







仅作为个人学习记录
介绍
当实现一个神经网络的时候,我们需要知道一些非常重要的技术和技巧。例如有一个包含
m
m
m个样本的训练集,你很可能习惯于用一个for循环来遍历训练集中的每个样本,但是当实现一个神经网络的时候,我们通常不直接使用for循环来遍历整个训练集,所以在这周的课程中你将学会如何处理训练集。
另外在神经网络的计算中,通常先有一个叫做前向暂停(forward pause)或叫做前向传播(foward propagation)的步骤,接着有一个叫做反向暂停(backward pause) 或叫做反向传播(backward propagation)的步骤。
案例
逻辑回归(logistic regression)是一个用于二分类(binary classification)的算法。首先我们从一个问题开始说起,这里有一个二分类问题的例子,假如你有一张图片作为输入,比如这只猫,如果识别这张图片为猫,则输出标签1作为结果;如果识别出不是猫,那么输出标签0作为结果。现在我们可以用字母
y
y
y来表示输出的结果标签,如下图所示:

我们来看看一张图片在计算机中是如何表示的,为了保存一张图片,需要保存三个矩阵,它们分别对应图片中的红、绿、蓝三种颜色通道,如果你的图片大小为64x64像素,那么你就有三个规模为64x64的矩阵,分别对应图片中红、绿、蓝三种像素的强度值。为了便于表示,这里我画了三个很小的矩阵,注意它们的规模为5x4而不是64x64,如下图所示:
为了把这些像素值放到一个特征向量中,我们需要把这些像素值提取出来,然后放入一个特征向量
x
x
x。为了把这些像素值转换为特征向量
x
x
x,我们需要像下面这样定义一个特征向量
x
x
x来表示这张图片,我们把所有的像素都取出来,例如255、231等等,直到取完所有的红色像素,接着最后是255、134、…、255、134等等,直到得到一个特征向量,把图片中所有的红、绿、蓝像素值都列出来。
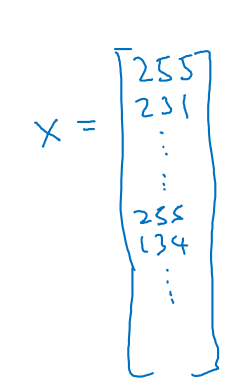
如果图片的大小为64x64像素,那么向量
x
x
x的总维度,将是64乘以64乘以3,这是三个像素矩阵中像素的总量。在这个例子中结果为12288。
现在我们用
n
x
=
12288
n_x=12288
nx=12288,来表示输入特征向量的维度,有时候为了简洁,我会直接用小写的
n
n
n来表示输入特征向量的维度。所以在二分类问题中,我们的目标就是习得一个分类器,它以图片的特征向量作为输入,然后预测输出结果为1还是0,也就是预测图片中是否有猫。

符号定义
x
x
x 表示一个
n
x
n_x
nx维数据,为输入数据,维度为
(
n
x
,
1
)
(n_x,1)
(nx,1);
y
y
y表示输出结果,取值为
(
0
,
1
)
(0,1)
(0,1);
(
x
(
i
)
,
y
(
i
)
)
(x^{(i)},y^{(i)})
(x(i),y(i)):表示第
i
i
i组数据,可能是训练数据,也可能是测试数据,此处默认为训练数据;
X
=
[
x
(
1
)
,
x
(
2
)
,
.
.
.
,
x
(
m
)
]
X=[x^{(1)},x^{(2)},...,x^{(m)}]
X=[x(1),x(2),...,x(m)] 表示所有的训练数据集的输入值,放在一个
n
x
×
m
n_x\times m
nx×m的矩阵中,其中
m
m
m表示样本数目;
Y
=
[
y
(
1
)
,
y
(
2
)
,
.
.
.
,
y
(
m
)
]
Y=[y^{(1)},y^{(2)},...,y^{(m)}]
Y=[y(1),y(2),...,y(m)]对应表示所有训练数据集的输出值,维度为
1
×
m
1\times m
1×m。
用一对
(
x
,
y
)
(x,y)
(x,y)来表示一个单独的样本,
x
x
x代表
x
n
x_n
xn维的特征向量,
y
y
y表示标签(输出结果)只能为0或1。 而训练集将由
m
m
m个训练样本组成,其中
(
x
(
1
)
,
y
(
1
)
)
(x^{(1)},y^{(1)})
(x(1),y(1))表示第一个样本的输入和输出,
(
x
(
2
)
,
y
(
2
)
)
(x^{(2)},y^{(2)})
(x(2),y(2))表示第二个样本的输入和输出,直到最后一个样本
(
x
(
m
)
,
y
(
m
)
)
(x^{(m)},y^{(m)})
(x(m),y(m)),然后所有的这些一起表示整个训练集。有时候为了强调这是训练样本的个数,会写作
M
t
e
s
t
M_{test}
Mtest,当涉及到测试集的时候,我们会使用
M
t
e
s
t
M_{test}
Mtest来表示测试集的样本数,所以这是测试集的样本数:

最后为了能把训练集表示得更紧凑一点,我们会定义一个矩阵用大写的
X
X
X表示,它由输入向量
x
(
1
)
x^{(1)}
x(1)、
x
(
2
)
x^{(2)}
x(2)等组成,如下图放在矩阵的列中,所以现在我们把
x
(
1
)
x^{(1)}
x(1)作为第一列放在矩阵中,
x
(
2
)
x^{(2)}
x(2)作为第二列,
x
(
m
)
x^{(m)}
x(m)放到第列
m
m
m,然后我们就得到了训练集矩阵
X
X
X。所以这个矩阵有
m
m
m列,
m
m
m是训练集的样本数量,然后这个矩阵的高度记为
n
x
n_x
nx,注意有时候可能因为其他某些原因,矩阵
X
X
X会由训练样本按照行堆叠起来而不是列,如下图所示:
x
(
1
)
x^{(1)}
x(1)的转置直到
x
(
m
)
x^{(m)}
x(m)的转置,但是在实现神经网络的时候,使用左边的这种形式,会让整个实现的过程变得更加简单。

现在来简单温习一下:
X
X
X是一个规模为
n
x
n_x
nx乘以
m
m
m的矩阵,当你用Python实现的时候,你会看到X.shape,这是一条Python命令,用于显示矩阵的规模,即X.shape等于
(
n
x
,
m
)
(n_x,m)
(nx,m),
X
X
X是一个规模为
n
x
n_x
nx乘以
m
m
m的矩阵。所以综上所述,这就是如何将训练样本(输入向量
X
X
X的集合)表示为一个矩阵。
那么输出标签
y
y
y呢?同样的道理,为了能更加容易地实现一个神经网络,将标签
y
y
y放在列中将会使得后续计算非常方便,所以我们定义大写
Y
Y
Y的等于
y
(
1
)
,
y
(
2
)
,
.
.
.
,
y
(
m
)
y^{(1)},y^{(2)},...,y^{(m)}
y(1),y(2),...,y(m),所以在这里是一个规模为1乘以
m
m
m的矩阵,同样地使用Python将表示为Y.shape等于
(
1
,
m
)
(1,m)
(1,m),表示这是一个规模为1乘以
m
m
m的矩阵。
















 2462
2462











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









