






Transformer模型是一种基于自注意力机制的神经网络架构,广泛应用于自然语言处理任务,如机器翻译、文本摘要等。
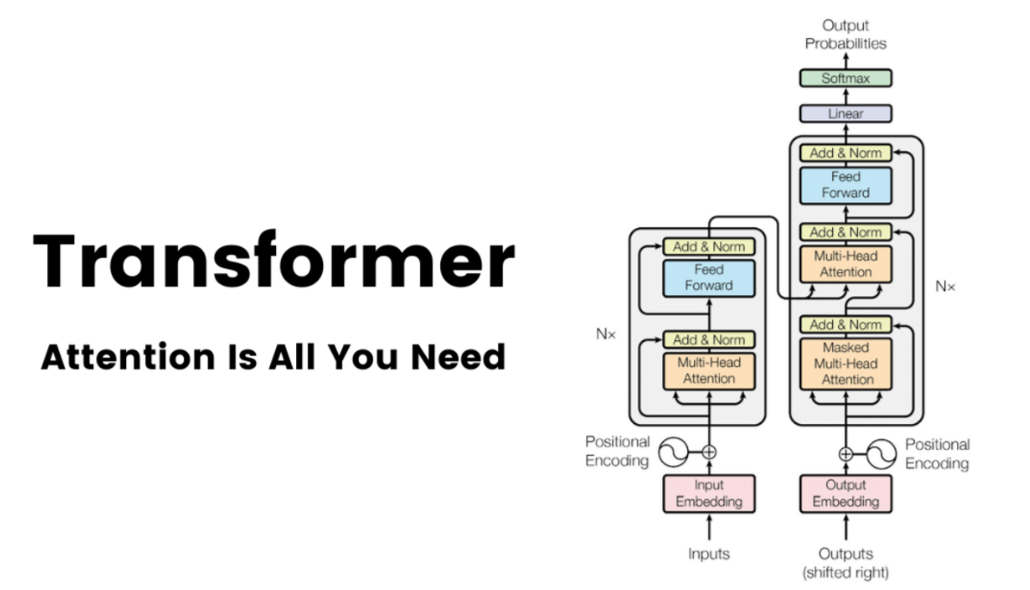
Transformer模型在多模态数据处理中扮演着重要角色,其能够高效、准确地处理包含不同类型数据(如图像、文本、音频等)的多模态数据。

Transformer多模态
下面是对四种多模态任务的简要介绍:
Voice-to-Text(语音到文本):
- Transformer模型在语音识别(ASR)领域的应用中,通过其自注意力机制能够捕捉语音序列中的长程依赖关系,从而提高语音识别的准确率。此外,Transformer模型并行计算的能力也使得其在处理大规模语音数据时具有更高的效率。
- 在实际应用中,基于Transformer的ASR模型通常包括一个编码器和一个解码器。编码器负责将输入的语音序列转换为高层次的特征表示,而解码器则根据这些特征表示生成对应的文本序列。通过大量的训练数据,模型可以学习到语音和文本之间的映射关系,从而实现语音到文本的转换。
- Conformer结合了Transformer和卷积神经网络(CNN)的优势,通过引入卷积操作来捕捉局部依赖关系,同时使用Transformer的自注意力机制来处理长程依赖。
- Conformer在语音识别任务中取得了显著的性能提升,尤其是在处理长序列和复杂语音时。

Conformer模型的架构
https://arxiv.org/pdf/2005.08100
*神经网络算法 - 一文搞懂Conformer模型(还在路上,尽情期待)*
*Text-to-Voice(文本到语音):*
- 在文本到语音(TTS)任务中,Transformer模型同样发挥着重要作用。与ASR任务相反,TTS任务的目标是根据输入的文本序列生成对应的语音序列。基于Transformer的TTS模型通常采用自回归的方式,即根据已生成的语音序列预测下一个音节的输出。
- 为了实现高质量的语音合成,基于Transformer的TTS模型通常还需要结合一些语音生成技术,如波形生成算法、声学模型和声码器等。通过这些技术的结合,可以生成自然流畅的语音输出。
- FastSpeech 2是基于Transformer的文本到语音模型,它通过非自回归的方式直接生成整个语音序列,提高了生成速度。
- FastSpeech 2模型采用了自注意力机制和相对位置编码,能够捕捉文本中的长期依赖关系,并生成自然流畅的语音。
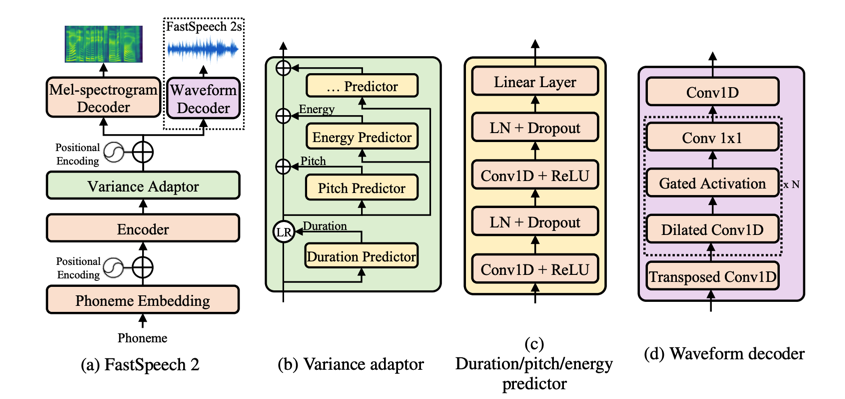
FastSpeech 2模型的架构
*https://arxiv.org/pdf/2006.04558*
*神经网络算法 - 一文搞懂FastSpeech 2模型(还在路上,尽情期待)*
*Text-to-Image(文本到图片)*:
- 在文本到图像(T2I)任务中,Transformer模型通过学习文本和图像之间的语义对应关系,实现了根据文本描述生成对应图像的功能。这种技术在创意设计、广告制作等领域具有广泛的应用前景。
- 为了实现T2I任务,基于Transformer的模型通常需要一个编码器来提取文本的特征表示,以及一个解码器或生成器来根据这些特征表示生成图像。此外,为了提高生成的图像质量和多样性,还需要采用一些生成对抗网络(GAN)等技术进行优化。
- DALL-E 2是OpenAI开发的一种基于Transformer的文本到图像生成模型,它能够根据文本描述生成高质量的图像。
- DALL-E 2使用了离散的文本和图像表示,通过Transformer的自注意力机制来捕捉文本和图像之间的语义对应关系。
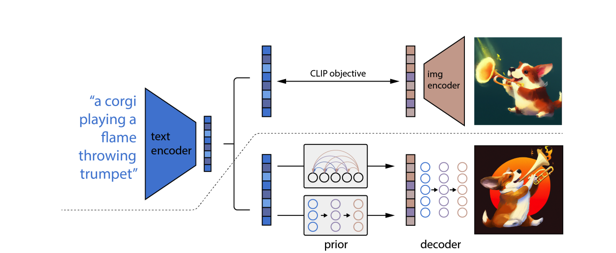
DALL-E 2模型的架构
*https://arxiv.org/pdf/2204.06125*
神经网络算法一文搞懂DALL-E 2(还在路上,尽情期待)
*Text-to-Video(文本到视频)*:
- 文本到视频(T2V)任务是一个更为复杂的多模态任务,它需要根据输入的文本描述生成一个包含多个图像帧的视频序列。这种技术在视频创作、虚拟现实等领域具有潜在的应用价值。
- 为了实现T2V任务,基于Transformer的模型需要处理更为复杂的数据结构和时间依赖关系。一种可能的解决方案是先将文本转换为一系列的图像帧(即使用T2I技术),然后使用一个额外的模型(如基于LSTM或Transformer的视频生成模型)将这些图像帧组合成一个连贯的视频序列。此外,还需要考虑到视频中的音频和字幕等其他模态的信息。
- VideoGPT是一种基于Transformer的视频生成模型,它能够根据文本描述生成连续的视频帧序列。
- VideoGPT采用了自回归的方式生成视频帧,通过捕捉帧之间的时间依赖关系来生成连贯的视频序列。

VideoGPT模型的架构
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高
针对所有自学遇到困难的同学们,我帮大家系统梳理大模型学习脉络,将这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓
👉[CSDN大礼包🎁:全网最全《LLM大模型入门+进阶学习资源包》免费分享(安全链接,放心点击)]()👈
















 671
671

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}