



简介
文章探讨了AI Agent落地过程中的"减法艺术",强调通过精准筛选信息、动态匹配工具、简化执行流程,而非盲目堆砌资源。提出了三大减法原则(信息、工具、流程)和六大可落地动作,包括RAG精准检索、工具动态装载、上下文隔离与修剪等。构建了最小可行架构和渐进式落地路线,帮助开发者以低成本高效能实现Agent应用,避免上下文中毒、干扰等问题,实现长期留存与复用。
在 Agent 技术落地过程中,行业内普遍存在一种认知误区:认为更大的上下文窗口、更全的工具集、更复杂的推理流程会自然带来更优的效果。然而,一线工程实践却反复证明:过度堆砌的信息、工具与流程,往往会引发上下文中毒、干扰、混淆等一系列问题,导致 Agent 性能下滑、成本高企。

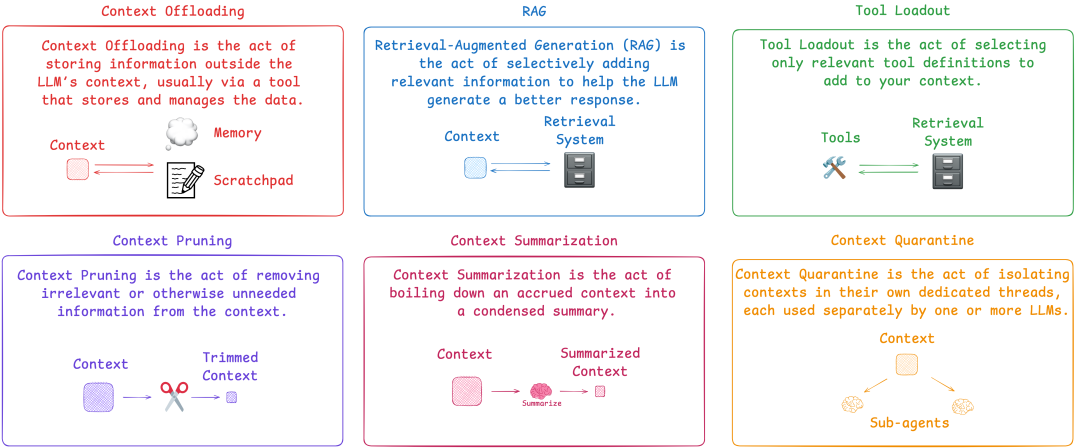
Agent 业务落地的核心逻辑并非 “加法竞赛”,而是 “减法艺术”,通过精准筛选信息、动态匹配工具、简化执行流程,保留完成当前任务 “必要且充分” 的资源,同时借助上下文工程与外部存储机制,解决 Token 冗余、信息过载等核心痛点。
本文将结合 LangChain、Cursor 等平台的实践经验,系统拆解 Agent 落地的 “减法” 原则、具体实施方案与最小可行架构。
一、Agent 落地的核心挑战:为什么必须做减法?
Agent 的本质是 “基于上下文的智能决策系统”,而上下文工程的核心矛盾在于 “可用上下文” 与 “必要上下文” 的不匹配。具体来看,四大核心挑战推动 Agent 必须通过 “减法” 优化:

1. Token 资源浪费:检索上下文远超实际需求
多次网页搜索、长文本交互等场景会让会话历史快速膨胀至数万 Token,不仅导致 API 调用成本飙升,还会显著降低模型响应速度。例如,将 10k Token 的网页搜索结果全程保留在上下文窗口中,其中 90% 的信息可能与当前任务无关。
2. 上下文窗口超限:必要信息超出模型承载能力
长期任务的计划文档、多轮交互的历史记忆、复杂工具的详细定义等,往往会超出模型的上下文窗口限制,导致关键信息无法被模型捕捉。
3. 信息定位困难:小众信息淹没于海量数据
当目标信息分散在数百份文件或数千轮对话中时,传统检索方式难以精准定位,导致 Agent “找不到所需信息”。
4. 动态学习缺失:交互关键信息无法复用
用户偏好、任务执行经验等动态信息若仅存储在会话上下文内,无法跨会话复用,且易被新信息覆盖,导致 Agent 难以实现长期学习。
此外,过度 “加法” 还会引发四大失效模式:
- 上下文中毒:早期的幻觉或错误被反复引用并固化,影响后续决策;
- 上下文干扰:模型过度依赖历史信息,忽略训练知识,策略更新滞后;
- 上下文混淆:过多工具或资料会诱导模型 “强行使用”,导致任务跑偏;
- 上下文冲突:多来源信息自相矛盾,拉低整体性能。
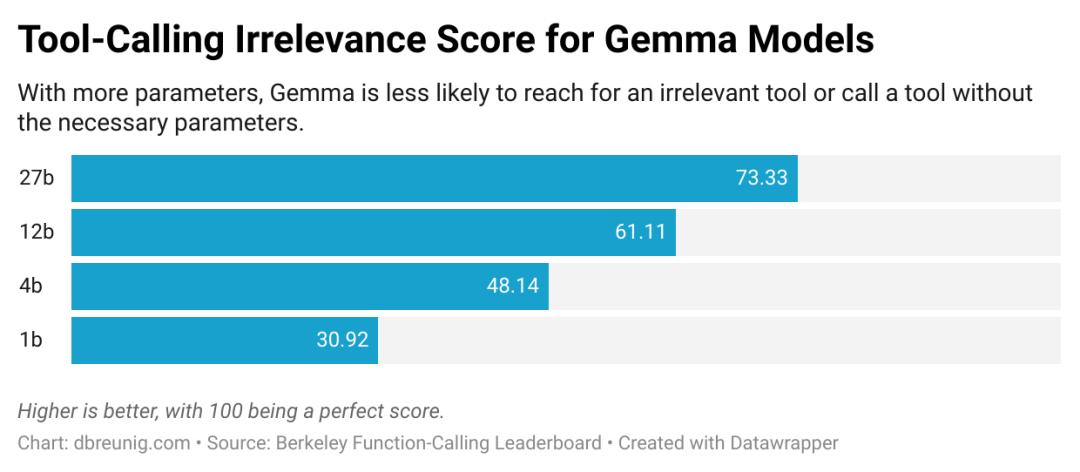
伯克利功能调用排行榜数据显示,工具数量与模型误用率呈正相关:当工具数量超过 30 个时,即使是参数规模较大的模型,也容易出现无关工具调用或参数缺失问题。
二、三大 “减法” 原则:信息、工具与流程的精准取舍
Agent 落地的 “减法” 并非盲目删减,而是基于任务目标的 “必要且充分” 原则,从信息、工具、流程三个核心维度优化:
1. 信息做减法:只留核心,冗余外置
核心逻辑:让 “检索到的上下文” 无限贴近 “真正需要的上下文”,并通过修剪、摘要、卸载等方式控制规模。
- 精准筛选:仅提取与当前任务强相关的信息片段,避免无关内容进入上下文窗口;
- 定期优化:通过修剪移除过期、重复信息,通过摘要压缩长文本,降低 Token 消耗;
- 外部存储:将中间结果、长文本、历史记忆等写入外部存储,主上下文仅保留引用与关键摘要。
2. 工具做减法:动态匹配,避免冗余
核心逻辑:工具的价值在于 “精准适配任务”,而非数量堆砌,过多工具会增加模型决策负担。
- 动态装载:基于任务类型语义检索相关工具,避免一次性加载所有工具;
- 数量控制:单次绑定工具数≤10 个,既保证功能覆盖,又避免描述重叠与误用;
- 聚焦核心:优先保留高频、高价值工具,移除边缘性功能工具。
3. 流程做减法:能简不繁,隔离解耦
核心逻辑:复杂流程未必带来更好效果,单体架构足够稳定时无需强行拆分,多体架构需聚焦并行优势。
- 架构选择:能单体不多体,单体架构稳定性更高、维护成本更低;
- 并行隔离:可拆分的子任务采用多智能体并行模式,每个子体配备独立上下文线程;
- 简化链路:长流程需将中间态卸载至外部存储,避免上下文持续膨胀。
三、六大可落地 “减法” 动作:从理论到工程实践
结合 LangChain 等平台的实践经验,以下六大 “减法” 动作可直接落地应用,覆盖信息处理、工具管理、流程优化全链路:
1. RAG 精准检索:信息选择的 “精准过滤器”
- 核心动作:先界定检索范围(例如:特定文件目录、时间区间),再从向量库中提取 3~5 个相关片段,避免 “全量投喂”。
- 控量策略:严格限制 chunk 长度与重叠度,复杂查询可接受 20k~25k Token 的一次性检索成本,但回答阶段仅保留 “被证实相关” 的片段;必要时通过 rerank 模型二次筛选,提升检索精准度。
- 落地价值:减少无关信息进入上下文,降低 Token 消耗与模型干扰。
2. 工具装载(Tool Loadout):工具管理的 “动态匹配器”
- 核心动作:基于任务需求动态挑选工具,而非固定加载全量工具集。
- 实现方式:用向量库索引 “工具描述”,先由小模型快速判断 “所需能力”,再通过语义检索筛选 Top-5~10 个工具绑定给 Agent。
- 经验阈值:单次装载工具数≤8 个时稳定性最佳,≥30 个工具易出现误用问题。
3. 上下文隔离(Context Quarantine):流程解耦的 “独立线程”
- 核心动作:将可并行的子任务分配至独立上下文线程,由 Supervisor 智能体汇总最终结果。
- 核心优势:实现关注点分离,降低子任务间的路径依赖,多智能体并行可显著提升处理效率;
- 适用场景:数据统计、多源信息汇总等可拆分的并行任务,非并行任务建议保留单体架构。
4. 上下文修剪(Context Pruning):信息减重的 “冗余清理器”
- 核心动作:定期从上下文窗口中移除无关、过期、重复的信息片段,保护核心指令与任务目标。
- 工具选择:采用轻量 rerank 模型(例如:小参数 LLM 或专用 rerank 模型)先过滤 80% 冗余信息,再交给主模型处理;
- 量化目标:RAG 阶段 25k Token 可修剪至 11k 左右,实现 Token 减半而答案质量不下降。
5. 上下文摘要(Context Summarization):信息压缩的 “高效转换器”
- 核心动作:对 “均相关但过长” 的文本,通过便宜模型进行结构化摘要,保留要点、数据与结论,去除冗余描述。
- 实施策略:先修剪再摘要,避免对冗余信息做无效处理;摘要目标为压缩 50%~70%,平衡信息密度与可读性;
- 工程化:将摘要模块设计为独立节点,支持离线评估与持续调优,不影响主流程性能。
6. 上下文卸载(Context Offloading):信息外置的 “扩展存储”
- 核心动作:将长链路工具输出、推理草稿、会话记忆等写入文件系统或外部存储,主对话仅保留短提示与必要引用。
- 两种形态:
- Scratchpad(草稿本):存储临时推理过程与中间态,不进入主上下文;
- Persistent Store(持久化存储):保存跨会话的知识库与用户偏好,支持长期复用;
- 关键优势:以 “单一接口” 实现无限量上下文存储,查询时仅将命中的小片段回填至对话,避免上下文泛滥。
四、最小可行架构(MVP):轻量化落地的核心流水线
将 “减法” 策略固化为轻量流水线,无需复杂部署即可快速落地,核心流程如下:

-
请求解析
接收用户请求后,解析任务类型、所需能力与信息范围,明确核心目标;
-
工具装载
基于解析结果语义检索,绑定≤8 个相关工具,避免功能冗余;
-
精准检索
采用 “先精确后语义” 的混合检索模式,通过 grep / 结构化索引精确定位,再通过 embedding+rerank 扩展相关片段;
-
修剪过滤
基于原始问题针对性过滤,丢弃明显无关、重复的信息片段;
-
摘要压缩
(按需启用):对仍过长的相关文本,通过便宜模型压缩 50%~70%,生成结构化摘要;
-
生成回答
主模型基于修剪后的信息与绑定工具,严格引用检索 / 摘要材料生成回答;
-
卸载存储
(按需启用):将中间结果、长文本、可复用知识写入文件系统,保存最小 “引用指纹” 供后续复用。
注:上述流程无需全量执行,默认启用 1~3、6 步骤,任务复杂度提升时再按需打开 4、5、7 步骤,平衡性能与效果。
五、文件系统:上下文 “减法” 的核心支撑
文件系统是 Agent “减法” 落地的关键支撑,通过 “外部化存储” 解决上下文膨胀问题,其核心价值体现在四大场景:
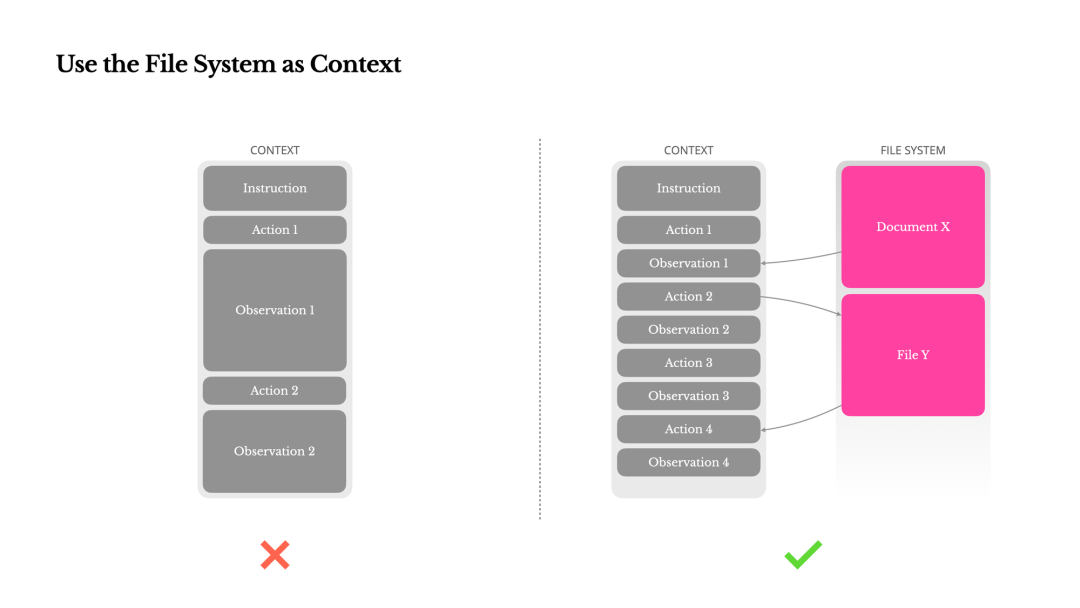
1. 解决 Token 过多问题
将工具调用结果、网页搜索等长文本写入文件系统,仅在需要时通过 grep 检索关键词,读取必要片段,避免冗余 Token 占用上下文窗口。
2. 突破上下文窗口限制
- 存储长期任务计划:将复杂任务的执行计划写入文件,后续随取随用,无需全程占用上下文;
- 存储子智能体知识:子智能体执行结果写入文件,避免 “电话游戏” 式信息失真;
- 存储指令文件:将大量操作指令放入文件,避免系统提示臃肿。
3. 精准定位小众信息
借助 ls/glob/grep 等命令实现结构化定位与全文检索,精确命中分散在海量文件中的小众信息,解决 “检索结果≠必要上下文” 问题。
4. 支持长期动态学习
将用户偏好、任务执行经验、技能指令等存入文件系统,跨会话复用;用户反馈后可即时更新文件内容,实现 Agent 渐进式学习。
六、渐进式落地路线:从 “能用” 到 “好用”
Agent “减法” 落地无需一步到位,可按以下四阶段逐步推进,平衡效果与成本:
Stage 0(基线):单体架构 + 基础功能
- 核心配置:单体 Agent+≤10 个手选工具;
- 信息处理:直接 RAG 检索(k=3~5),不做摘要与修剪;
- 目标:实现核心功能可用,建立性能基线。
Stage 1(做减法):动态工具 + 冗余过滤
- 核心优化:加入工具装载模块,动态匹配工具;引入上下文修剪,剔除明显无关信息;
- 预期效果:Token 消耗与时延显著下降,Agent 稳定性提升。
Stage 2(降本增效):摘要压缩 + 外部卸载
- 核心优化:长文本引入摘要节点(小模型压缩 50%~70%);启用文件系统卸载,工具长输出与草稿本不进入主上下文;
- 预期效果:Token 成本进一步降低,支持更长链路任务。
Stage 3(并行加速):多体架构 + 并行处理(可选)
- 核心优化:可并行子任务采用上下文隔离的多智能体架构,Supervisor 汇总结果;
- 适用场景:任务复杂度高、可拆分的场景,非必要不启用。
七、量化指标与反模式规避
1. 核心量化指标(落地必看)
- Token 成本:按会话维度统计,设置 8k(软阈值)/16k(硬阈值),避免超支;
- 工具装载规模:单次绑定工具数≤10,超过则报警并分析工具必要性;
- 检索有效率:最终被引用的检索片段占比≥50%,低于该值需优化检索策略;
- 用户反馈指标:代码留存率(编码场景)提升、不满意请求率下降;
- 回答一致性:跨多轮对话无自我矛盾与目标漂移。
2. 常见反模式(看到即改)
- 窗口大 = 一次性全塞:盲目将所有信息填入大上下文窗口,易引发中毒、干扰问题;
- 工具越多越聪明:追求工具全覆盖,忽视模型决策负担;
- 链越长越强大:过度拆分流程,未将中间态卸载,导致上下文持续膨胀;
- 全部在线推:摘要、修剪、重排等操作均在线执行,拉高整体延迟。
八、结语
Agent 业务落地的核心逻辑,是通过 “减法” 实现 “Less, but better”,剥离冗余信息、精简工具数量、简化执行流程,让 Agent 聚焦核心任务目标。文件系统作为上下文 “外部化” 的关键载体,与六大 “减法” 动作结合,可构建稳定、高效、低成本的 Agent 架构。
落地过程中,无需追求 “大而全” 的复杂方案,而是从最小可行架构起步,基于量化指标逐步优化。先做减法,再谈进化,才能让 Agent 在真实业务场景中实现长期留存与复用。
九、如何学习AI大模型?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
想正式转到一些新兴的 AI 行业,不仅需要系统的学习AI大模型。同时也要跟已有的技能结合,辅助编程提效,或上手实操应用,增加自己的职场竞争力。
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高
那么针对所有自学遇到困难的同学们,我帮大家系统梳理大模型学习脉络,将这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

学习路线

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


















 942
942

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









