






1. 前言
BERT(Bidirectional Encoder Representations from Transformers)是一种预训练的自然语言处理(NLP)模型,由 Google 于2018年提出论文*《BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding》*。BERT 采用 Transformer 架构,具体来说,是通过多层的 Transformer 编码器来实现。与以前的 NLP 模型不同,BERT 的关键创新在于使用双向(bidirectional)上下文来预训练模型,使其能够更好地理解和捕捉句子中的语境信息。
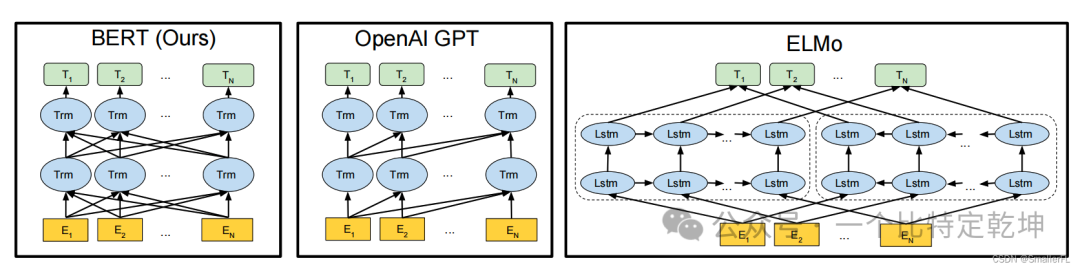
模型架构的差异对比。BERT 使用了一个双向 Transformer。OpenAI GPT使用一个从左到右的 Transformer。ELMo 使用从左到右、从右到左的 LSTMs, 用于为下游任务生成特性。在这三种方法中,只有 BERT 表示在所有层中都共同基于左右+上下文。BERT 的出现极大地推动了自然语言处理领域的发展,成为了许多 NLP 任务中的基准模型。它的成功也激发了更多基于 Transformer 架构的模型的研发,如 GPT(Generative Pre-trained Transformer)等。
😝朋友们如果有需要的话,可以V扫描下方二维码联系领取~

2. BERT 关键流程
BERT采用了 Transformer,这是一种基于自注意力机制(Self-Attention Mechanism)的架构。Transformer允许模型在处理输入序列时同时考虑到所有位置的上下文信息。
2.1 整体流程
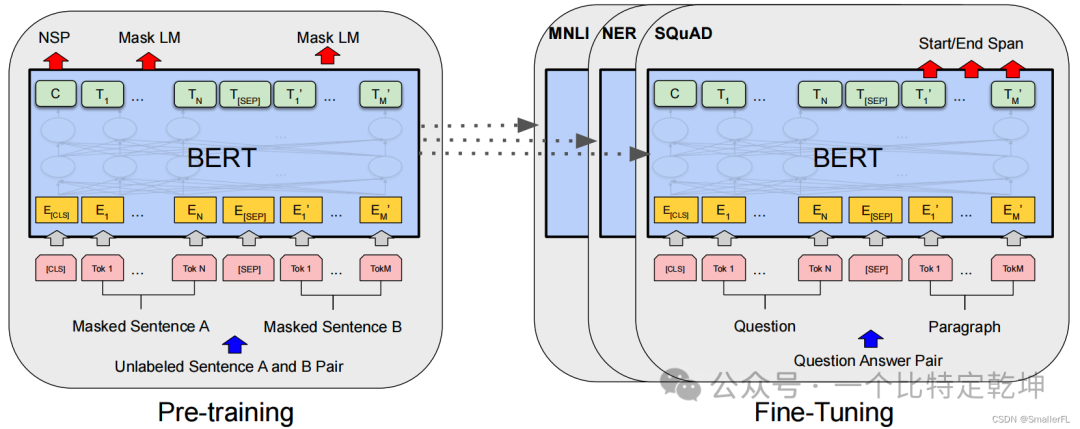
BERT 的整体流程 Pre-training 和 Fine-tuning。除了输出层之外,在 Pre-training 和 Fine-tuning 中都使用了相同的架构。
注意图中的输入 Input,
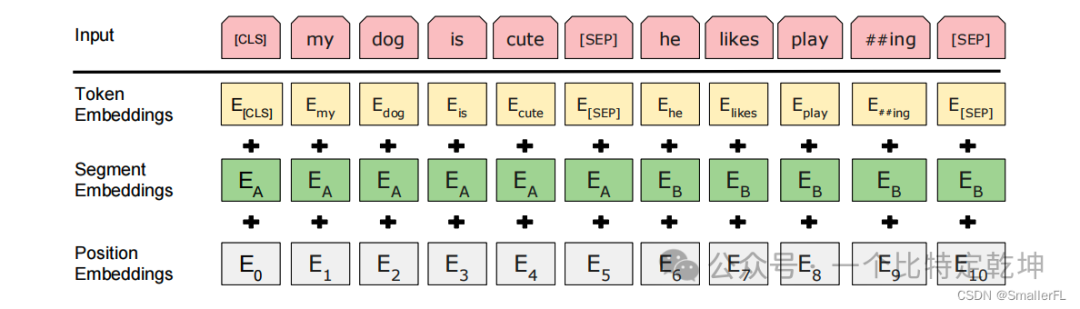
其中:
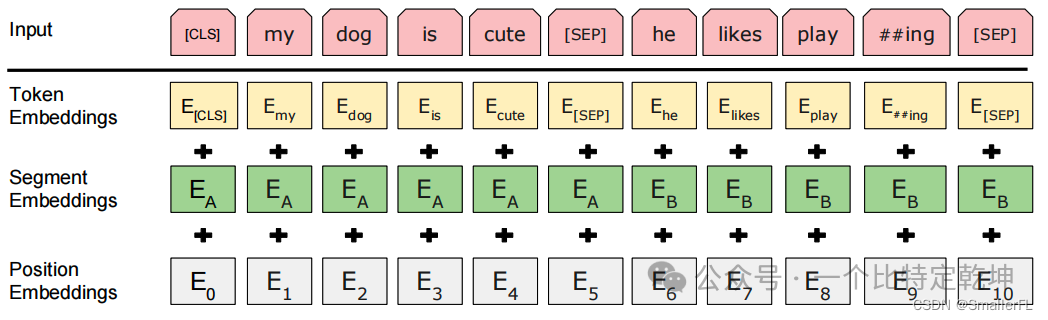
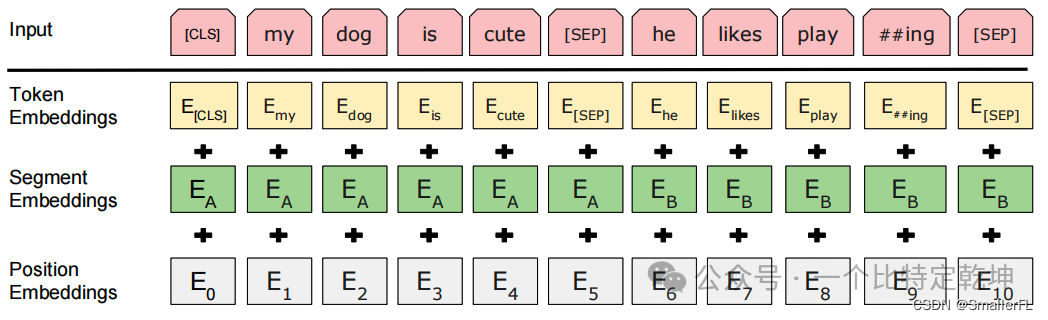
- TokenEmbeddings 是单词的字嵌入表示
- SegmentEmbeddings 是两个句子的区分标识,例如 “[CLS] My name is xx [SEP] How are you [SEP]” 那么对应的 SegmentEmbeddings 就是 0000001111,粗体0后1表示对应的单词
- PositionEmbeddings 是单词所在句子的位置
2.2 Pre-training(预训练)
在预训练阶段,BERT 是通过两个主要任务来学习词汇表示和上下文信息:Masked Language Model(MLM)和 Next Sentence Prediction(NSP)。
2.2.1 Masked Language Model (MLM)
在 MLM 任务中,BERT 通过随机遮蔽输入文本中的一些 token,然后让模型预测这些被遮蔽的 token。这个任务使得模型能够双向(从左到右和从右到左)观察上下文信息,从而更好地捕捉到 token 之间的关系。具体的步骤如下:
-
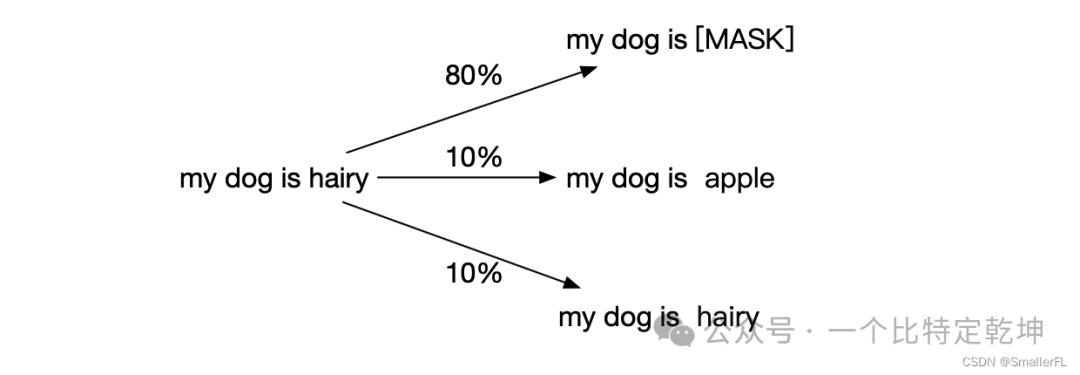
输入处理: 对于输入文本中的每个句子,随机选择15%的 token 进行遮蔽。然后,80%的被遮蔽的 token 被替换成一个特殊的 [MASK] 标记,10%的 token 被替换成其他随机的 token,而剩下的10%则保持原样。这样处理后,输入文本就变成了包含 [MASK] 标记的被遮蔽文本。例如:
-
MLM目标: 模型的目标是根据上下文预测被遮蔽的 token。在训练期间,模型通过比较模型输出和实际被遮蔽的 token 来计算损失,通过反向传播和优化算法来更新模型参数。
2.2.2 Next Sentence Prediction (NSP)
NSP 任务旨在让 BERT 模型理解句子之间的语义关系,以便在后续微调阶段对更复杂的语言任务有更好的泛化能力。
-
输入处理: 对于输入的一对句子,有50%的概率是真实的句子对(IsNext),另外50%是随机抽取的不相关的句子(NotNext)。然后,这一对句子被输入 BERT 模型。例如:

-
NSP 目标: 模型的目标是预测这一对句子是否在语义上是相邻的(IsNext)还是不相关的(NotNext)。在训练期间,通过比较模型输出和实际标签来计算损失。
通过这 MLM 以及 NSP 两个任务的预训练,BERT 模型能够学到通用的语言表示,同时捕捉双向上下文信息,使得模型在微调到特定任务时具有更强的泛化能力。这种预训练方法帮助 BERT 成为在各种自然语言处理任务上取得优异表现的基础模型。
2.3 Fine-tuning(微调)
预训练完成后,BERT 模型可以通过微调用于特定的下游任务,如文本分类、命名实体识别等。在微调过程中,可以保持部分预训练的参数不变,也可以调整一些参数以适应特定任务。以下是BERT微调的一般过程:
- 准备数据: 收集与目标任务相关的标注数据。这些数据需要包括输入文本和相应的标签,如情感分类标签、实体识别标签等。
- 数据处理: 将任务相关数据进行适当的预处理,包括 tokenization、添加特殊标记(如[CLS]和[SEP])等,以使其符合 BERT 的输入格式。
- 模型输入: 将微调数据输入 BERT 模型。通常,输入是一个句子或一对句子,具体取决于任务。对于分类任务,可能只需一个句子;而对于问答或文本匹配任务,则需要一对句子。
- Loss计算: 根据任务类型选择适当的损失函数。对于分类任务,通常使用交叉熵损失;对于回归任务,可以使用均方误差等。Loss 计算的目标是使 BERT 模型的输出尽可能接近实际标签。
- 反向传播和优化: 计算损失后,通过反向传播算法更新 BERT 模型的参数,以减小损失。通常采用梯度下降或其变种进行优化。
- 训练过程: 在任务相关数据上进行多轮迭代的训练,确保模型能够充分学习任务特定的模式和特征。可以选择冻结一些层的参数,只微调部分参数,以减少训练时间和资源的需求。
- 性能评估: 使用验证集评估模型的性能。可以根据任务需求选择不同的评价指标,如准确率、精确度、召回率、F1分数等。
- 调整和优化: 根据性能评估的结果进行调整和优化,可能包括调整学习率、选择不同的模型配置,或进一步微调。
- 测试集评估: 使用独立的测试集评估最终模型的性能。确保模型在未见过的数据上表现良好。
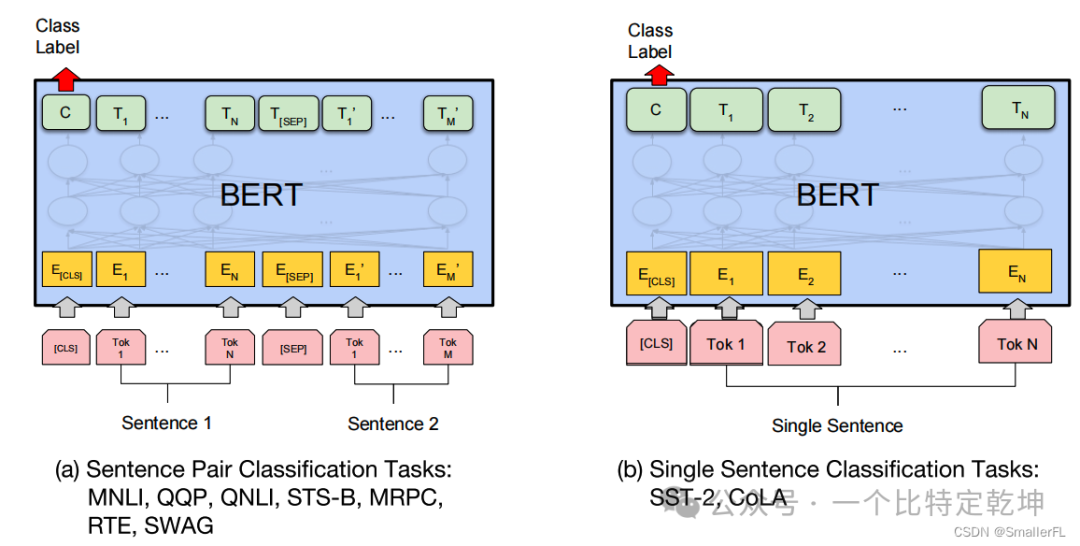
下图是论文里展示的 BERT 微调后适合的任务:
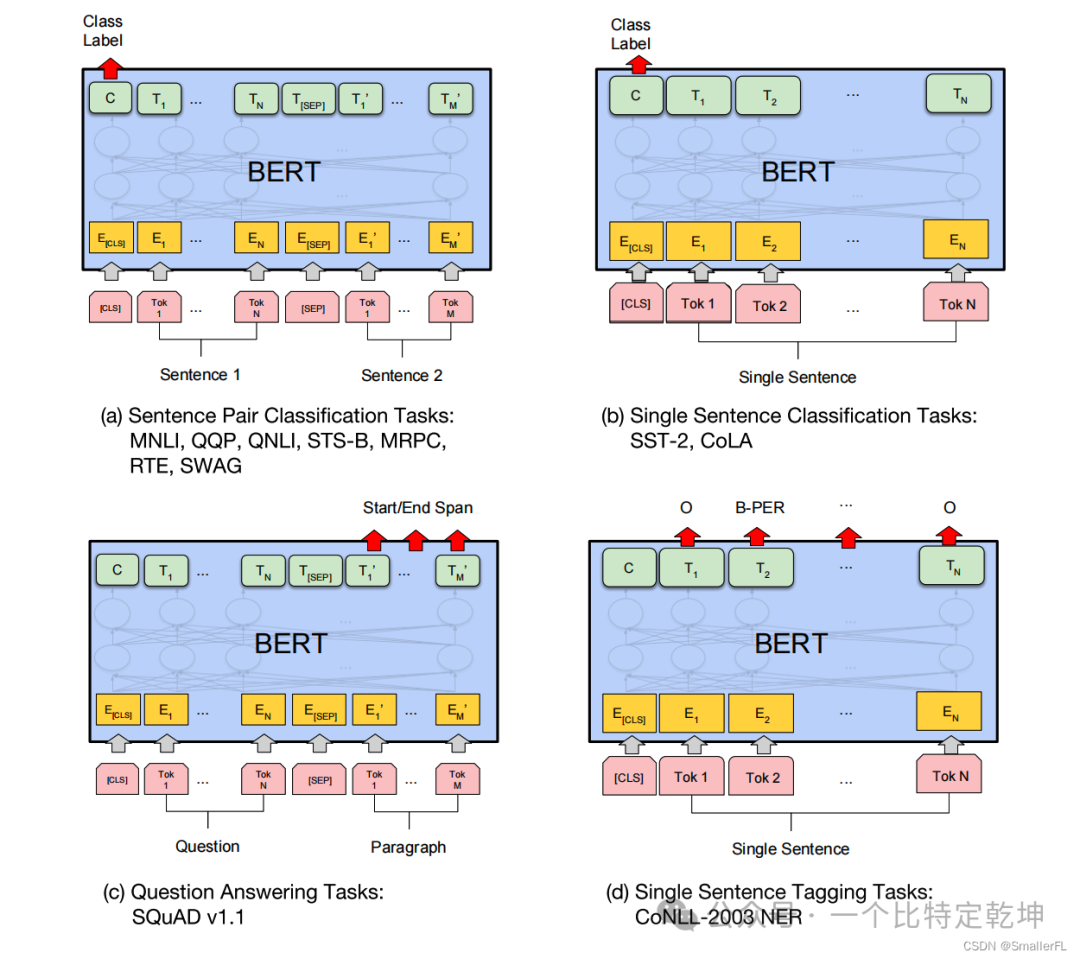
- (a)表示成对句子的分类任务,输出采用 [CLS] 的输出,因为 [CLS] 已经包含上下文信息
- (b)表示单个句子的分类任务,同样输出采用 [CLS] 的输出
- (c)表示问答任务,输出采用问题的回答
- (d)表示词标注任务,输出就是每个单词的标注结果
2.4 总结
(1)什么是 BERT。BERT 是一种基于 Transformer 模型的深度双向语言表征模型。模型的输入是文本的token序列,输出是每个 token 的隐含表征。这些隐含表征包含了文本的上下文信息,可以用于各种自然语言处理任务。BERT 模型的发布推动了 NLP 领域的发展,并成为后续许多 NLP 模型的基础。例如,RoBERTa、DistilBERT、XLNet 等模型都是基 于BERT 模型改进的。
(2)预训练。 BERT 模型的预训练采用了一种无监督学习方法。模型的输入是大量未标记文本,目标是预测下一个 token 的出现概率。通过这种预训练,模型可以学习到文本的上下文信息,并获得良好的语言表征能力。
(3)应用
- 文本分类
- 语义相似度
- 机器阅读理解
- 问答
- 文本摘要
- 机器翻译
(4)优缺点优点
优点:
- 可以学习到文本的上下文信息
- 具有良好的语言表征能力
- 可以用于各种自然语言处理任务
缺点:
- 模型参数量大,训练和推理成本高,训练慢
- 对小数据集的性能不佳
3. 源码准备
官方 bert github 源代码(https://github.com/google-research/bert) 采用的 tensorflow v1 版本,我本地调试采用的是 v2 版本,已上传到我的 bert github (https://github.com/SamllerFL/bert) ,有需要的自取。bert 的 tensorflow 代码 v1 和 v2 中间有一些兼容性的替换,如下:
import tensorflow as tf -> import tensorflow.compat.v1 as tf如果上面的import不变,也可以把代码的 tf -> tensorflow.compat.v1tf.contrib -> tf.compat.v1.estimatortf.gfile.GFile -> tf.io.gfile.GFiletf.variable_scope -> tf.compat.v1.variable_scope
此外,为了跑通 bert 代码,增加了输入输出以及字典文件:

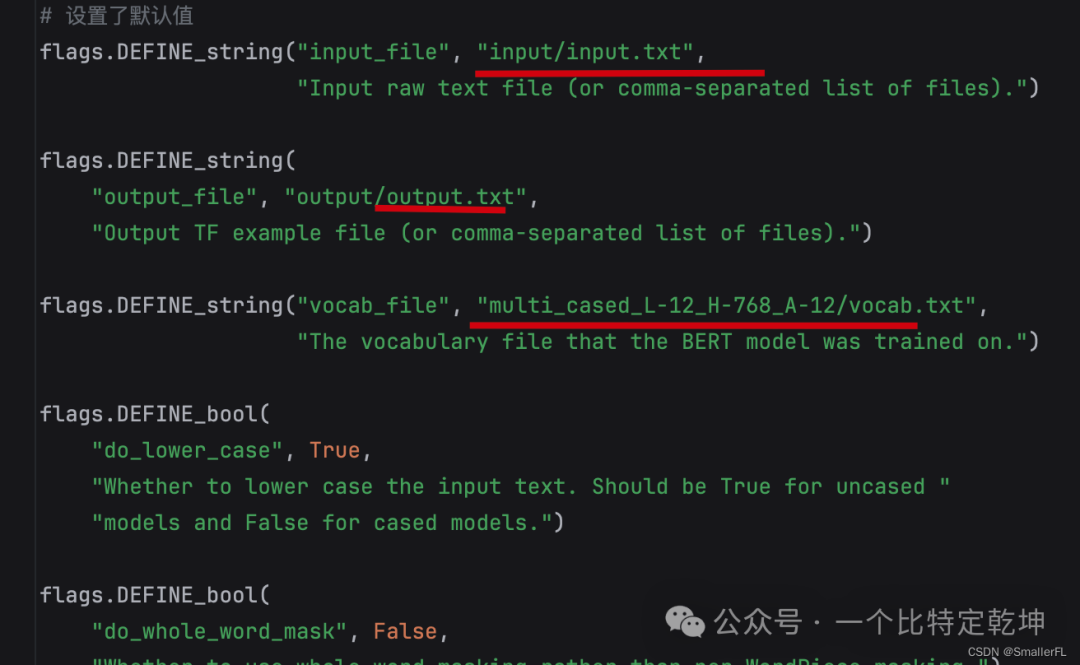
以及增加了 Flag 默认值,例如:
如果不想自己去调整 tensorflow v1 和 v2 版本的差异,建议 fork 或 clone 本人的 bert github 项目,其中已经准备了输入数据,方便调试源代码。
4. 先从数据准备看起
下面主要介绍 BERT 源码预训练的数据准备代码!理清楚几个关键变量的含义:input_ids、input_mask、segment_ids、masked_lm_positions、masked_lm_ids、masked_lm_weights、next_sentence_labels
bert 代码中存在一个 python 文件:create_pretraining_data.py,这个文件是用于给预训练准备数据用的。好,现在跟着我一起去 debug 代码,推荐用 Pycharm(习惯用 vscode 也可以),沉浸式 debug 代码是理解原理的最好方法!打上断点,然后开启 debug。
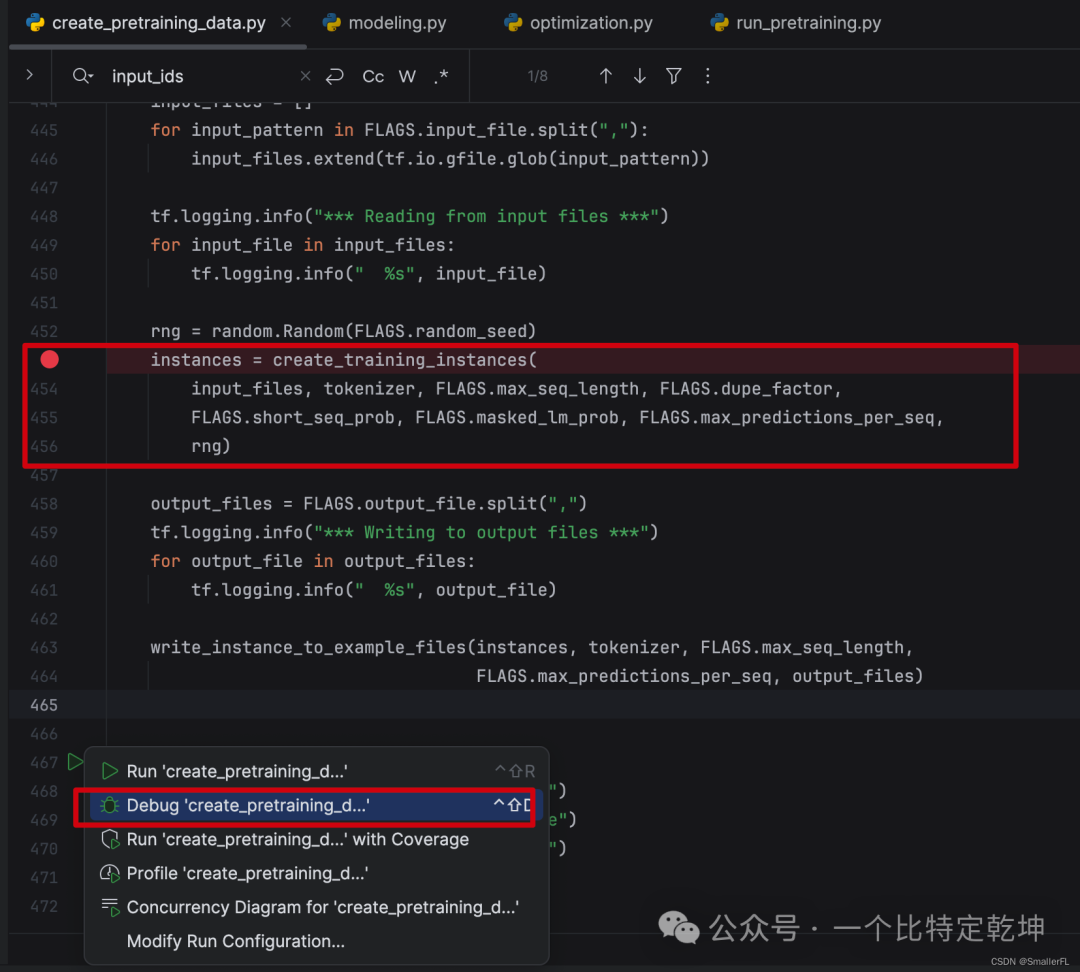
4.1 create_training_instances
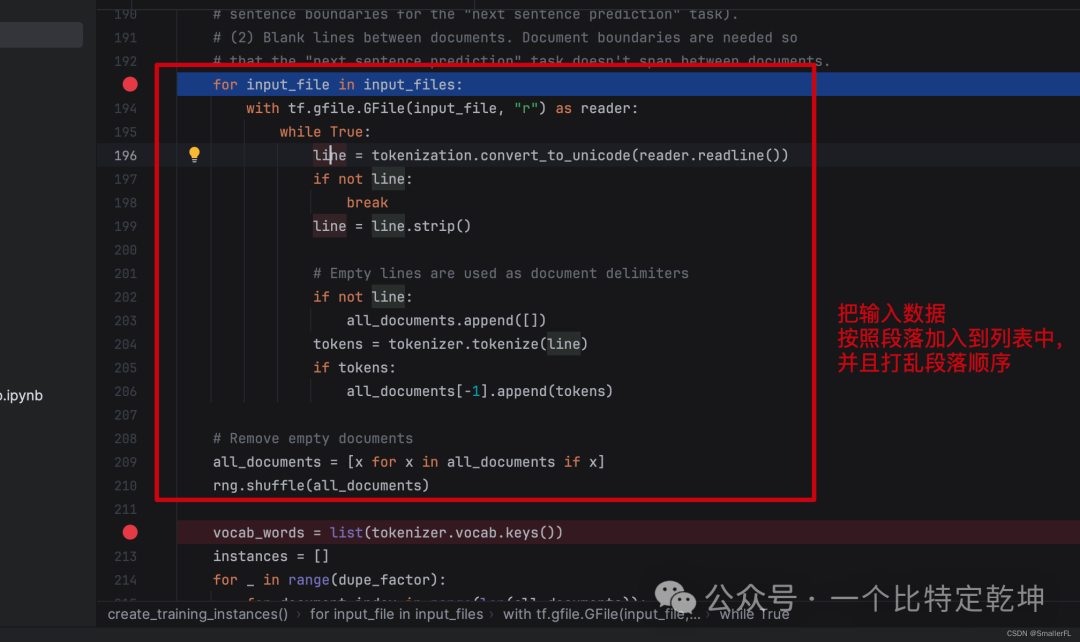
进入到第一个方法 create_training_instances。可以看到,input_files 是我准备好的输入语料,
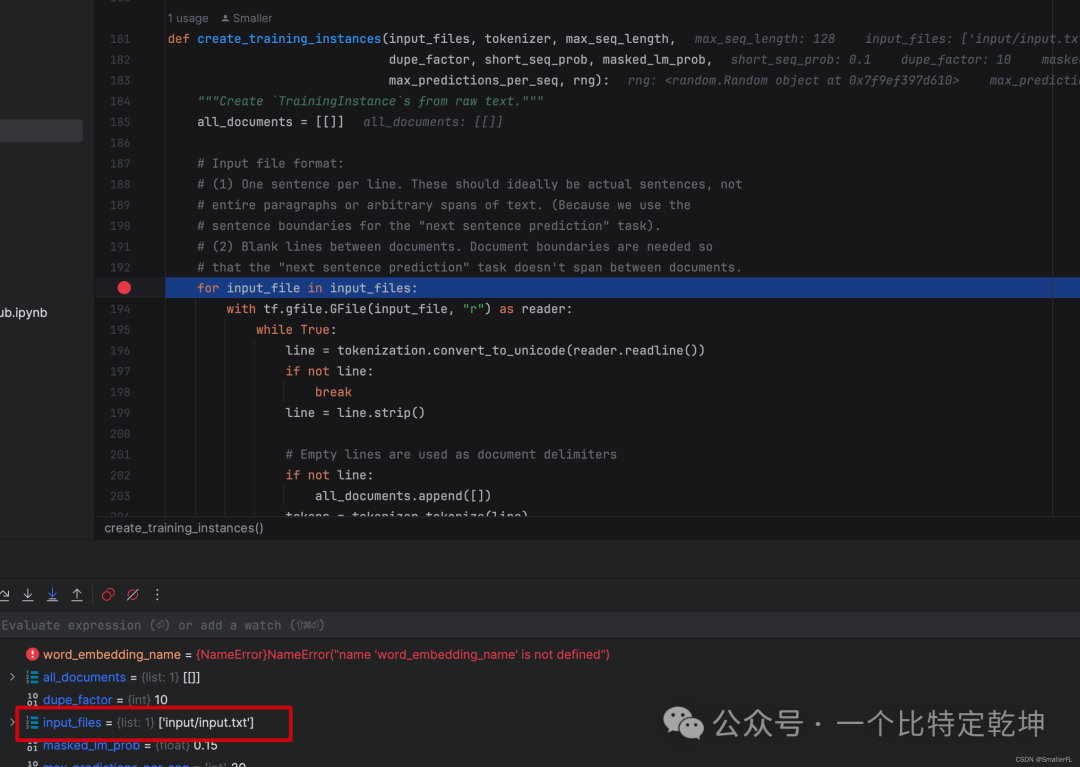
输入的语料在哪呢?我放在了input/input.txt:

那么这段代码很明显,就是把输入数据按照段落加入到 all_documents 列表里,并且打乱段落列表。
什么是段落(document)?看下面的例子:
BERT is undoubtedly a breakthrough in the use of Machine Learning for Natural Language Processing.
Training the language model in BERT is done by predicting 15% of the tokens in the input, that were randomly picked.
If we used [MASK] 100% of the time the model wouldn’t necessarily produce good token representations for non-masked words.
If we used [MASK] 90% of the time and random words 10% of the time.
If we used [MASK] 90% of the time and kept the same word 10% of the time, then the model could just trivially copy the non-contextual embedding.
这里一共有3个段落,因为英文的段落之间是用空行划分开的。
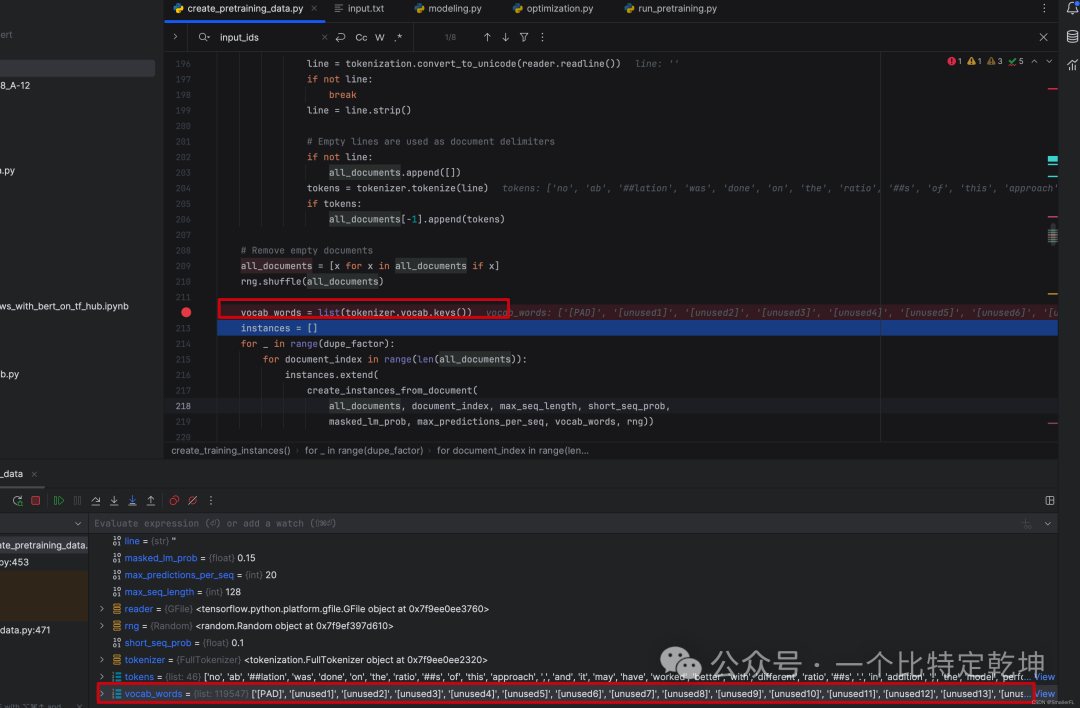
4.2 vocab_words = list(tokenizer.vocab.keys())
顺着代码接下来看 vocab_words = list(tokenizer.vocab.keys()) 方法,这里是把字典的单词导出成 list
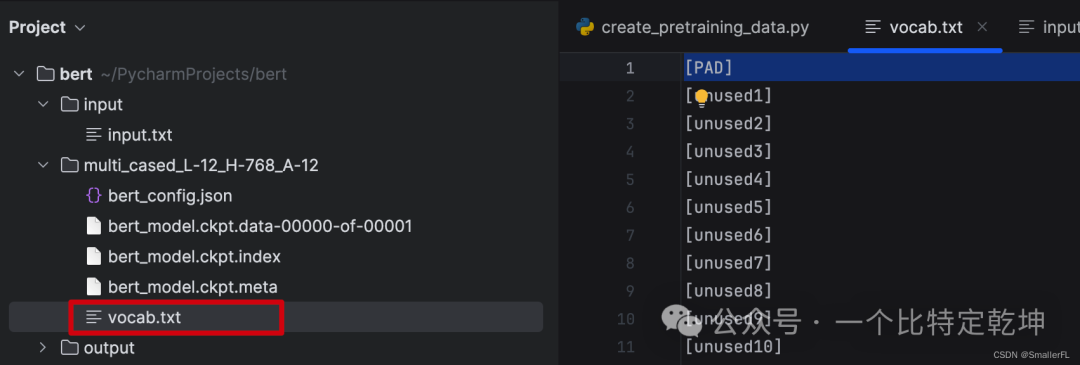
字典从哪来呢?实际源码是没有的,这里是我从官方下载后加入的,放在了 multi_cased_L-12_H-768_A-12/vocab.txt:
4.3 create_instances_from_document
那么顺着代码看,后续最关键的方法就是 create_instances_from_document 了。
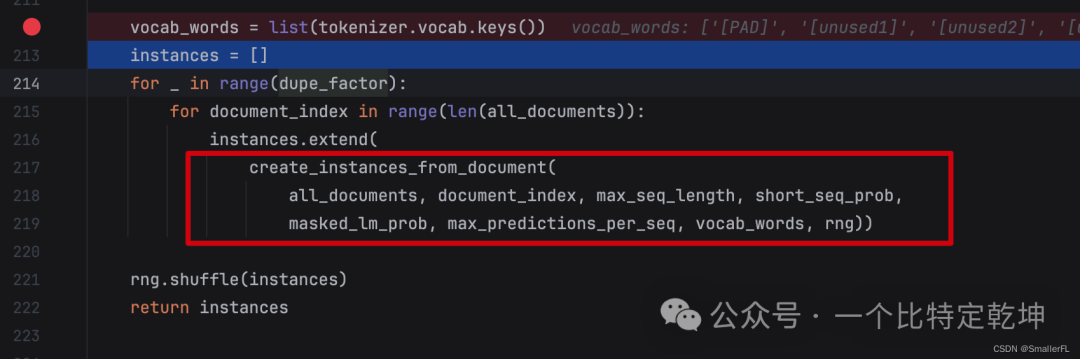
我们进到 create_instances_from_document 函数:
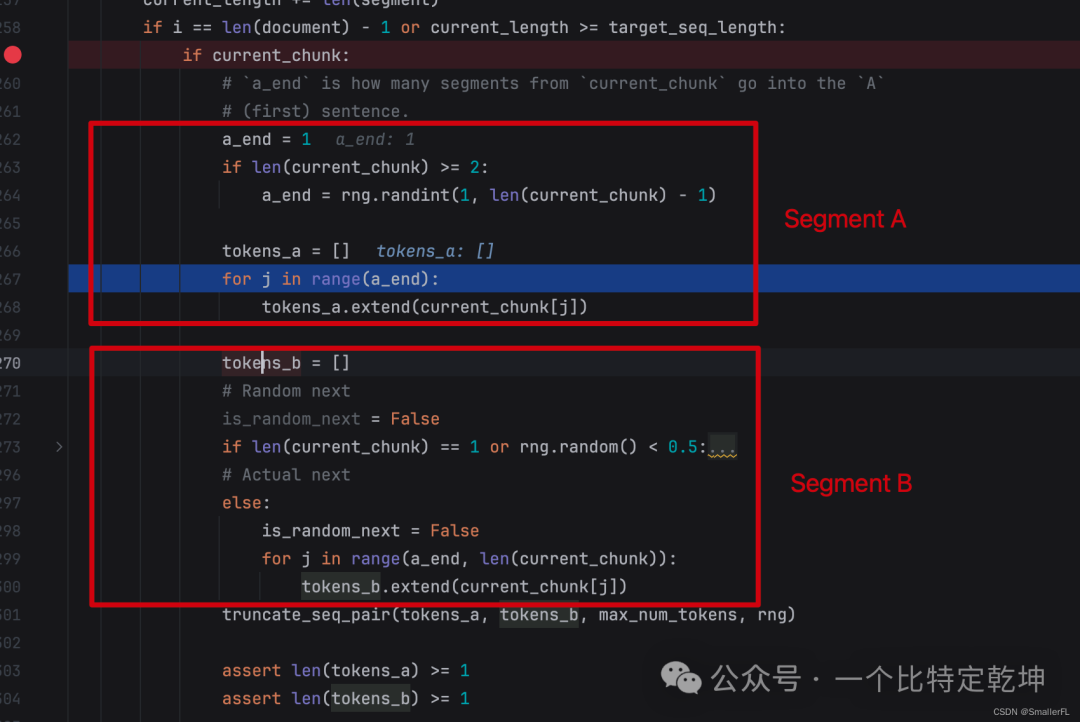
为了理解上述代码的含义,我们先看论文里的 Input 的组成,其中包含有一个 Segment Embedding:
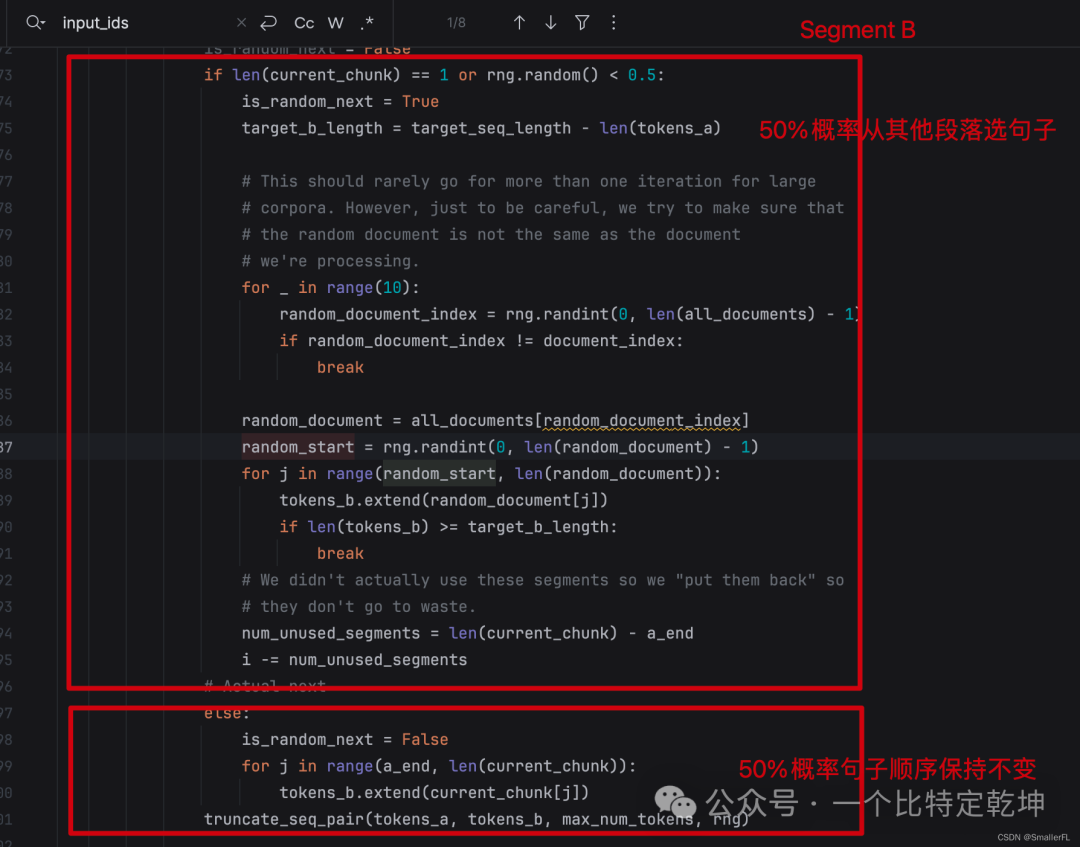
Segment Embedding 的组成是 和 (Segment A 和 Segment B)。其中 50% 概率保持顺序不变,即仍然是 A 句子之后的句子 B;50% 概率从其他段落随机抽取一个句子,拼接到 A 句子后。
这个就是论文的 Next Sentence Prediction (NSP)所描述的任务,具体细节可以查看前两章内容。
好了, NSP 的数据准备对应的代码如下:
我们接着往下看,代码里出现了 "[CLS]"、"[SEP]" 这个标识,以及 segment_ids.append(0),segment_ids.append(1) 方法
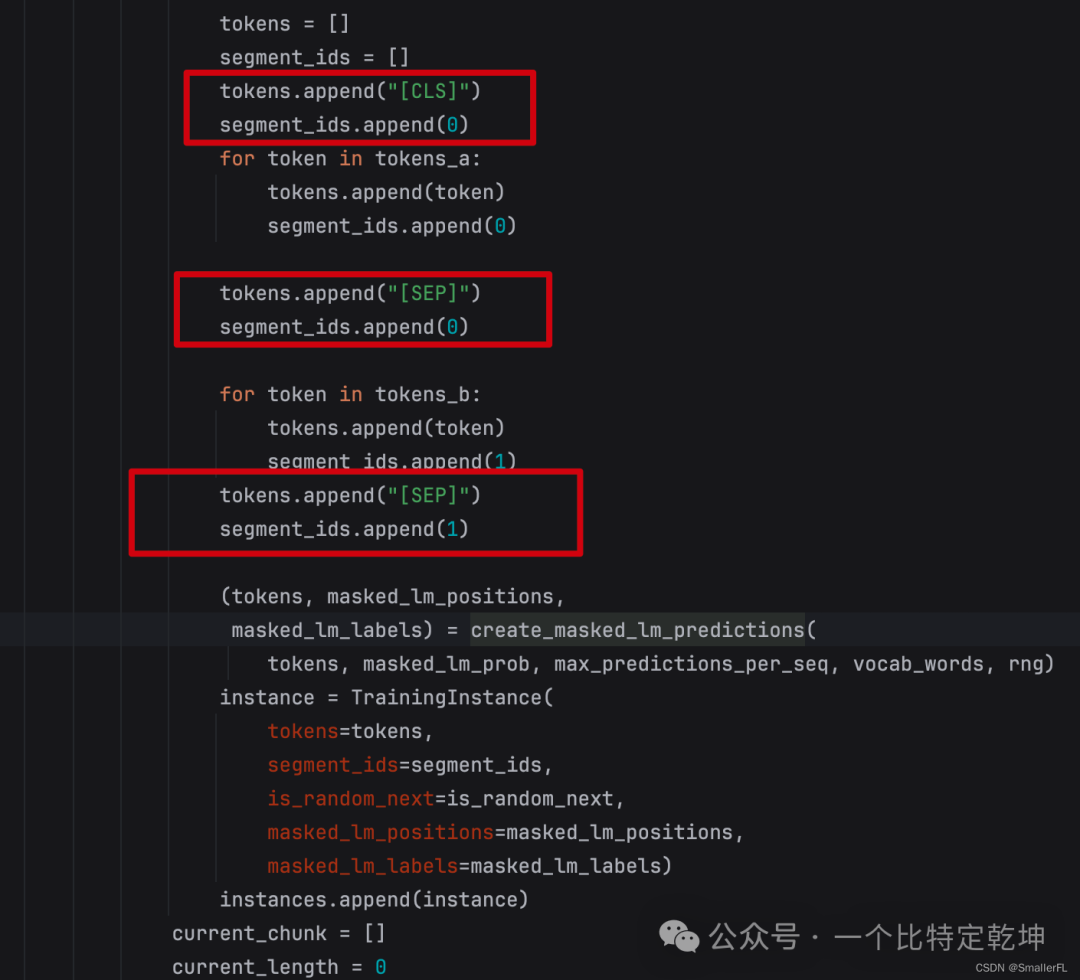
上面的代码已经相当明显了。
为了方便理解,我们假如:
句子 A 由以下 token 组成:[token_a1, token_a2]
句子 B 由以下 token 组成:[token_b1, token_b2]
那么,代码里最终的 tokens 会组装成这样:[[CLS],token_a1,token_a2,[SEP],token_b1,token_b2,[SEP]]。
而代码中的 segment_ids,会得到如下结果:[0,0,0,0,1,1,1]而 segment_ids 就是 Segment Embedding 的组成:EA+EB
4.4 create_masked_lm_predictions
到目前为止,我们组装了 NSP 所需要的数据。顺着往下看,最重要的函数就是 create_masked_lm_predictions ,而这个函数就是 BERT 所谓的 MASK 的关键数据准备步骤!
首先看这里的代码,还记得论文里说在所有的 tokens 里选择15%的比例用来 MASK 吗,就是这行代码的描述:
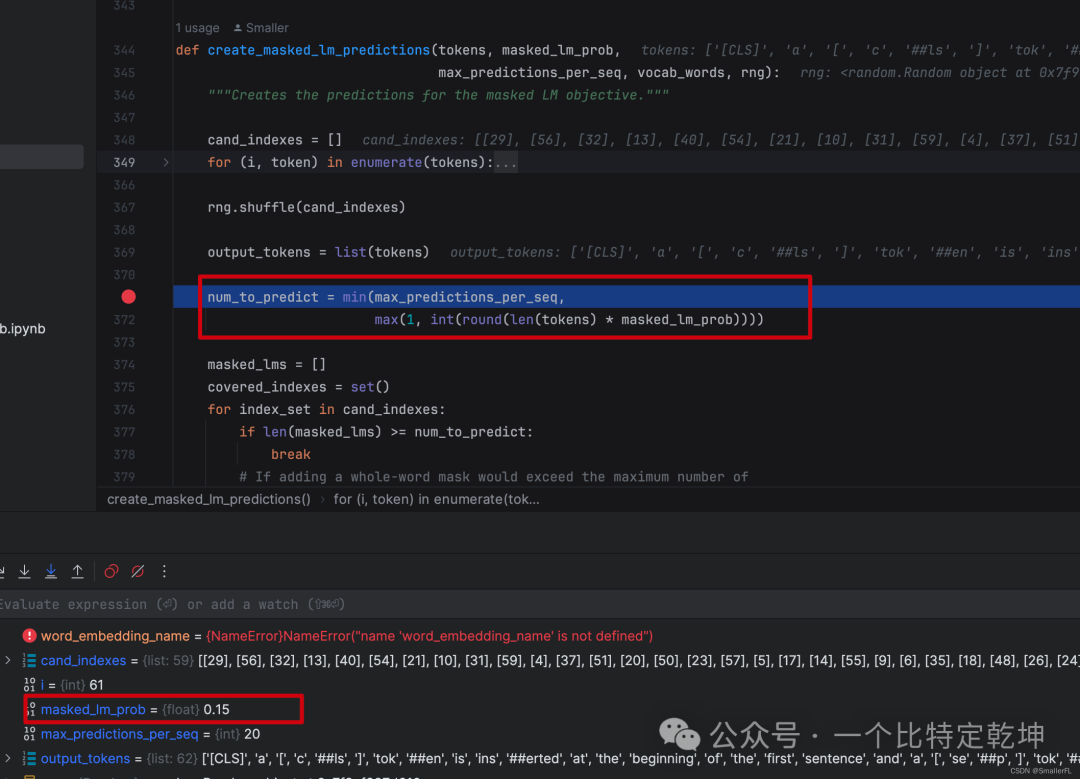
只不过这里的 num_to_predict 有一个最大限度,为 max_predictions_per_seq 即 20,这是设置的默认值!
如果忽略这个值,那么 len(tokens) * masked_lm_prob = len(tokens) * 15% 这就是选择 15% 的比例用来 MASK!
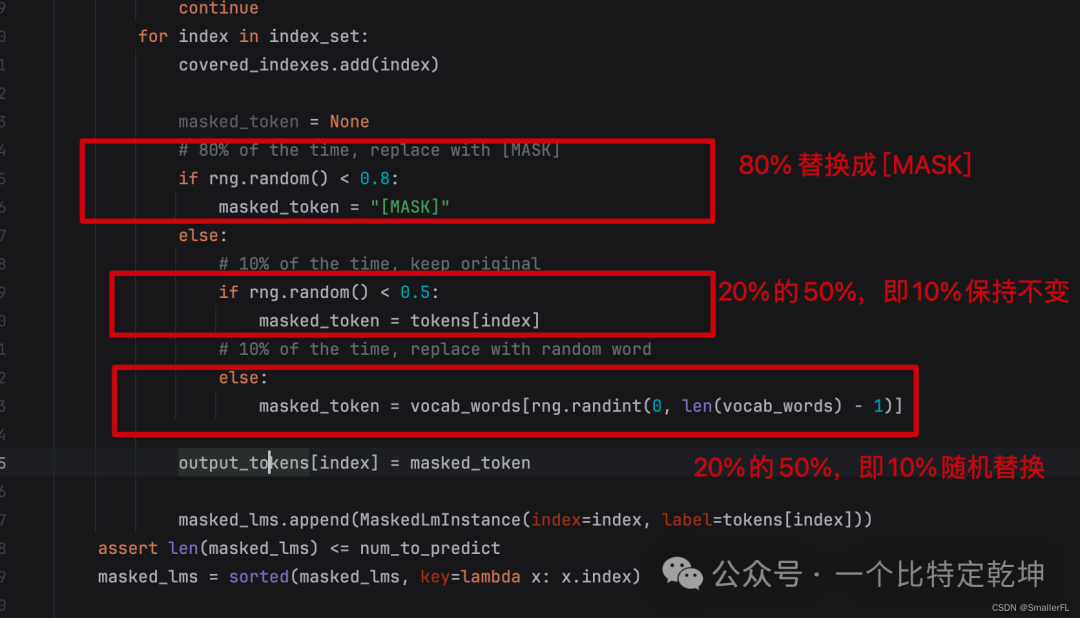
我们接着看 [MASK] 是如何替换的,看下面代码就非常清楚了!
那么这个函数返回的值是啥?返回值有三个(output_tokens, masked_lm_positions, masked_lm_labels),描述如下:
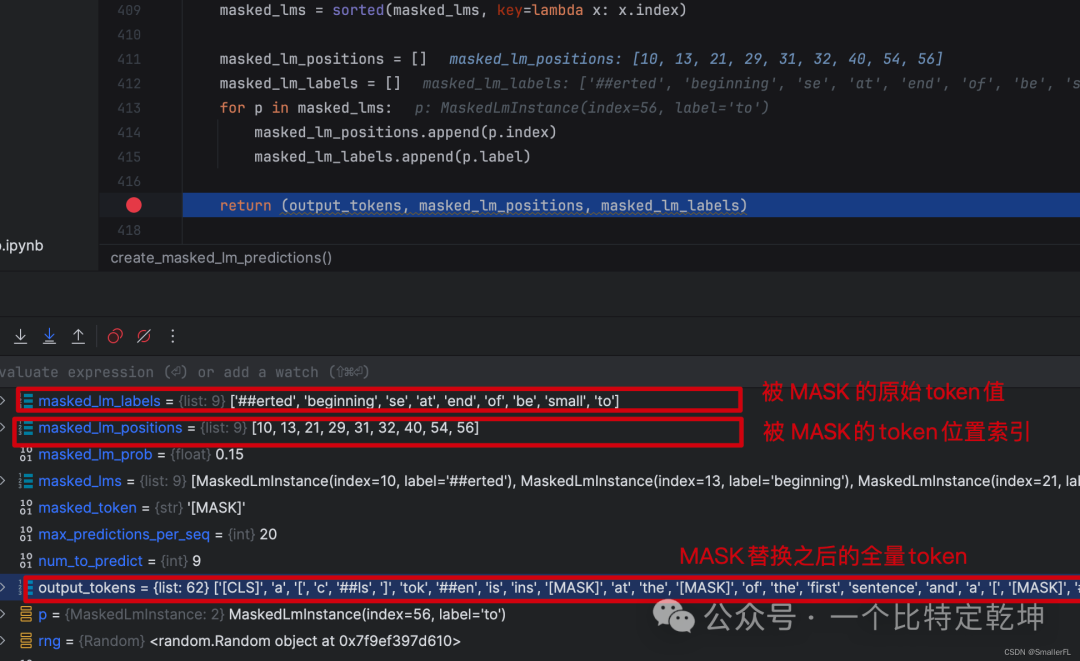
ok,到这里基本上就清楚了整体的数据准备的逻辑!
4.5 几个关键变量
我们大致跟着程序 debug 过了一遍数据准备的整体逻辑!下面总结一下输出的几个关键变量,这里面的变量有些会写入到文件里,必须深入理解其含义!
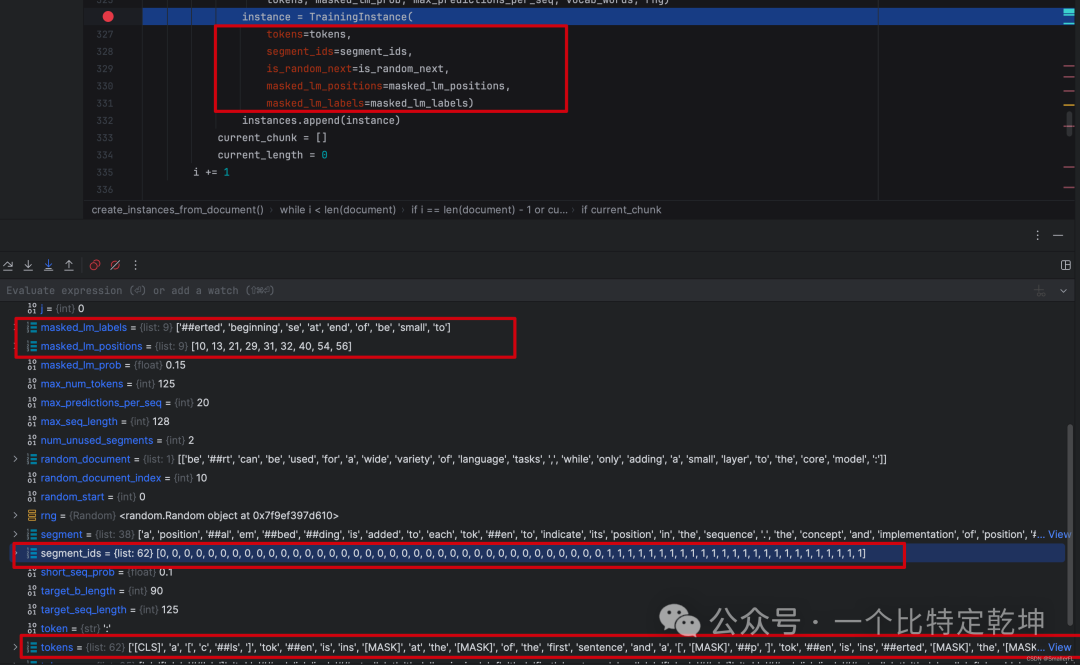
关键的变量含义如下:

为了方便理解还是举例:
句子 A 由以下 token 组成:[token_a1, token_a2],并且 token_a2 选中 MASK,并且变成 [MASK]
句子 B 由以下 token 组成:[token_b1, token_b2],并且 token_b2 选中 MASK,但是保持不变
且 B 是随机选择的,那么输出变量如下:

4.6 write_instance_to_example_files
最后一步是输出到外部的文件中,这就要看 write_instance_to_example_files 函数了:
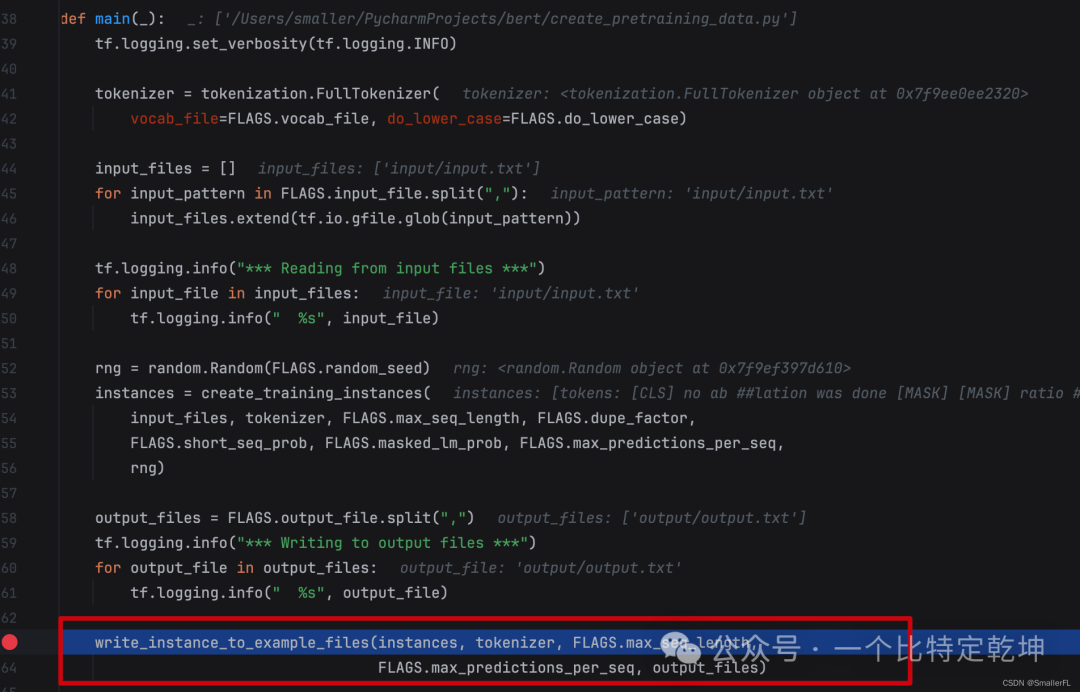
进入到其中,关键写入文件的几个变量input_ids、input_mask、segment_ids、masked_lm_positions、masked_lm_ids、masked_lm_weights、next_sentence_labels,这是后续预训练的输入参数,非常重要!
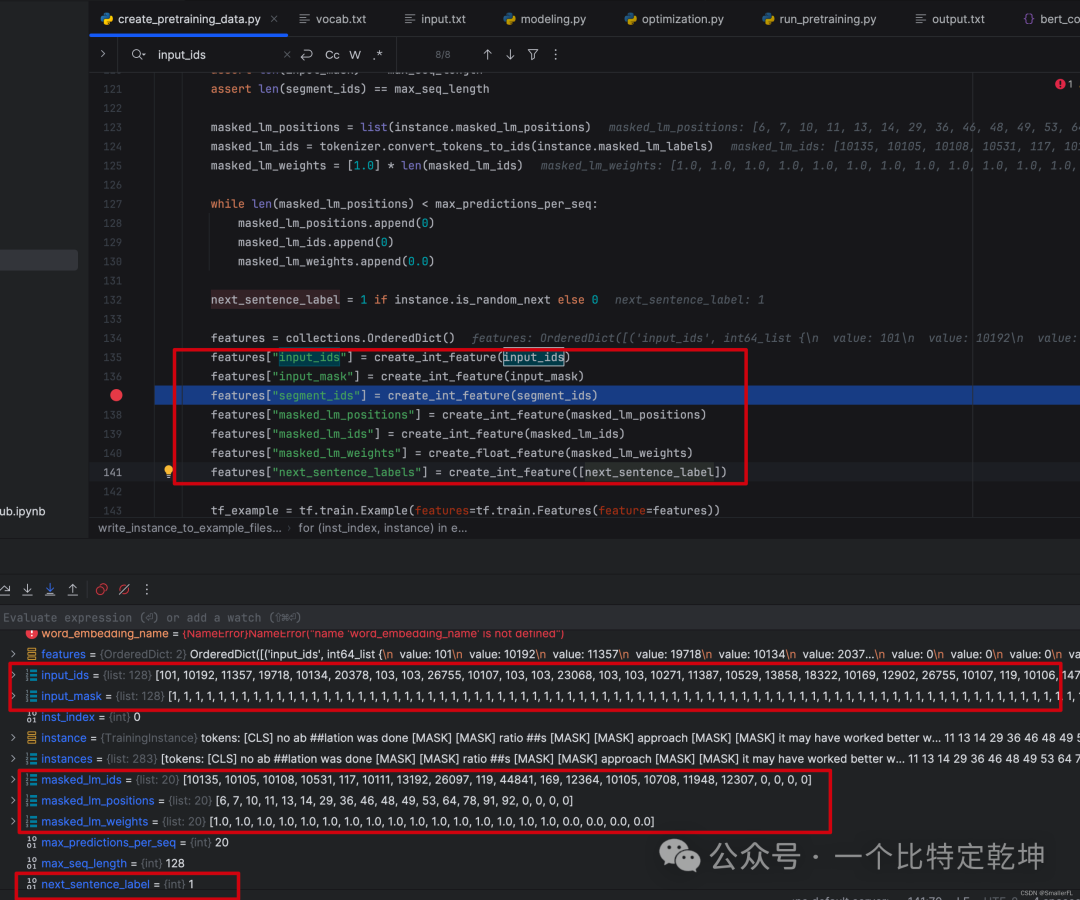
其中segment_ids、masked_lm_positions、masked_lm_ids 上文已经介绍过了。
# 以下是上一节描述的值,需要转换成输出到文件的值,贴在这里是方便对照
tokens: 带有[CLS]、[SEP],并且某些token已经被[MASK]的tokens列表
segment_ids: 句子A的token和句子B的token,按照0/1排列区分
is_random_next: 下一句是否随机选择的
masked_lm_positions: 被选中 MASK 的token位置索引
masked_lm_labels: 被选中 MASK 的token原始值
# 以下是输出到文件的值,也是会作为后续预训练的输入值,重点看!
input_ids:tokens在字典的索引位置,不足max_seq_length(128)则补0
input_mask:初始化为1,不足max_seq_length(128)则补0
segment_ids: 句子A的token和句子B的token,按照0/1排列区分。不足max_seq_length(128)则补0
masked_lm_positions: 被选中 MASK 的token位置索引
masked_lm_ids:被选中 MASK 的token原始值在字典的索引位置masked_lm_weights:初始化为1
next_sentence_labels:对应is_random_next,1表示随机选择,0表示正常语序
5. 预训练
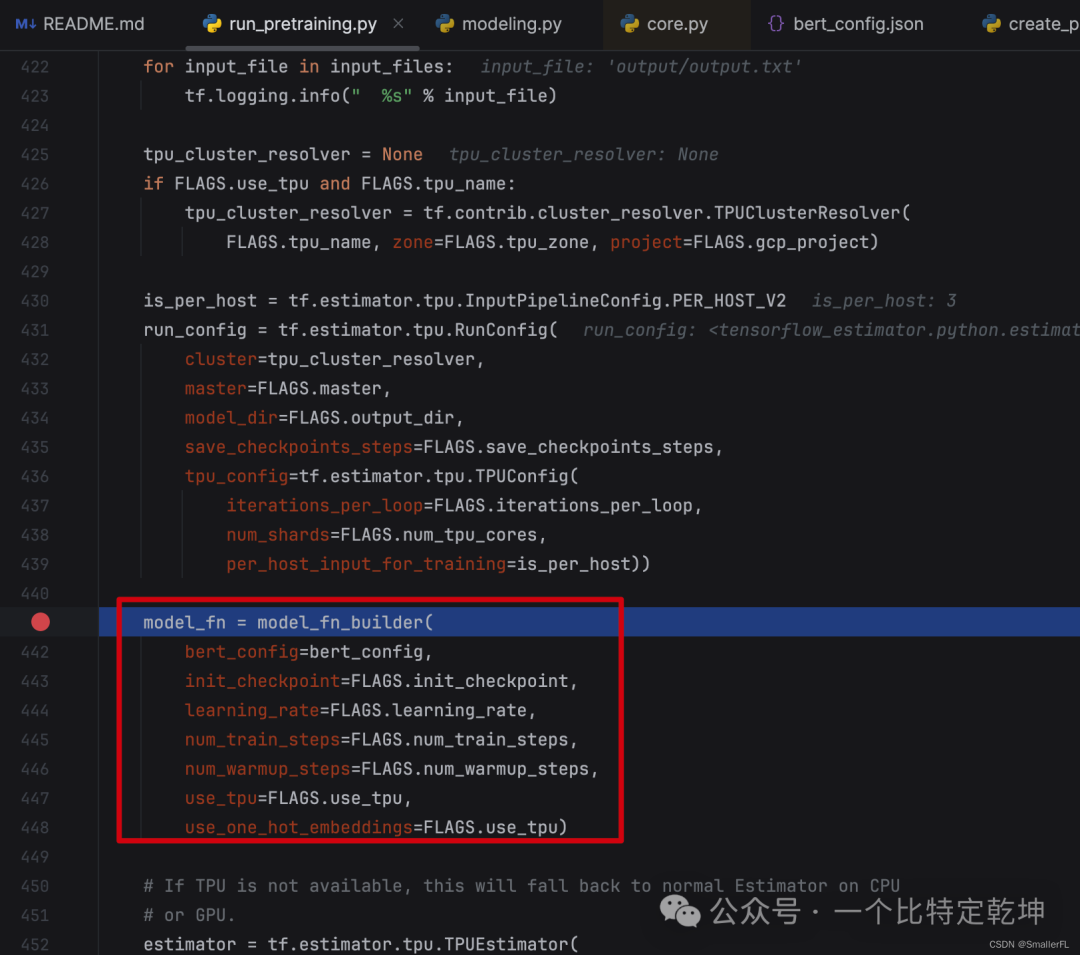
预训练代码在 run_pretraing.py 文件中,注意我们需要把数据准备的结果作为预训练的输入:
那我们打上断点,继续开启 debug 吧!
5.1 modeling.BertModel
看预训练代码,大部分的核心代码集中在 modeling.BertModel 这个 class 的 __init__ 代码中:
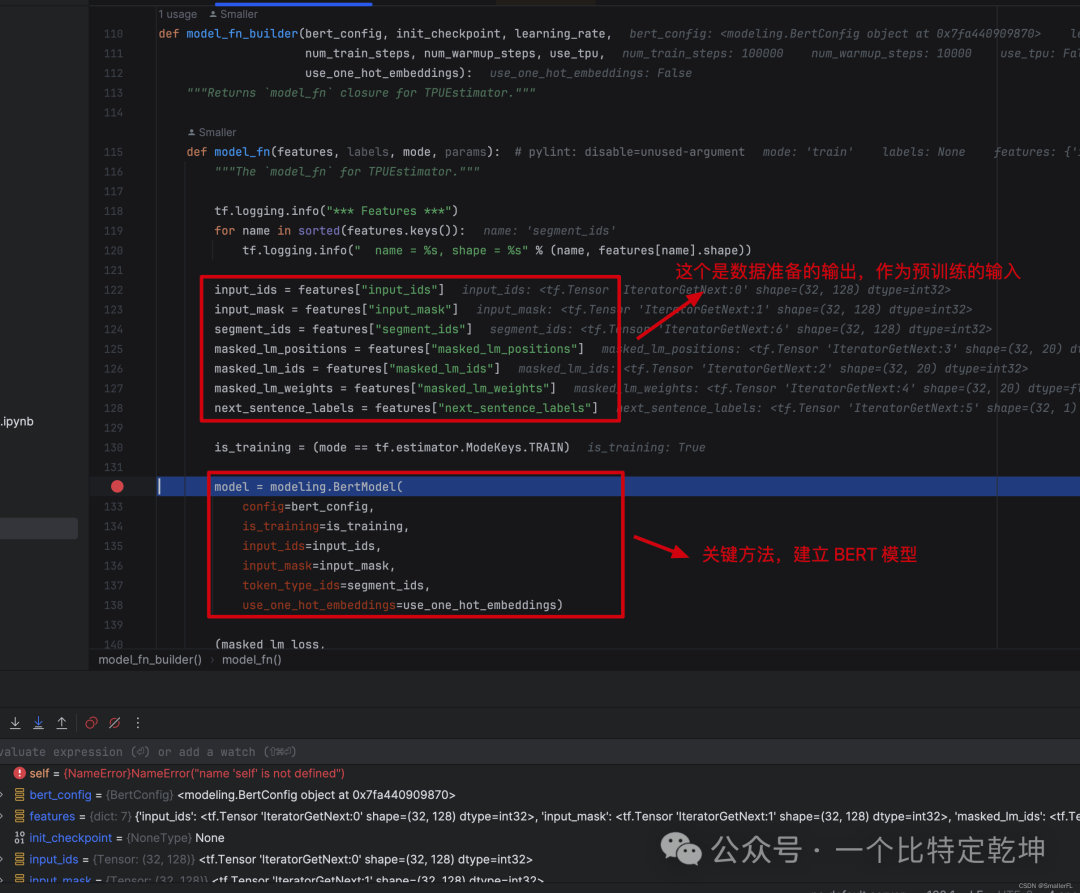
解释下 modeling.BertModel 的参数:
- config:BERT 的配置文件,后续的很多参数都来源于此。我放到路径
./multi_cased_L-12_H-768_A-12/bert_config.json,内容如下:

- is_training:True 表示训练,False 表示评估
- input_ids:对应于数据准备的字段
input_ids,形状[batch_size, seq_length],即[32, 128] - input_mask:对应于数据准备的字段
input_mask,形状[batch_size, seq_length],即[32, 128] - token_type_ids:对应于数据准备的字段
segment_ids,形状[batch_size, seq_length],即[32, 128] - use_one_hot_embeddings:词嵌入是否用 one_hot 模式
- scope:变量的scope,用于
tf.variable_scope(scope, default_name="bert")默认是 bert
5.1.1 embedding_lookup
在 modeling.BertModel 的 __init__ 代码中,第一个重要的方法是 embedding_lookup:
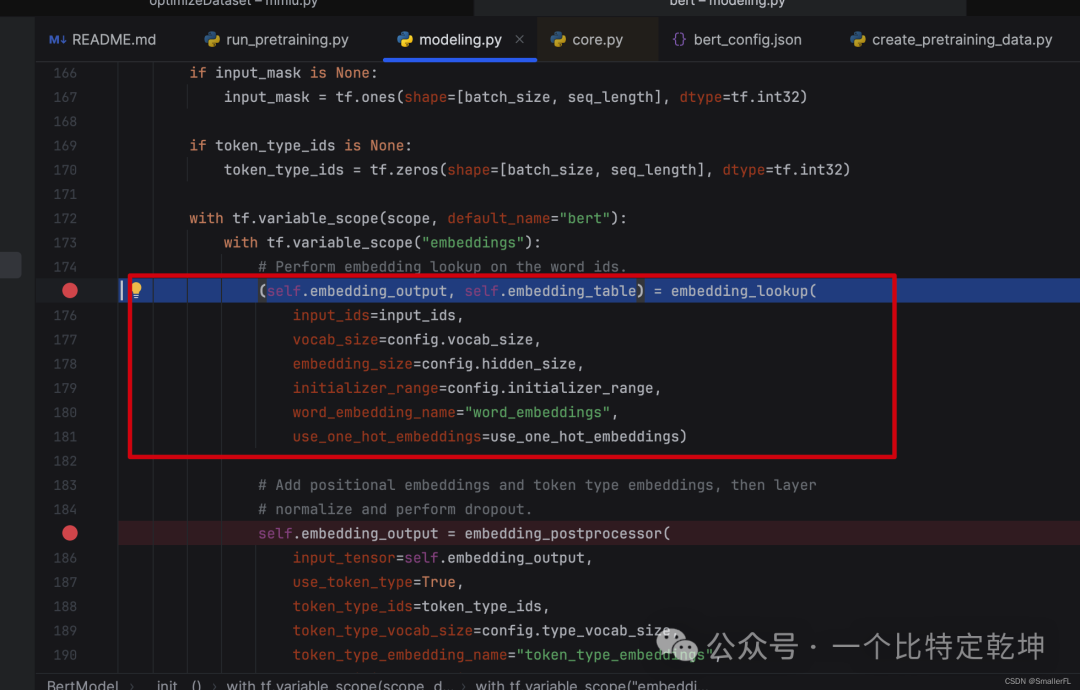
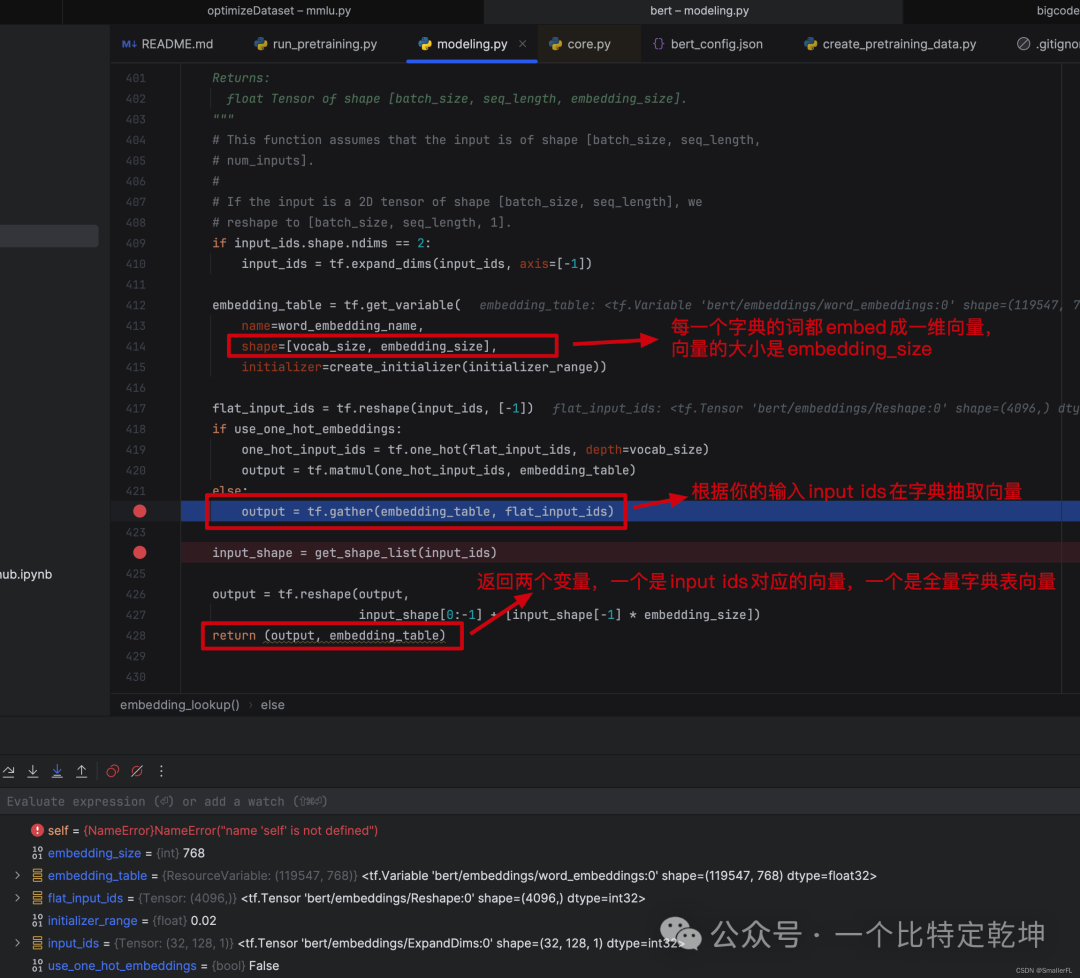
我们看下具体的代码,返回值有两个:
out_put是根据输入的input_ids在字典中找到对应的词,并且返回词对应的 embedding 向量,out_put的形状是[batch_size, seq_length, embedding_size]embedding_table是字典每一个词对应的向量,形状是[vocab_size, embedding_size]
ps: 有些同学不清楚字典是什么?字典在项目的 ./multi_cased_L-12_H-768_A-12/vocab.txt 里,每一行对应一个词,里例如id=0则表示字典第一个对应的词[PAD],字典内容如下:

5.1.2 embedding_postprocessor
后续的该方法是用于加上位置编码!
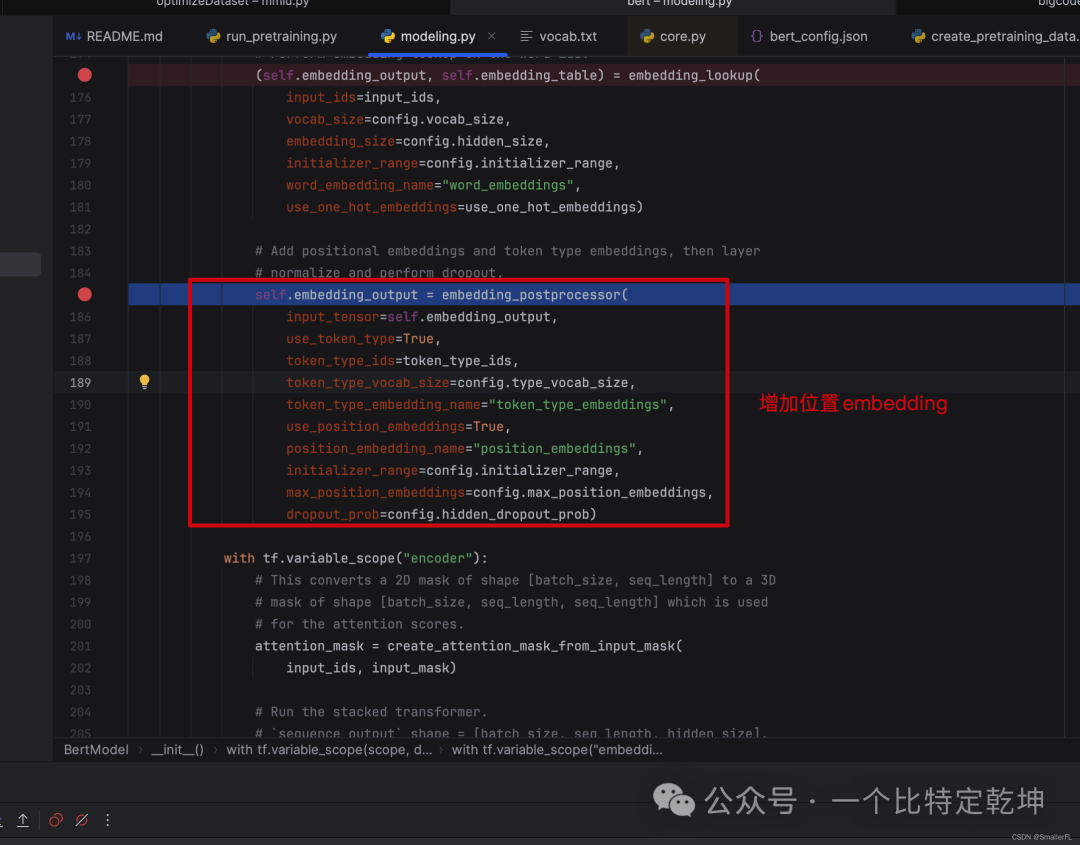
我们进到函数内部查看具体细节:
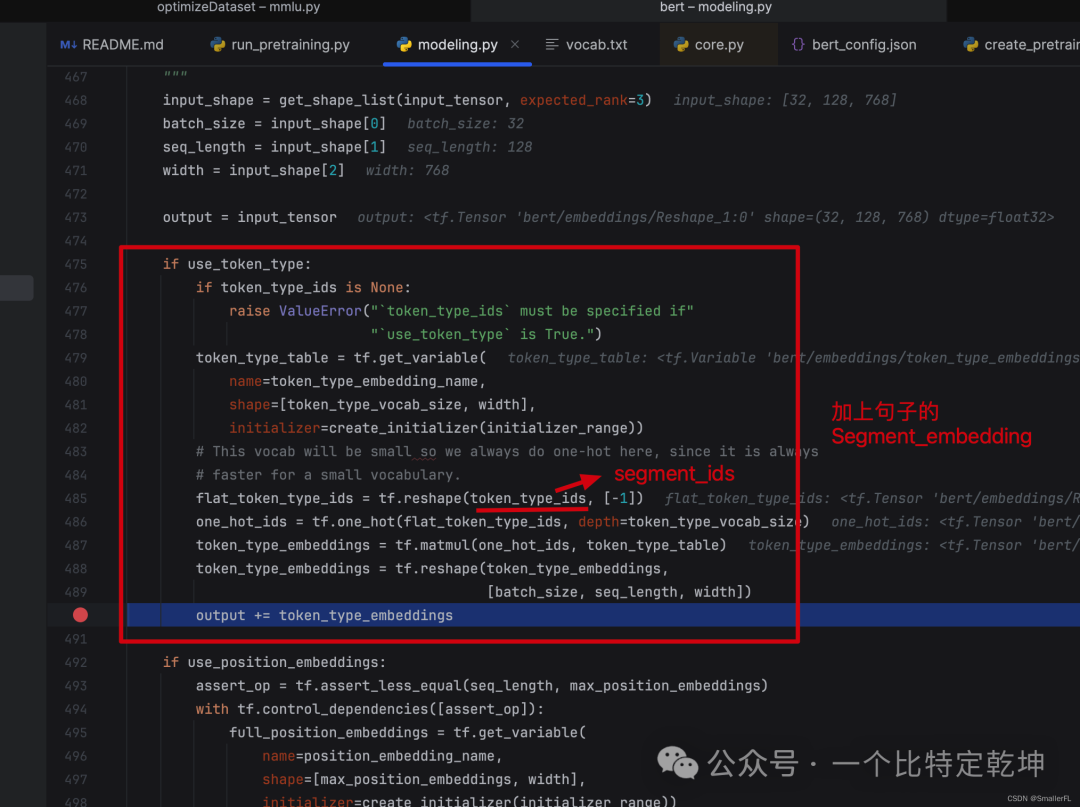
上面代码中,token_type_ids 对应的是 segment_ids,即句子的表示(用0/1来表示)。token_type_table 和上一节的 embedding_table 是一样的含义,这里就是向量化 segment_ids。由于 segment_ids 只用 0和1来表示,所以token_type_vocab_size=2,并且最终将 out_put 加上了 segment_ids 向量化的结果,就是图中的 TokenEmbeddings + SegmentEmbeddings
那么显而易见,下一段代码就是再加上 PositionEmbeddings 了!
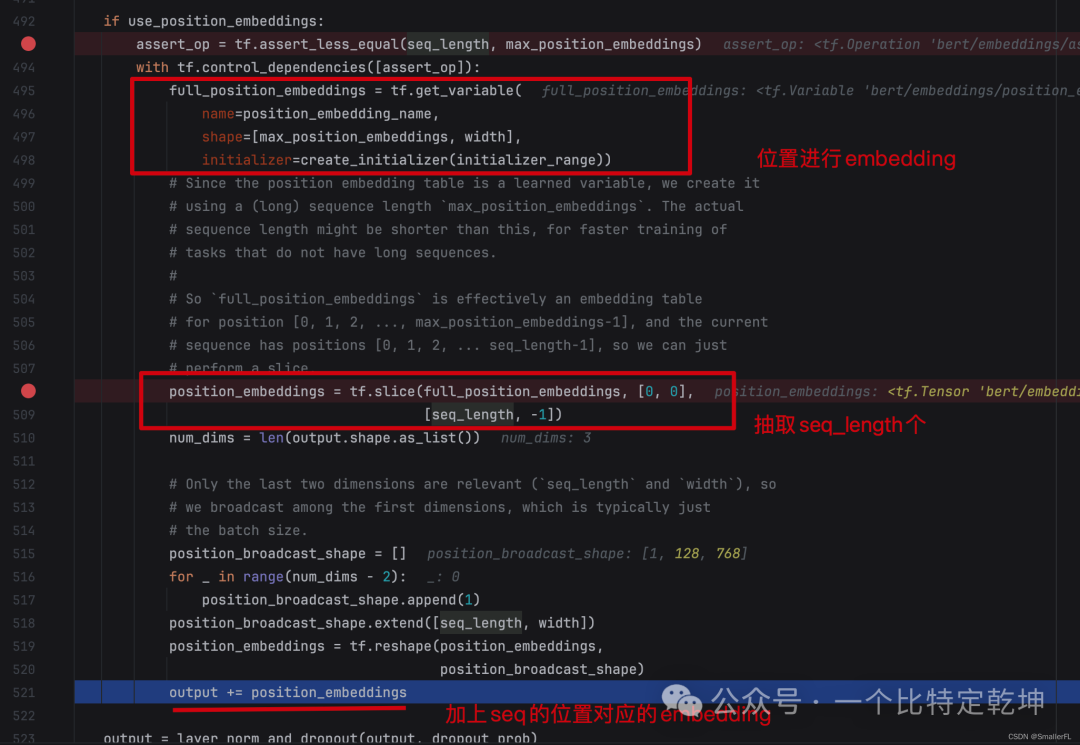
注意,这里的 position_embeddings 实际就是词在句子中的位置对应的 embedding~
最后将输出加上了 layer_norm_and_dropout ,即层归一和dropout。
5.1.3 transformer_model
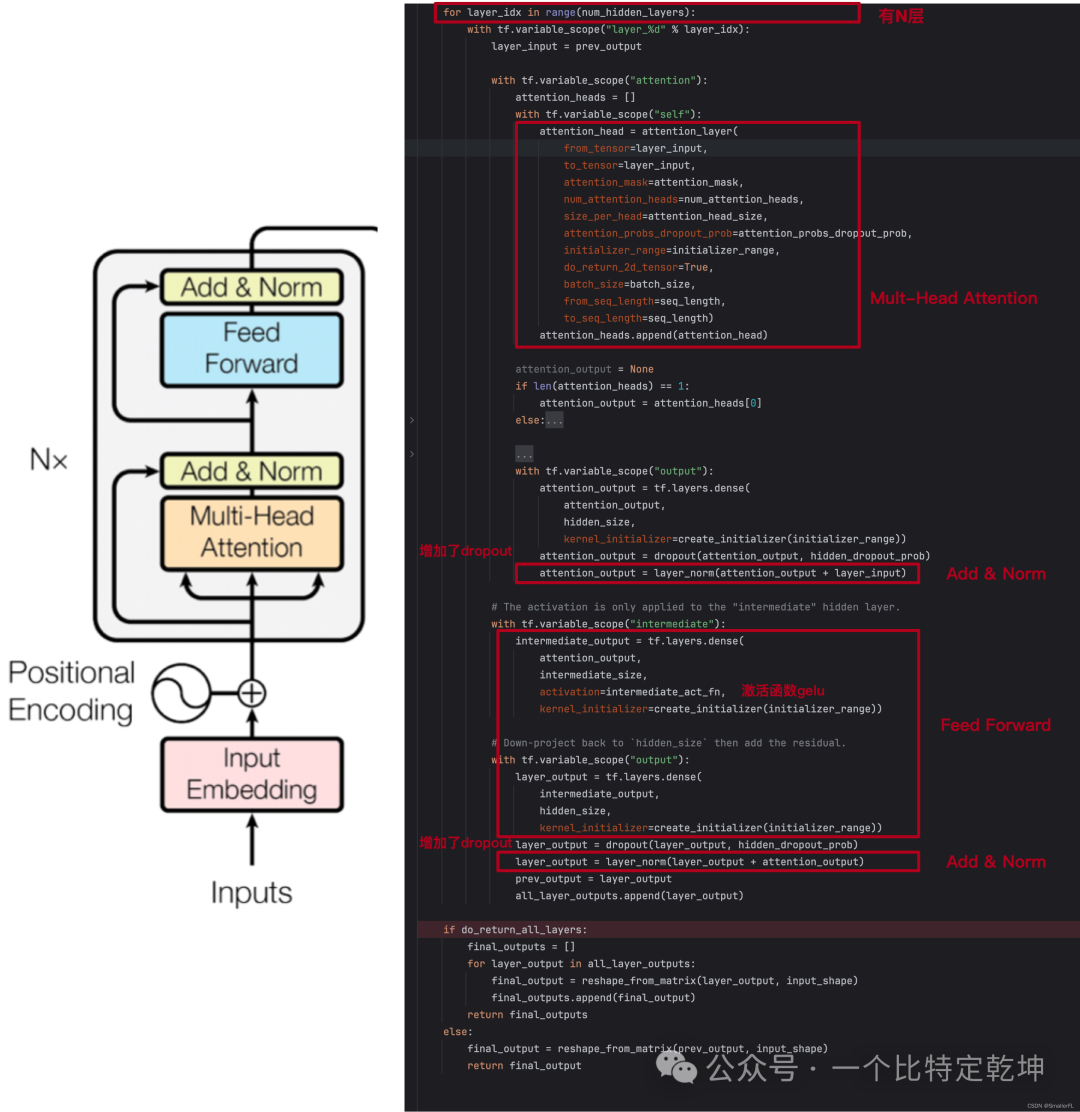
顺着代码debug下去,在准备好了数据之后,就是经典的 Transformer 模型了:
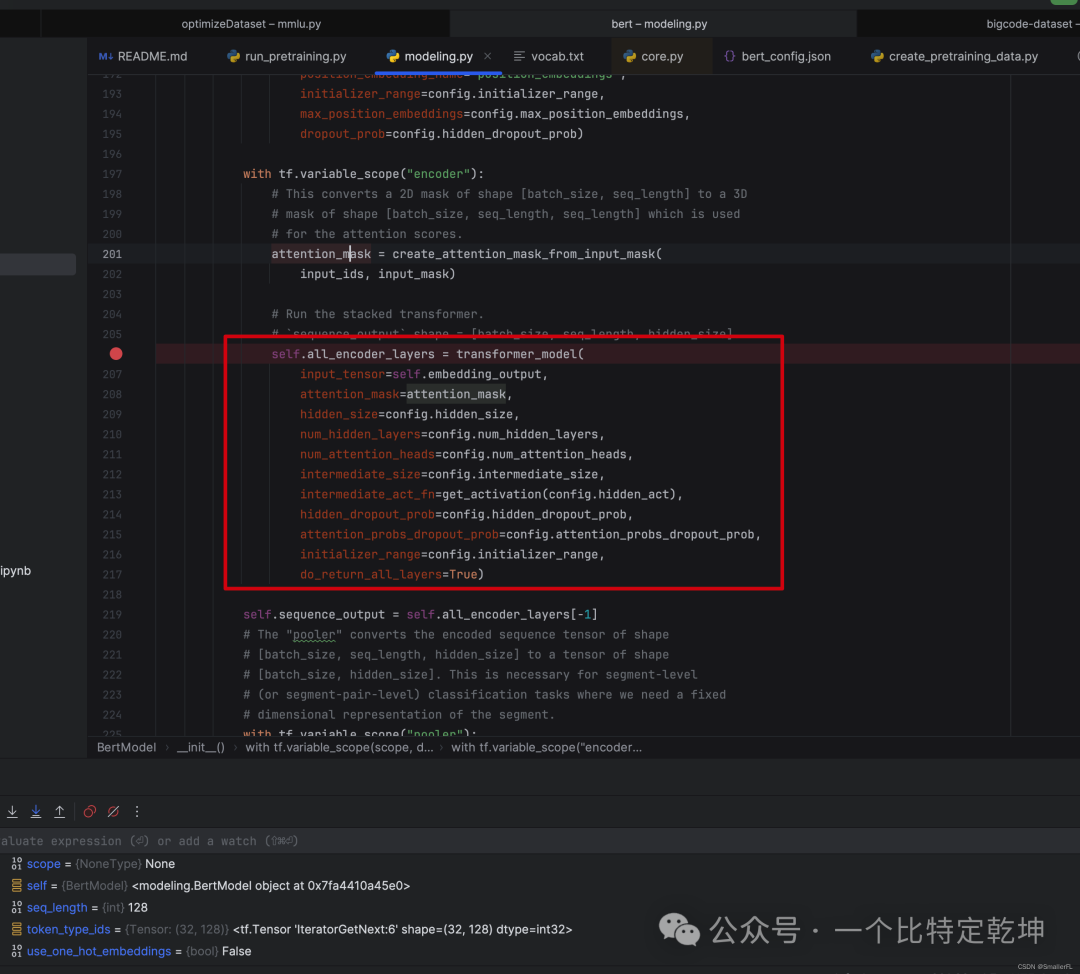
我们先回忆下 Transformer 的结构,因为下面的代码完全是对论文的编码器实现:
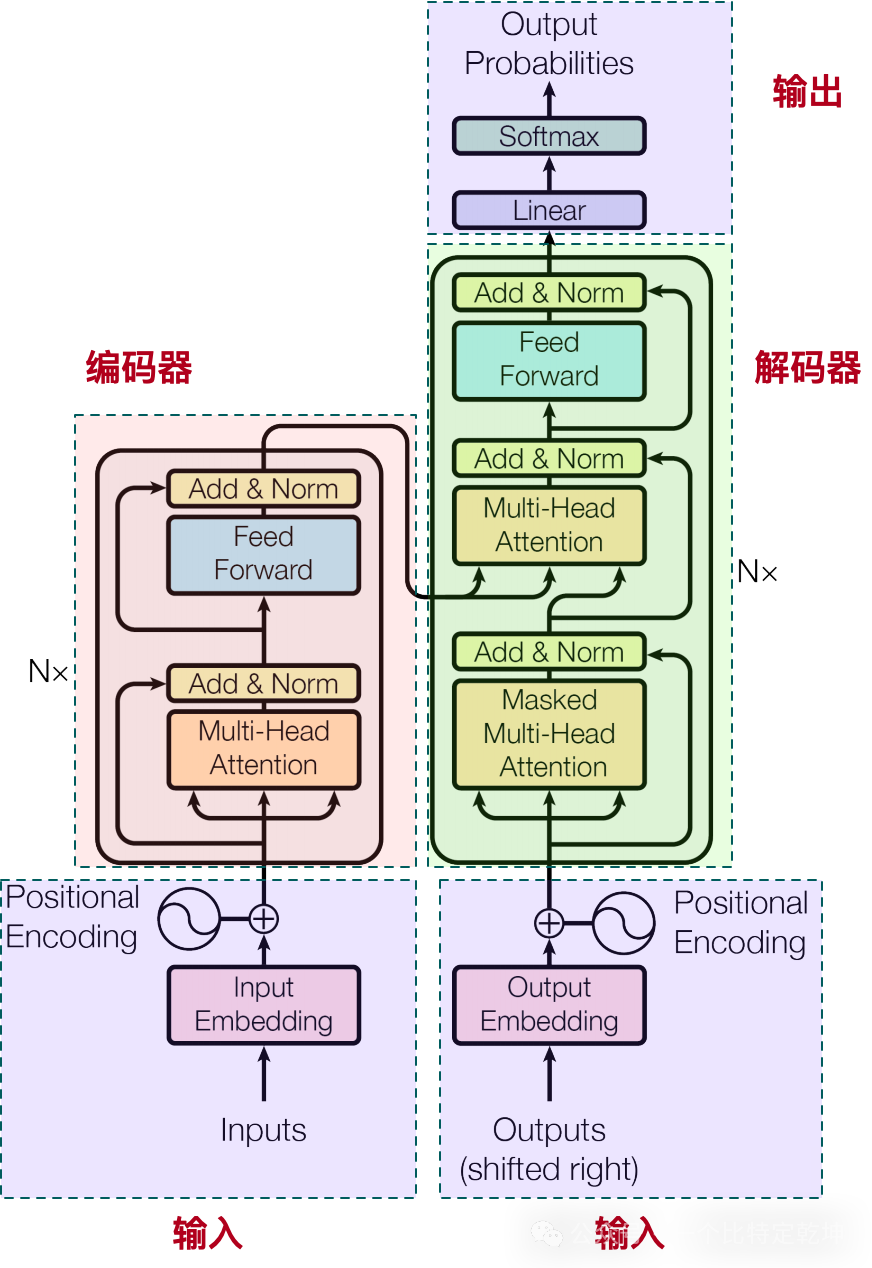
为了方便查看,我把代码的结构和论文的结构对比在一起:
transformer 结构构建完成之后,下面的self.sequence_out 是把最后一层的输出作为 transformer 的 encoding 结果输出。
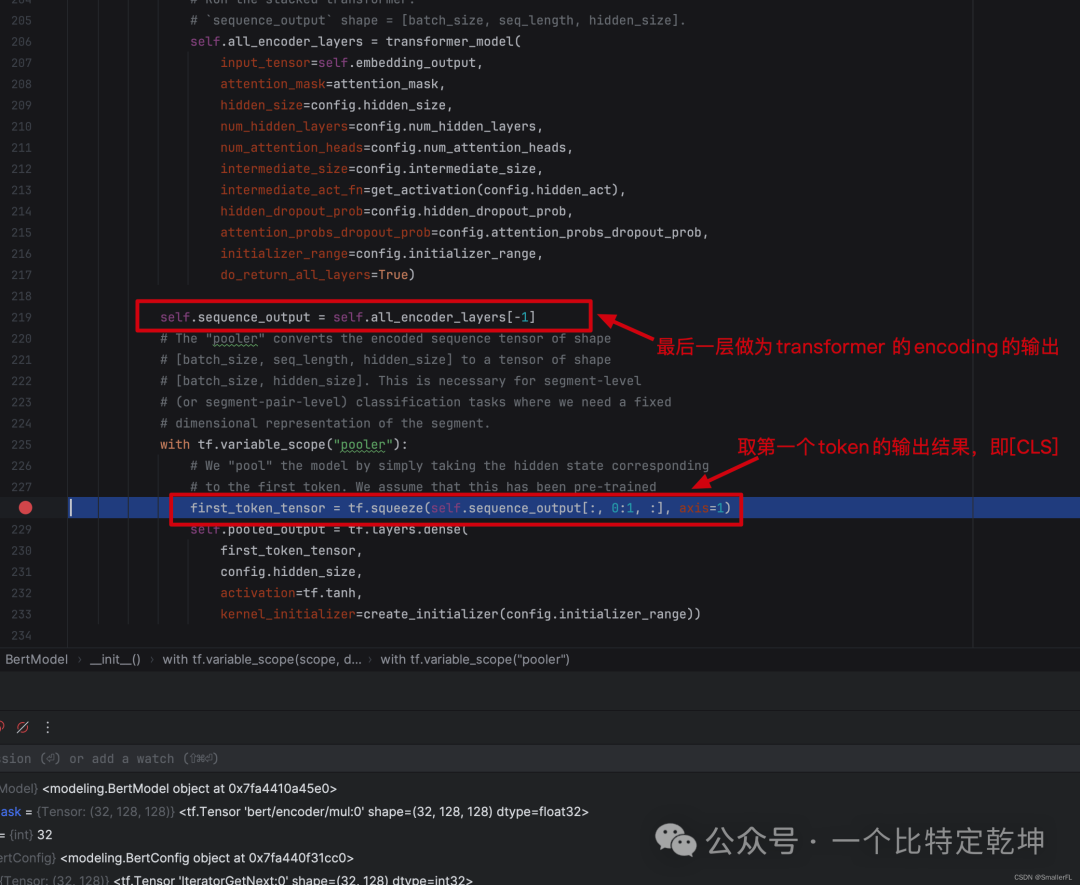
此外,first_token_tensor 是取第一个 token 的输出结果,即 [CLS] 的结果。因为 [CLS] 已经带有上下文信息了,因此对于分类而言,用 [CLS] 的输出即可。这个论文中也有说明:
以上就是 BERT 模型的构建整体流程,下面来看 BERT 模型的评估流程,包含 Masked Language Model(MLM)和 Next Sentence Prediction(NSP)。
5.2 get_masked_lm_output
先来看 Masked Language Model(MLM)的评估,对应代码中的 get_masked_lm_out ,见下图:
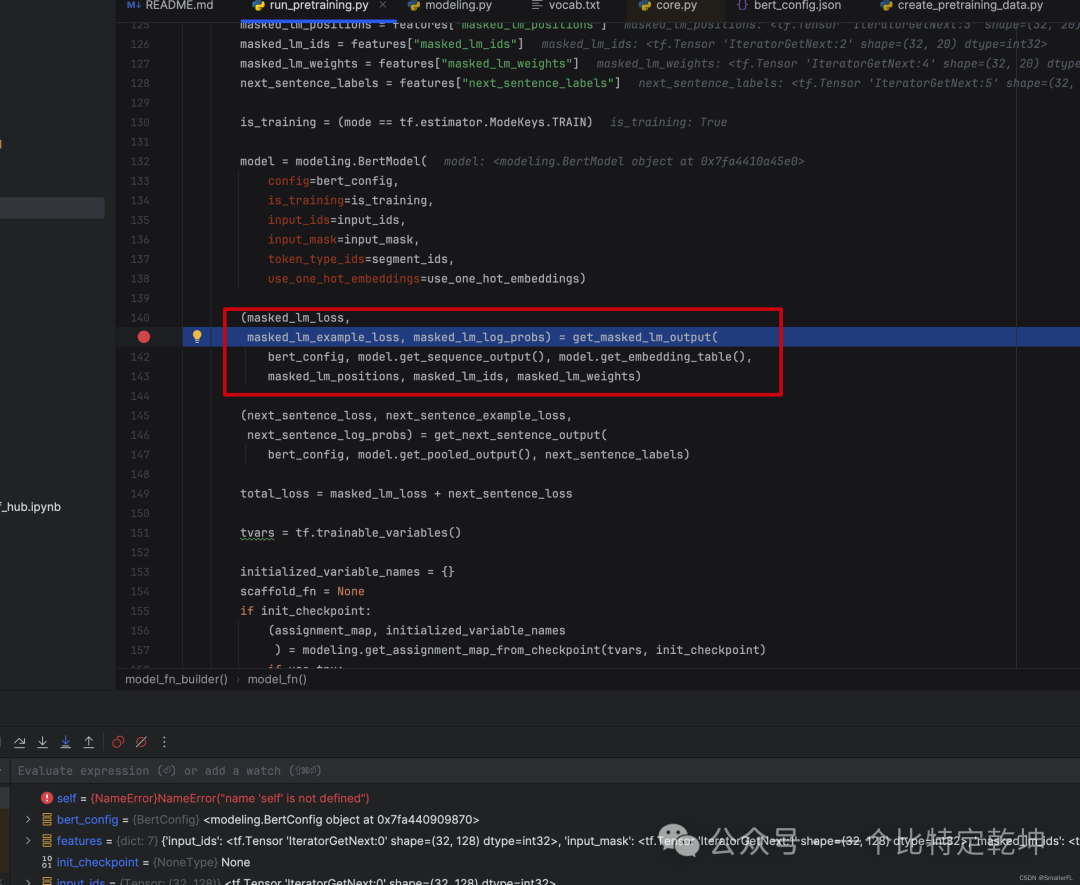
首先看下 get_masked_lm_out 的输入参数:
bert_config: BERT 的配置文件,对应我的路径./multi_cased_L-12_H-768_A-12/bert_config.jsoninput_tensor:BERT 模型的输出,即上文的self.sequence_outoutput_weights:对应上文embedding_lookup的第二个输出,即字典每一个词对应的向量,形状是[vocab_size, embedding_size]positions:对应features["masked_lm_positions"],即被选中 MASK 的 token 位置索引label_ids:对应features["masked_lm_ids"],即被选中 MASK 的 token 原始值在字典的索引位置label_weights:对应features["masked_lm_weights"]
下面是整体的代码,代码有些地方需要细细品味:
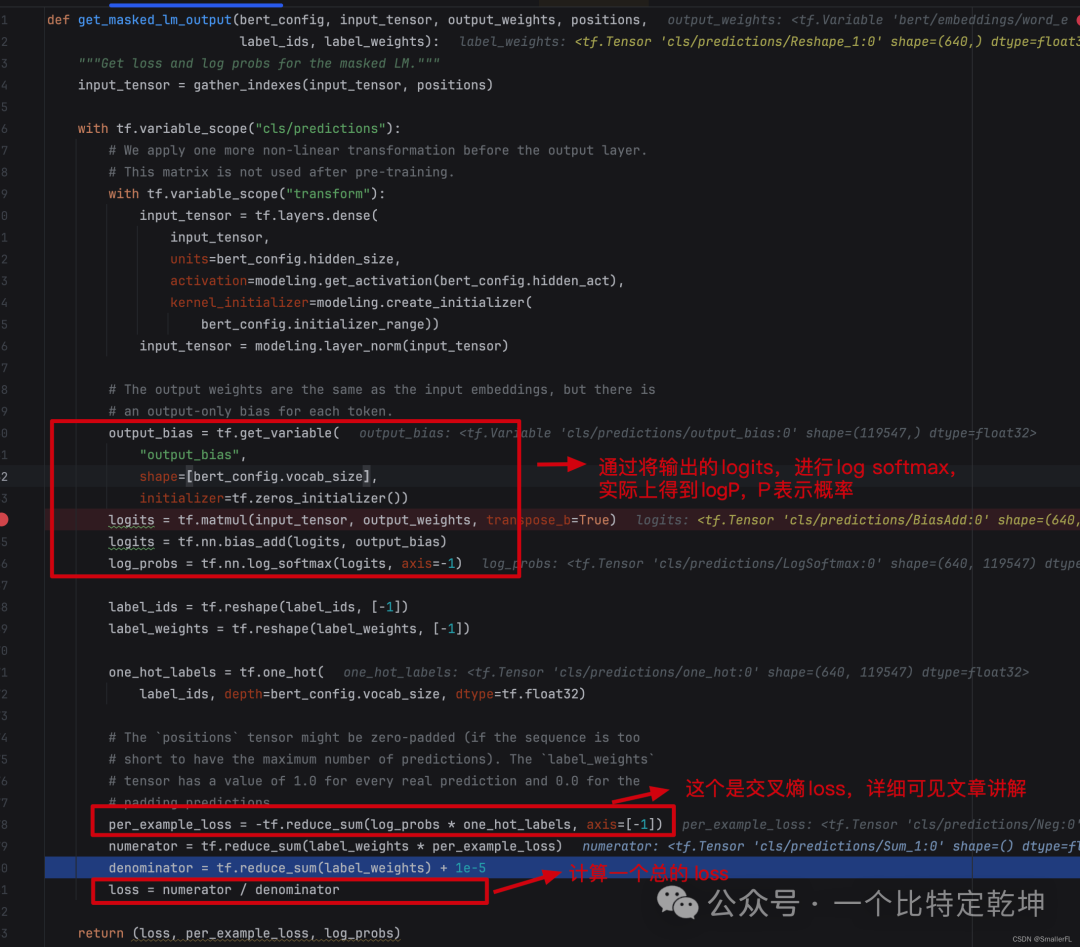
要看懂这里的代码,首先我们要知道 BERT 在 Masked Language Model(MLM)上要干啥。BERT 首先给句子的词打上了 [MASK] ,后续就要对 [MASK] 的词进行预测。预测,就是在词典中出现的词给出一个概率,看属于哪个词,本质上就是多分类问题。那么对于多分类问题,通常的做法是计算交叉熵。
这里就不详细阐述交叉熵的来龙去脉了,直接说明交叉熵如何计算。我们假设真实分布为 y,而模型输出分布为 ,总的类别数为 n,交叉熵损失函数的计算方法为:
好,我们来看代码中关键的几个步骤:
log_probs = tf.nn.log_softmax(logits, axis=-1),这个方法实际上计算的是:
其中 表达的是属于词典第 i 个词的概率的对数值。
one_hot_labels = tf.one_hot(label_ids, depth=bert_config.vocab_size, dtype=tf.float32),计算每个词的在字典的 one_hot 结果,形状是[batch_size*seq_len, vocab_size]。例如,“animal” 在字典第18883位置,那么"animal"对应的 one_hot 就是 [0,0,…0,1,0,…,0],其中向量长度就是字典的大小,1排在向量的18883个。per_example_loss = -tf.reduce_sum(log_probs * one_hot_labels, axis=[-1]),这个方法是用于交叉熵的。因为我们知道真实的分布情况,就是one_hot_labels对应的结果,那么对于某一个具体的词,其交叉熵的计算就是 ,将 y=1(即事先知道一定属于某个词)代入,即交叉熵为 。所以事先计算了log_probs,per_example_loss可以直接得到每个词的交叉熵的结果。loss将per_example_loss得到的结果赋予权重进行加权平均,得到一个最终的 loss,实际上就相当于
5.3 get_next_sentence_output
再来看 Next Sentence Prediction(NSP)评估,预测句子的下一句:
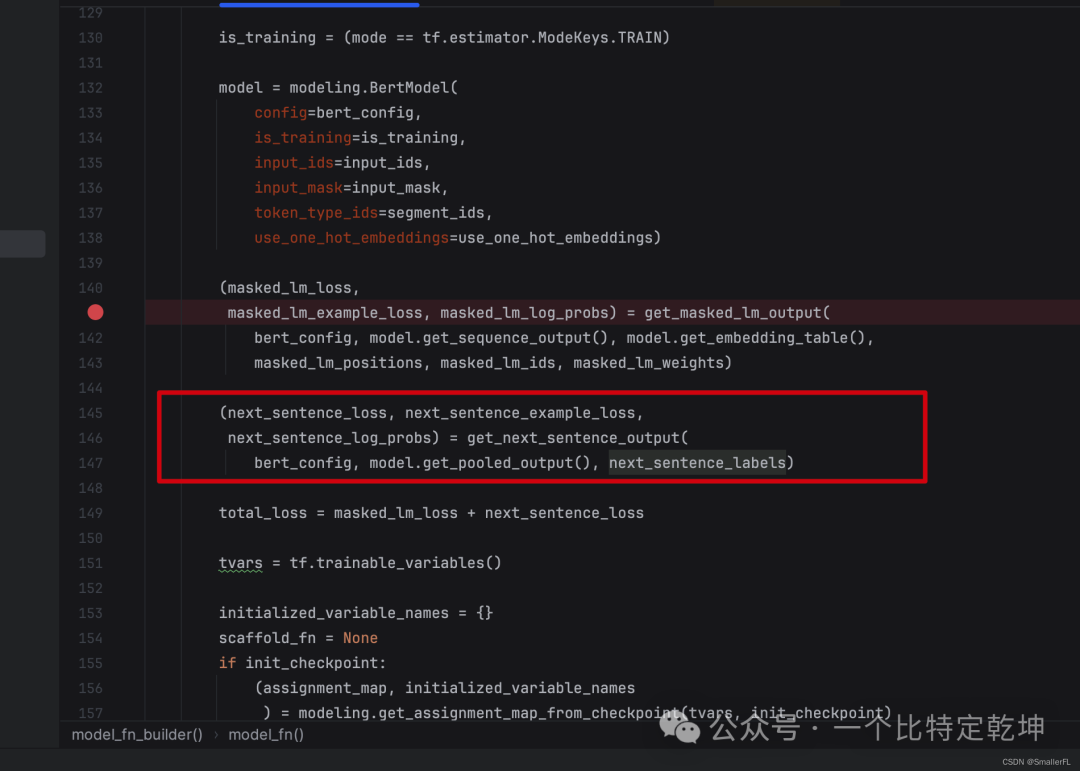
首先看下 get_next_sentence_output 的输入参数:
bert_config:BERT 的配置文件,对应我的路径./multi_cased_L-12_H-768_A-12/bert_config.jsoninput_tensor:[CLS]的输出线性变换后的结果,简单理解为[CLS]的输出作为当前函数的输入labels:对应features["next_sentence_labels"],1表示下一个句子是随机选择的,0表示正常语序
由于下一个句子只有两种选择,要么是随机的,要么是原先正常的句子,所以其实就是一个二分类问题:
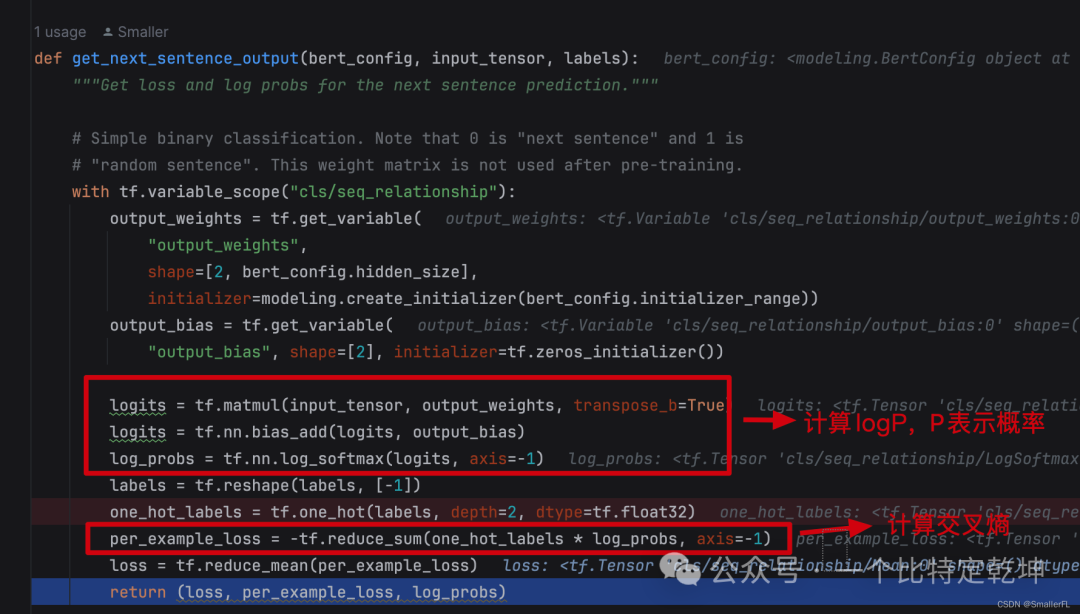
二分类的交叉熵:
上面的核心逻辑跟 get_masked_lm_output 一模一样。只不过这里的 loss 用的是平均值,没有用加权平均
5.4 训练
计算了 masked_lm_loss 以及 next_sentence_loss 之后,将两种 loss 相加,即是总的 loss
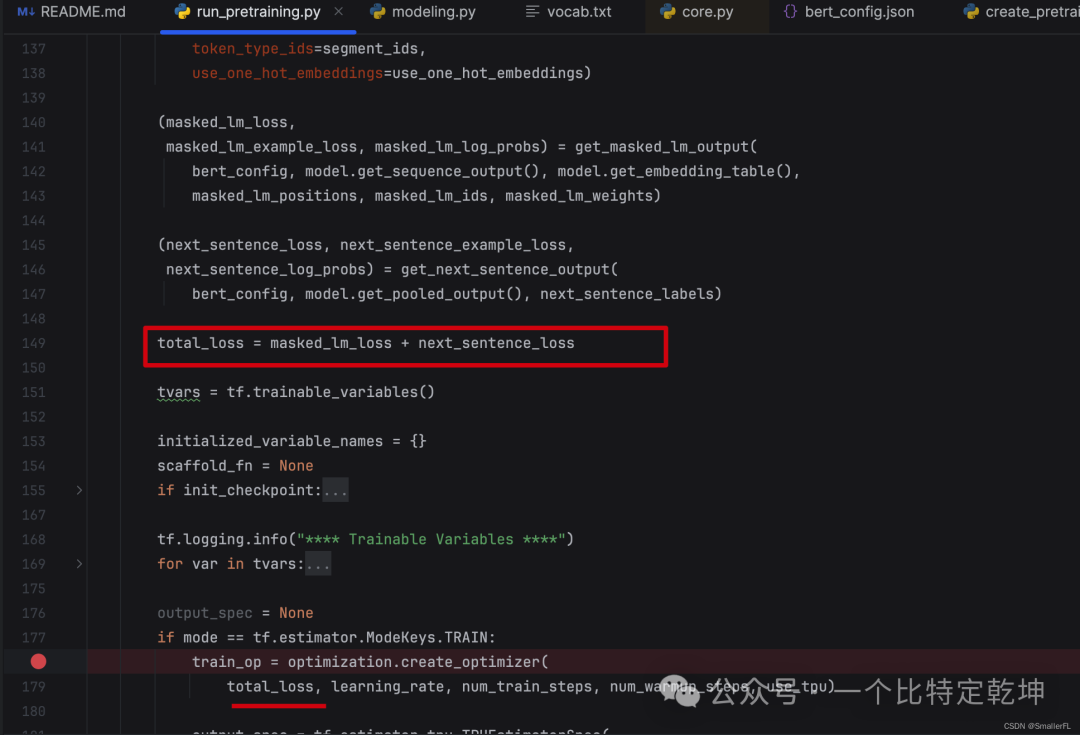
后续就训练模型降低 loss,跟一般的模型训练一样了。
零基础如何学习AI大模型
领取方式在文末
为什么要学习大模型?
学习大模型课程的重要性在于它能够极大地促进个人在人工智能领域的专业发展。大模型技术,如自然语言处理和图像识别,正在推动着人工智能的新发展阶段。通过学习大模型课程,可以掌握设计和实现基于大模型的应用系统所需的基本原理和技术,从而提升自己在数据处理、分析和决策制定方面的能力。此外,大模型技术在多个行业中的应用日益增加,掌握这一技术将有助于提高就业竞争力,并为未来的创新创业提供坚实的基础。
大模型典型应用场景
①AI+教育:智能教学助手和自动评分系统使个性化教育成为可能。通过AI分析学生的学习数据,提供量身定制的学习方案,提高学习效果。
②AI+医疗:智能诊断系统和个性化医疗方案让医疗服务更加精准高效。AI可以分析医学影像,辅助医生进行早期诊断,同时根据患者数据制定个性化治疗方案。
③AI+金融:智能投顾和风险管理系统帮助投资者做出更明智的决策,并实时监控金融市场,识别潜在风险。
④AI+制造:智能制造和自动化工厂提高了生产效率和质量。通过AI技术,工厂可以实现设备预测性维护,减少停机时间。
…
这些案例表明,学习大模型课程不仅能够提升个人技能,还能为企业带来实际效益,推动行业创新发展。
学习资料领取
如果你对大模型感兴趣,可以看看我整合并且整理成了一份AI大模型资料包,需要的小伙伴文末免费领取哦,无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发

部分资料展示
一、 AI大模型学习路线图
整个学习分为7个阶段


二、AI大模型实战案例
涵盖AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,皆可用。



三、视频和书籍PDF合集
从入门到进阶这里都有,跟着老师学习事半功倍。



四、LLM面试题


五、AI产品经理面试题

😝朋友们如果有需要的话,可以V扫描下方二维码联系领取~
👉[CSDN大礼包🎁:全网最全《LLM大模型入门+进阶学习资源包》免费分享(安全链接,放心点击)]👈

















 2206
2206

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









