






前言
最近发现很多做训练和推理的朋友都在讨论大模型参数量和模型大小之间的关系。
例如羊驼系列 LLaMA 大模型,按照参数量的大小有四个型号:LLaMA-7B、LLaMA-13B、LLaMA-33B 与 LLaMA-65B。
这里的 B 是 billion 的缩写,指代模型的参数规模。故最小的模型 7B 包含 70 亿个参数,而最大的一款 65B 则包含 650 亿个参数。
这个参数量到底是怎么算出来的?另外一个问题,对于一个存储有 100G 大小的模型,到底对应大模型的什么级别的参数量呢,十亿、百亿、千亿还是万亿呢?今天我们就来聊聊这个问题。
我们以大模型的最基本结构 Transformer 为例,首先来看一下参数量是怎么算出来的。
transformer 由 L 个相同的层组成,每个层分为两个部分:self-attention 和 MLP 层。
其中 self-attention 块,不管用的是 self-attention 还是 multi-head self-attention,参数量计算并不影响。
因为在输入时,对 Q,K,V 三个向量都进行了线性变换,只是 multi-head self-attention 会对隐藏层 h 切分成 head 份而已。

那么 self-attention 块的参数量为:4h²+4h。
MLP 块由 2 个线性层组成,这两个层的 shape 是先将维度 h 映射到 4h,然后第二个线性层再将维度从 4h 映射回 h。

self-attention 和 MLP 块各有一个 layer normalization,包含了 2 个可训练的参数:尺度缩放参数 gamma,和平移参数 beta,形状都是 [h]。
那么这两个 layer normalization 参数量为:4h。
那么,每个 transformer 层的参数量就为:12h²+13h。
除此之外,还有输入部分的词嵌入参数,词向量的维度为 h,假设词表大小 vocab size 为 V。
那么词嵌入的参数量为 Vh,而输出层的权重矩阵通常与输入的词嵌入矩阵参数是共享的,不会引入额外的参数量。
关于位置编码,这部分参数比较少,可以忽略。其中,如果采用可训练的位置编码,那么参数量为 N*h,N 是最大序列长度,例如 chatgpt 的 4k。
如果采用的是相对位置编码,如旋转编码 RoPE 或者 AliBi,则这部分就没有可训练的参数。
综上所述,L 层的 transformer 模型的总参数量为 L(12h²+13h)+Vh,当隐藏维度 h 较大时,可以忽略一次项,模型参数量可以近似为 12Lh²。
接下来,我们估计一下 LLaMA 的不同尺寸版本的参数量大小,看验证下是否符合上述规律:
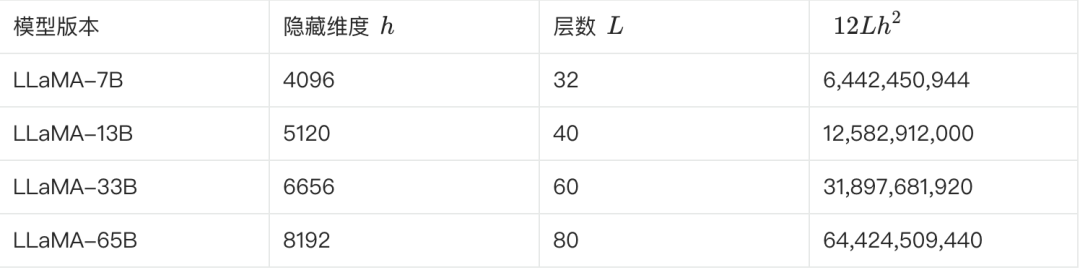
最后我们来看一下第二个问题,大模型参数量和模型大小是怎么换算的。
我们以 LLaMA-7B 为例,这个大模型参数量约为 70 亿,假设每个参数都是一个 fp32,即 4 个字节,总字节就是 280 亿字节,则 280 亿字节/1024/1024 = 26.7GB,当然这是原始的理论值,我们再往下看。
因为实际存储 weight 权重参数会存 fp16,所以模型大小继续减半为 13.35GB。
但是部分 layer norm 等数据会保留源格式 fp32,因此实际会稍微有所增加到 13.5GB 左右,看下图:
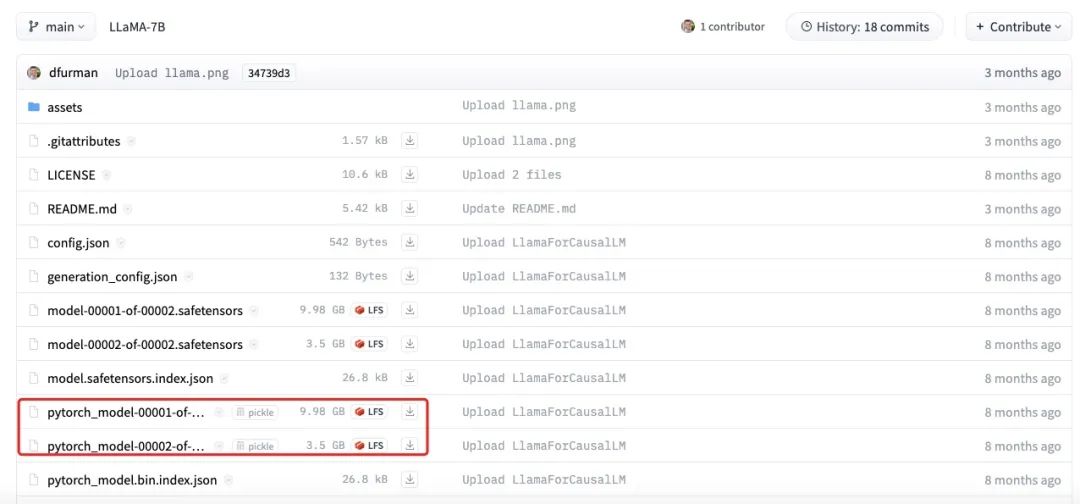
具体增加多少其实不是很重要了,因为在模型权重文件里面,参数量 98% 的大头是权重数据,其他数据占比其实很少,我们从开源的 LLaMA-7B 的实际的存储结果来看,是符合上面的计算的。
最后的最后
感谢你们的阅读和喜欢,作为一位在一线互联网行业奋斗多年的老兵,我深知在这个瞬息万变的技术领域中,持续学习和进步的重要性。
为了帮助更多热爱技术、渴望成长的朋友,我特别整理了一份涵盖大模型领域的宝贵资料集。
这些资料不仅是我多年积累的心血结晶,也是我在行业一线实战经验的总结。
这些学习资料不仅深入浅出,而且非常实用,让大家系统而高效地掌握AI大模型的各个知识点。如果你愿意花时间沉下心来学习,相信它们一定能为你提供实质性的帮助。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
大模型知识脑图
为了成为更好的 AI大模型 开发者,这里为大家提供了总的路线图。它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

经典书籍阅读
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。

实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

面试资料
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下

640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

















 4747
4747

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









