







暑期实习基本结束了,校招即将开启。
不同以往的是,当前职场环境已不再是那个双向奔赴时代了。求职者在变多,HC 在变少,岗位要求还更高了。提前准备才是完全之策。
最近,我们又陆续整理了很多大厂的面试题,帮助一些球友解惑答疑,分享技术面试中的那些弯弯绕绕。
总结链接如下:
编码器-解码器注意力:在“编码器-解码器注意力”层中,查询来自前一层解码器,而记忆键和值则来自编码器的输出。这使得解码器中的每个位置都能关注输入序列中的所有位置。这模仿了序列到序列模型中典型的编码器-解码器注意力机制。
(1)论文中对于编码器-解码器注意力的描述,让我们初步了解Encoder-Decoder Attention的Q来自前一层的解码器,K、V来自编码器的输出。

(2)当我们想深入了解,回到Transformer的架构图时,估计又懵逼了,怎么又变成Muti-Head Attention?
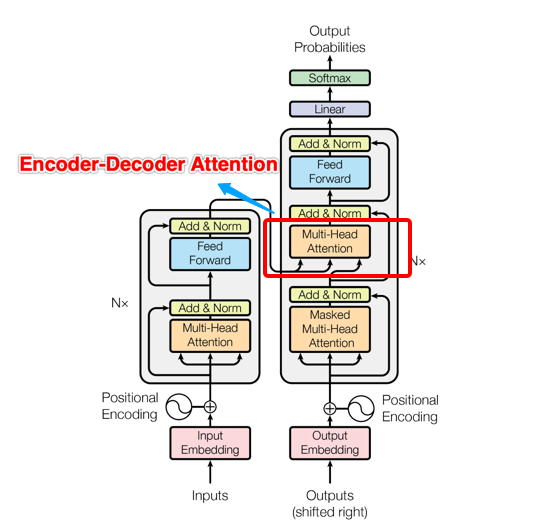
Transformer架构图
(3)新手的疑问:架构图中明明是Multi-Head Attention,论文中的描述又变为Encoder-Decoder Attention,怎么又冒出一个新名词Cross Attention?

编码器-解码器的 Cross Attention
Cross Attention:交叉注意力的输入来自两个不同的序列,一个序列用作查询(Q),另一个序列提供键(K)和值(V),实现跨序列的交互。
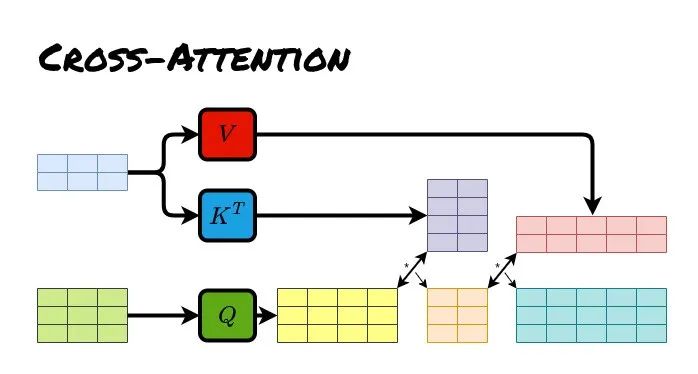
Cross Attention
Self Attention vs Cross Attention:Self Attention更适用于处理单个序列,而Cross Attention则更适用于处理多个序列之间的交互。
-
输入来源:
Self Attention:其输入来自同一序列,即查询(Q)、键(K)和值(V)都来自编码器。这种机制关注于序列内部元素之间的关联。
Cross Attention:其输入来自不同的序列。解码器序列作为查询(Q),而编码器序列作为键(K)和值(V)。这种机制关注于不同序列之间的元素关联。
-
应用场景:
Self Attention:在自然语言处理任务中尤为常见,如语言建模、文本分类等。由于它关注的是序列内部元素之间的关联,因此特别适用于处理单个序列,如句子或段落。
Cross Attention:在自然语言处理、计算机视觉等领域都有应用,如机器翻译、图像描述生成等。它允许模型关注不同序列之间的元素关联,从而能够处理多个序列之间的交互。
-
作用机制:
Self Attention:通过对序列中的每个元素(如词或图像patch)生成一个表示,并使用这个表示作为查询去关注序列中的其他元素,从而计算出一个新的表示。这个过程有助于捕捉序列内部的依赖关系。
Cross Attention:在两个序列之间建立关联,一个序列的元素作为查询去关注另一个序列中的所有元素。这种机制允许模型在翻译或生成任务中关注源序列和目标序列之间的对应关系。

Self Attention vs Cross Attention
Cross Attention应用机器翻译:在机器翻译等序列到序列(Seq2Seq)的任务中,交叉注意力机制允许解码器在生成输出的每一步中,都能关注到输入序列中与当前步最相关的信息,从而生成更准确的输出。这种机制大大提高了Seq2Seq模型的性能,特别是在处理长序列和复杂依赖关系时。
-
准备输入数据:
通常有两个不同的输入序列,我们称之为源序列(Source Sequence)和目标序列(Target Sequence)。在机器翻译任务中,源序列可以是原文,而目标序列可以是译文的部分或全部。
-
生成查询(Query)、键(Key)和值(Value):
对于交叉注意力,查询(Q)通常来自目标序列的某个元素或元素的表示。键(K)和值(V)则来自源序列的元素或元素的表示。
这些表示通常是通过嵌入层(Embedding Layer)或者经过某种形式的编码器(Encoder)得到的。
-
计算注意力得分:
对于每一个目标序列中的查询(Q),计算它与源序列中所有键(K)的相似度或相关性得分。这通常通过点积、加性注意力或缩放点积等方式实现。
-
归一化注意力得分:
使用Softmax函数将得分转换成概率分布,这样每个源序列中的键(K)都会有一个与之对应的权重。 -
计算加权和:
使用上一步得到的权重对源序列中的值(V)进行加权求和,得到一个加权表示(也称为上下文向量)。 -
输出上下文向量:
这个加权表示(上下文向量)捕捉了源序列中与目标序列查询最相关的信息,并将其作为交叉注意力的输出。 -
使用上下文向量:
这个上下文向量随后可以被用于目标序列的下一个处理步骤,例如在解码器(Decoder)中用于生成下一个词或预测下一个状态。



















 5295
5295

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









