






在解决分类问题的时候,可以选择的评价指标简直不要太多。但基本可以分成两2大类,我们今分别来说道说道
- 基于一个概率阈值判断在该阈值下预测的准确率
- 衡量模型整体表现(在各个阈值下)的评价指标
在说指标之前,咱先把分类问题中会遇到的所有情况简单过一遍。36度的北京让我们举个凉快一点的例子-我们预测会不会下雨!横轴是预测概率从0-1,红色的部分是没下雨的日子(负样本),蓝色的部分是下雨的日子(正样本)。在真实情况下我们很难找到能对正负样本进行完美分割的分类器,所以我们看到在预测概率靠中间的部分,正负样本存在重合,也就是不管我们阈值卡在哪里都会存在被错误预测的样本。
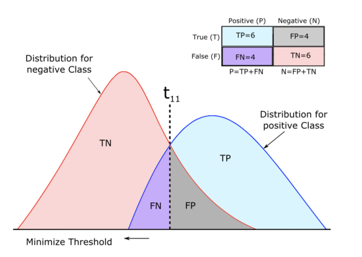
上述分布中的四种情况,可以简单的用confusion matrix来概括

TP:预测为正&真实为正 FP:预测为正&真实为负 TN:预测为负&真实为负 FN:预测为负&真实为正
基于阈值的指标
分类模型输出的是每个样本为正的概率,我们要先把概率转换成0/1预测。给定一个阈值,我们把预测概率大于阈值的样本预测为正,小于的为负。这时就会出现上述confustion matrix里面的四种情况。那我们该如何去评价模型表现呢?
新手视角- Accuracy!
这应该是大多数人第一个知道的评价指标,它把正负样本混在一起去评价整体的分类准确率。
[Accuracy = \frac{TP + TN}{TP + TN + FN + FP}]
老手会用一个在所有tutorial里面都能看到的Imbalance Sample的例子来告诉你,如果你的正样本只有1%,那全部预测为负你的准确率就是99%啦 - so simple and naive ~.~
当然Accuracy也不是不能用,和正样本占比放在一起比较也是能看出来一些信息的。但Accuracy确实更适用正负样本55开,且预测不止针对正样本的情况。
Accuracy知道咋算就可以啦,在解决实际问题的时候,往往会使用更有指向性的指标, 而且一般都会同时选用2个以上的指标因为不同指标之间往往都有trade-off
当目标是对正样本进行准确预测 - precision, recall, F1
precision从预测的角度衡量预测为正的准确率,recall从真实分布的角度衡量预测为正的准确率。**precision和recall存在trade-off, 想要挑选出更多的正样本,就要承担预测为正准确率下降的风险。**例如在飞机过安检时,想要保证危险物品基本都被识别出来,就肯定要承担一定的误判率。不过在这种情境下查不出危险物品显然比让误判乘客多开包检查一遍要重要的多。
[ \begin{align} precision &= \frac{TP}{TP+FP} \ recall &= \frac{TP}{TP+FN} \end{align} ]
既然有trade-off,一般就会用可以综合两个指标的复合指标 - F1 Score [ F1 =\frac{1}{\frac{1}{precision} + \frac{1}{recall}}= \frac{precision * recall}{precision + recall} ]
其实简单一点直接对precision,recall求平均也可以作为复合指标,但F1用了先取倒数再求平均的方式来避免precision或recall等于0这种极端情况的出现
当目标是对真实分布进行准确预测 - sensitivity(recall), specifity, fpr
sensitivity, sepcifity都从真实分布的角度,分别衡量正/负样本预测的准确率。这一对搭配最常在医学检验中出现,衡量实际生病/没生病的人分别被正确检验的概率。正确检验出一个人有病很重要,同时正确排除一个人没生病也很重要。
[ \begin{align} sensitivity &= recall \ specifity & =\frac{TN}{TN + FP} \ \end{align} ]
如果specifity对很多人来说很陌生的话,它兄弟很多人一定知道fpr。fpr和recall(tpr)一起构成了ROC曲线。这一对的tradeoff同样用医学检验的逻辑来解释就是,医生既不希望遗漏病人的病情(recall),要不希望把本身没病的人吓出病来(fpr)。 [ fpr = \frac{FP}{TN+FP} = 1- specifity ]
和阈值相关经常用到的指标差不多就是这些。这些指标的计算依赖于阈值的确定,所以在应用中往往用验证集来找出使F1/accuracy最大的阈值,然后应用于测试集,再用测试集的F1/accuracy来评价模型表现。下面是几个应用上述指标的kaggle比赛
- F1 score https://www.kaggle.com/c/quora-insincere-questions-classification/overview/evaluation
- accuracy https://www.kaggle.com/c/titanic/overview/evaluation
不过开始用到和阈值相关的评价指标有时是在模型已经确定以后。第一步在确定模型时,往往还是需要一些可以综合衡量模型整体表现的指标。简单!粗暴!别整啥曲线阈值的,你给我个数就完了!
综合评价指标
综合评价指标基本都是对上述指标再加工的产物。对应的kaggle比赛会持续更新。
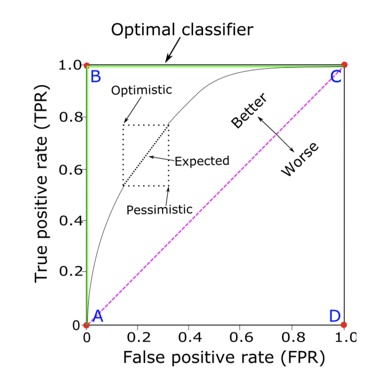
tpr(recall) + fpr = ROC-> AUC
随着阈值从1下降到0,我们预测为正的样本会逐渐变多,被正确筛选出的正样本会逐渐增多,但同时负样本被误判为正的概率也会逐渐上升。
整个遍历阈值的过程可以用ROC曲线来表示,横轴是误判率(fpr),纵轴是准确率(tpr/recall/sensitivity)。但是给你两个分类器想要直接比较谁的ROC曲线会有点困难,所以我们用一个scaler来描述ROC曲线就是AUC - Area under curve。 ROC曲线下的面积越大越接近完美的分类器,而对角线50%是随机猜正负就可以得到的AUC。
Kaggle链接 https://www.kaggle.com/c/santander-customer-transaction-prediction/overview/evaluation
AUC 适用于正负样本相对balance的情况,且分类问题对模型预测概率的准确度没有要求的情况。详见【实战篇】
precision + recall = AUCPR(AP)
和上述ROC-AUC的思路相同。随着阈值从1下降到0,预测为正的样本变多,被正确筛选出的正样本增多,但同时预测为正的准确率会下降。
这样我们得到PR曲线,以及曲线下的面积AUCPR。有时AUCPR也被称作AP,就是对所有recall取值对应的precision求平均。第一眼看上去我也被糊弄了,一直当成两个概念来记。但是式子一写出来,妈呀这俩不是一个东西么。 [ AUCPR = \sum_1^K\Delta{r(k)} * p(k) = \int_o^1 {p® dr} = AP ]
AP 刚好弥补AUC曲线的不足,适用于正负样本imbalance的情况,或者我们更关心模型在正样本上表现的情况。但AP同样不能保证模型预测概率的准确率。详见【实战篇】
cross-entropy loss
cross-entropy放在这里会有点奇怪,因为本质上它是和这里其他所有指标都不同的存在。其他的评价指标评价的是0/1的分类效果,或者更准确说是对排序效果(根据阈值把预测值从大到小分成0/1两半)进行评价。但是cross-entropy是直接对预测概率是否拟合真实概率进行评价。 [ L = -\sum_{i=1}^N y_i * log p_i + (1-y_i) * log(1-p_i) ]
kaggle链接 https://www.kaggle.com/c/statoil-iceberg-classifier-challenge/overview/evaluation
cross-entropy弥补了AP和AUC的不足。如果分类目标其实是获得对真实概率的估计的话,使用cross-entropy应该是你的选择。详见【实战篇】
*Mean F1 Score
kaggle链接 https://www.kaggle.com/c/instacart-market-basket-analysis/overview/evaluation
第一次见到这个指标是在Instacart的kaggle比赛里面。这里的mean不是指的对所有阈值下的F1求平均值而是对每个order_id的多个product_id求F1,再对所有order_id的F1求平均,有点绕…
之所以把这个评价指标也放在这里是因为这个特殊的评价方法会对你如何split训练集/测试集,以及如何选定最优的阈值产生影响。有兴趣的可以来试一试,反正我觉得自己是把能踩的坑都踩了一个遍,欢迎大家一起来踩坑 >_<
Reference
- Alaa Tharwat,Classification assessment methods,Applied Computing and Informatics
- Nan Ye,Kian Ming A. Chai,Wee Sun Lee,Hai Leong Chieu,Optimizing F-Measures: A Tale of Two Approaches,
- https://en.wikipedia.org/wiki/Confusion_matrix
零基础如何学习大模型 AI
领取方式在文末
为什么要学习大模型?
学习大模型课程的重要性在于它能够极大地促进个人在人工智能领域的专业发展。大模型技术,如自然语言处理和图像识别,正在推动着人工智能的新发展阶段。通过学习大模型课程,可以掌握设计和实现基于大模型的应用系统所需的基本原理和技术,从而提升自己在数据处理、分析和决策制定方面的能力。此外,大模型技术在多个行业中的应用日益增加,掌握这一技术将有助于提高就业竞争力,并为未来的创新创业提供坚实的基础。
大模型实际应用案例分享
①智能客服:某科技公司员工在学习了大模型课程后,成功开发了一套基于自然语言处理的大模型智能客服系统。该系统不仅提高了客户服务效率,还显著降低了人工成本。
②医疗影像分析:一位医学研究人员通过学习大模型课程,掌握了深度学习技术在医疗影像分析中的应用。他开发的算法能够准确识别肿瘤等病变,为医生提供了有力的诊断辅助。
③金融风险管理:一位金融分析师利用大模型课程中学到的知识,开发了一套信用评分模型。该模型帮助银行更准确地评估贷款申请者的信用风险,降低了不良贷款率。
④智能推荐系统:一位电商平台的工程师在学习大模型课程后,优化了平台的商品推荐算法。新算法提高了用户满意度和购买转化率,为公司带来了显著的增长。
…
这些案例表明,学习大模型课程不仅能够提升个人技能,还能为企业带来实际效益,推动行业创新发展。
学习资料领取
如果你对大模型感兴趣,可以看看我整合并且整理成了一份AI大模型资料包,需要的小伙伴文末免费领取哦,无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发

部分资料展示
一、 AI大模型学习路线图
整个学习分为7个阶段

二、AI大模型实战案例
涵盖AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,皆可用。

三、视频和书籍PDF合集
从入门到进阶这里都有,跟着老师学习事半功倍。


如果二维码失效,可以点击下方链接,一样的哦
【CSDN大礼包】最新AI大模型资源包,这里全都有!无偿分享!!!
😝朋友们如果有需要的话,可以V扫描下方二维码联系领取~
















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









