






文章目录
-
- 1、常见的生成模型
- 2、变分推断简介
- 3、文生图的评价指标
- 4、Diffusion Models
- 5、其他
- 技术交流群
- 精选
1、常见的生成模型
如图1所示,常见的生成模型有四种:GAN(Generative Adversarial Network)、VAE(Variational Autoencoder)、Flow-Based Models、Diffusion Models。
今天我们讲一讲扩散模型(DM,Diffusion Models)的原理。
DM和VAE一样,都是属于变分推断(VI,Variational Inference)的理论框架。

2、变分推断简介
2.1、统计学简介
在统计学中,一切都是分布(Distribution),到处都是分布。
统计学的根本目的就是获得数据分布。 只要得到了数据的分布,那一切问题都迎刃而解。
但现实数据的分布往往是不可得的,是极其复杂的,所以统计学在应用中到处充满假设:假设样本服从独立同分布原理;假设噪声服从高斯分布;假设特征之间相互独立等。翻开机器学习或者数理统计的书籍,到处充满着假设。没办法,现实问题太复杂!
如何获得复杂的未知分布呢? 最常用的方法就贝叶斯推断。
2.2、贝叶斯推断
贝叶斯推断的目的就是:找出复杂的未知分布。
贝叶斯推断有两类方法:一是MCMC采样;二是变分推断(VI,Variational Inference)。如图2所示。
MCMC属于采样的方法,成本高。变分推断属于数学优化的方法,成本相对较对低。

3、文生图的评价指标
文生图领域有两个评价指标:FID和CLIP。
3.1、FID
FID:Frechet Inception Distance。 用一个训练过的CNN网络提取图片的隐层特征,分别得到两个隐层特征的集合。一个是真实图片的隐层特征集合,一个是生成图片的隐层特征集合。再把这两个集合看作分布,计算两个分布的距离。
FID值越小越好。 如图3所示。

3.2、CLIP
CLIP:Contrastive Language-Image Pretraining。
一个预训练的图文对模型。基于4亿个图文对进行了对比学习。
CLIP得分越大越好。
3.3、优缺点
FID的评价很准确,但需要大量的数据,才能进行评估。
CLIP可以对单张图片进行评价,但只适用于图文对的场景。
4、Diffusion Models
4.1、Diffusion-生成过程
Diffusion生成目标对象的过程,称为生成过程、去噪过程、后向过程等。Diffusion的生成过程从噪声开始。本文都以图片生成为例。
首先, 从标准高斯分布中采样得到一张全是噪声的图片XT。
然后, 从XT 中去掉一点噪声,得到一张噪声更少的图片XT-1。**如此重复T步,**最后直到X1就是一张生成的图片。
意大利著名的雕塑家米开朗基罗说过:“塑像本来就在石头里,我只是把不需要的部分去掉。” Diffusion的生成过程与此类似,图片本来就在噪声里,Diffusion模型只是把不需要的噪声去掉,让图片显露出来!
如图5所示:
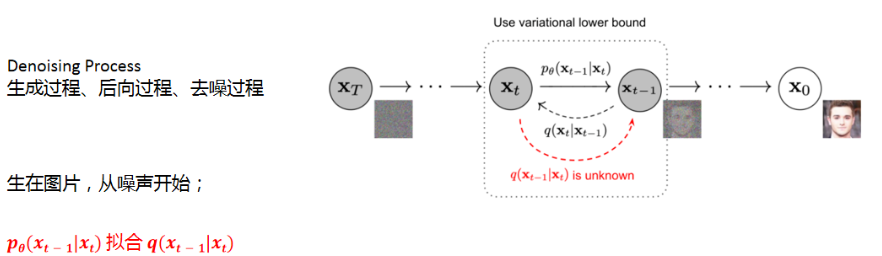
图5 Diffusion 去噪过程
4.2、Diffusion-扩散过程
Diffusion的扩散过程,也称为前向过程、加噪过程。 如图6所示。
扩散过程为模型的训练提供了有标注的样本。前面说过,生成过程是从噪声中逐步去噪声,最后生成图片。那模型怎么知道该去什么样的噪声,去多少噪声呢?这就是扩散过程的作用。扩散过程往已知的图片中逐步加入噪声,直到图片完全变成标准高斯噪声。这个加噪声的过程是人为控制的,所加的噪声也是知道的,所以反过来就用这个噪声作为标准,指导模型去噪,这相当于是一个有监督的学习过程。
总之,扩散过程是一个事先预定义的确定过程,用来给生成过程提供有监督的样本。
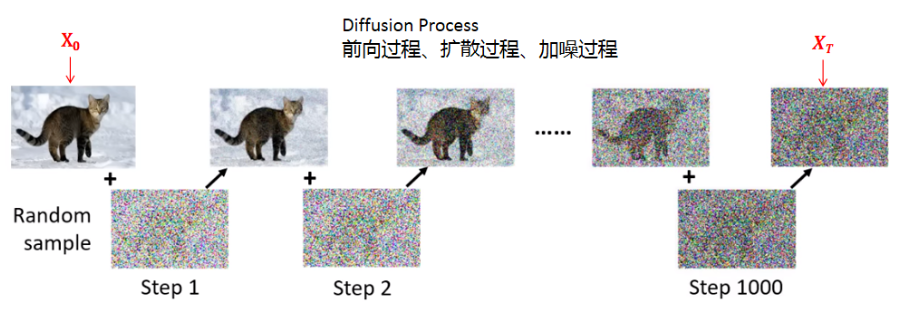
图6 Diffusion Model 加噪过程
4.3、Diffusion-模型训练
模型训练如图7所示。训练的神经网络是一个噪声预测器(Noise Predicter)。
Noise Predicter输入有两个:一是带噪声的图片;二是当前的步数。在Conditional的场景下,还会输入生成条件。
Noise Predicter的输出为:当前图片中所包含的噪声大小。
训练的优化目标为:预测出来的噪声与扩散过程中所加入的真实噪声之间的均方误差MSE(Mean-Square Error)。
4.4、Diffusion-模型推理
模型推理,就是生成数据的过程。确切的生成算法如图8所示。
Algorithm2来源于论文DDPM-《Denoising Diffusion Probabilistic Models》。
DDPM的主要问题是效率低下,因为必须要经过T步,才能生成最终图片。
从图中可以看出,Noise Predicter预测出图片的噪声后,用Xt减去噪声,就得到了去噪后的图片。
但去噪声后,又给图片加上了一点高斯噪声。这是为什么呢?通常认为这是算法落地中的一个Trick。在机器学习中,这种Trick很常见,如dropout。这样通常能增加模型的泛化性。另一种解释是,Diffusion整体上是一个自回归Autoregressive过程,与GPT类似。在AR模型中,每一步都喜欢加一点随机性,如GPT中常用的BeamSearch。
4.5、三种解释
Diffusion Models是一个马尔可夫层次化变分自编码器(Markovian Hierarchical Variational Autoencoder)。

优化EBLO等价于优化以下任意一种目标函数:
1. 优化对原始数据x0的预测结果;—在Discrete Diffusion Models会用到;
2 优化对原始噪声的预测结果;—连续Diffusion Models中最常用;
3. 优化对分数函数的预测结果;—基于热力学能量函数的推导时用到。
4.7、Diffusion-Conditional
前面讨论的是论文DDPM中原生的Diffusion Models。但实践使用时,我们是要根据条件来生成目标数据。如文生图,需要根据给定的文本来生成目标图片。
从原理上来看,根据给定的条件生成数据,和原生的DDPM是完全一样的。只是拟合目标由后验概率分布转化为条件后验概率分布。这两者的理论推导是完全相同的。
在实现上,Noise Predicter的输入中增加了一个条件项,如输入的文本。当然这个条件项往往是其它模态的,需要进行Embedding才能输入到Noise Predicter的神经网络里面。
5、其他
5.1
DDPM的改进
DDPM最大的问题就是它的生成过程速度慢,效率低。需要一步一步地进行Denoising。为此,论文DDIM(Denosing Diffusion Implicit Models)对它进行了改进。
DDPM通常需要1000步来生成一张图片,但DDIM通过只需要5-20步即可。当然DDIM的图片质量略差于DDPM。
5.2
离散场景
图片是一种典型的连续场景,因为每个像素的取值在给定的范围(如0-1)之间可以随便选取。但还有很多离散的场景,如Text、Graph等。在离散场景中如何使用Diffusion Models呢?这还是一个新兴的研究方向,常用的做法是改变噪声的形式。
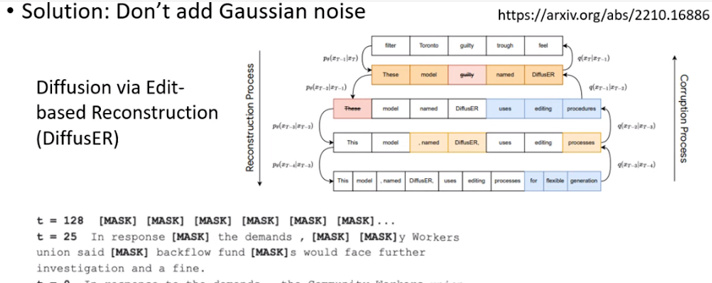
图12 Diffusion + Text
5.3
Stable Diffusion
Stable Diffusion是对原生Diffusion的一种改动。Stable Diffusion原来叫 Latent Diffusion Models。它与Diffusion的最大区别是噪声加在隐状态空间。
Diffusion的噪声与图片是相同尺寸的,它的加噪声和去噪声直接发生在原始数据上。Stable Diffusion会使用一个编码器,先把图片映射到一个低维的隐状态空间中,再在这个隐空间中对图片的Embedding进行加噪声和去噪声。因为隐状态空间的维度低,所以Stable Diffusion的速度比原生的Diffusion更快。但二者的理论基础是相同的!
如何学习AI大模型?
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓
















 6万+
6万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









