






前言
两家凑巧同一天放出了解题推理模型,简单对比着看了下实现方案,o1 类模型实现并没有和大家早期推测的那样用上 MCTS,PRM 这些方法,个人感觉也是太复杂的方法 scaling 不了。
目前各家用的方案看起来更像是 sft+rl 的加强版,把推理过程内含进生成,而不是用结构去引导生成。两家效果看报告比较接近,个有所长。
code 和 math deepseek 强了一点点,kimi 支持 vision。base 的 rl 基于 token, o1 的 rl 基于思考过程的 node,更符合直觉。
总体上,kimi 的方案是 pretraining,vanilla supervised fine-tuning (SFT),long-CoT supervised fine-turning,and reinforcement learning (RL)。
kimi 的方案可能更接近 openai o1,先用高质量的 Cot 数据 finetune一个推理模型,然后用一堆 rm 进行大规模的强化学习,路子比较传统一些。讲的比较清楚。
deepseek 的方案是 pretrainning,Cold start SFT,DeepSeek-R1-Zero,Rejection Sampling and SFT,RL2 for all Scenarios。
deepseek 方案最重要的步骤是 DeepSeek-R1-Zero,用了一个 cot 的 prompt 模板,然后一堆基于规则的 reward 模型,强化学习用的 GRPO,方法比较直接。
但是 deepseek 的方案从 base model 直接训练推理能力,实在太强了,有种大力出奇迹的美。
总体来说,deepseek 方案创新度更高,kimi 方案可能更接近 openai 的路子。
1、kimi 方案的一些细节
vanilla SFT
非推理任务,包括问答、写作和文本处理,先人工标注构建一个种子数据集,训练一个种子模型。
随后收集多样化提示,用种子模型为每个提示生成多个回复。标注者对这些回复进行排序,对排名最高的回复进行优化,以生成最终版本。
对于数学和编程问题等推理任务,基于规则和奖励模型的验证比人工判断更准确和高效,利用拒绝采样来扩展 SFT 数据集。
Long-CoT Supervised Fine-Tuning
这一步应该是让模型具有长思维链能力,方便后续 RL 学习。
首先要构建一套 RL Prompt,满足 3 个要求 Diverse Coverage(多样性)、Balanced Difficulty(难度均衡)、Accurate Evaluability(方便评估),然后构建了一个小而高质量的长链思维(long-CoT)预热数据集,其中包含针对文本和图像输入的经过准确验证的推理路径。
这种方法类似于拒绝采样(RS),但侧重于通过提示工程生成长链思维推理路径。
生成的预热数据集旨在封装对人类推理至关重要的关键认知过程,例如规划,即模型在执行前系统地列出步骤;评估,涉及对中间步骤的批判性评估;反思,使模型能够重新考虑并优化其方法;以及探索,鼓励考虑替代解决方案。
通过对该预热数据集进行轻量级的监督微调(SFT),经过微调后模型生成的回复更详细且逻辑一致更好。
ps:RL Prompt 具体什么样子,怎么指导 Long Cot 不太清楚。
RL
这部分篇幅很多,讲了推理问题的路径搜索和策略优化算法,但是看最后的 gradient 公式,就是正常的 policy gradient,很多东西都内含进生成里面了,比如策略 z。
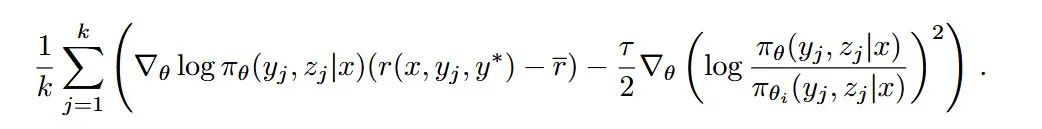
2、Deepseek 方案的一些细节
冷启动,针对 DeepSeek-R1-Zero 的可读性差,格式差,不符合人类偏好的问题,做了几千条冷启动数据 finetune。
Reasoning-oriented Reinforcement Learning,这个阶段类似 DeepSeek-R1-Zero 阶段,同时为了为了缓解语言混合问题,强化学习训练中引入了语言一致性奖励,score 为目标语言词汇在思维链中所占的比例。
Rejection Sampling and Supervised Fine-Tuning,利用推理数据和非推理数据一起进行 SFT,以增强模型在写作、角色扮演和其他通用任务中的能力。
Reinforcement Learning for all Scenarios,二次强化学习阶段,旨在提高模型的有用性和无害性,同时优化其推理能力,对于推理数据,用基于规则的奖励来指导数学、代码和逻辑推理领域的学习过程。
对于通用数据,采用奖励模型来捕捉复杂和微妙场景中的人类偏好。
3、总结
deepseek 方案看起来更简洁,创新程度更高,但是对工程能力要求更高,看起来简单实现起来就不是那么回事了。
kimi 的方案可能更接近 openai o1,论文写的比较详细,抄作业的难度会更低一点。
目前推理模型的核心还是高质量的 cot 推理数据加上上规模的强化学习。相信后面还会有很多接近 o1 效果的模型出现。
最后的最后
感谢你们的阅读和喜欢,作为一位在一线互联网行业奋斗多年的老兵,我深知在这个瞬息万变的技术领域中,持续学习和进步的重要性。
为了帮助更多热爱技术、渴望成长的朋友,我特别整理了一份涵盖大模型领域的宝贵资料集。
这些资料不仅是我多年积累的心血结晶,也是我在行业一线实战经验的总结。
这些学习资料不仅深入浅出,而且非常实用,让大家系统而高效地掌握AI大模型的各个知识点。如果你愿意花时间沉下心来学习,相信它们一定能为你提供实质性的帮助。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
大模型知识脑图
为了成为更好的 AI大模型 开发者,这里为大家提供了总的路线图。它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

经典书籍阅读
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。

实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

面试资料
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下

640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

















 706
706

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









