








既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
若矩阵中每个元素𝑎ij>0且满足𝑎ij × 𝑎ji = 1 ,则我们称该矩阵为正互反矩阵。
在层次分析法中,我们构造的判断矩阵均是正互反矩阵。若正互反矩阵满足𝑎ij × 𝑎jk = 𝑎ik ,则我们称其为一致矩阵。注意:在使用判断矩阵求权重之前,必须对其进行一致性检验。
那怎么进行一致性检验呢?
原理:检验我们构造的判断矩阵和一致矩阵是否有太大的差别。
下面需要用到线性代数的知识,没学过的朋友可以忽略掉证明过程,只需要了解如何计算即可。
若正互反矩阵(判断矩阵)满足aij × ajk = aik,则我们称其为一致矩阵。
判断矩阵越不一致时,最大特征值与n相差就越大。



进行一致性检验的步骤:
第一步:计算一致性指标CI
第二步:查找对应的平均随机一致性指标RI
注:在实际运用中,n很少超过10,如果指标的个数大于10,则可考虑建立二级指标体系,或使用我们以后要学习的模糊综合评价模型。
第三步:计算一致性比例CR
如果CR < 0.1, 则可认为判断矩阵的一致性可以接受;否则需要对判断矩阵进行修正。
注:特征值可用matlab软件进行计算,没学过线性代数的朋友也不需要担心。如果特征值中有虚数,则比较的是特征值的模长。第四步:如果CR > 0.1 如何修正?
一致性指标CI:0.1087
一致性比例CR:0.2090
注意:CR>=0.10,因此该判断矩阵A需要进行修改。
修改思想:往一致矩阵上调整~~~一致矩阵各行成倍数关系。


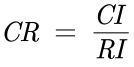

关于一致性检验的两个小问题:
(1)平均随机一致性指标RI怎么计算来的?
答:
注意:RI我们只需要会查表即可,不用管怎么来的,另外有些地方给的RI的表格和上面的有
细微区别,以上面的为准,因为上面使用的人最多。(2) 为什么要这样构造CI,为什么要以0.1为划分依据?
答:大家有兴趣的话可以去查看作者的原论文,作者是通过多次蒙特卡罗模拟得到的最佳的方案。


解决了一致性检验,那么一致矩阵要怎么计算权重呢?
对于景色这点而言:
苏杭的重要性如果是1,那么北戴河的重要性就是1/2,桂林的重要性就是1/4.
注意,权重一定要进行归一化处理:
苏杭 = 1 /(1+0.5+0.25)
北戴河 = 0.5 /(1+0.5+0.25)
桂林 = 0.25 /(1+0.5+0.25)仅使用第一列的数据,计算出来的权重:
苏杭 = 1 /(1+0.5+0.2)= 0.5882
北戴河 = 0.5 /(1+0.5+0.2)= 0.2941
桂林 = 0.2 /(1+0.5+0.2)= 0.1177使用第二列的数据,计算出来的权重:
苏杭 = 2 /(2+1+0.5)= 0.5714
北戴河 = 1 /(2+1+0.5)= 0.2857
桂林 = 0.5 /(2+1+0.5)= 0.1429使用第三列的数据,计算出来的权重:
苏杭 = 5 /(5+2+1)= 0.625
北戴河 = 2 /(5+2+1)= 0.25
桂林 = 1 /(5+2+1)= 0.125

方法1:算术平均法求权重
仅使用第一列的数据,计算出来的权重:
苏杭 = 1 /(1+0.5+0.2)= 0.5882
北戴河 = 0.5 /(1+0.5+0.2)= 0.2941
桂林 = 0.2 /(1+0.5+0.2)= 0.1177使用第二列的数据,计算出来的权重:
苏杭 = 2 /(2+1+0.5)= 0.5714
北戴河 = 1 /(2+1+0.5)= 0.2857
桂林 = 0.5 /(2+1+0.5)= 0.1429使用第三列的数据,计算出来的权重:
苏杭 = 5 /(5+2+1)= 0.625
北戴河 = 2 /(5+2+1)= 0.25
桂林 = 1 /(5+2+1)= 0.125综合上述三列,我们求平均权重:
苏杭 = ( 0.5882 + 0.5714 + 0.625 ) / 3=0.5949
北戴河 = ( 0.2941 + 0.2857 + 0.25 ) / 3=0.2766
桂林 = ( 0.1177 + 0.1429 + 0.125 ) / 3=0.1285步骤:
第一步:将判断矩阵按照列归一化(每一个元素除以其所在列的和)
第二步:将归一化的各列相加(按行求和)
第三步:将相加后得到的向量中每个元素除以n即可得到权重向量
下图公式说明上面的三个步骤:

方法2:几何平均法求权重
几何平均法求权重也有三步:
第一步:将A的元素按照行相乘得到一个新的列向量
第二步:将新的向量的每个分量开n次方
第三步:对该列向量进行归一化即可得到权重向量
下图公式说明上面的三个步骤:

方法3:特征值法求权重
拿景色举个例子:
注意,权重一定要进行归一化处理:
苏杭 = 1 /(1+0.5+0.25)
北戴河 = 0.5 /(1+0.5+0.25)
桂林 = 0.25 /(1+0.5+0.25)假如我们的判断矩阵一致性可以接受,那么我们可以仿照一致矩阵权重的求法。
第一步:求出矩阵A的最大特征值以及其对应的特征向量
第二步:对求出的特征向量进行归一化即可得到我们的权重
最大特征值为3.0055 , 一致性比例 CR = 0.0053
对应的特征向量:[‐0.8902,‐0.4132,‐0.1918]
对其归一化:[0.5954,0.2764,0.1283]


将计算结果填入权重表:
然后逐一将每一个指标的数据填进去就行了。
求上面这个判断矩阵的权重:
汇总结果得到权重矩阵:
我们可以得到使用特征值法求得的权重矩阵,根据此矩阵,我们可以计算出每个旅游景点的得分。





计算各方案的得分:
苏杭得分:
类似的,我们可以得到北戴河得分为0.245,桂林得分为0.455.
因此小明最佳的旅游景点应该是桂林。
注意:这里用EXCEL计算可大大减轻工作量哦。
要点: F4可以锁定单元格。


二、模型总结
层次分析法第一步:
1.分析系统中各因素之间的关系,建立系统的递阶层次结构.
准则层—方案层的判断矩阵的数值要结合实际来填写,如果题目中有其他数据,可以考虑利用这些数据进行计算。例如:有一个指标是交通安全程度,现在要比较开放小区、半开放小区和封闭小区,而且你收集到了这些小区车流量的数据,那么就可以根据这个数据进行换算作为你的判断矩阵。
注意:如果你用到了层次分析法,那么这个层次结构图要放在你的建模论文中哦。
层次图如何制作呢?
①使用PPT自带的功能SmartArt生成;
②使用专业软件:亿图图示;
注:同类型的软件如Visio也是可以的~如果不想下载软件,可以使用在线的ProcessOn,也很方便。
层次分析法第二步:
2. 对于同一层次的各元素关于上一层次中某一准则的重要性进行两两比较,构造两两比较矩阵(判断矩阵)。
接下来构造判断矩阵:
上面这个矩阵的名称是:判断矩阵O — C
任何评价类模型都具有主观性。
理想:采用专家群体判断
现实:几乎都是自己填的层次分析法第三步:
- 由判断矩阵计算被比较元素对于该准则的相对权重,并进行一致性检验(检验通过权重才能用)。三种方法计算权重:
(1)算术平均法(2)几何平均法(3)特征值法强烈建议大家在比赛时三种方法都使用:
以往的论文利用层次分析法解决实际问题时,都是采用其中某一种方法求权重,而不同的计算方法可能会导致结果有所偏差。为了保证结果的稳健性,本文采用了三种方法分别求出了权重后计算平均值,再根据得到的权重矩阵计算各方案的得分,并进行排序和综合分析,这样避免了采用单一方法所产生的偏差,得出的结论将更全面、更有效。注:
(1)一致矩阵不需要进行一致性检验,只有非一致矩阵的判断矩阵才需要进行一致性检验;(2)在论文写作中,应该先进行一致性检验,通过检验后再计算权重,视频中讲解的只是为了顺应计算过程。
层次分析法第四步:
4 . 根据权重矩阵计算得分,并进行排序。




层次分析法可以参考优秀论文的做法,例如:
① 【2008年国赛B题一等奖】关于高等教育学费标准的评价及建议;
②【2016年国赛MATLAB创新奖B题】中国人民大学‐小区开放道路通行影响
层次分析法的一些局限性:
(1)评价的决策层不能太多,太多的话n会很大,判断矩阵和一致矩阵差异可能会很大。
注:平均随机一致性指标RI的表格中n最多是15。
(2)如果决策层中指标的数据是已知的,那么我们如何利用这些数据来使得评价的更加准确呢?
这个得自己思考一下。

三、模型Matlab代码详解
1.Matlab基本的小常识
分号的作用、注释的快捷键、clc和clear、disp和input等等。
(1)在每一行的语句后面加上分号(一定要是英文的哦;中文的长这个样子;)表示不显示运行结果,例如a = 3;
(2)多行注释:选中要注释的若干语句,快捷键Ctrl+R
(3)取消注释:选中要取消注释的语句,快捷键Ctrl+T
(4)clear可以清楚工作区的所有变量
(5)clc可以清除命令行窗口中的所有文本,让屏幕变得干净
(6)clear;clc 一起使用,起到“初始化”的作用,防止之前的结果对新脚本文件(后缀名是 .m)产生干扰。说明分号也用于区分行。
(7)输出和输入函数(disp 和 input)
disp函数:matlab中disp()就是屏幕输出函数,类似于c语言中的printf()函数
disp(‘我是花花,大家好鸭~~’)
input函数:一般我们会将输入的数、向量、矩阵、字符串等赋给一个变量,这里我们赋给A
A = input(‘请输入A:’);
B = input(‘请输入B:’)
注意观察工作区,并体会input后面加分号和不加分号的区别
(8)matlab中两个字符串的合并有两种方法
(a)strcat(str1,str2……,strn)
strcat(‘字符串1’,‘字符串2’)
(b)[str 1,str 2,……, str n]或[str1 str2 …… strn]
[‘字符串1’ ‘字符串2’]
[‘字符串1’,‘字符串2’]
一个有用的字符串函数:num2str 将数字转换为字符串
c = 100
num2str©
disp([‘c的取值为’ num2str©])
disp(strcat(‘c的取值为’, num2str©))
2. sum函数
(1)如果是向量(无论是行向量还是列向量),都是直接求和。
E = [1,2,3]
sum(E)
E = [1;2;3]
sum(E)(2)如果是矩阵,则需要根据行和列的方向作区分。
clc
E = [1,2;3,4;5,6]
a=sum(x); %按列求和(得到一个行向量)
a = sum(E)
a = sum(E,1) %1是按列求和(得到一个列向量)
% a=sum(x,2); %2是按行求和(得到一个列向量)
a = sum(E,2)
% a=sum(x(😃); %对整个矩阵求和
a = sum(sum(E))
a = sum(E(😃)
3. Matlab中如何提取矩阵中指定位置的元素?
(1)取指定行和列的一个元素(输出的是一个值)
clc; A=[1 1 4 1/3 3;1 1 4 1/3 3;1/4 1/4 1 1/3 1/2;3 3 3 1 3;1/3 1/3 2 1/3 1];
A
A(2,1)
A(3,2)(2)取指定的某一行的全部元素(输出的是一个行向量)
clc; A
A(2,:)
A(5,:)(3)取指定的某一列的全部元素(输出的是一个列向量)
clc; A
A(:,1)
A(:,3)(4)取指定的某些行的全部元素(输出的是一个矩阵)
clc; A
A([2,5]😅 % 只取第二行和第五行(一共2行)
A(2:5,:) % 取第二行到第五行(一共4行)
A(2:2:5,:) % 取第二行和第四行 (从2开始,每次递增2个单位,到5结束)
1:3:10
10👎1
A(2:end,:) % 取第二行到最后一行
A(2:end-1,:) % 取第二行到倒数第二行(5)取全部元素(按列拼接的,最终输出的是一个列向量)
clc; A
A(😃
4. size函数
clc;
A = [1,2,3;4,5,6]
B = [1,2,3,4,5,6]
size(A)
size(B)% size(A)函数是用来求矩阵A的大小的,它返回一个行向量,第一个元素是矩阵的行数,第二个元素是矩阵的列数
[r,c] = size(A)
% 将矩阵A的行数返回到第一个变量r,将矩阵的列数返回到第二个变量cr = size(A,1) %返回行数,注意后面的数字1、2
c = size(A,2) %返回列数
5. repmat函数
B = repmat(A,m,n): 将矩阵A复制m×n块,即把A作为B的元素,B由m×n个A平铺而成。
A = [1,2,3;4,5,6]
B = repmat(A,2,1) %列方向复制2倍,行方向复制1倍
B = repmat(A,3,2) %列方向复制3倍,行方向复制2倍
6. Matlab中矩阵的运算(加点和不加点)
MATLAB在矩阵的运算中,“*” 号和 “/” 号代表矩阵之间的乘法与除法(A / B = A*inv(B))
A = [1,2;3,4]
B = [1,0;1,1]
A * B
inv(B) % 求B的逆矩阵
B * inv(B)
A * inv(B)
A / B% 两个形状相同的矩阵对应元素之间的乘除法需要使用 “.*” 和 “./”
A = [1,2;3,4]
B = [1,0;1,1]
A .* B
A ./ B% 每个元素同时和常数相乘或相除操作都可以使用
A = [1,2;3,4]
A * 2
A .* 2
A / 2
A ./ 2% 每个元素同时乘方时只能用 .^
A = [1,2;3,4]
A .^ 2
A ^ 2
A * A
7. Matlab中求特征值和特征向量
Matlab中求特征值和特征向量
在Matlab中,计算矩阵A的特征值和特征向量的函数是eig(A),其中最常用的两个用法:
A = [1 2 3 ;2 2 1;2 0 3](1)E=eig(A):求矩阵A的全部特征值,构成向量E。
E=eig(A)(2)[V,D]=eig(A):求矩阵A的全部特征值,构成对角阵D,并求A的特征向量构成 V 的列向量。
(V的每一列都是D中与之相同列的特征值的特征向量)
[V,D]=eig(A)
8. find函数的基本用法
下面例子来自博客:https://www.cnblogs.com/anzhiwu815/p/5907033.html 博客内有更加深入的探究

既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
值和特征向量的函数是eig(A),其中最常用的两个用法:
A = [1 2 3 ;2 2 1;2 0 3]
(1)E=eig(A):求矩阵A的全部特征值,构成向量E。
E=eig(A)(2)[V,D]=eig(A):求矩阵A的全部特征值,构成对角阵D,并求A的特征向量构成 V 的列向量。
(V的每一列都是D中与之相同列的特征值的特征向量)
[V,D]=eig(A)
8. find函数的基本用法
下面例子来自博客:https://www.cnblogs.com/anzhiwu815/p/5907033.html 博客内有更加深入的探究
[外链图片转存中…(img-t1qwjGTO-1715253162016)]
[外链图片转存中…(img-BZLjLRl5-1715253162016)]
[外链图片转存中…(img-b9TBOK9F-1715253162016)]
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









