






1 BPE、wordpiece、sentencepiece的区别?
目前的机器学习模型都是基于数学模型,这意味着输入必须是数字形式。然而,在真实场景中,我们处理的输入通常包含许多非数字形式(有时即使原始输入是数字形式,也需要进行转换)。最典型的例子就是自然语言处理(NLP)中的文本输入。为了让文本能够被模型处理,我们需要将其转换成数字形式,这个转换过程就是通过映射关系(mapping)实现的。具体来说,我们将文本映射成对应的数字,即token,而这个映射过程的工具就是tokenizer。它可以将文本编码成数字(encode),也可以将数字解码回文本(decode)。
-
词级别(Word Level)
在词级别上,一个词对应一个ID。比如“武汉市/长江/大桥/欢迎/你”和“武汉/市长/江大桥/欢迎/你”,我们应该选择哪个方案呢? -
字符级别(Char Level)
考虑到分词的复杂性,我们可以选择不分词,而是按“字”(char)来作为最小单元进行映射。这样词表就小多了:对于英文,仅需要26个字母;对于中文,根据2013年中华人民共和国教育部发布的《通用规范汉字表》定义,国家规定的通用规范汉字共有8105个,相对来说并不算多。然而,将文本切分得过细会导致序列长度增加,显著增加建模难度(需要通过字来学习词的语义),并且通常会影响模型效果。 -
子词级别(Subword Level)
子词级别(subword level)介于字符和单词之间。例如,'Transformers’可能会被分成’Transform’和’ers’两个部分。这个方案在词汇量和语义独立性之间取得了平衡,是一种相对较优的方案。
在子词级别的tokenizer方法中,主要有以下几种:BPE、Bytes BPE、WordPiece、Unigram、SentencePiece。下面简要总结各个方法:
BPE(Byte Pair Encoding)
BPE 通过统计词频来确定是否合并相邻的子词对(pair subwords)。具体步骤如下:
初始化时,将所有单词拆分为字符。
统计所有相邻字符对的频率,找到出现频率最高的一对。
合并这对字符,更新词表。
重复步骤2和3,直到达到预定的词汇表大小。
这种方法通过逐步合并高频字符对,逐渐形成常用的子词,从而减少词汇表的大小。
Bytes BPE
Bytes BPE 是BPE的变种,适用于处理任意语言的文本,包括非拉丁字符和特殊符号。它直接在字节级别进行操作,不依赖于特定的字符集,因此对多语言和非标准文本有更好的兼容性。
WordPiece
WordPiece 方法最初由Google在训练其BERT模型时提出。它与BPE类似,通过统计子词对的频率进行合并,但其目标是最大化词汇表的语言覆盖率和分词质量。考虑的是合并后能否最大程度提高训练数据的整体似然值(通常基于 n-gram 模型得分)。这意味着 WordPiece 更侧重于选择能够优化语言模型性能的子词组合。BPE选择频数最高的相邻子词合并,而WordPiece选择使得语言模型概率最大的相邻子词加入词表。
具体步骤包括:
将单词拆分为字符。
统计词频,合并频率最高的子词对。
不断重复,直到达到预定的词汇表大小。
WordPiece 相较于BPE,更注重子词合并后的语义完整性和词汇覆盖率。
Unigram
Unigram 是一种基于概率模型的分词方法。它和 BPE 以及 WordPiece 从表面上看一个大的不同是,前两者都是初始化一个小词表,然后一个个增加到限定的词汇量,而 Unigram Language Model 却是先初始一个大词表,接着通过语言模型评估不断减少词表,直到限定词汇量。
其核心思想是:
初始化一个包含大量子词的词汇表。
根据子词的概率,计算给定文本的最优分词方案。
移除低概率的子词,不断精简词汇表。
迭代上述过程,直到达到预定的词汇表大小。
Unigram 方法通过概率模型,能够更灵活地处理词汇分布和词频变化,适用于多语言文本。
SentencePiece
SentencePiece 是一个独立于语言和字符集的分词方法,适用于多语言处理。SentencePiece它是谷歌推出的子词开源工具包,它是把一个句子看作一个整体,再拆成片段,而没有保留天然的词语的概念。一般地,它把空格也当作一种特殊字符来处理,再用BPE或者Unigram算法来构造词汇表。SentencePiece除了集成了BPE、ULM子词算法之外,SentencePiece还能支持字符和词级别的分词。
其特点是:
不需要预处理(如分词或去停用词)。
直接在原始文本上操作,生成子词单元。
支持BPE和Unigram模型。
SentencePiece 通过统一的分词框架,简化了多语言模型的训练流程,提高了分词的一致性和效率。
这些子词级别的tokenizer方法各有优缺点,选择哪种方法应根据具体的应用场景和需求来确定。
2 attention的复杂度?attention的优化?
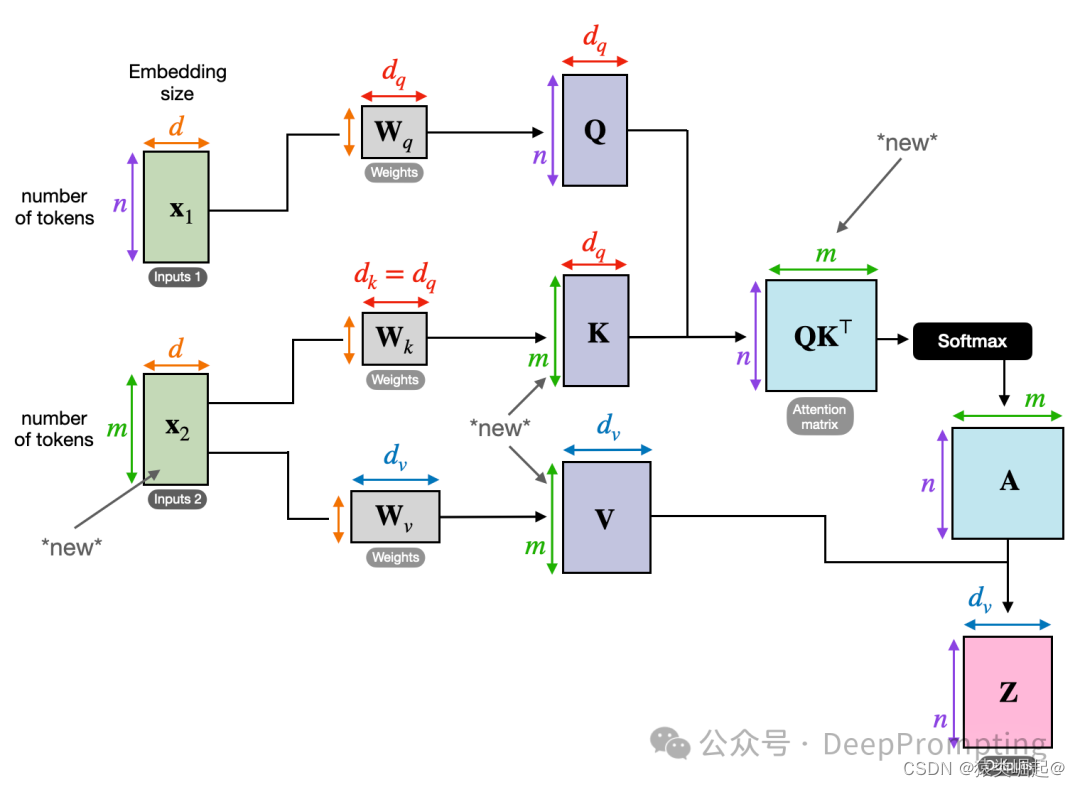

由于自注意力机制的二次复杂度,处理长序列时的计算和内存需求非常高。为了优化attention机制,减少复杂度,研究人员提出了多种改进方法。
这些优化方法有效地降低了注意力机制在长序列处理中的计算和内存开销,使得Transformer模型能够在更多实际应用中处理更长的输入序列。
3 代码实现Multihead self-attention?
import torch
import torch.nn as nn
import torch.nn.functional as F
class ScaledDotProductAttention(nn.Module):
def __init__(self, d_k):
super(ScaledDotProductAttention, self).__init__()
self.d_k = d_k
def forward(self, Q, K, V, mask=None):
scores = torch.matmul(Q, K.transpose(-2, -1)) / torch.sqrt(self.d_k)
if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9)
attn = F.softmax(scores, dim=-1)
output = torch.matmul(attn, V)
return output, attn
class MultiHeadAttention(nn.Module):
def __init__(self, d_model, num_heads):
super(MultiHeadAttention, self).__init__()
assert d_model % num_heads == 0
self.d_model = d_model
self.num_heads = num_heads
self.d_k = d_model // num_heads
self.d_v = d_model // num_heads
self.W_q = nn.Linear(d_model, d_model)
self.W_k = nn.Linear(d_model, d_model)
self.W_v = nn.Linear(d_model, d_model)
self.fc = nn.Linear(d_model, d_model)
self.attention = ScaledDotProductAttention(self.d_k)
def forward(self, Q, K, V, mask=None):
batch_size = Q.size(0)
# Linear projections
Q = self.W_q(Q).view(batch_size, -1, self.num_heads, self.d_k).transpose(1, 2)
K = self.W_k(K).view(batch_size, -1, self.num_heads, self.d_k).transpose(1, 2)
V = self.W_v(V).view(batch_size, -1, self.num_heads, self.d_v).transpose(1, 2)
# Apply attention on all the projected vectors in batch
scores, attn = self.attention(Q, K, V, mask=mask)
# Concatenate and apply final linear layer
scores = scores.transpose(1, 2).contiguous().view(batch_size, -1, self.d_model)
output = self.fc(scores)
return output, attn
Example usage
d_model = 512
num_heads = 8
seq_length = 10
batch_size = 32
multihead_attn = MultiHeadAttention(d_model, num_heads)
Q = torch.rand(batch_size, seq_length, d_model)
K = torch.rand(batch_size, seq_length, d_model)
V = torch.rand(batch_size, seq_length, d_model)
mask = None # Replace with actual mask if needed
output, attn = multihead_attn(Q, K, V, mask)
print(output.shape) # Should be (batch_size, seq_length, d_model)
print(attn.shape) # Should be (batch_size, num_heads, seq_length, seq_length)
ScaledDotProductAttention:
这是实现缩放点积注意力的类。它计算注意力权重并应用这些权重来组合值(value)。
MultiHeadAttention: 这是实现多头自注意力的类。
首先,将查询(Q)、键(K)和值(V)通过线性变换映射到高维空间。
然后,将这些向量分成多个头(num_heads),每个头的维度为d_model/num_heads。
每个头独立地应用缩放点积注意力。
最后,将每个头的输出拼接起来,并通过一个线性层进行变换。
Example Usage:
示例代码展示了如何初始化和使用MultiHeadAttention模块,生成一些随机的输入张量,并应用多头注意力。
这个实现展示了多头自注意力的基本结构和计算过程,可以在实际应用中作为一个模块使用。
那么,我们该如何学习大模型?
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
一、大模型全套的学习路线
学习大型人工智能模型,如GPT-3、BERT或任何其他先进的神经网络模型,需要系统的方法和持续的努力。既然要系统的学习大模型,那么学习路线是必不可少的,下面的这份路线能帮助你快速梳理知识,形成自己的体系。
L1级别:AI大模型时代的华丽登场

L2级别:AI大模型API应用开发工程

L3级别:大模型应用架构进阶实践

L4级别:大模型微调与私有化部署

一般掌握到第四个级别,市场上大多数岗位都是可以胜任,但要还不是天花板,天花板级别要求更加严格,对于算法和实战是非常苛刻的。建议普通人掌握到L4级别即可。
以上的AI大模型学习路线,不知道为什么发出来就有点糊,高清版可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。















 791
791











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









