







MLOps,即机器学习的 DevOps。它能够帮助企业或组织更好地管理生产中的机器学习模型的复杂性,从而使机器学习项目更快速、更可靠地推广到市场。在本文中,我们将回顾 OSSInsight.io 2022 年列出的排名前 5 的最热门开源 MLOps 工具。
MLOps 主要优势
MLOps 的最大优势之一是它使 AI 研究员和软件工程师能够更紧密地协作。AI 研究员可以专注于开发模型,而软件工程师可以专注于实施模型。这种协作有助于确保模型快速高效地部署,并满足业务需求。另一个 MLOps 的优点是它有助于自动化模型开发和部署的过程。这意味着 AI 研究员可以减少做重复性任务的时间,并有更多时间开发新模型。自动化还有助于确保模型一致地以高质量的方式部署。
MLOps 常见实践
MLOps 仍然是一个相对较新的领域(如下所示,以下五个工具大都是在 2018 年首次发布的),并没有通用的实施方法。然而,也有很多常见实践。比如 使用 Pipeline 流水线,流水线有助于自动化构建、测试和部署机器学习模型的过程。
另一种常见实践是 使用容器化技术(例如 Docker)来打包机器学习模型,使得模型可以在不同的环境中轻松部署。
最后,许多 MLOps 从业者 使用监控和日志工具来跟踪生产中机器学习模型的性能。这可以提前发现问题,并有助于提高模型的整体质量。
2022 5 款最佳 MLOps 工具
实施 MLOps 可能具有挑战性,但其好处是显而易见的。采用 MLOps 实践的组织可以提高机器学习模型的质量,并加快开发和部署过程。 在本文中,我们选择了 OSSInsight.io 2022 年排名前 5 的最热门开源 MLOps 工具,即 Jina(排名第 1)、MLFlow(排名第 2)、NNI(排名第 3)、Kubefliow(排名第 4)和 Label Studio(排名第 5)。排名是根据 2022 年在 Github 上的 Star、Pull Request、PR 创建者和 Issue 而定的。
OSSInsight 是一款功能强大的洞察工具,可帮助人们深入分析单个 GitHub 仓库/开发人员,使用相同的指标比较任意两个仓库,并提供全面、有价值和有趋势的开源洞察。
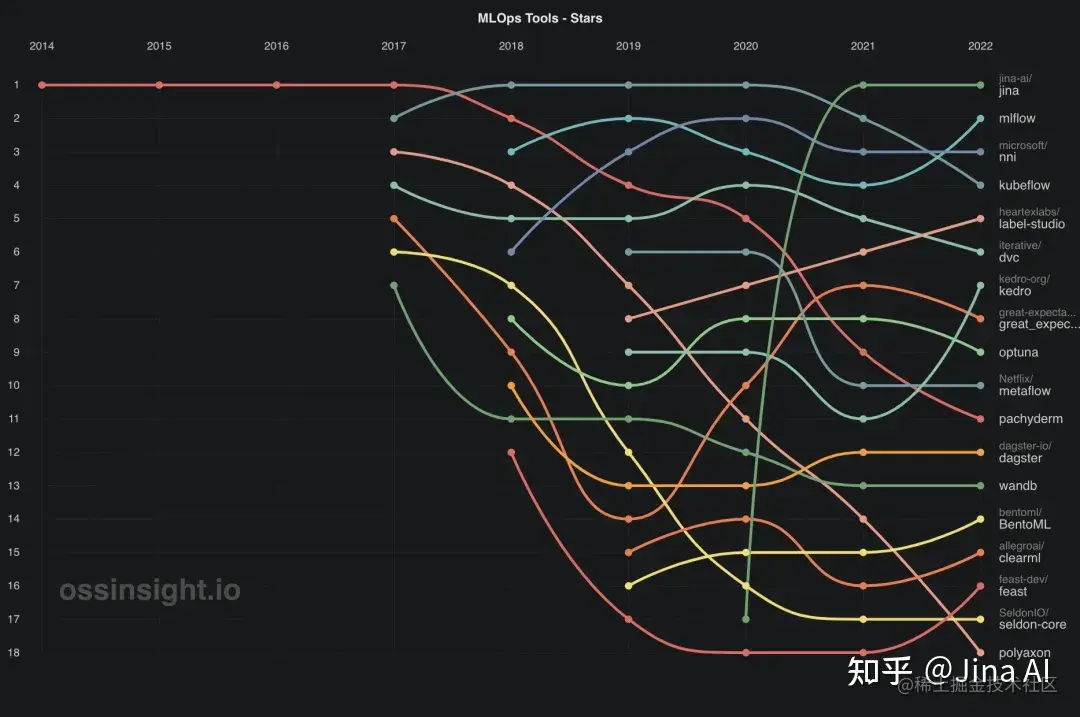
上图显示了自 2011 年以来每年仓库排名的变化情况。仓库按 Star、Pull Request 、PR 创建者和 Issue 来排名。
前 5 工具是 Jina、MLFlow、NNI、Kubeflow 和 Label Studio。
MLOps 排行榜#
01 Jina AI
根据 OSSInsight,Jina AI 的同名核心产品 Jina 是目前最热门的 MLOps 开源工具。Jina 是一个 多模态 AI 的 MLOps 框架。它简化了云端的神经搜索和创意 AI 的构建和部署。Jina 极大简化了基础架构 AI 的复杂性,开发者可以轻松将 PoC 升级为生产就绪服务,直接使用 Jina 封装好的高级解决方案工程和 云原生技术。地址:get.jina.ai/

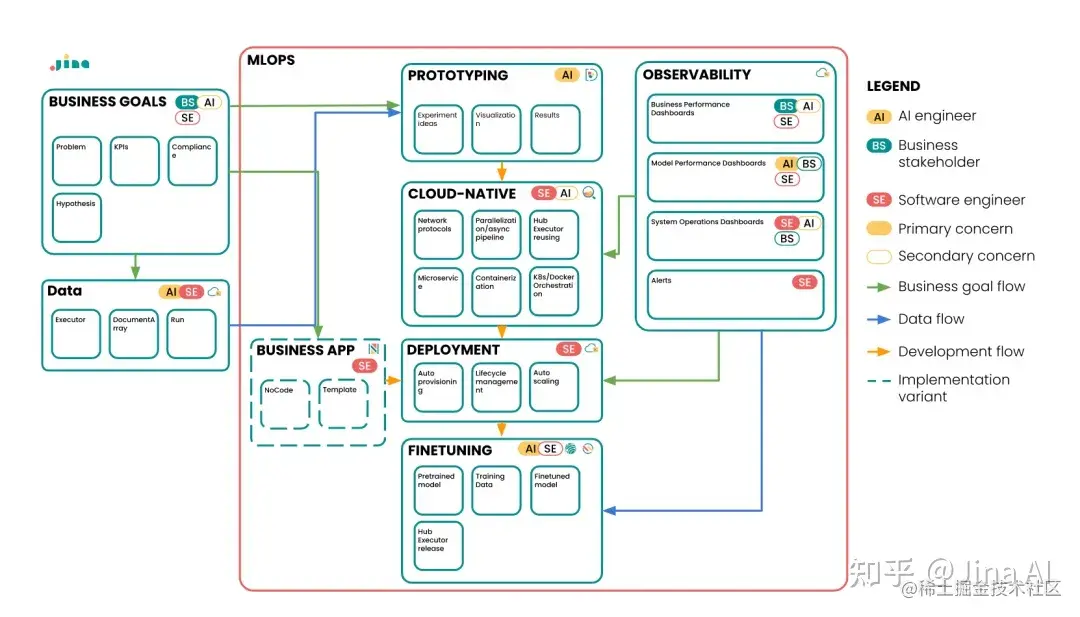
Jina AI 的 MLOps 涵盖了从原型设计、服务器化、部署、微调、监控等的全部开发过程。Jina 提供了前沿的云原生功能,先进的解决方案,但学习 Jina 却非常简单。
只需掌握 Jina 的三个基本概念:
- Document 是基本数据结构。(目前这个项目属于 Linux 基金会,Jina AI正式将DocArray捐赠给Linux基金会)
- Executor 是一个使用 Document 作为 IO 函数的 Python 类。
- Flow 将 Executors 连接成流水线。
有了这三个概念,人们可以轻松地用 45 行代码构建采用分片技术的 基于语义的文本搜索!’
python复制代码from pprint import pprint
from jina import Flow, requests, DocumentArray, Document, Executor
class MyFeature(Executor):
@requests
async def foo(self, docs, **kwargs):
docs.apply(Document.embed_feature_hashing)
class MyDB(Executor):
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
self.db = DocumentArray()
@requests(on='/index')
def index(self, docs, **kwargs):
self.db.extend(docs)
@requests(on='/query')
def query(self, docs, **kwargs):
return self.db.find(docs, metric='jaccard', use_scipy=True)[0][:3]
class MyRanker(Executor):
@requests(on='/query')
async def foo(self, docs, **kwargs):
return DocumentArray(sorted(docs, key=lambda x: x.scores['jaccard'].value))
d = Document(uri='https://www.gutenberg.org/files/1342/1342-0.txt').load_uri_to_text()
da = DocumentArray(Document(text=s.strip()) for s in d.text.split('\n') if s.strip())
if __name__ == '__main__':
f = (
Flow()
.add(uses=MyFeature)
.add(uses=MyDB, shards=3, polling={'/query': 'ALL', '/index': 'ANY'})
.add(uses=MyRanker)
)
with f:
f.post('/index', da, show_progress=True)
pprint(
f.post('/query', Document(text='she smiled too much'))[
:, ('text', 'scores__jaccard__value')
]
)
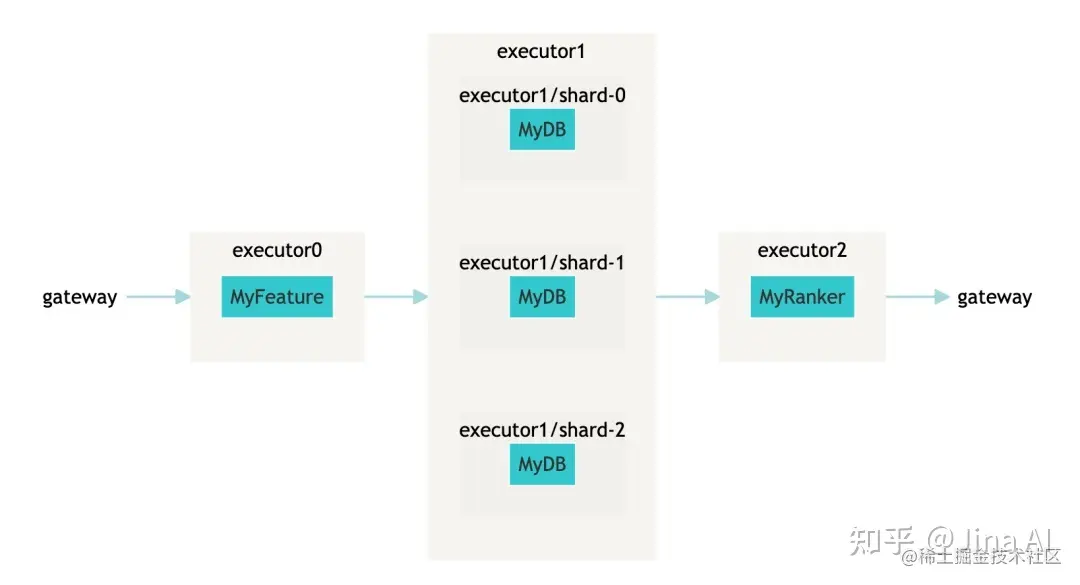
使用 Executor Hub,用户可以轻松地使用 LLM 或 Hugging Face 上的预训练模型来对 Document 进行 embedding。此外,在实践中,如果没有适当的领域采用或知识转移,性能通常不理想。微调是提高神经搜索和嵌入相关任务性能的有效解决方案。Jina AI 还提供了 Finetuner 工具,通过简化工作流并在云端处理所有复杂性和基础架构,使微调更简单、更快速、更有效。
最后,Jina AI 还为 Jina 项目提供了免费托管服务,用户可以基于 CPU/GPU 的 Jina Flow,使用 Kubernetes 中的自动配置功能部署。现在处于公共测试阶段,提供免费托管服务。
总的来说,Jina AI 提供了一系列强大的工具和资源,关注公众号,了解最新的 MLOps 动态和最佳实践。
02 MLFlow

MLflow 排在榜单第 2 名。与专门针对神经搜索和多模态 AI 应用的 Jina 不同,MLflow 是一个更通用的平台,旨在简化机器学习开发,包括跟踪实验、将代码打包成可重复运行的代码、共享和部署模型。它提供了一组轻量级 API,可与任何现有的机器学习应用或库(TensorFlow、PyTorch、XGBoost 等)一起使用,无论你当前在哪里运行 ML 代码(例如在笔记本、独立应用程序或云端)。MLflow 的当前组件有:
- MLflow Tracking:用于在机器学习实验中记录参数、代码和结果,并使用交互式 UI 进行比较。
- MLflow Projects:一种使用 Conda 和 Docker 进行可重复运行的代码打包格式,可以与他人分享 ML 代码。
- MLflow Models:一种模型打包格式和工具,可让您轻松在 Docker、Apache Spark、Azure ML 和 AWS SageMaker 等平台上部署相同的模型(来自任何 ML 库),用于批量和实时评分。
- MLflow Model Registry:用于协作管理 MLflow 模型的全生命周期的集中式模型存储、一组 API 和 UI。
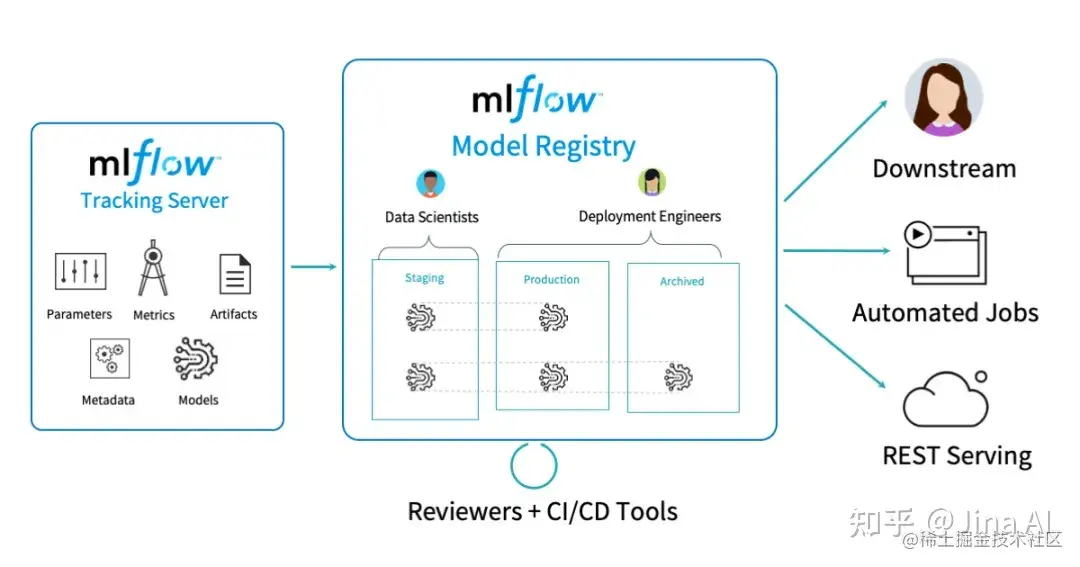
MLflow Projects 提供了打包可复用数据科学代码的标准格式。每个项目只是一个具有代码或 Git 仓库的目录,并使用描述符文件指定其依赖项以及如何运行代码。MLflow Project 由一个 MLproject 的简单 YAML 文件定义。
yaml复制代码name: My Project
conda_env: conda.yaml
entry_points:
main:
parameters:
data_file: path
regularization: {type: float, default: 0.1}
command: "python train.py -r {regularization} {data_file}"
validate:
parameters:
data_file: path
command: "python validate.py {data_file}"
项目可以通过 Conda 环境指定其依赖项。一个项目还可能有多个调用运行的入口点,具有命名参数。您可以使用 mlflow run 命令行工具运行项目,无论是从本地文件还是从 Git 仓库:
arduino
复制代码mlflow run example/project -P alpha=0.5mlflow run git@github.com:databricks/mlflow-example.git -P alpha=0.5
MLflow 会自动为项目设置正确的环境并运行它。
03 NNI

微软的 NNI(神经网络智能)是一个轻量级但功能强大的工具包,可帮助用户自动化特征工程,神经架构搜索,超参数调优和模型压缩,以进行深度学习。NNI 简化了扩展和管理 AutoML 实验的工作。
与更多关注推理的 Jina 不同,NNI 专注于模型训练和实验。它提供了强大且易于使用的 API,用于促进高级训练,如 AutoML。自动神经架构搜索在寻找更好模型方面发挥着越来越重要的作用。最近的研究已经证明了自动 NAS 的可行性,并导致了超过许多手动设计和调整的模型的模型。代表性作品包括 NASNet,ENAS,DARTS,网络形态学和演化。
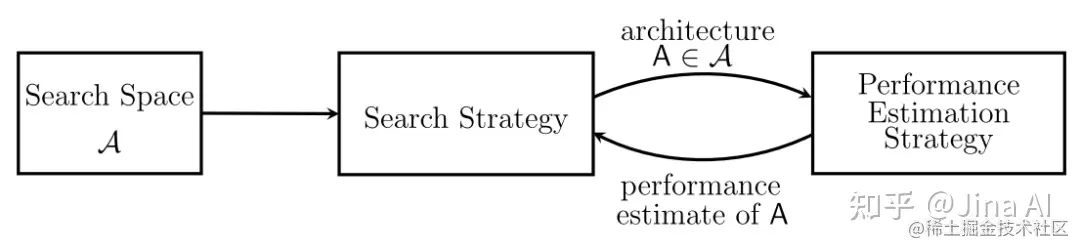
神经架构搜索的过程类似于超参数优化,只不过目标是最佳架构而不是超参数。
一般来说,神经架构搜索通常包括三项任务:搜索空间设计,搜索策略选择和性能评估。这些任务都很麻烦,但在 NNI 中却很容易解决:
ini复制代码# define model space
class Model(nn.Module):
self.conv2 = nn.LayerChoice([
nn.Conv2d(32, 64, 3, 1),
DepthwiseSeparableConv(32, 64)
])
model_space = Model()
# search strategy + evaluator
strategy = RegularizedEvolution()
evaluator = FunctionalEvaluator(
train_eval_fn)
# run experiment
RetiariiExperiment(model_space,
evaluator, strategy).run()
04 Kubeflow

Kubeflow 是 Kubernetes 的机器学习工具包。它最初是谷歌内部运行 Tensorflow 的开源方式。它最初只是一种在 Kubernetes 上运行 TensorFlow 作业的简单方法,但是后来扩展成了一个多体系结构,多云框架,能够运行端到端的机器学习工作流。
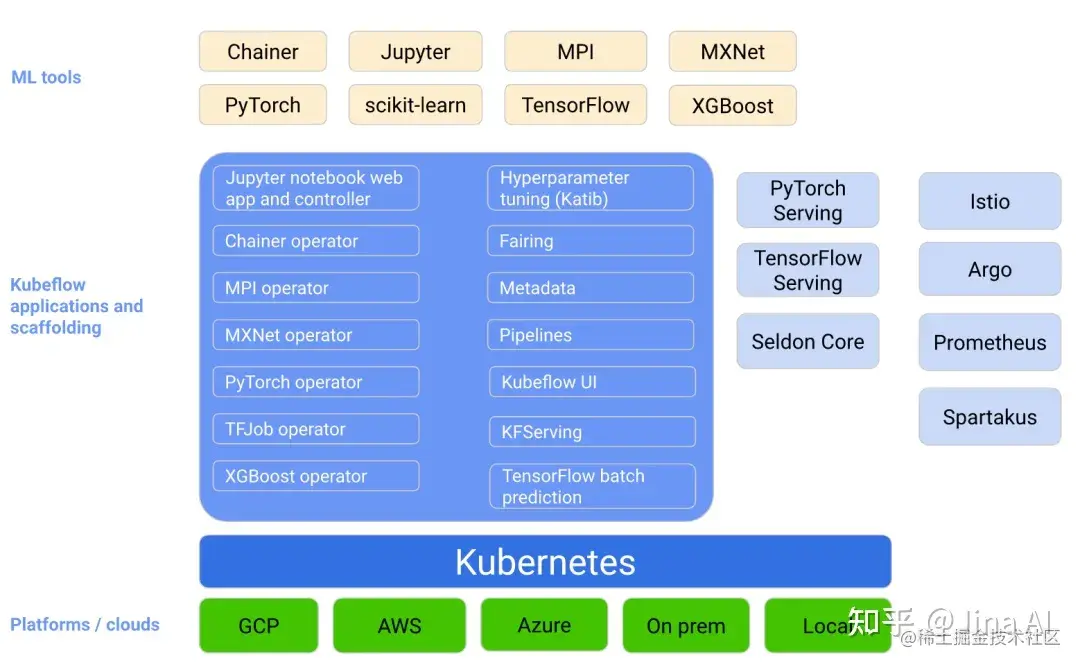
上图显示了 Kubeflow 作为在 Kubernetes 之上排列 ML 系统组件的平台。Kubeflow 致力于使 ML 工作流在 Kubernetes 上的部署变得简单,可移植和可扩展。目标不是再次创建其他服务,而是提供一种在不同基础架构上部署机器学习的开源系统的简单方法。您应该能够在任何运行 Kubernetes 的地方运行 Kubeflow。与 Jina,MLFlow 和 NNI 相比,Kubeflow 涵盖了最完整的 ML 生命周期,包括:
- Training
- AutoML
- Deployment
- Serving
- Pipelines
- Manifests
- Notebooks
与 Jina 的 “Flow” 和 MLFlow 的 “Project” 概念相比,Kubeflow pipeline 涵盖了更多内容。Kubeflow Pipelines 是一个基于 Docker 容器的构建和部署可移植,可扩展的机器学习 (ML) 工作流的平台。具体而言,它包括:
- 用于管理和跟踪实验,作业和运行的用户界面 (UI)。
- 用于调度多步 ML 工作流的引擎。
- 用于定义和操作流程和组件的 SDK。
- 用于使用 SDK 与系统交互的笔记本。
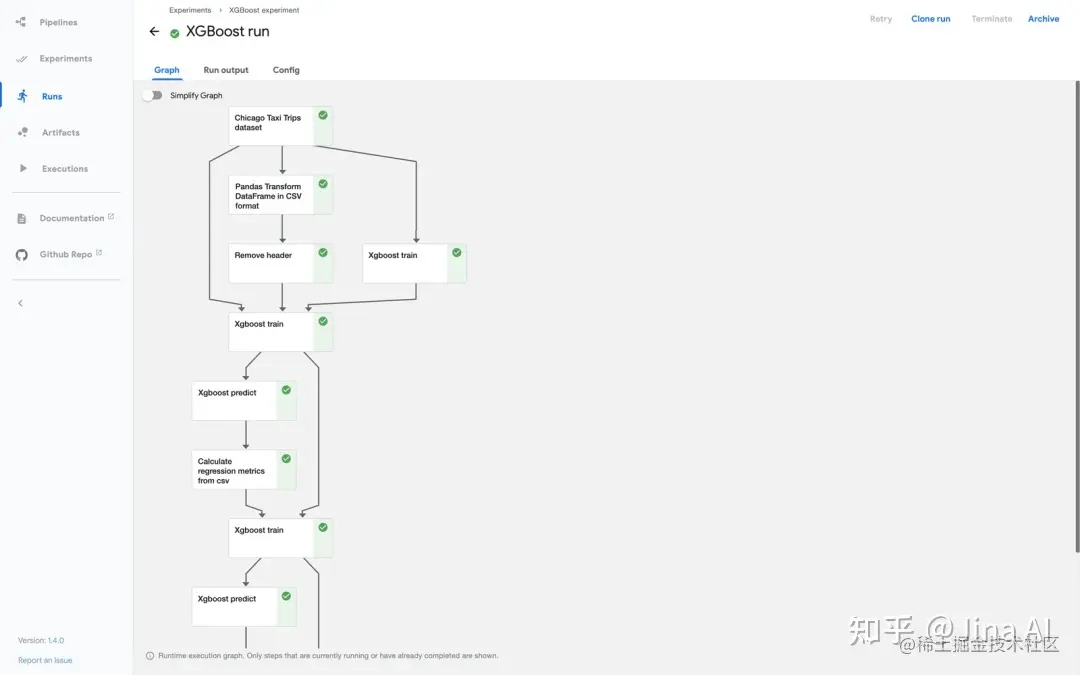
Kubeflow Pipelines UI 中示例流程的运行时执行图
05 Label Studio

Label Studio 是 Heartex 开发的一款开源工具,专注于机器学习生命周期的早期阶段:数据标注。数据标注是将标签添加到数据集的过程,使其能够用于训练机器学习模型。数据标注是非常重要的。首先,它能创建质量更高的数据集。如果数据集未被标记,机器学习模型可能难以从中学习。其次,数据标注可以帮助加速训练过程。第三,数据标注可以提高机器学习模型的结果,使其更加准确。数据标注通常是人工完成的,这是一个耗时且昂贵的过程。
Label Studio 让您可以使用简单的 UI 来标记音频、文本、图像、视频和时间序列等数据类型,并将它们导出到各种模型格式。它可以用于准备原始数据或改进现有的训练数据,以获得更准确的 ML 模型。
您还可以将 Label Studio 与机器学习模型集成,以提供标签的预测(预标记),或进行持续的主动学习。Label Studio ML 后端是一个 SDK,可以让您包装机器学习代码并将其转换为 Web 服务器。然后,就可以将该服务器连接到 Label Studio 实例以执行 2 项任务:
- 基于模型推理结果动态预注释数。
- 据根据最近注释的数据重新训练或微调模型。
例如,要根据示例脚本初始化 ML 后端。
css
复制代码Label-studio-ml init my_ml_backend --script label_studio_ml/examples/simple_text_classifier/simple_text_classifier.pylabel-studio-ml start my_ml_backend
在定义加载器后,您可以为模型定义两种方法:推理调用和训练调用。您可以使用推理调用即时从模型中获取预标记。必须更新示例 ML 后端脚本中的现有predict方法,使其适用于您的特定用例。
ruby复制代码def predict(self, tasks, **kwargs):
predictions = []
# Get annotation tag first, and extract from_name/to_name keys from the labeling config to make predictions
from_name, schema = list(self.parsed_label_config.items())[0]
to_name = schema['to_name'][0]
for task in tasks:
# for each task, return classification results in the form of "choices" pre-annotations
predictions.append({
'result': [{
'from_name': from_name,
'to_name': to_name,
'type': 'choices',
'value': {'choices': ['My Label']}
}],
# optionally you can include prediction scores that you can use to sort the tasks and do active learning
'score': 0.987
})
return predictions
编写您自己的代码来覆盖 predict(tasks, **kwargs) 方法,该方法采用 JSON 格式的 Label Studio 任务并以 Label Studio 接受的格式返回预测。写下你自己的训练调用,通过覆盖fit(annotations,kwargs)方法来更新你的模型的新注释,该方法接受格式化为 JSON 的 Label Studio 注释并返回可以存储有关创建的模型的任意 dict。
python
复制代码def fit(self, completions, workdir=None, **kwargs):# ... do some heavy computations, get your model and store checkpoints and resourcesreturn {'checkpoints': 'my/model/checkpoints'} # <-- you can retrieve this dict as self.train_output in the subsequent calls
如果你只想在不重新训练模型的情况下预注释任务,你不需要在代码中使用此调用。但如果你确实想根据 Label Studio 的注释重新训练模型,请使用fit(annotations,kwargs)方法。在将模型代码与类封装、定义加载器以及定义方法之后,你就可以将模型作为 ML 后端与 Label Studio 一起使用了。很难否认,任何机器学习模型的成功在很大程度上取决于其训练数据的质量。这就是为什么 Label Studio 在 2022 年排名较高,在 MLOps 中起着至关重要的作用。
在内部采用 MLOps 的公司
作为机器学习的重要一环,MLOps 在过去的一年里已经得到了越来越多公司的采用。我们发现越来越多的公司在采用 MLOps 实践,并且分享了他们的经验。特别是,MLOps 有两种主要的方法:中心化方法 和 分散化方法。
- 中心化方法的典型代表是谷歌和 Facebook,他们有负责开发和管理整个 ML 流程的中心化团队。中心化方法的优点在于能够内部开发和管理整个 ML 流程,这样可以更好地控制和透明度。但缺点是可能会变得非常隔离,不同的团队相互独立工作。
- 分散化方法的典型代表是亚马逊和 Netflix,他们有分散的团队,分别管理 ML 流程的一部分。分散化方法的优点在于能够更快地行动并且更灵活,因为每个团队只负责 ML 管道的一部分。但缺点是透明度较低且更难以追踪问题。
在 2022 年,最佳的 MLOps 设置既包含中心化的方法,也包含分散化的方法,具体取决于公司的需求。例如,一家公司可能有一个中心化的团队负责开发 ML 算法,而一个分散化的团队负责训练和部署模型。
向 2023 迈进!
展望 2023 年,我们预计会有更多的公司采用 MLOps 实践,MLOps 的好处将变得更加明显。特别是 在 多模态 AI 的范式转变 中,更多的文本、图像、视频,甚至 3D 模型数据,我们将看到数据集变得更加复杂,自动化数据管道和机器学习管理流程的需求将变得更加关键。
在 2023 年,最成功的 MLOps 配置将是能在人、流程和工具之间找到正确平衡的配置。我们预计,最受迎的开源 MLOps 工具将是那些提供易于使用的界面,并允许自定义以满足特定需求的工具。本文中提到的工具和平台将继续发展并变得更加友好,使它们能够被更广泛的用户使用。我们也预计会看到新的平台出现,以及向现有平台添加新功能和功能。
就具体工具而言,我们认为版本控制工具将变得越来越重要,用于管理 ML 代码和模型。数据注释和标记工具也将获得更多普及,因为对高质量训练数据的需求变得更加明显。最后,模型管理工具将成为管理生产中部署的各种机器学习模型的必要工具。总的来说,我们预计 MLOps 领域将变得更加多元,将提供更多的工具来满足不同组织的需求。2023 年,MLOps 是所有想要在不断变化的机器学习领域保持竞争力的公司必不可少的一部分!让 MLOps 加速您的发展,建立机器学习能力,在竞争中脱颖而出!
零基础如何学习大模型 AI
领取方式在文末
为什么要学习大模型?
学习大模型课程的重要性在于它能够极大地促进个人在人工智能领域的专业发展。大模型技术,如自然语言处理和图像识别,正在推动着人工智能的新发展阶段。通过学习大模型课程,可以掌握设计和实现基于大模型的应用系统所需的基本原理和技术,从而提升自己在数据处理、分析和决策制定方面的能力。此外,大模型技术在多个行业中的应用日益增加,掌握这一技术将有助于提高就业竞争力,并为未来的创新创业提供坚实的基础。
大模型实际应用案例分享
①智能客服:某科技公司员工在学习了大模型课程后,成功开发了一套基于自然语言处理的大模型智能客服系统。该系统不仅提高了客户服务效率,还显著降低了人工成本。
②医疗影像分析:一位医学研究人员通过学习大模型课程,掌握了深度学习技术在医疗影像分析中的应用。他开发的算法能够准确识别肿瘤等病变,为医生提供了有力的诊断辅助。
③金融风险管理:一位金融分析师利用大模型课程中学到的知识,开发了一套信用评分模型。该模型帮助银行更准确地评估贷款申请者的信用风险,降低了不良贷款率。
④智能推荐系统:一位电商平台的工程师在学习大模型课程后,优化了平台的商品推荐算法。新算法提高了用户满意度和购买转化率,为公司带来了显著的增长。
…
这些案例表明,学习大模型课程不仅能够提升个人技能,还能为企业带来实际效益,推动行业创新发展。
学习资料领取
如果你对大模型感兴趣,可以看看我整合并且整理成了一份AI大模型资料包,需要的小伙伴文末免费领取哦,无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发

部分资料展示
一、 AI大模型学习路线图
整个学习分为7个阶段

二、AI大模型实战案例
涵盖AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,皆可用。

三、视频和书籍PDF合集
从入门到进阶这里都有,跟着老师学习事半功倍。


如果二维码失效,可以点击下方链接,一样的哦
【CSDN大礼包】最新AI大模型资源包,这里全都有!无偿分享!!!
😝朋友们如果有需要的话,可以V扫描下方二维码联系领取~


















 859
859

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









