
starts = (shifted_mask != mask) & mask # 可以找到数字的起始位置
3、生成position索引,根据数字起始位置重置索引结果。效果如下图。
# Generate IDs for each segment of 1s, processing row-wise
segment_ids = torch.cumsum(starts, dim=1) # 每行累加True
# Generate an index array row-wise
index = torch.arange(mask.size(1)).repeat(mask.size(0), 1).to(device) # 每一行建立\[0,1,2,....\]的位置索引
# Reset index at the start of each segment
reset\_index = torch.zeros\_like(mask).long()
second\_term = index \* starts.long() # 索引\*mask
reset\_index = reset\_index.scatter\_add(1, segment\_ids, second\_term) # 把second\_term的数字按segment\_ids顺序排列,后面补0.
# Calculate positions in segment
positions = index - reset\_index.gather(1, segment\_ids) + 1
结合算盘嵌入和标准位置嵌入,显著提高了模型的准确性。

RetNet
https://github.com/Jamie-Stirling/RetNet
Retentive Network: A Successor to Transformer for Large Language Models
RetNet就是将传统的softmax注意力机制变成了线性注意力。
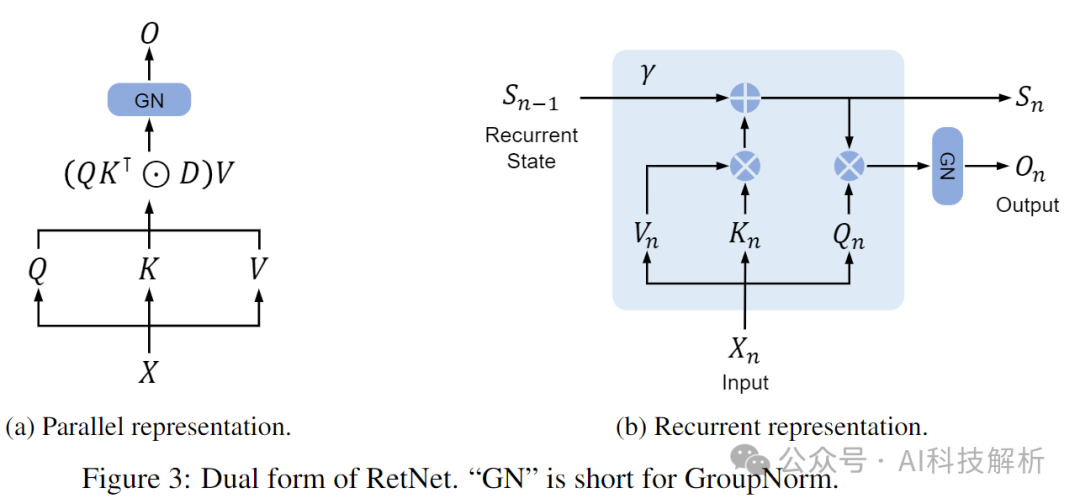
代码
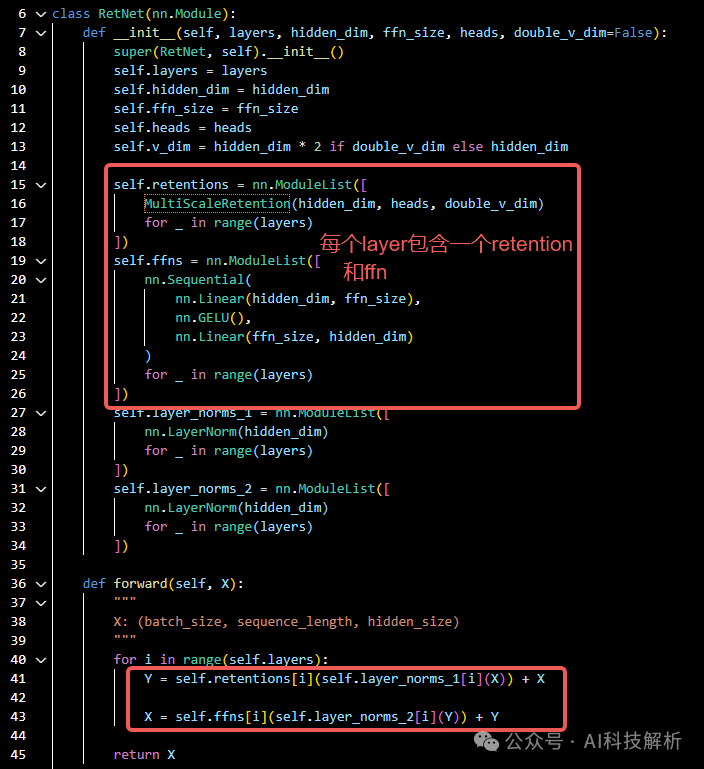
RetNet
在MultiScaleRetention中包含多个SimpleRetention模块,代替原本Attention模块的head。最终将多个模块的结果cat到一起。
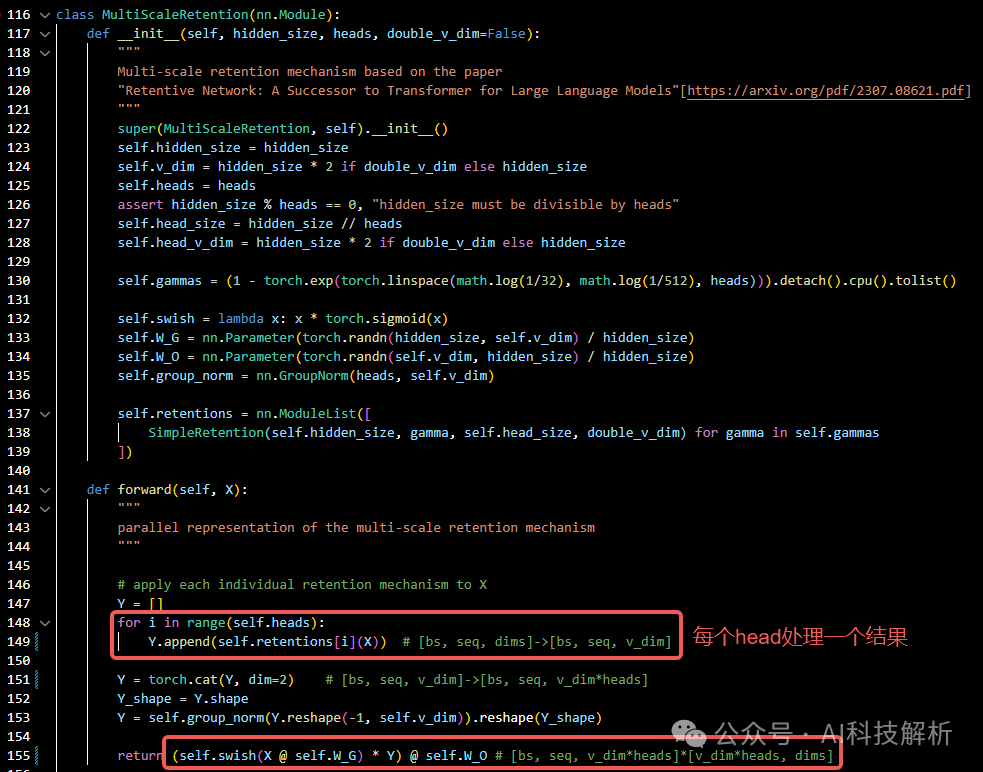
MultiScaleRetention
SimpleRetention是线性Attention实现。
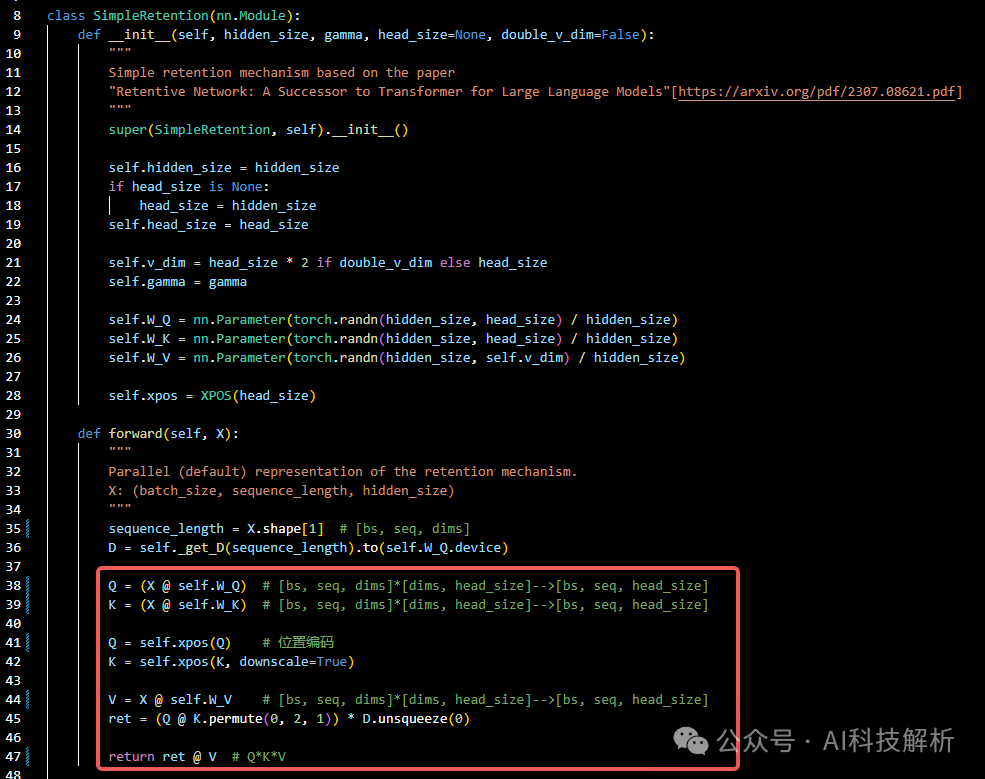
SimpleRetention
效果评估
随着模型的增大,Perplexity 会越来越低。
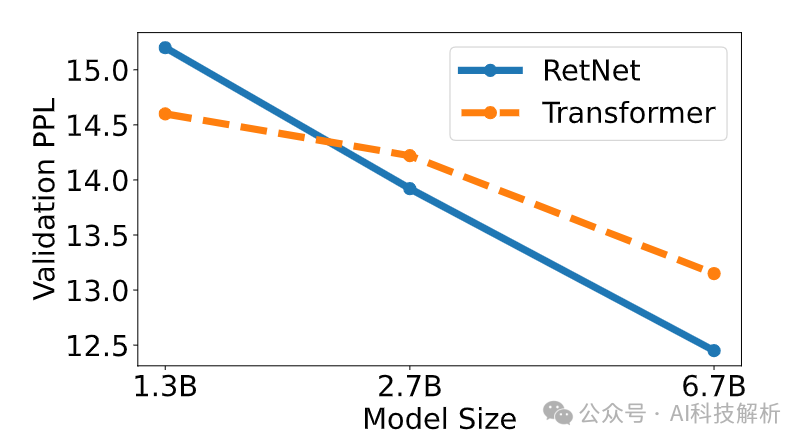
Perplexity
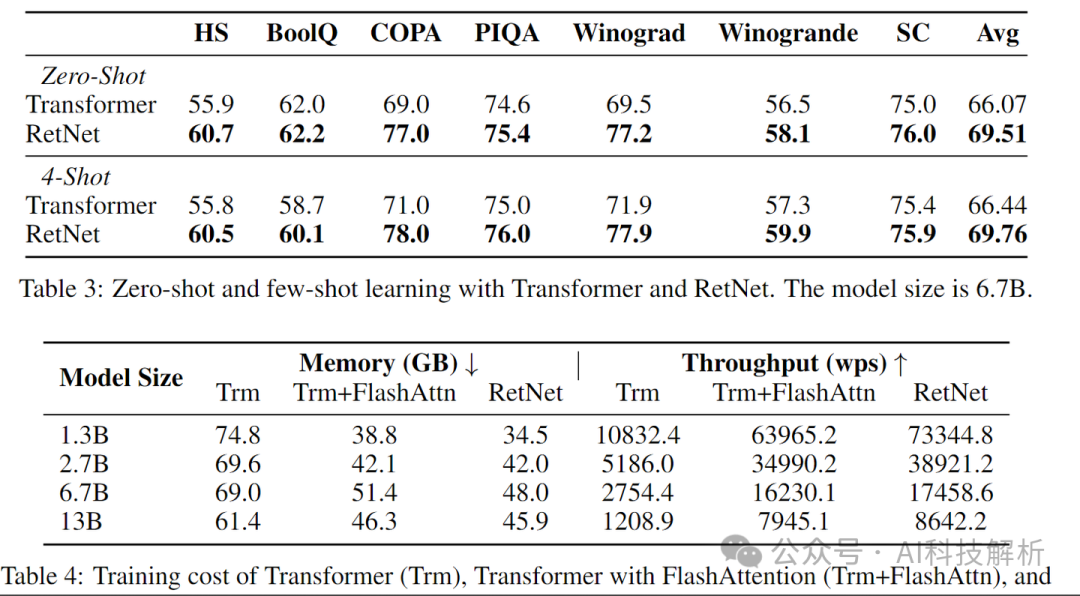
在参数量相同的情况下,计算速度更快,吞吐量更高,模型评分也不错。
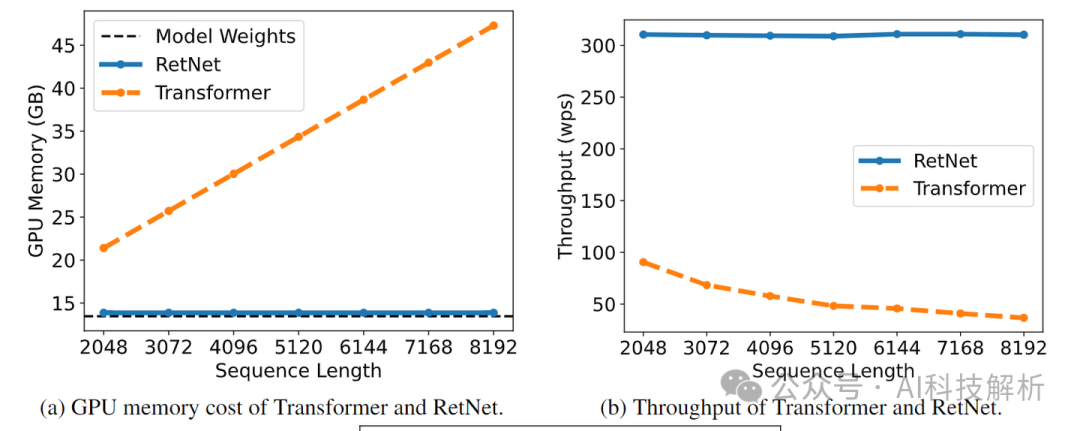
GPU memory cost和Throughput 都很高。
整体效果都很好,但其实质量上还有待继续探索。
如何学习AI大模型?
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。
本文转自 https://blog.csdn.net/xiangxueerfei/article/details/140085266?spm=1001.2014.3001.5501,如有侵权,请联系删除。















 100
100

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









