






2022年的10月,在Stable Diffusion刚刚开源的日子里,所有人都沉迷于其无限的可能和巨大的魔力。每个人都在用不同的关键词排列组合,尝试着生成各种各样有趣的内容。然而,当人们想要稳定地生成一些特定的角色,或者尝试稳定的生成特定的作品风格时,却发现Stable Diffusion并没有他们想得那么可控。事实上,Stable Diffusion生成的特征吻合度密切正比于你想要生成东西的知名度。因为越是知名的东西,训练集里所包含的样本数就越多,Stable Diffusion也就越能够掌握其特征。比如初音未来,常年位居同人绘画的创作数第一,拥有大量的样本数据。在当时就可以通过其角色名 (miku),加上一些特征提示词(双马尾,蓝绿头发,百褶裙等),生成比较符合角色特征的图片。

本图生成于2022年11月9日,是当时我应朋友要求生成的一张初音未来图片,他是初音的粉丝
然而,对于一些并不那么出名的角色而言,仅凭提示词就想生成符合角色特征的图片就非常非常困难了。那这个时候我们怎么去控制Stable Diffusion生成符合角色特征的图片呢?从最开始的Textual Inversion,到DreamBooth,再到革命性的LoRA, 都是为了解决这个问题而生的。这篇文章我们就简单的来梳理以下这几项技术的发展史。
一,Textual Inversion
Textual Inversion的思路非常非常的简单。举例来说,现在我们想要通过"a photo of Nahida"生成一张《原神》里面小草神纳西妲的图像:

a photo of Nahida的目标—— 一张纳西妲的图像
但是,Stable Diffusion不认识“Nahida”这个名字,它不知道一个叫“Nahida”的角色到底有什么样的特征。如果你读过我上一篇的有关文字如何控制Diffusion的文章的话,你就会知道其实是一个叫做CLIP的语言模型负责辨别我们输入进去的词汇的。因此,Stable Diffusion不认识“Nahida”这个名字, 归根结底可以看成是CLIP这个语言模型不认识“Nahida”这个名字,因此CLIP没办法把这个词转换成合适的语义向量(embedding), Stable Diffusion也就没办法得知对应的视觉信息。
那如何解决这个问题呢?很简单,我们训练一个叫“Nahida”语义向量就好啦。我们先给“Nahida”这个词创建一个专有名称(对应下图 S∗S^*),我们再给这个专有名称S∗S^*配对一个专有的语义向量(对应下图 v∗v^*) 。这样CLIP一见到你输入了Nahida这个词,就知道这是个专有名词,它就知道应该去找对应的语义向量 v∗v^* 作为输入了。
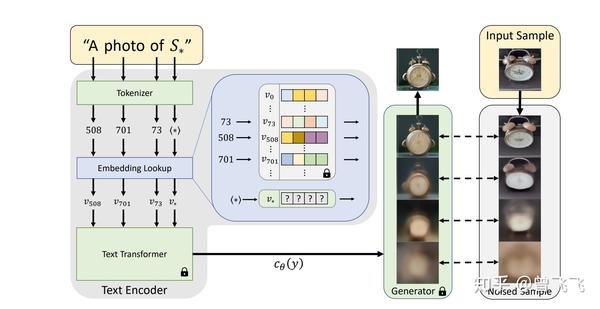
当你用足够的图片(20~30张左右),训练这个语义向量 v∗v^*,训练完成后就能够用Nahida这个词语生成一张包含纳西妲的图片啦。
上面是一些训练集示例,下面是训练过程中的效果,大概在2500steps的时候产生了比较合理的效果。

值得注意的是,上面这些示例图实在仅仅采用“a photo of Nahida”的时候所产生的样例图,所以看上去视觉效果较差。一旦合理地去调整prompt,Textual Inversion还是能够产出效果较为不错的图片的。同时,由于大部分Stable Diffusion的模型都是1.5版本的,其语义模型都采用的是CLIP模型,因此你在一个模型上训练好的语义向量往往可以无缝衔接到另外一个模型上。

二,DreamBooth
由于模型在训练过程中只需要保存一条语义向量就足够,因此Textual Inversion相对来说储存占用空间较小,一般十几KB就足够了。然而,这也带来了一个弊端,那就是Textual Inversion保存的信息有限,生成的角色的特征一般有点像,但又没那么像。同时,如果你要训练一些特定画风的模型,比如最近大火的真人模型chilloutmix,或者经典的二次元模型Anything V3,那这些画风层次上的控制就更不可能用几十kb的小小embedding来满足。
这就要提到另外一项技术DreamBooth了。这项技术的影响非常深远,几乎目前所有在市面上流通的模型都是采用DreamBooth炼制出来的Stable Diffusion V1.5的变种。同时,它的思想也并不复杂。对比起上面Textual Inversion一点模型的参数都不改,DreamBooth做的就极端很多了,它几乎改了整个模型的所有参数,因此训练出来的结果俨然就是个全新的Stable Diffusion 模型,大小都是一样大的,大概8G左右。(当然你也可以通过降低精度来缩小模型,比如改成fp16精度或者fp8精度。模型的大小就会缩小到1/2或者1/4)
那具体来说DreamBooth是怎么改变Stable Diffusion 模型的参数的呢?整体来说也很简单,以下面的狗狗为例,同样我们先指定一个专有名词作给这个小狗,不过DreamBooth里面把它叫做 [V][V] 而不是上面的 S∗S^* . 同时,这次你还需要给你想要生成的物体指定一个类别,比如说我们用 A dogA\ dog 来指定“dog”作为专有名词[V][V]的类别。这样的话,我们最终的目标就是在输入“ A [V] dogA \ [V]\ dog ”的情况下,模型可以输出我们训练集中的那只小狗图片,就算成功了。
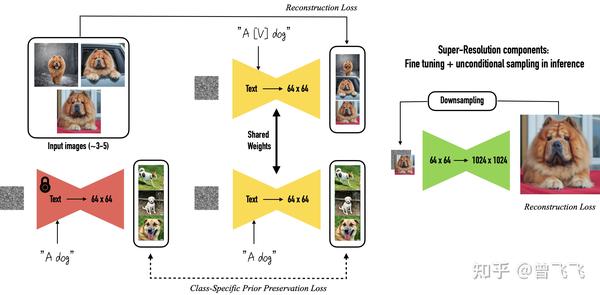
DreamBooth的想法是要保证两件事,第一是我们生成的结果要像这只狗,这也是最基本的要求,第二是要保证你原来的模型不能被这个新的finetune过程破坏,也就是说受训练的模型不应该在训练后忘记它原本有的知识和能力。
那么首先第一点,为了保证结果像我们给出的这只狗,我们只要输入“ A [V] dogA \ [V]\ dog ”然后去计算和原始图片集的Reconstruction Loss就好了。同时,因为DreamBooth里谷歌用的是他们自家的Imagen模型,所有里面是有超分辨率的模块的。为了保证细节上的一致性,谷歌就额外训练了他们的超分辨率模块,来确保模型能够恢复图像细节上的信息。
第二点,我们必须保证原来模型的知识不能在finetune的过程中被破坏,这是很重要的一点,也往往很容易被忽视。如果我对模型不加以约束,单纯用上面的Reconstruction Loss去训练,模型很容易就会过拟合到这只狗上。这样的话,就算我想要模型生成一只平平无奇的狗,模型可能也会丢给我一张训练用的狗狗图片。因此,dreambooth在训练之前,会先随机生成一些随机的狗的图片,一般50张左右,在训练的过程中用Prior Preservation Loss对模型加以约束,让模型不要跑的太偏。不加约束的话,就会出现下面实验中的情况。当我输入"A dogA\ dog"而不是“ A [V] dogA \ [V]\ dog ”的时候,模型生成的图片却也都是训练集里柯基的样子(下图第二行),这明显就过拟合了。当我们加了Prior Preservation Loss之后,模型便不会过拟合,它就又能够生成平平无奇的普通狗狗了,就像图片最后一行中所展示的结果一样。

第一行是没有Finetune的模型,可以生成多样的狗,第二行finetune但不加prior loss,就只能生成过拟合的狗了
三,LoRA:新时代
DreamBooth的效果说好确实好,角色特征说像也确实像,但是就是模型太大了点,一个角色要占2~8个G。而且DreamBooth炼制出来的角色特征还不通用,假如我在某个A画风的模型上炼制的角色模型,当我想要生成B\C画风下的同一个角色时,我又得在B\C模型上去重新炼制了。这样的效率实在是过于低下,因此至今为止DreamBooth都仅仅是用来训练特定画风的模型,而很少用于训练角色。(尽管它训练出来的角色效果很好)
那有没有一个模型,既能够保存小巧的储存空间,又能够非常高精度的保留角色特征呢?今年春节前后,很多惊艳的AI绘画图片大量地出现在各大讨论群中,一个叫作LoRA的技术渐渐为大众所知。
事实上,LoRA并不是一项新技术,早在2021年,微软便发表了相关的论文。当然,当时的LoRA针对的并不是Stable Diffusion这种生成模型的finetune,而是GPT这样大型的语言模型的finetune。
LoRA的主要思想在于,当一个大型神经网络在大量数据上进行训练时,它会学习到一种可以用较少维度来捕捉数据特征的简单数据表示,这就是文中所谓的low intrinsic dimension。所以当网络适应新任务时,它的权重变化也很是低维度的,这个过程便可以用一个低秩矩阵来表示。LoRA就采用了一个可训练的低秩矩阵来帮助Transformer适应新任务。
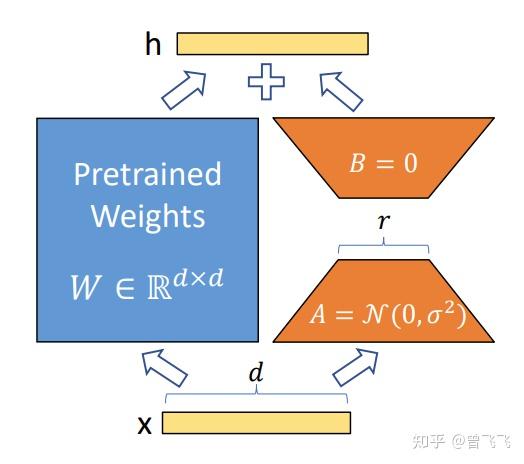
假如原来预训练的模型可以用上图中的蓝色方块( WW 矩阵)代替,那么原来的forward过程可以看作 h = Wxh \ =\ Wx . 现在我们用一个类似ResNet的额外连接 x→A→B→hx\to A\to B\to h ,把输入x和输出h联系起来。不同之处在于,ResNet是直接连接,我们这里采用可训练的矩阵(橙色的 和A和BA和B )来连接。此时forward过程就变换为 h = Wx+BAxh\ =\ Wx+BAx 。A矩阵的作用是对x进行降维,B矩阵再把维度升上去,两次矩阵乘法相当于一个Encoder一个Decoder,这样就完成了这么一个跳跃连接的过程。最开始训练的时候,我们初始化A的参数为正太分布的 N(0,σ2)N(0,\sigma^2) , B为全零矩阵,那样的话刚开始的时候 BAx=0BAx=0 ,对forward过程不造成影响, forward过程就和初始的过程保持一致了。在这个基础上我们再对A和B矩阵的参数加以训练,就可以完成Finetune的过程了。(P. S. 甚至感觉有点像最近的ControlNet的原理。)
这次我们采用LoRA重新训练一下纳西妲,就能出来非常非常符合角色特征的图片了。

服饰,发饰几乎完全一致,LoRA的效果非常的好,春节的那段时候震惊了许多人
最近很热门的真人Cosplay很大程度上也归因于LoRA对角色特征的还原:

LoRA来源:https://civitai.com/models/11896/raiden-shogun-or-realistic-genshin-lora
甚至还有人利用中国水墨画训练了水墨风格的LoRA,非常令人惊艳。

LoRA来源:https://civitai.com/models/12597/moxin
四,总结
目前Stable Diffusion的主流finetune方法基本上就是Textual Inversion,DreamBooth以及LoRA。其中,Textual Inversion已经渐渐被LoRA所取代,但谁也说不准,以后又会有什么更好更强大的方法可能会取代掉LoRA。这半年来我们见证了这项技术太多的突飞猛进,我相信它的进化也仍然没有结束,ChatGPT也是如此。而这个时代的我们正在真正的见证着一项新的强大技术的到来—— 一如70年代的微处理器,80年代的PC,90/00年代的互联网,以及10年代的移动终端。
最后的最后,码字不易,喜欢的话可以点个赞或者收藏,作者会很开心的。后续作者也会更新更多关于深度学习领域的内容,感兴趣的话也可以关注一下哦~
1.stable diffusion安装包
随着技术的迭代,目前 Stable Diffusion 已经能够生成非常艺术化的图片了,完全有赶超人类的架势,已经有不少工作被这类服务替代,比如制作一个 logo 图片,画一张虚拟老婆照片,画质堪比相机。
最新 Stable Diffusion 除了有win多个版本,就算说底端的显卡也能玩了哦!此外还带来了Mac版本,仅支持macOS 12.3或更高版本。

2.stable diffusion视频合集
我们在学习的时候,往往书籍源码难以理解,阅读困难,这时候视频教程教程是就很适合了,生动形象加上案例实战,一步步带你入坑stable diffusion,科学有趣才能更方便的学习下去。

3.stable diffusion模型下载
stable diffusion往往一开始使用时图片等无法达到理想的生成效果,这时则需要通过使用大量训练数据,调整模型的超参数(如学习率、训练轮数、模型大小等),可以使得模型更好地适应数据集,并生成更加真实、准确、高质量的图像。

4.stable diffusion提示词
提示词是构建由文本到图像模型解释和理解的单词的过程。可以把它理解为你告诉 AI 模型要画什么而需要说的语言,整个SD学习过程中都离不开这本提示词手册。

5.SD从0到落地实战演练

如果你能在15天内完成所有的任务,那你堪称天才。然而,如果你能完成 60-70% 的内容,你就已经开始具备成为一名SD大神的正确特征了。
这份完整版的stable diffusion资料我已经打包好,需要的点击下方插件,即可前往免费领取!


















 3137
3137

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









