






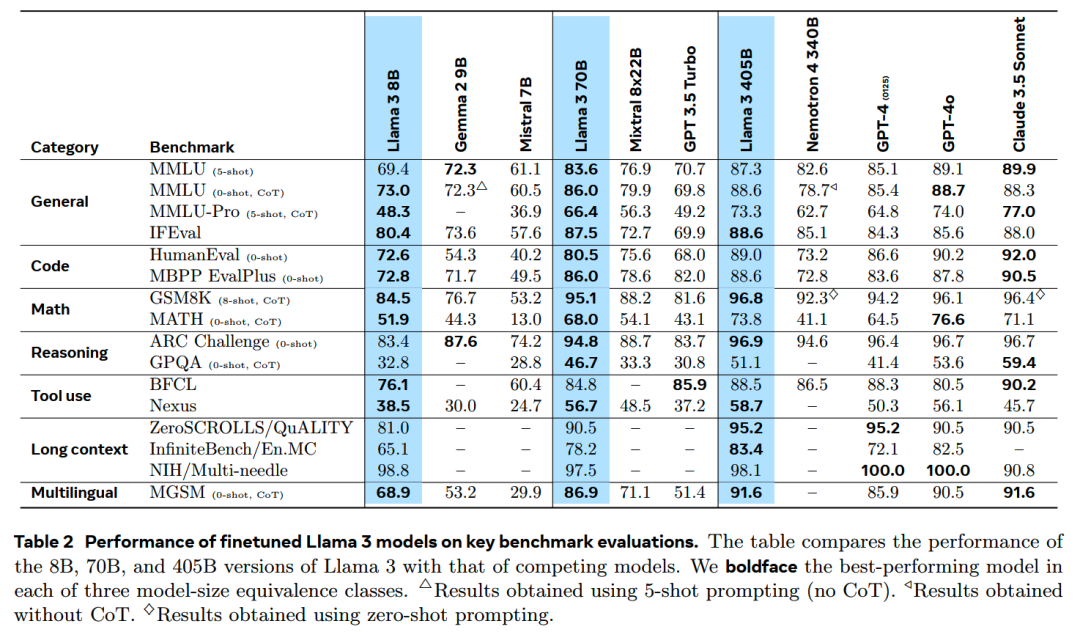
最近Llama-3.1-405B模型放出,从官方的评测结果看,已经超越了GPT-4-0125,基本达到顶尖闭源模型Claude-3.5-Sonnet和GPT-4-OMNI的水平;而更小规模的8B和70B模型相比其他同规模模型优势更加明显:
Meta还放出了将近100页的Llama-3技术报告,披露了一些方案的细节,从中还是能得到很多有用的信息的。本篇先梳理一下预训练相关的内容。
(最近这两周真是大新闻一个接一个啊,这不Mistral Large V2又出来了;另外Llama-3仍然不支持中文,某种角度上算是利好中文大模型开发者吧)
1.Llama-3家族
Llama-3家族包括早先发布的8B/70B模型,以及最近刚放出来的Llama-3.1系列的8B/70/405B模型:

在这些模型里,Llama-3.1-405B作为最强的旗舰模型,也是大家最关注的,报告里基本也是以405B模型为主介绍的。
1.1.关于405B模型
405B模型总共在15.6T token上进行预训练,并且支持128k的窗口长度。这个数据量是Llama-2的将近9倍(15.6T vs 1.8T),而总训练计算量也达到了Llama-2-70B训练的50+倍。
405B × 15.6T这个模型规模和数据量是根据Meta实验出来的scaling law计算出来的(后面会讲到)。对于较小的模型,Meta进行了“比scaling law建议的compute-optimal token数”更多的训练,而从结果上看,效果确实也有进一步的提升。
405B这个规模的dense模型在如今MoE的潮流中显得有些“复古”。Meta对此给出了解释:不做成MoE模型是因为要追求能力的最大化(通常来说,相同总参数量下dense模型还是比MoE要强一些的),同时使用标准的Transformer模型可以让训练更加稳定,毕竟这样大规模的训练成本巨大,如果中间训炸了还是比较麻烦的。包括在post-training中使用的supervised finetuning(SFT),rejection sampling(RS),and direct preference optimization(DPO)都是经受住了许多考验,证明有效的方案。看起来这里在路线的选择上,Meta倾向于保守一些。
405B模型的训练用到了16k个 H100,并行方案结合了tensor parallelism、pipeline parallelism、context parallelism和data parallelism,整个集群的搭建也是花了很多精力。
1.2.模型结构
Llama-3和之前的两个版本在模型结构上没有做太多变化。少数的几个改动也是在其他工作都已经广泛应用的了:
- 使用GQA,降低推理时KV cache的需求。
- 训练时使用document mask,防止各个文档关注到序列中拼接的其他无关文档;这个改动对预训练后期的长窗口训练比较重要,而对短文本的常规预训练没太大影响。
- 把RoPE的base frequency增大到500,000,按《Effective long-context scaling of foundation models》的结果,这个数值足够支持32,768长度的窗口了。
- 使用了128k大小的词表,其中100k是从tiktoken来的,其它28k用于支持非英文内容;更大的词表提供了更高的压缩率,平均每token字符数3.17–>3.94。
具体的模型参数如下表

1.3.Scaling Laws
LLM的scaling law可以告诉我们在给定的预算下,应该用多少的数据和训多大的模型来获得效果最佳的模型。不过在用scaling law来预测最佳模型规模的时候,会遇到两个问题:
- 现有的scaling law主要用next-token prediction的loss来预测,但这个loss未必和下游任务的效果单调相关
- 用于拟合scaling law的实验如果使用的compute budget比较少,可能会因为随机性等引入了一些噪音,导致scaling law拟合的结果失真
针对这个两个问题,Meta用一个two-stage的方法来建立downstream benchmark performace和模型规模+数据量的关系:
- 首先建立“compute-optimal model在downstream task上的negative log-likelihood”和训练FLOPs的关系
- 然后建立negative log-likelihood与task accuracy之间的关联,这里除了scaling law models,还用上了Llama-2中有更高训练FLOPs的模型
类似的方法也应用到选择pre-training data mix中。
具体来说,对从40M到16B的模型进行不同FLOPs的训练,得到各个compute预算下的最佳规模:
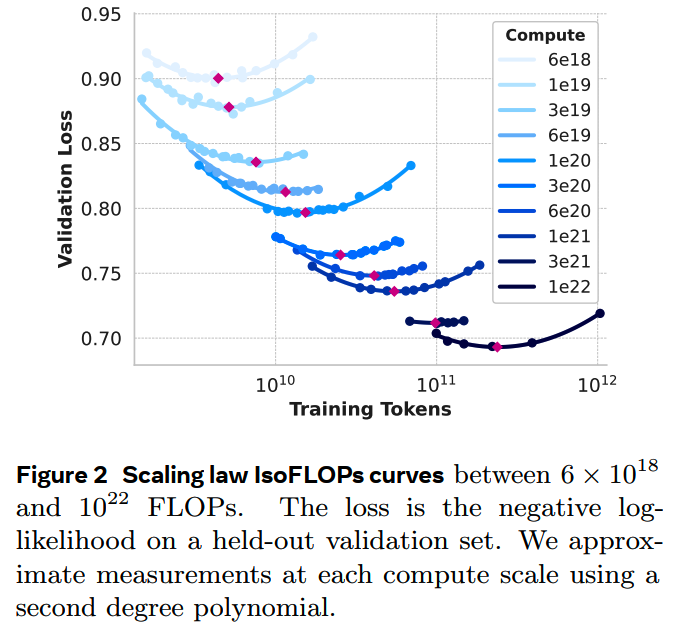
这里训练的时候根据模型大小使用了不同的lr,同时在不同的compute budget下使用了从250k到4M不等的batch size。
基于这些实验结果,对给定compute budget C下的optimal number of training token 进行拟合:
得到 ,从这里推算出 FLOPs的计compute budget对应的最佳规模和数据量是402B和16.55T token。
从这些实验结果还另外得到一个发现:随着compute budget的增加,IsoFLOPs的曲线逐渐变得平缓,这说明大规模的模型对规模和训练数据量的少量波动会更加robust,少量的波动不会对最终结果造成很大影响。
在这个基础上,先拟合“各个compute budget下最佳模型在下游benchmark的正确答案上的Normalized NLL per Char”和FLOPs之间的线性关系,再拟合Normalized NLL per Char和下游任务accuracy的sigmoid关系。这样就建立了FLOPs和下游benchmark上accuracy的关系。在ARC Challenge任务上的拟合情况如下

从结果上看,这个方法预测的405B效果基本准确,偏差很小。
2.Pre-Training
2.1.数据
Llama-3的训练数据更新到2023年底。
1、数据获取
大部分数据是从网页爬取的,要经过一系列的清洗处理才可用。
(1)personally identifiable information(PII)and safety filtering
首先就是要清洗掉和个人信息相关,以及包含成人内容的数据。
(2)text extraction and cleaning
为了提取网页数据,Meta构建了效果更好的HTML parser,并用人工检验了效果。
对于数学相关的页面,特意保留了图片,因为很多公式都被渲染成了图片。
此外,经过实验还发现markdown格式的数据对效果有损害,因此把所有markdown marker都干掉了。
(3)去重
- URL-level:对于同一个页面,只保留最新的版本。
- Document-level:用MinHash做了文档级别的近似去重。
- Line-level:和ccNet的做法相似,对于一个包含30M文档的bucket,如果某行数据重复出现超过6次就会被删除。人工检查发现这样做能够删掉一些如网页导航、cookie warnings这样的没太大价值的数据,但是也会删掉一些高频的高质量数据,不过从结果上来看总体的正收益是比较大的。
(4)Heuristic filtering
数据质量清洗:
- 参考《Scaling language models: Methods, analysis & insights from training gopher》,用n-gram coverage ratio过滤掉包含大量重复信息的内容(比如logging和error messages);这些内容在大量重复的同时又不完全相同,所以可能在去重中会被漏掉。
- 参考《Exploring the limits of transfer learning with a unified text-to-text transformer》,用dirty word counting过滤成人内容。
- 通过token分布的KL散度过滤掉包含过量outlier token的内容。
(5)Model-based quality filtering
用Llama-2对数据质量做分类,然后用fasttext和DistilRoberta学习Llama-2给出的数据,用于对数据是否符合质量要求进行分类。
(6)Code and reasoning data
在代码和推理数据上,使用类似DeepSeek-Coder-V2的做法。针对包含数学推理、STEM领域推理以及与自然语言交织的代码网页,调整了HTML的提取规则、质量分类的prompt等。
(7)Multilingual data
对于多语言数据,在移除可能包含PII和成人内容的数据之后:
- 用fasttext把数据进行176种语言的分类。
- 进行document-level和line-level的去重。
- 用每种语言各自的质量分类器过滤低质量数据。
并通过实验确定最终各种语言的占比,平衡英文和多语言的应答质量。
2、Data Mix
不同来源和领域的数据配比会极大影响各个下游任务效果。这里主要用到knowledge classification和scaling law experiments来决定数据配比。
- Knowledge classification:给数据进行领域的分类,并减少训练数据中某些种类的数据,比如arts和entertainment数据。
- Scaling laws for data mix:通过在规模较小的模型对不同的data mix分别跑scaling law的实验,来获取最佳的data mix。
- Data mix summary:最终的数据中,约50%属于general knowledge,25%属于数学和推理,17%的代码以及8%的多语言数据。
3、Annealing Data
在learning rate的退火阶段使用高质量的代码和数学数据可以提升在关键benchmark上的效果。参考《Datacomp-lm: In search of the next generation of training sets for language models》的做法,在退火阶段对高质量数据进行了upsampled。
按这个做法,在GSM8k和MATH数据集上检测了8B模型,发现都有比较大的提升,但是405B模型的提升则不大,猜测可能是因为405B模型的in-context learning能力和推理能力本身已经比较强了,因此即使不在退火阶段使用相关高质量数据集,也已经效果比较好。
另外,既然annealing加入对应数据可以提升下游任务的效果,那么就可以用annealing来检测数据质量了。通过在退火阶段加入不同的数据,观察对下游任务的影响,来判断所加数据是否是高质量数据,这和《Does your data spark joy?performance gains from domain upsampling at the end of training》的思路类似。
2.2.训练方案
405B模型的预训练分为3个阶段:
- initial pre-training
- long-context pre-training
- annealing
(1)initial pre-training
一些训练设置:
- cosine learning rate schedule
- peark lr = 8e-5
- batch size schedule:最开始用长度4k的窗口训练,batch size为4M;训练到252M(个人觉得这里可能是写错了,应该是252B) token之后,把窗口长度提升到8k,batch size也增大到8M token;在训练了2.87T之后,再次把长度double,batch size变成16M;这样的batch size schedule更加稳定,突刺更少出现
在训练的后期还加入了更多时间上更新的网络数据,把模型的知识截止点往后推进。
(2)long-context pre-training
Llama-3最终支持128k的窗口,但是模型并不是从8k或者16k一下子提升到128k,而是从8k开始,分6次增大窗口到128k,并且之后当模型适应了当前阶段的长度变化之后,才会继续提升到下一阶段的长度。
判断模型是否已经适应当前长度有两个标准:
- 在短文本评测上的表现完全恢复
- 对当前长度下的大海捞针任务做到100%召回
整个长文本训练总共训练了800B数据。
(3)annealing
在最后的40M(这里可能是写错了,应该是40B,毕竟一个step都128M了) token数据,lr线性衰减到0,同时提高高质量数据的比例。最后,对annealing阶段的多个model checkpoint进行平均,获得最终模型。
3.小结
从个人角度觉得有几个点可以参考:
- 使用annealing来发现有价值的预训练数据
- 长文本的curriculum learning,逐步扩展
- 通过scaling law把FLOPs和下游任务效果关联起来,但是这个成本比较高,一般机构直接用结果就行了
- 基于和下游任务效果关联的scaling law选择data mix,同样是大力出奇迹,all you need is money
- checkpoint average,和苹果用到的model soup类似,是个值得关注的技巧
如何学习AI大模型?
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓
















 71
71

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









