






前言
为了让 AI 模型在特定环境中有用,它通常需要访问背景知识。如客服聊天机器人需要了解它所服务的特定业务,法律分析机器人则需要掌握大量的过往案例。
开发者通常通过 RAG扩展 AI 模型的知识。RAG 是一种从知识库中检索相关信息并将其附加到用户提示词中的方法,从而显著提升模型的回答能力。但传统的 RAG 解决方案在编码信息时会丢失上下文,导致系统无法从知识库中检索到相关信息。
本文介绍了一种显著提升 RAG 检索步骤的方法,称为“上下文检索”,它利用两个子技术:
-
上下文嵌入(Contextual Embeddings)
-
上下文 BM25(Contextual BM25)
该方法可将检索未命中率减少49%,结合重新排序后,甚至可减少67%。这些改进显著提高检索准确性,进而提升下游任务表现。
可通过操作指南轻松部署自己的上下文检索解决方案。
关于简单使用较长提示词的说明
有时最简单的解决方案就是最好。如你的知识库小于 200,000 个 token(约 500 页材料),你可直接将整个知识库包含在给模型的提示词中,无需 RAG 或类似方法。
Claude 已发布提示词缓存,可显著加快并更实惠。开发者现可在 API 调用之间缓存常用提示词,减少超过 2 倍的延迟,降低高达 90% 的成本(阅读提示词缓存操作指南)。
然而,随知识库增长,你需要一个更具扩展性的解决方案。这时,上下文检索就派上用场。
1 RAG 简介:扩展到更大的知识库
对于无法放入上下文窗口的更大知识库,RAG 是典型的解决方案。RAG 通过以下步骤预处理知识库:
-
将知识库(文档的“语料库”)拆分成较小的文本块,通常不超过几百个 token;
-
使用嵌入模型将这些文本块转换为向量嵌入,编码其含义;
-
将这些嵌入存储在向量数据库中,允许通过语义相似性进行搜索。
在运行时,当用户向模型输入查询时,向量数据库用于根据查询的语义相似性查找最相关的文本块。然后,将最相关的文本块添加到发送给生成模型的提示词中。
尽管嵌入模型擅长捕捉语义关系,但它们可能会错过重要的精确匹配。幸运的是,有一种较老的技术可以在这些情况下提供帮助。BM25(最佳匹配 25)是一种排名函数,使用词汇匹配来查找精确的单词或短语匹配。对于包含唯一标识符或技术术语的查询,它特别有效。
BM25 基于 TF-IDF(词频-逆文档频率)的概念。TF-IDF 衡量一个单词在文档集合中的重要性。BM25 通过考虑文档长度并对词频应用饱和函数来改进这一点,这有助于防止常见词主导结果。
以下是 BM25 在语义嵌入失败时的成功之处:假设用户查询“错误代码 TS-999”在技术支持数据库中的信息。嵌入模型可能会找到有关错误代码的内容,但可能会错过精确的“TS-999”匹配。而 BM25 则通过查找这个特定的文本字符串来识别相关文档。
通过结合嵌入和 BM25 技术,RAG 解决方案可以更准确地检索到最适用的文本块,以下是步骤:
-
将知识库(文档“语料库”)分解为较小的文本块,通常不超过几百个 token;
-
为这些块创建 TF-IDF 编码和语义嵌入;
-
使用 BM25 基于精确匹配查找最佳文本块;
-
使用嵌入基于语义相似性查找最佳文本块;
-
使用排名融合技术结合并去重来自(3)和(4)的结果;
-
将前 K 个文本块添加到提示词中生成响应。
通过利用 BM25 和嵌入模型,传统的 RAG 系统可以提供更全面和准确的结果,平衡精确术语匹配和广泛语义理解。
 标准的 RAG 系统使用嵌入和 BM25 结合检索信息。TF-IDF 衡量词的重要性,是 BM25 的基础。
标准的 RAG 系统使用嵌入和 BM25 结合检索信息。TF-IDF 衡量词的重要性,是 BM25 的基础。
这种方法可以让你以低成本扩展到庞大的知识库,远超单个提示词所能容纳的范围。但传统 RAG 系统有一个显著的局限:它们往往破坏上下文。
传统 RAG 中的上下文问题
在传统 RAG 中,文档通常被拆分为较小的块,以便于检索。尽管这种方法在许多应用中表现良好,但当单个文本块缺乏足够的上下文时,可能会导致问题。
例如,假设你的知识库中嵌入了一个财务信息集合(比如美国证券交易委员会的文件),你收到如下问题:“2023 年第二季度 ACME 公司收入增长了多少?”
一个相关的文本块可能包含:“公司收入比上一季度增长了 3%。”然而,这个块本身并未指明是哪家公司或哪个时间段,导致很难检索到正确的信息或有效使用这些信息。
2 引入上下文检索
上下文检索通过在嵌入前将块特定的解释性上下文添加到每个块中(“上下文嵌入”)以及创建 BM25 索引(“上下文 BM25”)来解决此问题。
回到美国证券交易委员会文件的例子。以下是一个文本块的转换示例:
原始文本块 = “公司收入比上一季度增长了 3%。”
上下文化文本块 = “本块来自 ACME 公司 2023 年第二季度的证券交易委员会文件;上一季度的收入为 3.14 亿美元。公司收入比上一季度增长了 3%。”
值得注意的是,过去曾提出过其他使用上下文改进检索的方法。其他提案包括:为文本块添加通用文档摘要(实验后发现效果有限),使用假设文档嵌入(评估后发现效果不佳),以及基于摘要的索引(实验后表现不佳)。这些方法与本文提出的方案不同。
实现上下文检索
当然,手动为知识库中的成千上万个块注释上下文太费力。为实现上下文检索,转向了 Claude。编写了一个提示词,指示模型提供简洁、特定于块的上下文,使用整个文档的上下文来解释该块。使用了以下 Claude 3 Haiku 提示词为每个块生成上下文:
<document>
{{WHOLE_DOCUMENT}}
</document>
这是我们希望在整个文档中定位的块
<chunk>
{{CHUNK_CONTENT}}
</chunk>
请提供简短的上下文,以便在文档中更好地定位此块以改进搜索检索。只回答简短的上下文,别无其他。
生成的上下文文本通常为 50 到 100 个 token,将其附加到文本块之前进行嵌入并创建 BM25 索引。
实际预处理流程的示意图:
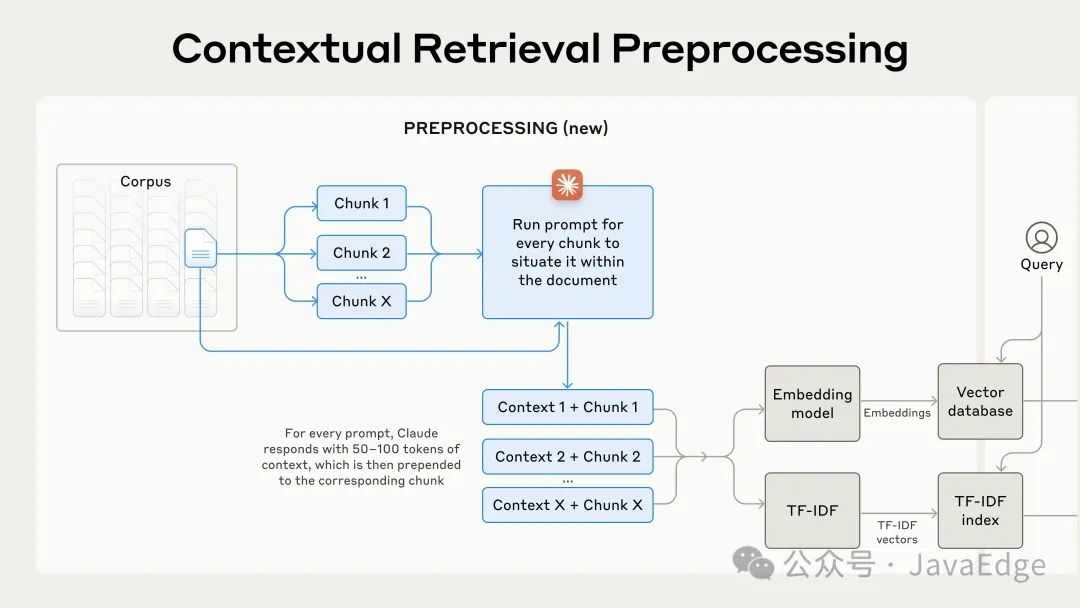 上下文检索是一种预处理技术,可以提高检索准确性。
上下文检索是一种预处理技术,可以提高检索准确性。
如果你有兴趣使用上下文检索,可通过操作指南入手。
使用提示词缓存降低上下文检索的成本
得益于 Claude 的特殊提示词缓存功能,上下文检索在低成本上具有独特优势。使用提示词缓存,你无需为每个块传入参考文档。你只需将文档一次性加载到缓存中,然后引用先前缓存的内容。假设每个块 800 个 token,文档 8,000 个 token,50 个 token 的上下文指令,以及每个块 100 个 token 的上下文,生成上下文化块的一次性成本为每百万文档 token 1.02 美元。
方法论
在各个知识领域(代码库、小说、ArXiv 论文、科学论文)、嵌入模型、检索策略和评估指标之间进行了实验。附录 II中提供了一些问题和答案的示例。
下图显示了在所有知识领域中使用最优嵌入配置(Gemini Text 004)并检索前 20 个块的平均表现。使用 1 减去 Recall@20 作为评估指标,它衡量前 20 个块中未能检索到相关文档的百分比。你可以在附录中看到完整结果——上下文化提高了评估的每种嵌入源组合的表现。
性能提升
实验表明:
-
上下文嵌入将前 20 个块检索失败率降低了 35%(5.7% → 3.7%)。
-
上下文嵌入和上下文 BM25 结合使用,将前 20 个块检索未命中率降低了 49%(5.7% → 2.9%)。
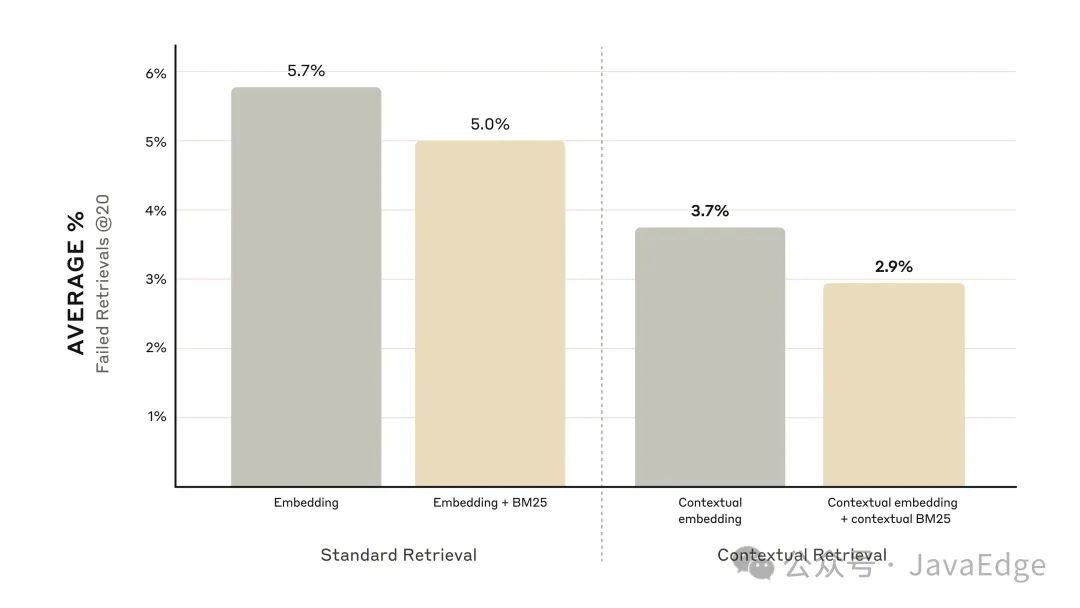 上下文嵌入和上下文 BM25 结合使用将前 20 个块检索未命中率降低了 49%。
上下文嵌入和上下文 BM25 结合使用将前 20 个块检索未命中率降低了 49%。
实施考虑
在实施上下文检索时,需要考虑以下几点:
-
文本块边界:考虑如何将文档拆分为文本块。文本块大小、边界以及重叠会影响检索表现。
-
嵌入模型:尽管上下文检索提高了测试的所有嵌入模型的性能,但某些模型可能受益更多。发现 Gemini 和 Voyage 嵌入特别有效。
-
自定义上下文提示词:虽然提供的通用提示词效果不错,但你可以通过针对特定领域或用例调整提示词,获得更好的结果(例如,包含知识库其他文档中定义的关键术语词汇表)。
-
文本块数量:将更多的文本块添加到上下文窗口中可以增加包含相关信息的机会。然而,过多信息可能会对模型造成干扰,因此有一个限度。尝试了 5、10 和 20 个块,发现 20 个块是最有效的选项,但值得根据你的用例进行实验。
始终进行评估:通过传递上下文化的文本块并区分上下文和块内容,生成的响应可能会得到改进。
3 通过重排,进一步提升性能
最后一步,可结合上下文检索与另一种技术,以进一步提升性能。在传统 RAG 中,AI 系统会在其知识库中搜索潜在的相关信息块。当知识库很大时,这种初始检索往往会返回大量块——有时成百上千块,且相关性和重要性各不相同。
重新排序是一种常用的过滤技术,确保只有最相关的文本块被传递给模型。重新排序能提供更好的响应,并减少成本和延迟,因为模型处理的信息更少。关键步骤如下:
-
进行初始检索,获取潜在相关文本块的前 N 个(使用前 150 个);
-
将前 N 个文本块与用户的查询一起传递给重新排序模型;
-
使用重新排序模型,根据每个块与提示词的相关性和重要性给出得分,然后选择前 K 个块(使用前 20 个);
-
将前 K 个文本块作为上下文传递给模型生成最终结果。
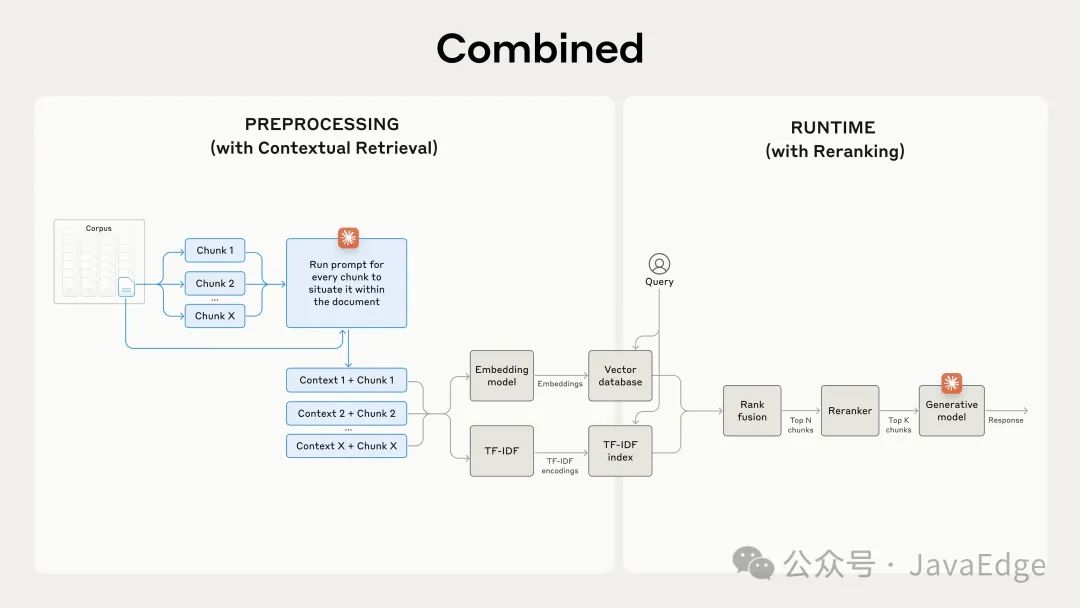 结合上下文检索和重新排序以最大化检索准确性。
结合上下文检索和重新排序以最大化检索准确性。
性能提升
市场上有多种重新排序模型。使用 Cohere reranker 进行测试。Voyage 也提供了重新排序器,但没时间测试。实验表明,跨多个领域,添加重新排序步骤进一步优化了检索。
重新排序后的上下文嵌入和上下文 BM25 将前 20 个块检索未命中率降低了 67%(5.7% → 1.9%)。
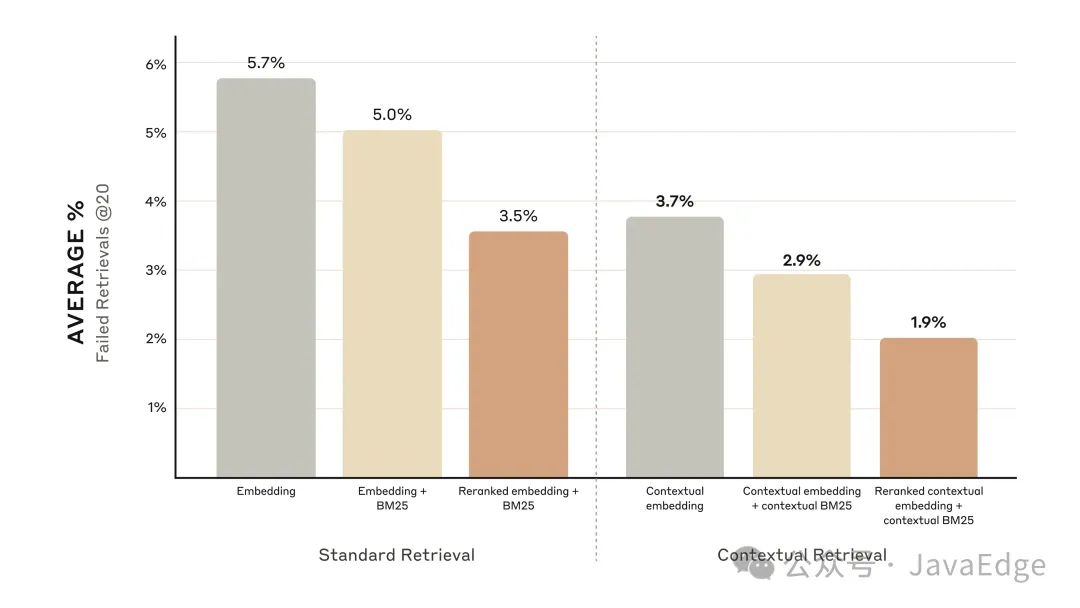 重新排序的上下文嵌入和上下文 BM25 将前 20 个块检索未命中率降低了 67%。
重新排序的上下文嵌入和上下文 BM25 将前 20 个块检索未命中率降低了 67%。
成本和延迟考虑
重新排序的一个重要考虑因素是对延迟和成本的影响,尤其是在对大量文本块进行重新排序时。因为重新排序在运行时增加了额外的步骤,必然会增加少量延迟,尽管重新排序器会并行对所有文本块进行评分。在检索更多文本块以提高性能与检索较少文本块以降低延迟和成本之间存在权衡。建议在你的具体用例上进行不同设置的实验,找到合适的平衡点。
4 结论
大量测试比较上述所有技术(嵌入模型、BM25 的使用、上下文检索的使用、重新排序的使用,以及检索的前 K 个结果总数)的不同组合,跨各种数据集类型。发现摘要:
-
嵌入+BM25 优于仅使用嵌入;
-
Voyage 和 Gemini 是测试过的最佳嵌入模型;
-
向模型传递前 20 个文本块比传递前 10 个或前 5 个更有效;
-
为文本块添加上下文极大地提高了检索准确性;
-
重新排序优于不重新排序;
-
所有这些优势是可叠加的:为了最大化性能改进,可以将上下文嵌入(来自 Voyage 或 Gemini)与上下文 BM25 相结合,再加上重新排序步骤,并将 20 个文本块添加到提示词中。
鼓励所有使用知识库的开发者通过操作指南进行实验,以解锁新的性能水平。
最后的最后
感谢你们的阅读和喜欢,我收藏了很多技术干货,可以共享给喜欢我文章的朋友们,如果你肯花时间沉下心去学习,它们一定能帮到你。
因为这个行业不同于其他行业,知识体系实在是过于庞大,知识更新也非常快。作为一个普通人,无法全部学完,所以我们在提升技术的时候,首先需要明确一个目标,然后制定好完整的计划,同时找到好的学习方法,这样才能更快的提升自己。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

大模型知识脑图
为了成为更好的 AI大模型 开发者,这里为大家提供了总的路线图。它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

经典书籍阅读
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。

实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

面试资料
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下

640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】















 3907
3907

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









