








一、导言
《ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design》提出了一种新的卷积神经网络(CNN)架构设计方法,并给出了一系列实用的设计指南,旨在提高模型在实际应用中的效率。其优点主要体现在以下几个方面:
-
直接性能指标评估:传统的CNN设计往往侧重于计算复杂度(如FLOPs)这一间接指标,而该研究主张在目标平台上直接评估模型的速度等直接性能指标。这考虑到了内存访问成本和平台特性等其他因素,从而提供了更贴近实际应用场景的性能评估方式。
-
实用性设计原则:通过一系列控制实验,文章得出了几条高效网络设计的实用原则,比如平衡卷积、注意分组卷积的成本、减少网络碎片化以及限制逐元素运算等,这些原则对实际设计轻量化、高效率网络具有重要指导意义。
-
ShuffleNet V2架构:基于上述设计原则,论文介绍了一个新架构——ShuffleNet V2,该架构不仅优化了特征重用模式,类似于DenseNet在保持高精度的同时提高了效率,而且在速度与精度权衡上达到了当时最优。
-
详实的实验验证:作者在ImageNet 2012分类数据集上进行了广泛的消融实验,比较了不同复杂度级别的ShuffleNet V2与其他知名网络架构(如ShuffleNet V1、MobileNet V2、Xception、DenseNet)的性能。实验结果全面展示了ShuffleNet V2在速度与精度上的优越性,并通过各种配置的比较,验证了所提设计原则的有效性。
-
对实际问题的洞察:研究揭示了在不同任务(如图像分类与对象检测)中,网络表现排名的变化,特别是指出扩大感受野对检测任务的重要性,并据此提出了ShuffleNet V2*变体,通过增加少量FLOPs进一步提升了准确性,为未来工作指明了方向。
-
跨平台考虑:文档不仅关注GPU上的性能,还考虑了ARM平台的表现,显示了不同设计选择对不同硬件环境的影响,增强了设计的通用性和实用性。
综上所述,这篇文档通过提供一套面向实践的CNN设计原则和一个高效的网络架构ShuffleNet V2,对推动深度学习模型设计领域的发展做出了重要贡献,尤其是在追求高效、轻量化模型设计方面。

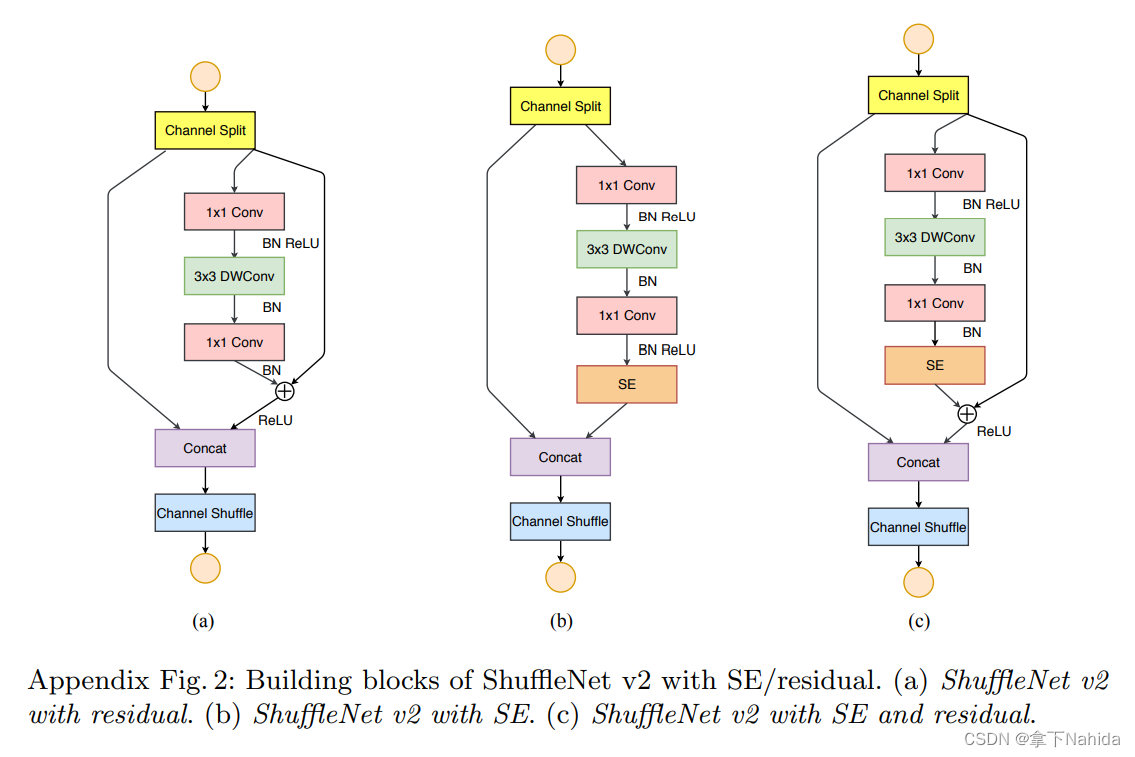
二、准备工作
首先在YOLOv5/v7项目文件下的models文件夹下创建新的文件shufflenetv2.py
导入如下代码
from models.common import *
def channel_shuffle(x, groups):
batchsize, num_channels, height, width = x.data.size()
channels_per_group = num_channels // groups
# reshape
x = x.view(batchsize, groups,
channels_per_group, height, width)
x = torch.transpose(x, 1, 2).contiguous()
# flatten
x = x.view(batchsize, -1, height, width)
return x
class conv_bn_relu_maxpool(nn.Module):
def __init__(self, c1, c2): # ch_in, ch_out
super(conv_bn_relu_maxpool, self).__init__()
self.conv = nn.Sequential(
nn.Conv2d(c1, c2, kernel_size=3, stride=2, padding=1, bias=False),
nn.BatchNorm2d(c2),
nn.ReLU(inplace=True),
)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
def forward(self, x):
return self.maxpool(self.conv(x))
class Shuffle_Block(nn.Module):
def __init__(self, inp, oup, stride):
super(Shuffle_Block, self).__init__()
if not (1 <= stride <= 3):
raise ValueError('illegal stride value')
self.stride = stride
branch_features = oup // 2
assert (self.stride != 1) or (inp == branch_features << 1)
if self.stride > 1:
self.branch1 = nn.Sequential(
self.depthwise_conv(inp, inp, kernel_size=3, stride=self.stride, padding=1),
nn.BatchNorm2d(inp),
nn.Conv2d(inp, branch_features, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(branch_features),
nn.ReLU(inplace=True),
)
self.branch2 = nn.Sequential(
nn.Conv2d(inp if (self.stride > 1) else branch_features,
branch_features, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(branch_features),
nn.ReLU(inplace=True),
self.depthwise_conv(branch_features, branch_features, kernel_size=3, stride=self.stride, padding=1),
nn.BatchNorm2d(branch_features),
nn.Conv2d(branch_features, branch_features, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(branch_features),
nn.ReLU(inplace=True),
)
@staticmethod
def depthwise_conv(i, o, kernel_size, stride=1, padding=0, bias=False):
return nn.Conv2d(i, o, kernel_size, stride, padding, bias=bias, groups=i)
def forward(self, x):
if self.stride == 1:
x1, x2 = x.chunk(2, dim=1) # 按照维度1进行split
out = torch.cat((x1, self.branch2(x2)), dim=1)
else:
out = torch.cat((self.branch1(x), self.branch2(x)), dim=1)
out = channel_shuffle(out, 2)
return out其次在在YOLOv5/v7项目文件下的models/yolo.py中在文件首部添加代码
from models.shufflenetv2 import *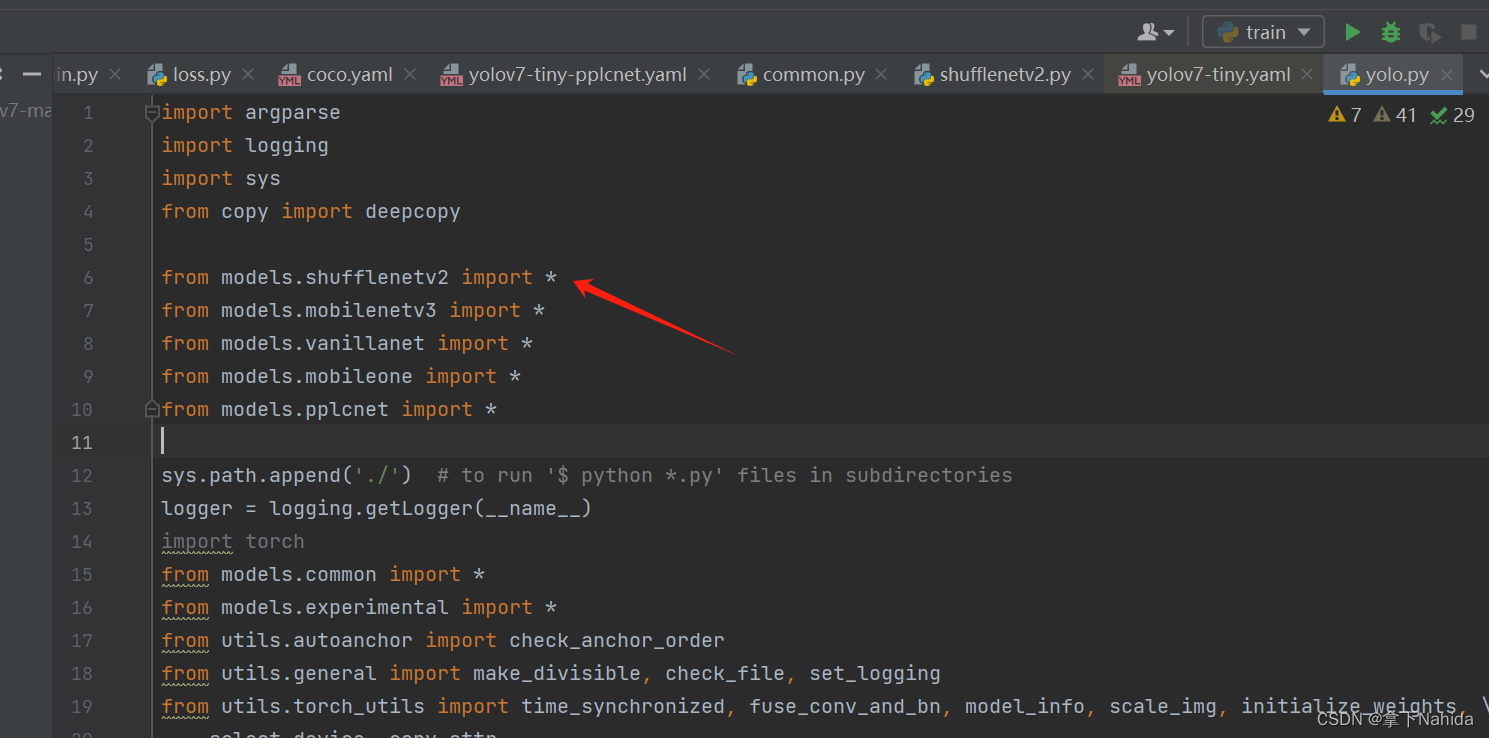
并搜索def parse_model(d, ch)
定位到如下行添加以下代码
conv_bn_relu_maxpool, Shuffle_Block, # ShuffleNetv2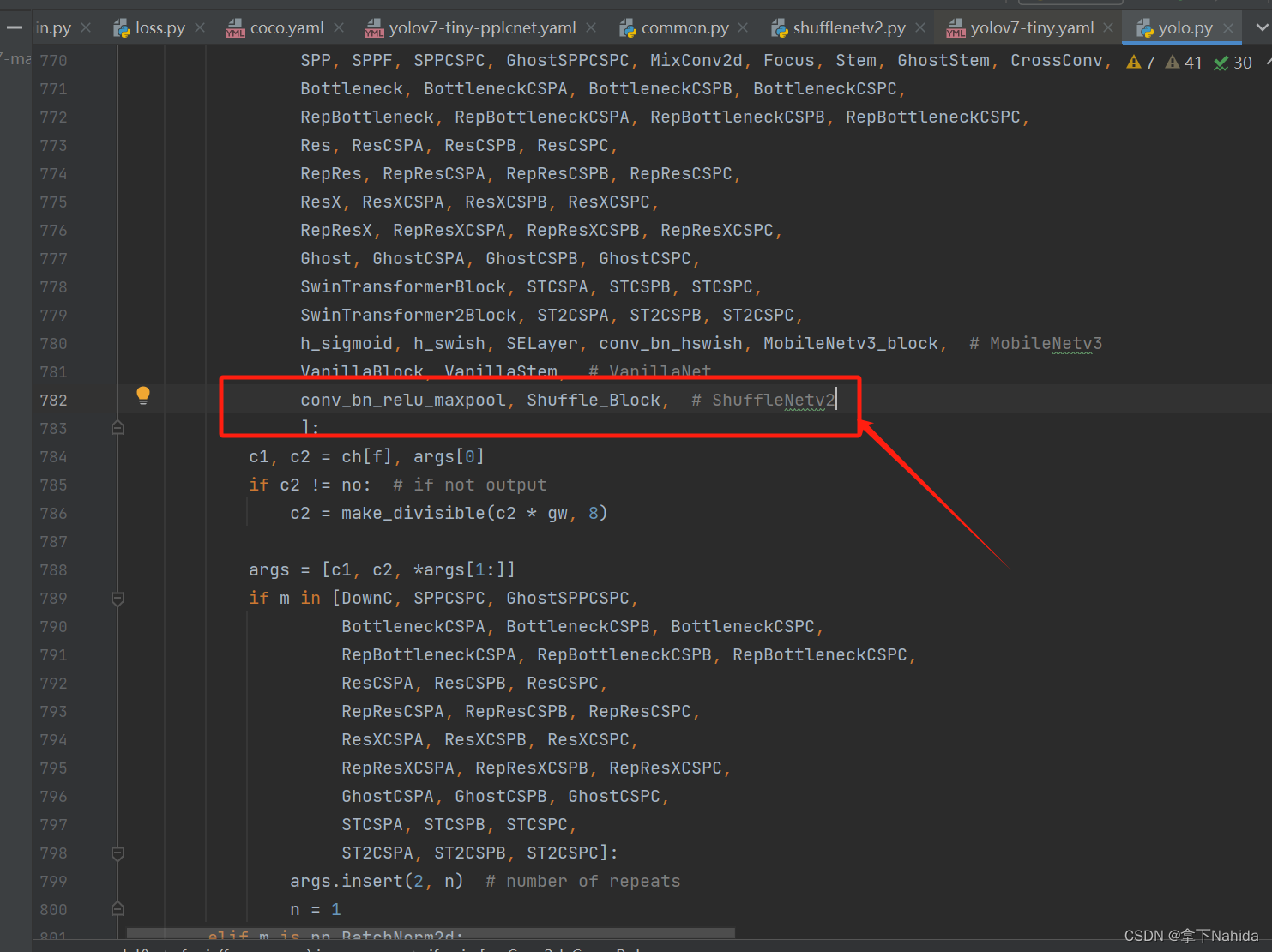
三、YOLOv7-tiny改进工作
完成二后,在YOLOv5项目文件下的models文件夹下创建新的文件yolov7-tiny-shufflenetv2.yaml,导入如下代码。
# parameters
nc: 80 # number of classes
depth_multiple: 1.0 # model depth multiple
width_multiple: 1.0 # layer channel multiple
# anchors
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# yolov7-tiny backbone
backbone:
# [from, number, module, args]
# Shuffle_Block: [out, stride]
[[ -1, 1, conv_bn_relu_maxpool, [ 32 ] ], # 0-P2/4
[ -1, 1, Shuffle_Block, [ 128, 2 ] ], # 1-P3/8
[ -1, 3, Shuffle_Block, [ 128, 1 ] ], # 2
[ -1, 1, Shuffle_Block, [ 256, 2 ] ], # 3-P4/16
[ -1, 7, Shuffle_Block, [ 256, 1 ] ], # 4
[ -1, 1, Shuffle_Block, [ 512, 2 ] ], # 5-P5/32
[ -1, 3, Shuffle_Block, [ 512, 1 ] ], # 6
]
# yolov7-tiny head
head:
[[-1, 1, Conv, [256, 1, 1, None, 1, nn.LeakyReLU(0.1)]],
[-2, 1, Conv, [256, 1, 1, None, 1, nn.LeakyReLU(0.1)]],
[-1, 1, SP, [5]],
[-2, 1, SP, [9]],
[-3, 1, SP, [13]],
[[-1, -2, -3, -4], 1, Concat, [1]],
[-1, 1, Conv, [256, 1, 1, None, 1, nn.LeakyReLU(0.1)]],
[[-1, -7], 1, Concat, [1]],
[-1, 1, Conv, [256, 1, 1, None, 1, nn.LeakyReLU(0.1)]], # 37-15
[-1, 1, Conv, [128, 1, 1, None, 1, nn.LeakyReLU(0.1)]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[4, 1, Conv, [128, 1, 1, None, 1, nn.LeakyReLU(0.1)]], # route backbone P4
[[-1, -2], 1, Concat, [1]],
[-1, 1, Conv, [64, 1, 1, None, 1, nn.LeakyReLU(0.1)]],
[-2, 1, Conv, [64, 1, 1, None, 1, nn.LeakyReLU(0.1)]],
[-1, 1, Conv, [64, 3, 1, None, 1, nn.LeakyReLU(0.1)]],
[-1, 1, Conv, [64, 3, 1, None, 1, nn.LeakyReLU(0.1)]],
[[-1, -2, -3, -4], 1, Concat, [1]],
[-1, 1, Conv, [128, 1, 1, None, 1, nn.LeakyReLU(0.1)]], # 47-25
[-1, 1, Conv, [64, 1, 1, None, 1, nn.LeakyReLU(0.1)]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[2, 1, Conv, [64, 1, 1, None, 1, nn.LeakyReLU(0.1)]], # route backbone P3
[[-1, -2], 1, Concat, [1]],
[-1, 1, Conv, [32, 1, 1, None, 1, nn.LeakyReLU(0.1)]],
[-2, 1, Conv, [32, 1, 1, None, 1, nn.LeakyReLU(0.1)]],
[-1, 1, Conv, [32, 3, 1, None, 1, nn.LeakyReLU(0.1)]],
[-1, 1, Conv, [32, 3, 1, None, 1, nn.LeakyReLU(0.1)]],
[[-1, -2, -3, -4], 1, Concat, [1]],
[-1, 1, Conv, [64, 1, 1, None, 1, nn.LeakyReLU(0.1)]], # 57-35
[-1, 1, Conv, [128, 3, 2, None, 1, nn.LeakyReLU(0.1)]],
[[-1, 25], 1, Concat, [1]],
[-1, 1, Conv, [64, 1, 1, None, 1, nn.LeakyReLU(0.1)]],
[-2, 1, Conv, [64, 1, 1, None, 1, nn.LeakyReLU(0.1)]],
[-1, 1, Conv, [64, 3, 1, None, 1, nn.LeakyReLU(0.1)]],
[-1, 1, Conv, [64, 3, 1, None, 1, nn.LeakyReLU(0.1)]],
[[-1, -2, -3, -4], 1, Concat, [1]],
[-1, 1, Conv, [128, 1, 1, None, 1, nn.LeakyReLU(0.1)]], # 65-43
[-1, 1, Conv, [256, 3, 2, None, 1, nn.LeakyReLU(0.1)]],
[[-1, 15], 1, Concat, [1]],
[-1, 1, Conv, [128, 1, 1, None, 1, nn.LeakyReLU(0.1)]],
[-2, 1, Conv, [128, 1, 1, None, 1, nn.LeakyReLU(0.1)]],
[-1, 1, Conv, [128, 3, 1, None, 1, nn.LeakyReLU(0.1)]],
[-1, 1, Conv, [128, 3, 1, None, 1, nn.LeakyReLU(0.1)]],
[[-1, -2, -3, -4], 1, Concat, [1]],
[-1, 1, Conv, [256, 1, 1, None, 1, nn.LeakyReLU(0.1)]], # 73-51
[35, 1, Conv, [128, 3, 1, None, 1, nn.LeakyReLU(0.1)]],
[43, 1, Conv, [256, 3, 1, None, 1, nn.LeakyReLU(0.1)]],
[51, 1, Conv, [512, 3, 1, None, 1, nn.LeakyReLU(0.1)]],
[[52,53,54], 1, IDetect, [nc, anchors]], # Detect(P3, P4, P5)
]
from n params module arguments
0 -1 1 928 models.shufflenetv2.conv_bn_relu_maxpool[3, 32]
1 -1 1 9632 models.shufflenetv2.Shuffle_Block [32, 128, 2]
2 -1 3 27456 models.shufflenetv2.Shuffle_Block [128, 128, 1]
3 -1 1 52736 models.shufflenetv2.Shuffle_Block [128, 256, 2]
4 -1 7 242816 models.shufflenetv2.Shuffle_Block [256, 256, 1]
5 -1 1 203776 models.shufflenetv2.Shuffle_Block [256, 512, 2]
6 -1 3 404736 models.shufflenetv2.Shuffle_Block [512, 512, 1]
7 -1 1 131584 models.common.Conv [512, 256, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]
8 -2 1 131584 models.common.Conv [512, 256, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]
9 -1 1 0 models.common.SP [5]
10 -2 1 0 models.common.SP [9]
11 -3 1 0 models.common.SP [13]
12 [-1, -2, -3, -4] 1 0 models.common.Concat [1]
13 -1 1 262656 models.common.Conv [1024, 256, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]
14 [-1, -7] 1 0 models.common.Concat [1]
15 -1 1 131584 models.common.Conv [512, 256, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]
16 -1 1 33024 models.common.Conv [256, 128, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]
17 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
18 4 1 33024 models.common.Conv [256, 128, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]
19 [-1, -2] 1 0 models.common.Concat [1]
20 -1 1 16512 models.common.Conv [256, 64, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]
21 -2 1 16512 models.common.Conv [256, 64, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]
22 -1 1 36992 models.common.Conv [64, 64, 3, 1, None, 1, LeakyReLU(negative_slope=0.1)]
23 -1 1 36992 models.common.Conv [64, 64, 3, 1, None, 1, LeakyReLU(negative_slope=0.1)]
24 [-1, -2, -3, -4] 1 0 models.common.Concat [1]
25 -1 1 33024 models.common.Conv [256, 128, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]
26 -1 1 8320 models.common.Conv [128, 64, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]
27 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
28 2 1 8320 models.common.Conv [128, 64, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]
29 [-1, -2] 1 0 models.common.Concat [1]
30 -1 1 4160 models.common.Conv [128, 32, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]
31 -2 1 4160 models.common.Conv [128, 32, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]
32 -1 1 9280 models.common.Conv [32, 32, 3, 1, None, 1, LeakyReLU(negative_slope=0.1)]
33 -1 1 9280 models.common.Conv [32, 32, 3, 1, None, 1, LeakyReLU(negative_slope=0.1)]
34 [-1, -2, -3, -4] 1 0 models.common.Concat [1]
35 -1 1 8320 models.common.Conv [128, 64, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]
36 -1 1 73984 models.common.Conv [64, 128, 3, 2, None, 1, LeakyReLU(negative_slope=0.1)]
37 [-1, 25] 1 0 models.common.Concat [1]
38 -1 1 16512 models.common.Conv [256, 64, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]
39 -2 1 16512 models.common.Conv [256, 64, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]
40 -1 1 36992 models.common.Conv [64, 64, 3, 1, None, 1, LeakyReLU(negative_slope=0.1)]
41 -1 1 36992 models.common.Conv [64, 64, 3, 1, None, 1, LeakyReLU(negative_slope=0.1)]
42 [-1, -2, -3, -4] 1 0 models.common.Concat [1]
43 -1 1 33024 models.common.Conv [256, 128, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]
44 -1 1 295424 models.common.Conv [128, 256, 3, 2, None, 1, LeakyReLU(negative_slope=0.1)]
45 [-1, 15] 1 0 models.common.Concat [1]
46 -1 1 65792 models.common.Conv [512, 128, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]
47 -2 1 65792 models.common.Conv [512, 128, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]
48 -1 1 147712 models.common.Conv [128, 128, 3, 1, None, 1, LeakyReLU(negative_slope=0.1)]
49 -1 1 147712 models.common.Conv [128, 128, 3, 1, None, 1, LeakyReLU(negative_slope=0.1)]
50 [-1, -2, -3, -4] 1 0 models.common.Concat [1]
51 -1 1 131584 models.common.Conv [512, 256, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]
52 35 1 73984 models.common.Conv [64, 128, 3, 1, None, 1, LeakyReLU(negative_slope=0.1)]
53 43 1 295424 models.common.Conv [128, 256, 3, 1, None, 1, LeakyReLU(negative_slope=0.1)]
54 51 1 1180672 models.common.Conv [256, 512, 3, 1, None, 1, LeakyReLU(negative_slope=0.1)]
55 [52, 53, 54] 1 17132 models.yolo.IDetect [1, [[10, 13, 16, 30, 33, 23], [30, 61, 62, 45, 59, 119], [116, 90, 156, 198, 373, 326]], [128, 256, 512]]
Model Summary: 352 layers, 4492652 parameters, 4492652 gradients, 8.5 GFLOPS运行后若打印出如上文本代表改进成功。
四、YOLOv5s改进工作
完成二后,在YOLOv5项目文件下的models文件夹下创建新的文件yolov5s-shufflenetv2.yaml,导入如下代码。
nc: 80 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 v6.0 backbone
# custom backbone
backbone:
# [from, number, module, args]
[[-1, 1, conv_bn_relu_maxpool, [32]], # 0-P2/4
[-1, 1, Shuffle_Block, [128, 2]], # 1-P3/8
[-1, 3, Shuffle_Block, [128, 1]], # 2
[-1, 1, Shuffle_Block, [256, 2]], # 3-P4/16
[-1, 7, Shuffle_Block, [256, 1]], # 4
[-1, 1, Shuffle_Block, [512, 2]], # 5-P5/32
[-1, 3, Shuffle_Block, [512, 1]], # 6
]
# YOLOv5 head
head:
[[-1, 1, Conv, [512, 1, 1]], # 7
[-1, 1, nn.Upsample, [None, 2, 'nearest']], # 8
[[-1, 4], 1, Concat, [1]], # cat backbone P4 # 9
[-1, 1, C3, [512, False]], # 10
[-1, 1, Conv, [256, 1, 1]], # 11
[-1, 1, nn.Upsample, [None, 2, 'nearest']], # 12
[[-1, 2], 1, Concat, [1]], # cat backbone P3 # 13
[-1, 1, C3, [256, False]], # 14 (P3/8-small) # 14
[-1, 1, Conv, [128, 3, 2]], # 15
[[-1, 11], 1, Concat, [1]], # cat head P4 # 16
[-1, 1, C3, [256, False]], # 17 (P4/16-medium) # 17
[-1, 1, Conv, [256, 3, 2]], # 18
[[-1, 7], 1, Concat, [1]], # cat head P5 # 19
[-1, 1, C3, [512, False]], # 20 (P5/32-large) # 20
[[14, 17, 20], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
from n params module arguments
0 -1 1 232 models.shufflenetv2.conv_bn_relu_maxpool[3, 8]
1 -1 1 872 models.shufflenetv2.Shuffle_Block [8, 32, 2]
2 -1 1 752 models.shufflenetv2.Shuffle_Block [32, 32, 1]
3 -1 1 3968 models.shufflenetv2.Shuffle_Block [32, 64, 2]
4 -1 2 5056 models.shufflenetv2.Shuffle_Block [64, 64, 1]
5 -1 1 14080 models.shufflenetv2.Shuffle_Block [64, 128, 2]
6 -1 1 9152 models.shufflenetv2.Shuffle_Block [128, 128, 1]
7 -1 1 16640 models.common.Conv [128, 128, 1, 1]
8 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
9 [-1, 4] 1 0 models.common.Concat [1]
10 -1 1 82688 models.common.C3 [192, 128, 1, False]
11 -1 1 8320 models.common.Conv [128, 64, 1, 1]
12 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
13 [-1, 2] 1 0 models.common.Concat [1]
14 -1 1 20864 models.common.C3 [96, 64, 1, False]
15 -1 1 18496 models.common.Conv [64, 32, 3, 2]
16 [-1, 11] 1 0 models.common.Concat [1]
17 -1 1 20864 models.common.C3 [96, 64, 1, False]
18 -1 1 36992 models.common.Conv [64, 64, 3, 2]
19 [-1, 7] 1 0 models.common.Concat [1]
20 -1 1 82688 models.common.C3 [192, 128, 1, False]
21 [14, 17, 20] 1 4662 models.yolo.Detect [1, [[10, 13, 16, 30, 33, 23], [30, 61, 62, 45, 59, 119], [116, 90, 156, 198, 373, 326]], [64, 64, 128]]
Model Summary: 216 layers, 326326 parameters, 326326 gradients, 1.0 GFLOPs运行后若打印出如上文本代表改进成功。
五、YOLOv5n改进工作
完成二后,在YOLOv5项目文件下的models文件夹下创建新的文件yolov5s-shufflenetv2.yaml,导入如下代码。
nc: 80 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.25 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 v6.0 backbone
# custom backbone
backbone:
# [from, number, module, args]
[[-1, 1, conv_bn_relu_maxpool, [32]], # 0-P2/4
[-1, 1, Shuffle_Block, [128, 2]], # 1-P3/8
[-1, 3, Shuffle_Block, [128, 1]], # 2
[-1, 1, Shuffle_Block, [256, 2]], # 3-P4/16
[-1, 7, Shuffle_Block, [256, 1]], # 4
[-1, 1, Shuffle_Block, [512, 2]], # 5-P5/32
[-1, 3, Shuffle_Block, [512, 1]], # 6
]
# YOLOv5 head
head:
[[-1, 1, Conv, [512, 1, 1]], # 7
[-1, 1, nn.Upsample, [None, 2, 'nearest']], # 8
[[-1, 4], 1, Concat, [1]], # cat backbone P4 # 9
[-1, 1, C3, [512, False]], # 10
[-1, 1, Conv, [256, 1, 1]], # 11
[-1, 1, nn.Upsample, [None, 2, 'nearest']], # 12
[[-1, 2], 1, Concat, [1]], # cat backbone P3 # 13
[-1, 1, C3, [256, False]], # 14 (P3/8-small) # 14
[-1, 1, Conv, [128, 3, 2]], # 15
[[-1, 11], 1, Concat, [1]], # cat head P4 # 16
[-1, 1, C3, [256, False]], # 17 (P4/16-medium) # 17
[-1, 1, Conv, [256, 3, 2]], # 18
[[-1, 7], 1, Concat, [1]], # cat head P5 # 19
[-1, 1, C3, [512, False]], # 20 (P5/32-large) # 20
[[14, 17, 20], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
from n params module arguments
0 -1 1 464 models.shufflenetv2.conv_bn_relu_maxpool[3, 16]
1 -1 1 2768 models.shufflenetv2.Shuffle_Block [16, 64, 2]
2 -1 1 2528 models.shufflenetv2.Shuffle_Block [64, 64, 1]
3 -1 1 14080 models.shufflenetv2.Shuffle_Block [64, 128, 2]
4 -1 2 18304 models.shufflenetv2.Shuffle_Block [128, 128, 1]
5 -1 1 52736 models.shufflenetv2.Shuffle_Block [128, 256, 2]
6 -1 1 34688 models.shufflenetv2.Shuffle_Block [256, 256, 1]
7 -1 1 66048 models.common.Conv [256, 256, 1, 1]
8 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
9 [-1, 4] 1 0 models.common.Concat [1]
10 -1 1 329216 models.common.C3 [384, 256, 1, False]
11 -1 1 33024 models.common.Conv [256, 128, 1, 1]
12 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
13 [-1, 2] 1 0 models.common.Concat [1]
14 -1 1 82688 models.common.C3 [192, 128, 1, False]
15 -1 1 73856 models.common.Conv [128, 64, 3, 2]
16 [-1, 11] 1 0 models.common.Concat [1]
17 -1 1 82688 models.common.C3 [192, 128, 1, False]
18 -1 1 147712 models.common.Conv [128, 128, 3, 2]
19 [-1, 7] 1 0 models.common.Concat [1]
20 -1 1 329216 models.common.C3 [384, 256, 1, False]
21 [14, 17, 20] 1 9270 models.yolo.Detect [1, [[10, 13, 16, 30, 33, 23], [30, 61, 62, 45, 59, 119], [116, 90, 156, 198, 373, 326]], [128, 128, 256]]
Model Summary: 216 layers, 1279286 parameters, 1279286 gradients, 3.7 GFLOPs运行后打印如上代码说明改进成功。
更多文章产出中,主打简洁和准确,欢迎关注我,共同探讨!
















 911
911











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









