






01 引言
在 Qwen2 发布后的过去三个月里,许多开发者基于 Qwen2 语言模型构建了新的模型,并提供了宝贵的反馈。在这段时间里,通义千问团队专注于创建更智能、更博学的语言模型。Qwen 家族的最新成员:Qwen2.5系列正式开源!
这可能是历史上最大的开源发布!最新发布包括了语言模型 Qwen2.5,以及专门针对编程的 Qwen2.5-Coder 和数学的 Qwen2.5-Math 模型。所有开放权重的模型都是稠密的、decoder-only的语言模型,提供多种不同规模的版本,包括:
-
Qwen2.5: 0.5B, 1.5B, 3B, 7B, 14B, 32B, 以及72B;
-
Qwen2.5-Coder: 1.5B, 7B, 以及即将推出的32B;
-
Qwen2.5-Math: 1.5B, 7B, 以及72B。
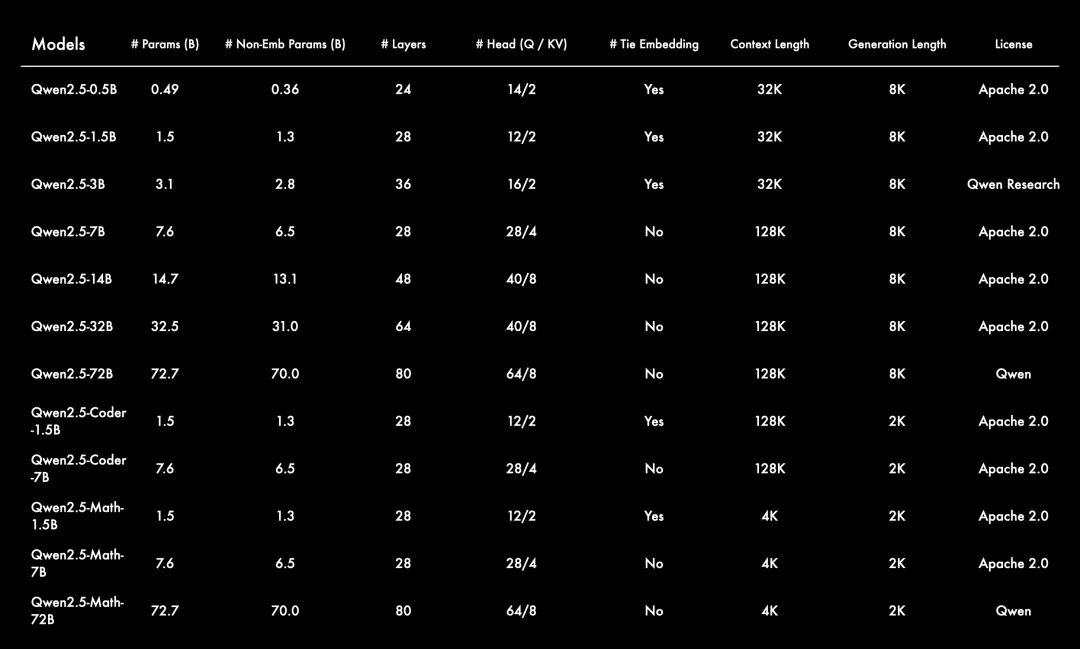
除了3B和72B的版本外,Qwen2.5所有的开源模型都采用了 Apache 2.0 许可证。您可以在相应的模型仓库中找到许可证文件。此外,本次通义千问团队还开源了性能不输于GPT-4o的 Qwen2-VL-72B。
小编敲黑板:
-
更大的训练数据集: Qwen2.5 语言模型的所有尺寸都在最新的大规模数据集上进行了预训练,该数据集包含多达 18T tokens。相较于 Qwen2,Qwen2.5 获得了显著更多的知识(MMLU:85+),并在编程能力(HumanEval 85+)和数学能力(MATH 80+)方面有了大幅提升。
-
更强的指令遵循能力: 新模型在指令执行、生成长文本(超过 8K 标记)、理解结构化数据(例如表格)以及生成结构化输出特别是 JSON 方面取得了显著改进。Qwen2.5 模型总体上对各种system prompt更具适应性,增强了角色扮演实现和聊天机器人的条件设置功能。
-
长文本支持能力: 与 Qwen2 类似,Qwen2.5 语言模型支持高达 128K tokens,并能生成最多 8K tokens的内容。
-
强大的多语言能力: 它们同样保持了对包括中文、英文、法文、西班牙文、葡萄牙文、德文、意大利文、俄文、日文、韩文、越南文、泰文、阿拉伯文等 29 种以上语言的支持。
-
专业领域的专家语言模型能力增强,即用于编程的 Qwen2.5-Coder 和用于数学的 Qwen2.5-Math,相比其前身 CodeQwen1.5 和 Qwen2-Math 有了实质性的改进。具体来说,Qwen2.5-Coder 在包含 5.5 T tokens 编程相关数据上进行了训练,使即使较小的编程专用模型也能在编程评估基准测试中表现出媲美大型语言模型的竞争力。同时,Qwen2.5-Math 支持 中文 和 英文,并整合了多种推理方法,包括CoT(Chain of Thought)、PoT(Program of Thought)和 TIR(Tool-Integrated Reasoning)。
02 模型性能
Qwen2.5
为了展示 Qwen2.5 的能力,开源模型 Qwen2.5-72B —— 一个拥有 720 亿参数的稠密 decoder-only 语言模型——与领先的开源模型如 Llama-3.1-70B、Mistral-Large-V2 和 DeepSeek-V2.5 进行了基准测试。多个基准测试中展示了经过指令调优的版本的综合结果,评估了模型的能力和人类偏好。
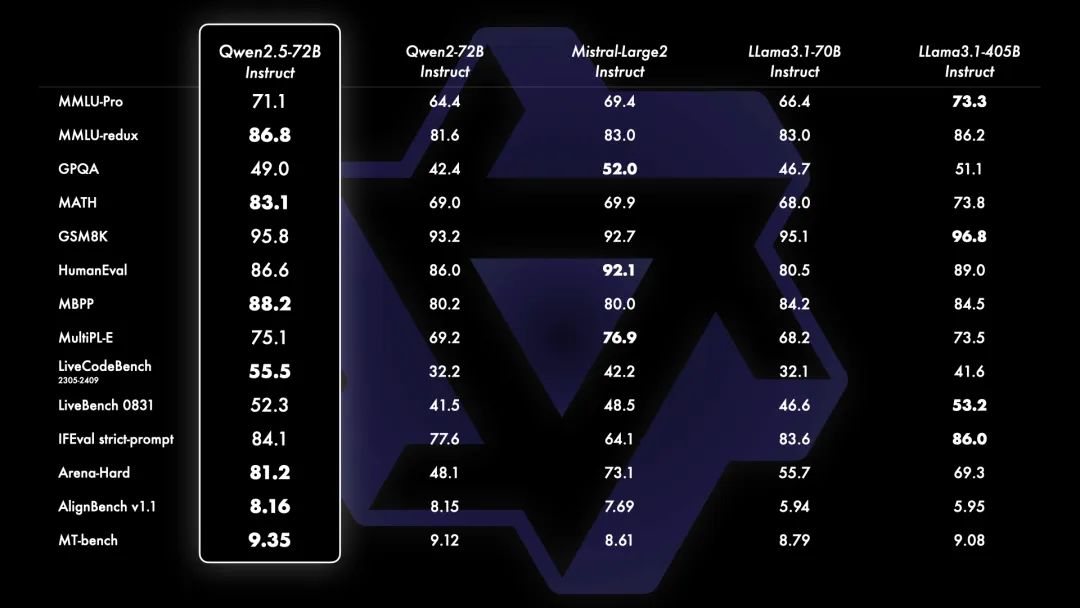
Qwen2.5 的一个重要更新是重新引入 Qwen2.5-14B 和 Qwen2.5-32B。这些模型在多样化的任务中超越了同等规模或更大规模的基线模型,例如 Phi-3.5-MoE-Instruct 和 Gemma2-27B-IT。它们在模型大小和能力之间达到了最佳平衡,提供了匹配甚至超过一些较大模型的性能。
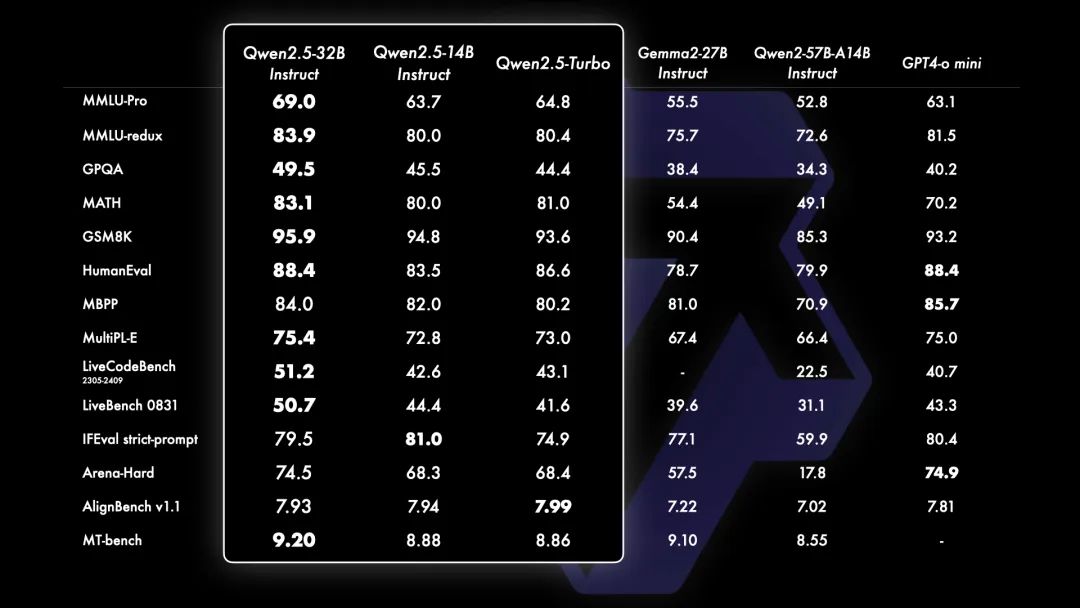
近来也出现了明显的转向小型语言模型(SLMs)的趋势。尽管历史上小型语言模型(SLMs)的表现一直落后于大型语言模型(LLMs),但二者之间的性能差距正在迅速缩小。值得注意的是,即使是只有大约 30 亿参数的模型现在也能取得高度竞争力的结果。附带的图表显示了一个重要的趋势:在 MMLU 中得分超过 65 的新型模型正变得越来越小,这凸显了语言模型的知识密度增长速度加快。特别值得一提的是, Qwen2.5-3B 成为这一趋势的一个典型例子,它仅凭约 30 亿参数就实现了令人印象深刻的性能,展示了其相对于前辈模型的高效性和能力。

除了在基准评估中取得的显著增强外,通义千问还改进了后训练方法。四个主要更新包括支持最长可达 8K 标记的长文本生成,大幅提升了对结构化数据的理解能力,生成结构化输出(尤其是 JSON 格式)更加可靠,并且在多样化的系统提示下的表现得到了加强,这有助于有效进行角色扮演。请查阅 LLM 博客了解如何利用这些功能的详细信息。
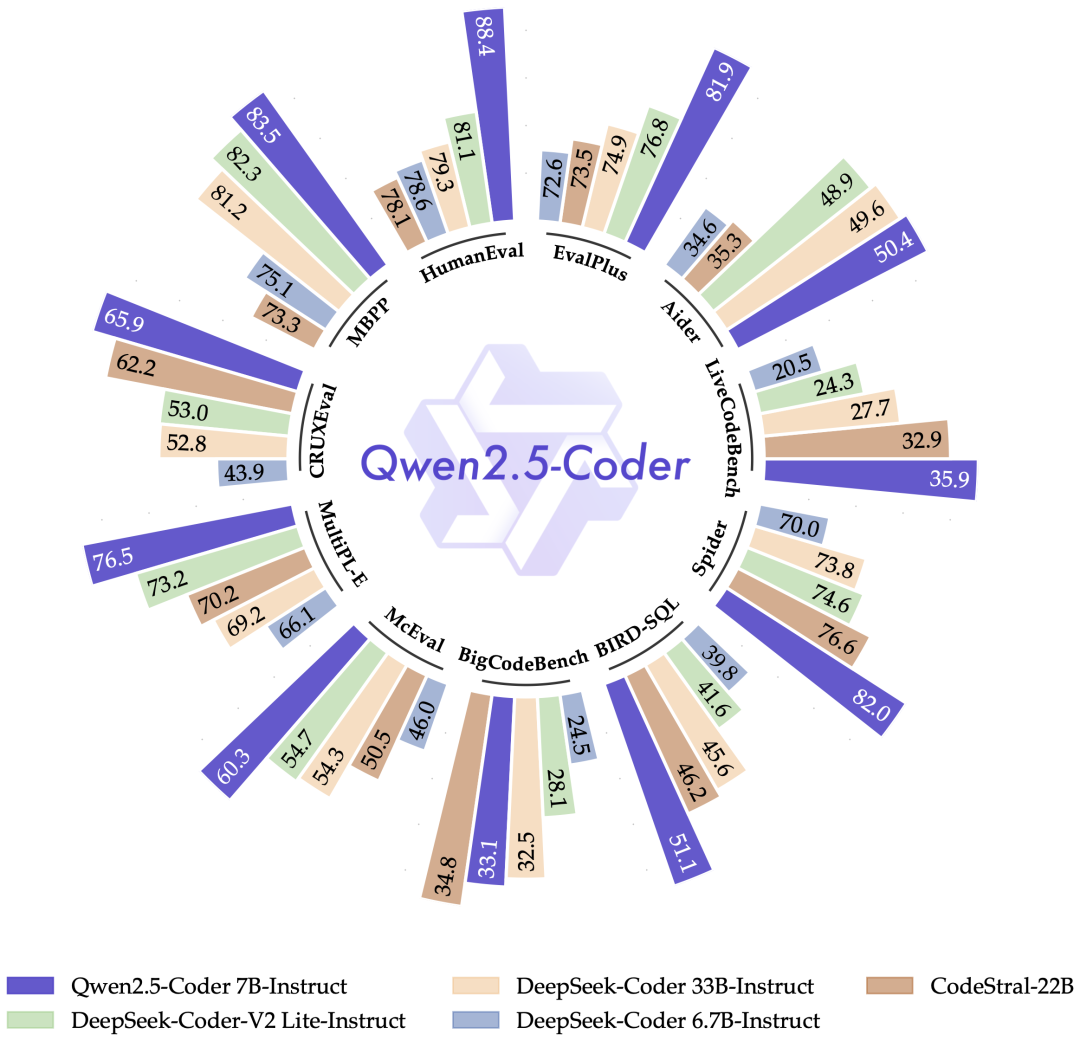
Qwen2.5-Coder
自从推出 CodeQwen1.5 以来,通义千问吸引了大量依赖该模型完成各种编程任务的用户,这些任务包括调试、回答编程相关的问题以及提供代码建议。Qwen2.5-Coder 特别为编程应用而设计。在本节展示了 Qwen2.5-Coder-7B-Instruct 的性能结果,并将其与领先的开源模型进行了基准测试,其中包括那些参数量大得多的模型。
Qwen2.5-Coder 是您个人编程助手的优秀选择。尽管它的体积较小,但在多种编程语言和任务中,它的表现超过了众多大型语言模型,展现了其卓越的编程能力。
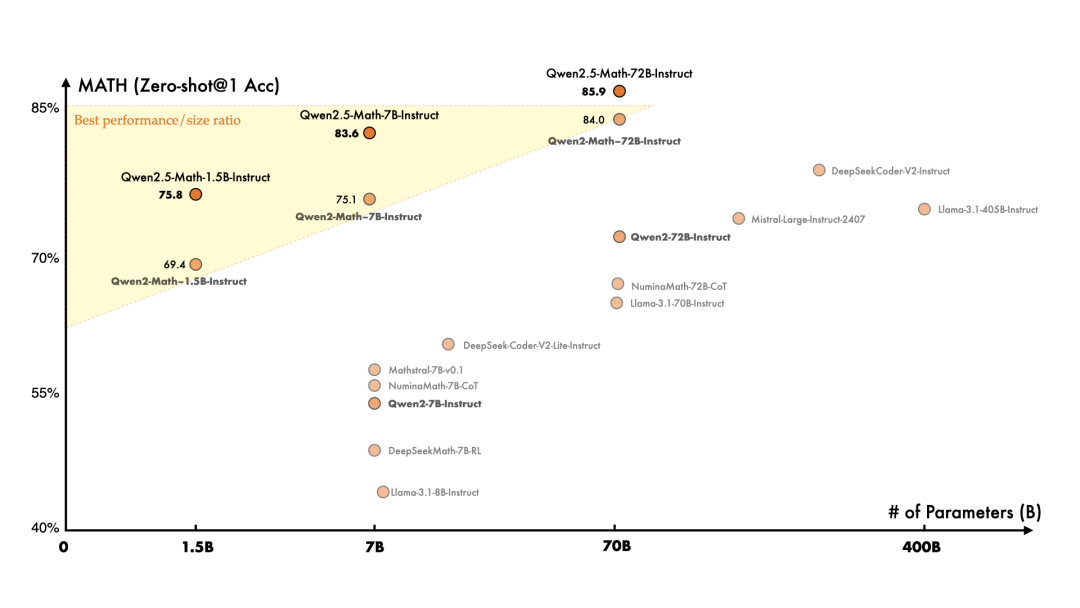
Qwen2.5-Math
在数学专用语言模型方面,通义千问上个月发布了首批模型 Qwen2-Math,而这一次,相比于 Qwen2-Math,Qwen2.5-Math 在更大规模的数学相关数据上进行了预训练,包括由 Qwen2-Math 生成的合成数据。此外,这一次增加了对中文的支持,并通过赋予其进行 CoT(Chain of Thought)、PoT(Program of Thought)和 TIR(Tool-Integrated Reasoning)的能力来加强其推理能力。Qwen2.5-Math-72B-Instruct 的整体性能超越了 Qwen2-Math-72B-Instruct 和 GPT4-o,甚至是非常小的专业模型如 Qwen2.5-Math-1.5B-Instruct 也能在与大型语言模型的竞争中取得高度竞争力的表现。

03 魔搭社区最佳实践
模型链接
Qwen模型下载链接:
https://modelscope.cn/organization/qwen
可以使用ModelScope CLI(首推),Python SDK或者git clone的方式下载。
Qwen2.5系列模型体验:
-
Qwen2.5合集:
-
https://modelscope.cn/studios/qwen/Qwen2.5
-
小程序体验:
-
看图解数学题(Qwen2-VL+Qwen2.5-Math
-
https://modelscope.cn/studios/qwen/Qwen2.5-Math-demo
-
小程序体验:
模型推理
使用transformers推理
from modelscope import AutoModelForCausalLM, AutoTokenizer`` ``model_name = "qwen/Qwen2.5-7B-Instruct"`` ``model = AutoModelForCausalLM.from_pretrained(` `model_name,` `torch_dtype="auto",` `device_map="auto"``)``tokenizer = AutoTokenizer.from_pretrained(model_name)`` ``prompt = "Give me a short introduction to large language model."``messages = [` `{"role": "system", "content": "You are Qwen, created by Alibaba Cloud. You are a helpful assistant."},` `{"role": "user", "content": prompt}``]``text = tokenizer.apply_chat_template(` `messages,` `tokenize=False,` `add_generation_prompt=True``)``model_inputs = tokenizer([text], return_tensors="pt").to(model.device)`` ``generated_ids = model.generate(` `**model_inputs,` `max_new_tokens=512``)``generated_ids = [` `output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)``]`` ``response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
模型微调
本文使用ms-swift对qwen2.5和qwen2-vl进行自我认知微调和图像OCR微调,并对微调后的模型进行推理。ms-swift是魔搭社区官方提供的LLM工具箱,支持300+大语言模型和80+多模态大模型的微调到部署。ms-swift开源地址:https://github.com/modelscope/ms-swift
在开始微调之前,请确保您的环境已正确安装
# 安装ms-swift``git clone https://github.com/modelscope/ms-swift.git``cd ms-swift``pip install -e .[llm]`` ``# qwen2-vl``# https://github.com/QwenLM/Qwen2-VL/issues/96``pip install git+https://github.com/huggingface/transformers@21fac7abba2a37fae86106f87fcf9974fd1e3830``# vllm加速``pip install vllm>=0.6.1
通常,大模型微调通常使用自定义数据集进行微调。在这里,我们将展示可直接运行的demo。
Qwen2.5
我们对Qwen2.5-72B-Instruct进行自我认知微调。
自我认知数据集:https://www.modelscope.cn/datasets/swift/self-cognition
通用混合数据集:
https://www.modelscope.cn/datasets/AI-ModelScope/Magpie-Qwen2-Pro-200K-English
https://www.modelscope.cn/datasets/AI-ModelScope/Magpie-Qwen2-Pro-200K-Chinese
微调脚本:
# 实验环境:4 * A100``# 显存占用:4 * 70GB``NPROC_PER_NODE=4 CUDA_VISIBLE_DEVICES=0,1,2,3 swift sft \` `--model_type qwen2_5-72b-instruct \` `--model_id_or_path qwen/Qwen2.5-72B-Instruct \` `--dataset qwen2-pro-en#500 qwen2-pro-zh#500 self-cognition#500 \` `--logging_steps 5 \` `--learning_rate 1e-4 \` `--output_dir output \` `--lora_target_modules ALL \` `--model_name 小黄 'Xiao Huang' \` `--model_author 魔搭 ModelScope \` `--deepspeed default-zero3`` ``# 单卡A10/3090可运行的例子 (Qwen2.5-7B-Instruct)``# 显存占用:24GB``CUDA_VISIBLE_DEVICES=0 swift sft \` `--model_type qwen2_5-7b-instruct \` `--model_id_or_path qwen/Qwen2.5-7B-Instruct \` `--dataset qwen2-pro-en#500 qwen2-pro-zh#500 self-cognition#500 \` `--logging_steps 5 \` `--max_length 2048 \` `--learning_rate 1e-4 \` `--output_dir output \` `--lora_target_modules ALL \` `--model_name 小黄 'Xiao Huang' \` `--model_author 魔搭 ModelScope
自定义数据集文档可以查看:https://github.com/modelscope/ms-swift/blob/main/docs/source/Instruction/%E8%87%AA%E5%AE%9A%E4%B9%89%E4%B8%8E%E6%8B%93%E5%B1%95.md
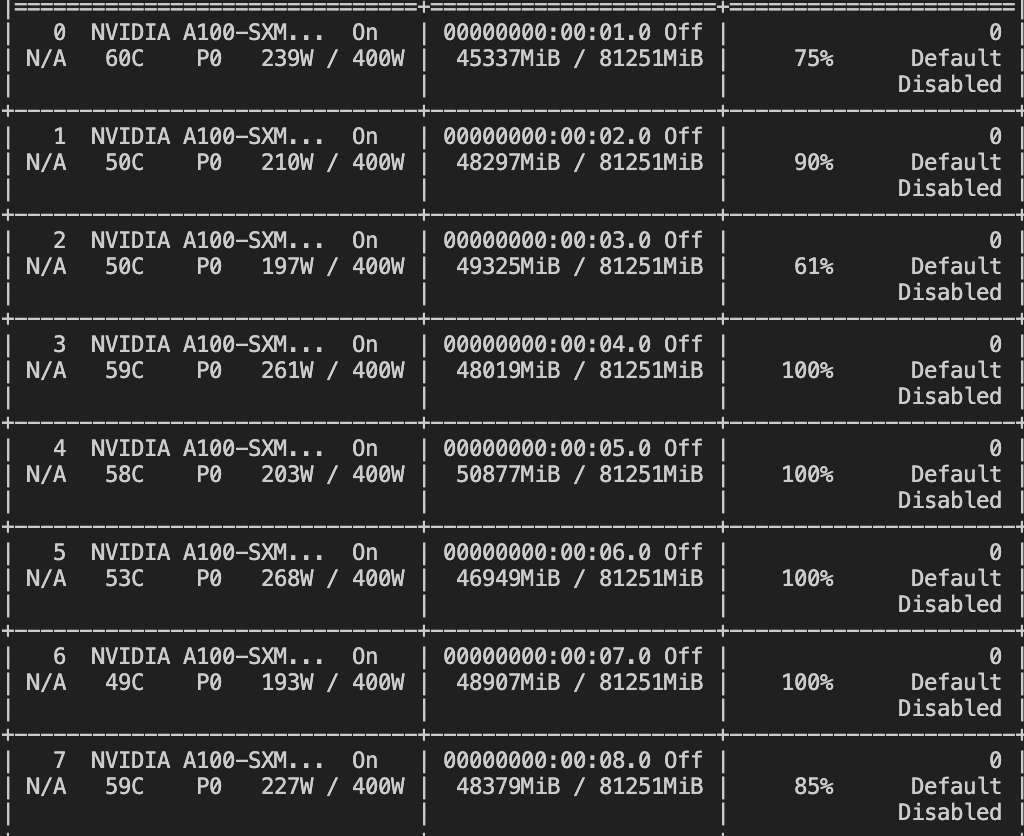
微调显存消耗:
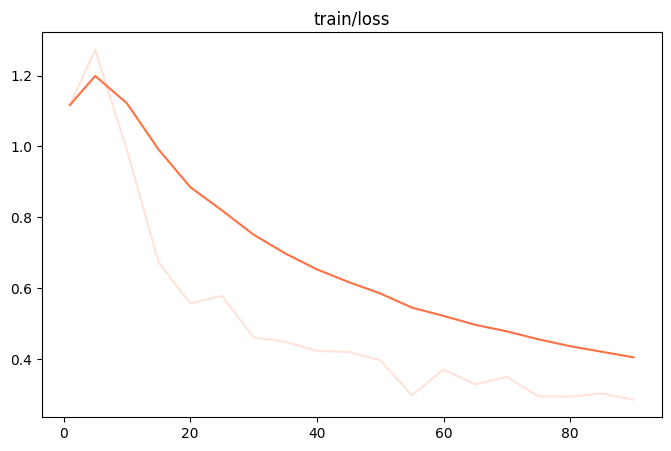
微调过程的loss可视化:
微调后推理脚本如下,这里的ckpt_dir需要修改为训练生成的last checkpoint文件夹。我们可以使用vLLM对merge后的checkpoint进行推理加速:
# 直接推理``CUDA_VISIBLE_DEVICES=0,1 swift infer \` `--ckpt_dir output/qwen2_5-72b-instruct/vx-xxx/checkpoint-xxx \`` ``# merge-lora并使用vLLM进行推理加速``CUDA_VISIBLE_DEVICES=0,1 swift export \` `--ckpt_dir output/qwen2_5-72b-instruct/vx-xxx/checkpoint-xxx \` `--merge_lora true`` ``CUDA_VISIBLE_DEVICES=0,1,2,3 swift infer \` `--ckpt_dir output/qwen2_5-72b-instruct/vx-xxx/checkpoint-xxx-merged \` `--infer_backend vllm --max_model_len 8192 \` `--tensor_parallel_size 4
微调后模型对验证集进行推理的示例:

Qwen2-VL
我们对Qwen2-VL-72B-Instruct进行OCR微调。Grouding任务和视频微调的例子可以查看ms-swift文档:https://github.com/modelscope/ms-swift/blob/main/docs/source/Multi-Modal/qwen2-vl%E6%9C%80%E4%BD%B3%E5%AE%9E%E8%B7%B5.md
微调数据集:https://modelscope.cn/datasets/AI-ModelScope/LaTeX_OCR
微调脚本:
# 实验环境:8 * A100``# 显存占用:``SIZE_FACTOR=8 MAX_PIXELS=602112 \``NPROC_PER_NODE=8 CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 \``swift sft \` `--model_type qwen2-vl-72b-instruct \` `--model_id_or_path qwen/Qwen2-VL-72B-Instruct \` `--sft_type lora \` `--dataset latex-ocr-print#20000 \` `--deepspeed default-zero3``如果要使用自定义数据集,只需按以下方式进行指定:``# val_dataset可选,如果不指定,则会从dataset中切出一部分数据集作为验证集` `--dataset train.jsonl \` `--val_dataset val.jsonl \``自定义数据集格式:``{"query": "<image>55555", "response": "66666", "images": ["image_path"]}``{"query": "<image><image>eeeee", "response": "fffff", "history": [], "audios": ["image_path1", "image_path2"]}``{"query": "EEEEE", "response": "FFFFF", "history": [["query1", "response1"], ["query2", "response2"]]}
微调显存消耗:
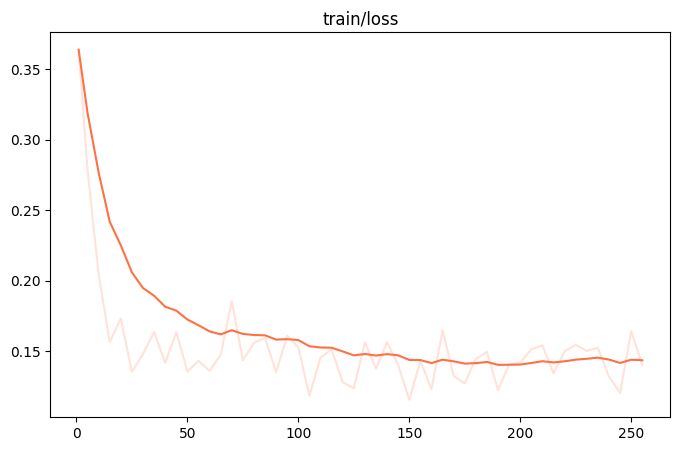
微调过程的loss可视化:(由于时间原因,这里只微调了250个steps)
微调后推理脚本如下,这里的ckpt_dir需要修改为训练生成的last checkpoint文件夹。我们可以使用vLLM对merge后的checkpoint进行推理加速:
# 直接推理``CUDA_VISIBLE_DEVICES=0,1 swift infer \` `--ckpt_dir output/qwen2-vl-72b-instruct/vx-xxx/checkpoint-xxx \` `--load_dataset_config true`` ``# merge-lora并使用vLLM进行推理加速``CUDA_VISIBLE_DEVICES=0,1 swift export \` `--ckpt_dir output/qwen2-vl-72b-instruct/vx-xxx/checkpoint-xxx \` `--merge_lora true`` ``CUDA_VISIBLE_DEVICES=0,1,2,3 swift infer \` `--ckpt_dir output/qwen2-vl-72b-instruct/vx-xxx/checkpoint-xxx-merged \` `--load_dataset_config true --infer_backend vllm \` `--tensor_parallel_size 4 --max_model_len 16384
微调后模型对验证集进行推理的示例:

模型部署
vLLM部署
modelscope download --model=qwen/Qwen2.5-7B-Instruct --local_dir ./Qwen2.5-7B-Instruct``vllm serve ./Qwen2.5-7B-Instruct --enable-auto-tool-choice --tool-call-parser hermes
ollama部署
modelscope download --model=qwen/Qwen2.5-3B-Instruct-GGUF --local_dir ./ qwen2.5-3b-instruct-q5_k_m.gguf``ollama create qwen2_5 -f /mnt/workspace/Modelfile``ollama run qwen2_5
Modelfile现已支持function call
FROM /mnt/workspace/qwen2.5-3b-instruct-q5_k_m.gguf`` ``# set the temperature to 0.7 [higher is more creative, lower is more coherent]``PARAMETER temperature 0.7``PARAMETER top_p 0.8``PARAMETER repeat_penalty 1.05``TEMPLATE """{{ if .Messages }}``{{- if or .System .Tools }}<|im_start|>system``{{ .System }}``{{- if .Tools }}`` ``# Tools`` ``You are provided with function signatures within <tools></tools> XML tags. You may call one or more functions to assist with the user query. Don't make assumptions about what values to plug into functions. Here are the available tools:``<tools>{{- range .Tools }}{{ .Function }}{{- end }}</tools>`` ``For each function call, return a JSON object with function name and arguments within <tool_call></tool_call> XML tags as follows:``<tool_call>``{"name": <function-name>, "arguments": <args-json-object>}``</tool_call>{{- end }}<|im_end|>{{- end }}``{{- range .Messages }}``{{- if eq .Role "user" }}``<|im_start|>{{ .Role }}``{{ .Content }}<|im_end|>``{{- else if eq .Role "assistant" }}``<|im_start|>{{ .Role }}``{{- if .Content }}``{{ .Content }}``{{- end }}``{{- if .ToolCalls }}``<tool_call>``{{ range .ToolCalls }}{"name": "{{ .Function.Name }}", "arguments": {{ .Function.Arguments }}}``{{ end }}</tool_call>``{{- end }}<|im_end|>``{{- else if eq .Role "tool" }}``<|im_start|>user``<tool_response>``{{ .Content }}``</tool_response><|im_end|>``{{- end }}``{{- end }}``<|im_start|>assistant``{{ else }}{{ if .System }}<|im_start|>system``{{ .System }}<|im_end|>``{{ end }}{{ if .Prompt }}<|im_start|>user``{{ .Prompt }}<|im_end|>``{{ end }}<|im_start|>assistant``{{ end }}``"""
Swingdeploy云端部署
魔搭的一键部署服务,SwingDeploy,也在第一时间支持了Qwen2.5模型模型的部署,这里以Qwen2.5-3B-Instruct为例,直接使用CPU资源,将模型从ModelScope部署为OpenAI API兼容的专属服务。可从魔搭首页进入“模型服务->部署服务”,或直接访问
https://www.modelscope.cn/my/modelService/deploy
资源选择“函数计算(FC)”进行Serverless服务部署,如果第一次使用,按照页面提示账号绑定和授权即可:
点击“新建部署”后,可调出部署页面:
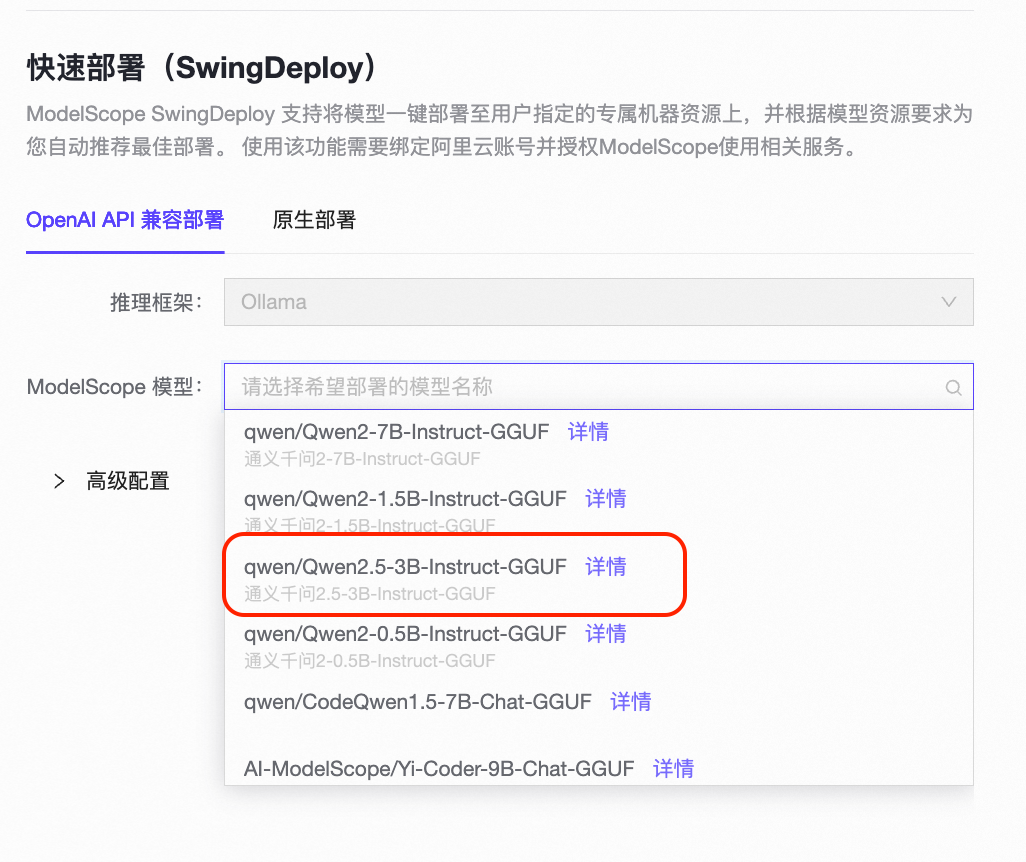
选择GGUF格式的Qwen2.5-3B模型 “Qwen2.5-3B-Instruct-GGUF”,默认CPU部署即可。等待部署成功后,点击“立即使用”,就可以看到成功部署后使用OpenAI API以及SDK调用Qwen2.5-3B-Instruct模型的方法。拷贝代码即可使用。
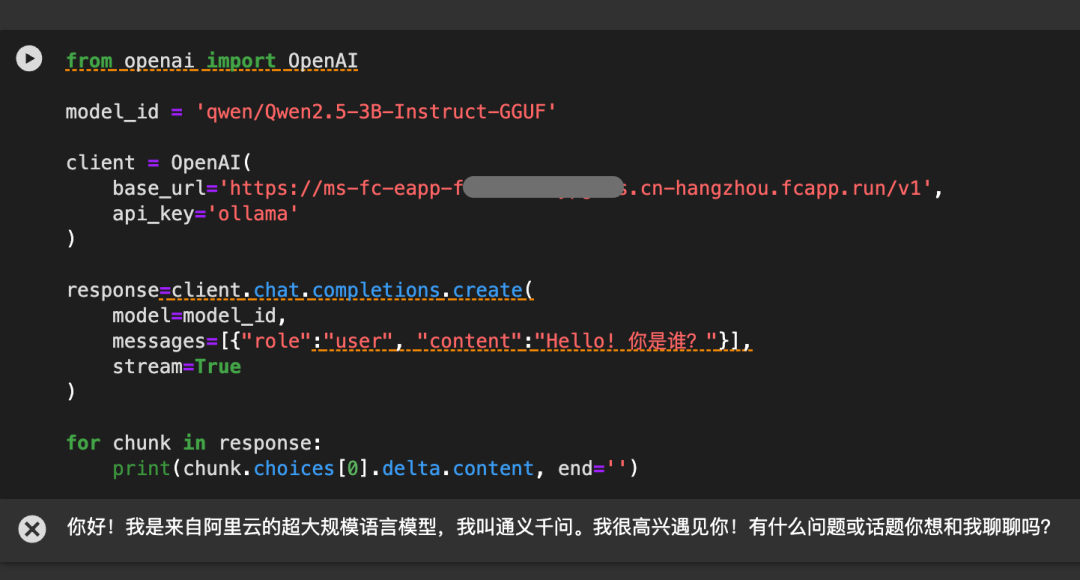
Note:因为是serverless部署,不使用的时候不计费,第一次调用可能要稍作等待。
零基础如何学习AI大模型
领取方式在文末
为什么要学习大模型?
学习大模型课程的重要性在于它能够极大地促进个人在人工智能领域的专业发展。大模型技术,如自然语言处理和图像识别,正在推动着人工智能的新发展阶段。通过学习大模型课程,可以掌握设计和实现基于大模型的应用系统所需的基本原理和技术,从而提升自己在数据处理、分析和决策制定方面的能力。此外,大模型技术在多个行业中的应用日益增加,掌握这一技术将有助于提高就业竞争力,并为未来的创新创业提供坚实的基础。
大模型典型应用场景
①AI+教育:智能教学助手和自动评分系统使个性化教育成为可能。通过AI分析学生的学习数据,提供量身定制的学习方案,提高学习效果。
②AI+医疗:智能诊断系统和个性化医疗方案让医疗服务更加精准高效。AI可以分析医学影像,辅助医生进行早期诊断,同时根据患者数据制定个性化治疗方案。
③AI+金融:智能投顾和风险管理系统帮助投资者做出更明智的决策,并实时监控金融市场,识别潜在风险。
④AI+制造:智能制造和自动化工厂提高了生产效率和质量。通过AI技术,工厂可以实现设备预测性维护,减少停机时间。
…
这些案例表明,学习大模型课程不仅能够提升个人技能,还能为企业带来实际效益,推动行业创新发展。
学习资料领取
如果你对大模型感兴趣,可以看看我整合并且整理成了一份AI大模型资料包,需要的小伙伴文末免费领取哦,无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发
AI大模型学习路线
如果你对AI大模型入门感兴趣,那么你需要的话可以点击这里大模型重磅福利:入门进阶全套104G学习资源包免费分享!
扫描下方csdn官方合作二维码获取哦!

这是一份大模型从零基础到进阶的学习路线大纲全览,小伙伴们记得点个收藏!

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
100套AI大模型商业化落地方案

大模型全套视频教程

200本大模型PDF书籍

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
LLM面试题合集

大模型产品经理资源合集

大模型项目实战合集

👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


















 771
771

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









