






在大模型的开发过程中,模型初始化决定了模型训练的效果、收敛速度以及性能表现。通过合理的初始化策略,可以避免梯度消失和梯度爆炸问题,确保模型能更好地学习到数据中的有用信息。在本文中,我们将从初始化策略、权重与偏置初始化、代码实现等多个角度详细介绍大模型的初始化过程。
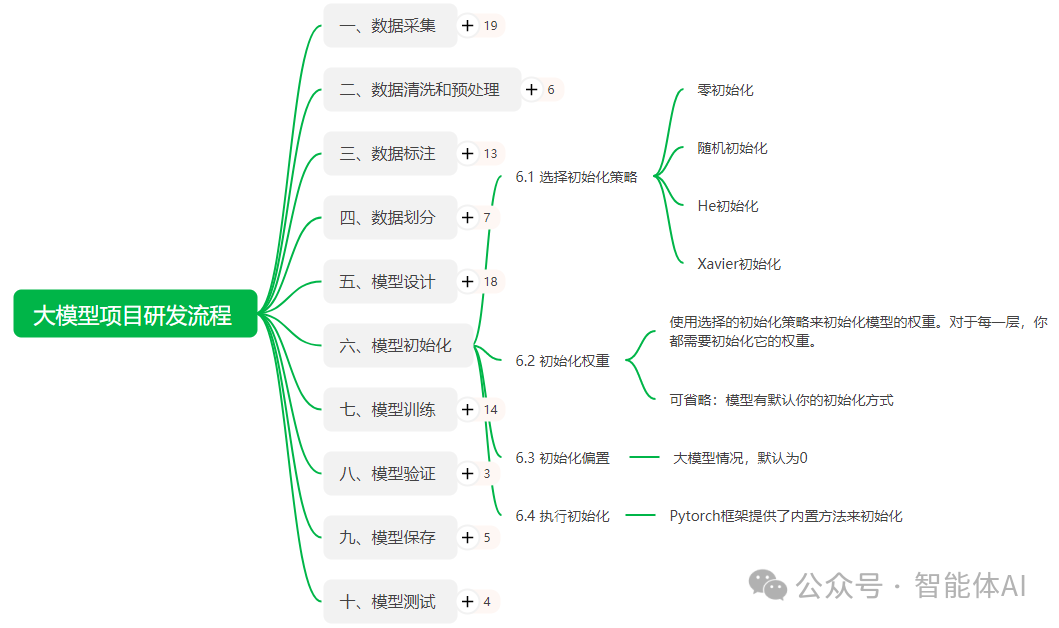
一、选择初始化策略
模型初始化的关键是为每层的权重选择合适的初始值,以确保模型能够有效地训练并避免数值不稳定的现象。下面是几种常见的初始化策略及其适用场景。
1. 零初始化
零初始化非常简单,即将所有的权重设为零。这种方式虽然操作简单,但它的问题在于所有的神经元输出将完全相同,导致模型无法学习不同的特征,因此通常不推荐在神经网络中使用零初始化。
import torch
import torch.nn as nn
# 使用零初始化来初始化模型的权重
def zero_init(m):
if isinstance(m, nn.Linear):
nn.init.zeros_(m.weight) # 将权重初始化为0
# 创建简单的全连接模型
model = nn.Sequential(
nn.Linear(128, 64),
nn.ReLU(),
nn.Linear(64, 10)
)
# 应用零初始化
model.apply(zero_init)
问题:由于每个神经元的输出相同,反向传播中的梯度将无法有效更新权重,模型训练失败。
解决方案:零初始化一般只用于特定情况,比如偏置项的初始化,但不应用于权重的初始化。
2. 随机初始化
随机初始化通过给每个权重赋予一个小的随机值来避免零初始化的问题。通常采用正态分布或均匀分布来生成随机数。然而,随机初始化的权重如果过大或过小,会导致梯度消失或梯度爆炸。
# 使用随机初始化
def random_init(m):
if isinstance(m, nn.Linear):
nn.init.normal_(m.weight, mean=0, std=0.01) # 使用正态分布初始化权重
# 应用随机初始化
model.apply(random_init)
问题:初始权重值如果设得过大,可能会导致梯度爆炸;如果太小,可能导致梯度消失,训练变得非常缓慢。
解决方案:结合后续激活函数和模型深度,调整随机初始化的标准差范围,使模型更稳定地训练。
3. He初始化
He初始化专门为ReLU激活函数设计,它通过缩放初始化值的方差来减小梯度消失的问题,特别适合深层网络。He初始化根据输入的数量fan_in计算合适的方差。
# 使用He初始化
def he_init(m):
if isinstance(m, nn.Linear):
nn.init.kaiming_normal_(m.weight, nonlinearity='relu') # He初始化
# 应用He初始化
model.apply(he_init)
问题:He初始化在使用ReLU及其变体激活函数时效果显著,但对其他激活函数可能不适用。
解决方案:仅在使用ReLU等非线性激活函数时采用He初始化,其他情况下应考虑其他初始化方法。
4. Xavier初始化
Xavier初始化(也叫Glorot初始化)通过控制输入和输出的方差,确保信号在前向传播和反向传播时保持稳定,适用于Sigmoid和Tanh激活函数。
# 使用Xavier初始化
def xavier_init(m):
if isinstance(m, nn.Linear):
nn.init.xavier_normal_(m.weight) # Xavier初始化
# 应用Xavier初始化
model.apply(xavier_init)
问题:Xavier初始化对使用Sigmoid和Tanh激活函数的网络非常有效,但对于ReLU可能效果不佳。
解决方案:在网络使用Sigmoid或Tanh激活函数时采用Xavier初始化,ReLU函数则使用He初始化。
二、初始化权重
选择合适的初始化策略后,我们需要在模型的每一层中使用该策略来初始化权重。在深度学习框架(如Pytorch)中,通常可以通过内置函数来管理权重的初始化,但我们仍需根据具体任务定制初始化方式。
以下示例展示如何在一个简单的全连接神经网络中,使用自定义的He初始化方法:
import torch
import torch.nn as nn
# 定义一个模型
class MyModel(nn.Module):
def __init__(self):
super(MyModel, self).__init__()
self.fc1 = nn.Linear(128, 64)
self.fc2 = nn.Linear(64, 10)
def forward(self, x):
x = torch.relu(self.fc1(x))
x = self.fc2(x)
return x
# 使用He初始化模型的权重
def init_weights(m):
if isinstance(m, nn.Linear):
nn.init.kaiming_normal_(m.weight, nonlinearity='relu') # He初始化权重
model = MyModel()
model.apply(init_weights) # 为所有层初始化权重
解释:这里我们定义了一个简单的两层全连接网络,并使用He初始化策略来初始化每层的权重。nn.init.kaiming_normal_是Pytorch提供的He初始化函数。
三、初始化偏置
偏置项的初始化通常比权重初始化简单。在大多数情况下,偏置项可以初始化为0,这样可以加速收敛。特别是在大模型的场景下,偏置项的初始化为0是一个常见的选择。
# 初始化偏置为0
def init_bias(m):
if isinstance(m, nn.Linear):
nn.init.zeros_(m.bias) # 将偏置初始化为0
model.apply(init_bias) # 应用偏置初始化
解释:这里我们通过Pytorch的nn.init.zeros_函数,将模型的每一层的偏置初始化为0。
问题:有时偏置的初始化可能会影响模型的学习速度,特别是在某些任务中。
解决方案:偏置项默认初始化为0已经能满足大多数需求,只有在特定场景下需要根据任务需求调整偏置值。
四、执行初始化
深度学习框架(如Pytorch)为开发者提供了丰富的初始化工具,这使得初始化过程变得简单且高效。下面我们演示如何在模型定义过程中直接调用Pytorch的内置初始化方法。
import torch.nn.init as init
# 直接初始化权重
def init_weights(m):
if isinstance(m, nn.Linear):
init.kaiming_normal_(m.weight) # He初始化
model = MyModel()
model.apply(init_weights) # 为所有层执行初始化
解释:这里通过model.apply(init_weights),我们为模型的每一层都应用了He初始化。这种方式可以确保所有符合条件的层都进行初始化。
问题:当层次较多时,手动初始化容易导致遗漏或不一致。
解决方案:通过apply()方法统一初始化各个层,并记录日志,以确保每一层都按照预期初始化。
五、总结
在大模型的研发中,模型的初始化是影响模型训练效果的重要步骤。通过本文的详细介绍,我们总结了以下关键点:
-
权重初始化策略的选择:根据模型的激活函数和任务需求,选择合适的初始化策略,如He初始化、Xavier初始化等。
-
偏置初始化:大多数情况下,偏置初始化为0是最佳选择,但可根据具体任务进行调整。
-
代码实现:通过Pytorch框架,我们可以简化初始化的流程,确保模型能够快速有效地开始训练。
通过本文的代码示例与讲解,相信你能够在自己的项目中灵活应用这些技术,提升模型的表现。在下一篇文章中,我们将深入探讨如何优化大模型的训练。
在大模型时代,我们如何有效的去学习大模型?
现如今大模型岗位需求越来越大,但是相关岗位人才难求,薪资持续走高,AI运营薪资平均值约18457元,AI工程师薪资平均值约37336元,大模型算法薪资平均值约39607元。

掌握大模型技术你还能拥有更多可能性:
• 成为一名全栈大模型工程师,包括Prompt,LangChain,LoRA等技术开发、运营、产品等方向全栈工程;
• 能够拥有模型二次训练和微调能力,带领大家完成智能对话、文生图等热门应用;
• 薪资上浮10%-20%,覆盖更多高薪岗位,这是一个高需求、高待遇的热门方向和领域;
• 更优质的项目可以为未来创新创业提供基石。
可能大家都想学习AI大模型技术,也_想通过这项技能真正达到升职加薪,就业或是副业的目的,但是不知道该如何开始学习,因为网上的资料太多太杂乱了,如果不能系统的学习就相当于是白学。为了让大家少走弯路,少碰壁,这里我直接把都打包整理好,希望能够真正帮助到大家_。
一、AGI大模型系统学习路线
很多人学习大模型的时候没有方向,东学一点西学一点,像只无头苍蝇乱撞,下面是我整理好的一套完整的学习路线,希望能够帮助到你们学习AI大模型。

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF书籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。


四、AI大模型各大场景实战案例

结语
【一一AGI大模型学习 所有资源获取处(无偿领取)一一】
所有资料 ⚡️ ,朋友们如果有需要全套 《LLM大模型入门+进阶学习资源包》,扫码获取~
👉[CSDN大礼包🎁:全网最全《LLM大模型入门+进阶学习资源包》免费分享(安全链接,放心点击)]()👈
















 82
82

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}