







计算机视觉系统的视觉 RAG 组件
我们相信视觉领域即将发生范式转变,从而产生_计算机视觉管道 2.0_,其中一些传统阶段(例如标记)将被可提示的基础模型所取代。
本文深入剖析了Visual RAG(Visual Retrieval-Augmented Generation)的创新领域,揭示了它的核心价值以及它如何根本性地转变了我们对传统计算机视觉任务的处理方式。文章将从RAG的基本概念出发,深入探讨其在视觉识别、图像分析和智能监控等应用中的实践,阐释这项前沿技术如何为构建更智能、更高效的人工智能系统奠定基石。
1. 什么是检索增强生成(RAG)?
1.1 什么是视觉提示?
为了更好地理解检索增强生成 (RAG) [1],我们首先来了解“提示”的定义。
提示是一种通过提供特定指令或查询来指导基础模型(例如多模式大型语言模型(MLLM))执行任务的技术。
在视觉领域,视觉提示[3] 使用视觉输入(例如图像、线条或点)来指示大规模视觉模型执行特定任务,通常包括模型未明确训练的任务。
下图展示了如何将可提示模型用来创建更强大的系统,其中的关键见解是模型可以通过视觉提示连接:YOLO-World 输出可以用作 SegmentAnything 的视觉提示。
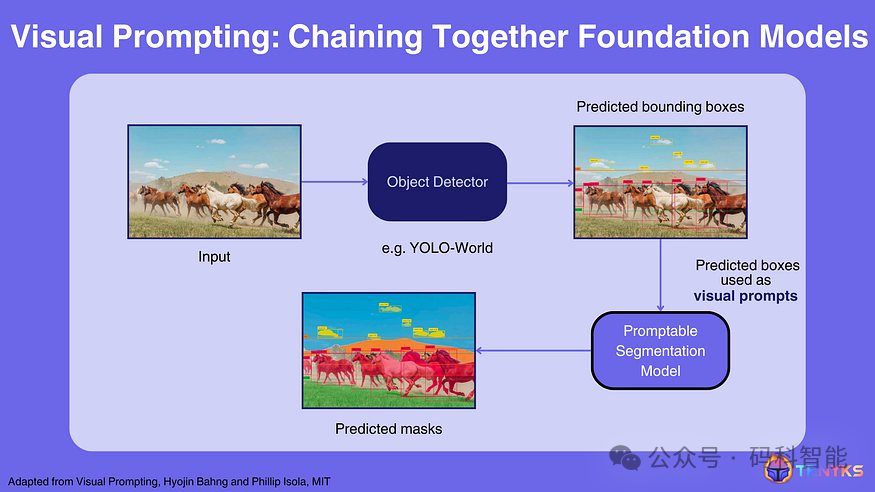
因此,事实证明,提示为建立 RAG 等更先进的技术提供了基础。
1.2 什么是RAG?
RAG 将提示与信息检索的原理结合起来。[2] 当你使用 GenAI 模型(例如 GPT-4 或 LLaVA [5])时,你获得的答案来自(零样本)模型 [4],该模型受到其信息截止值(或其自身的训练数据,无论是数量还是质量)的限制。因此,模型的知识是静态的,在某个点之后不会更新。
检索增强生成 (RAG)使系统能够检索相关上下文,然后将其与原始提示相结合。此增强提示用于查询模型,提供模型原本无法获得的数据。
1.3 了解 RAG 的工作原理
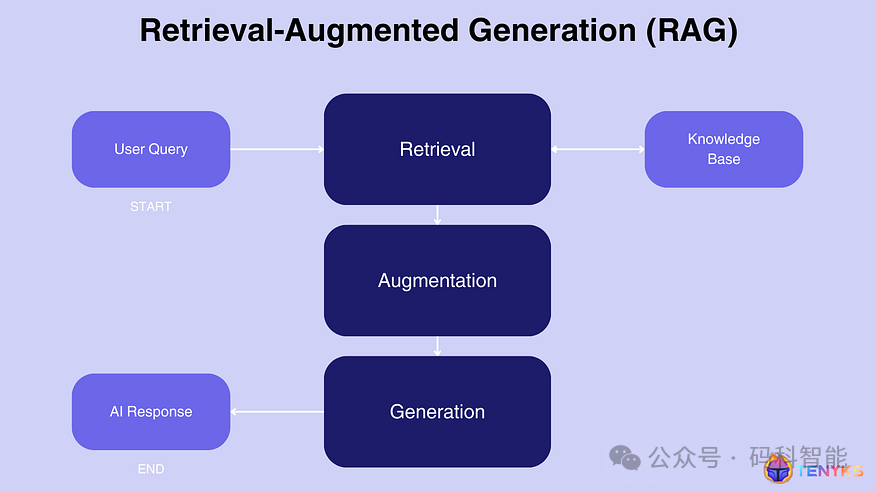
通过下图可以看到经分解后,典型的 RAG 工作流程:
-
检索:当给出查询或提示时,系统首先从知识库或外部数据源检索相关信息。
-
增强:然后使用检索到的信息来增强或改进模型的输入。
-
生成:最后,模型根据原始查询和检索到的信息生成响应。
2. RAG 如何在计算机视觉中使用?
2.1 传统(文本)RAG 与 可视化 RAG
如下图所示,Visual RAG 将检索增强生成 (RAG) 的概念应用于视觉任务。传统的 RAG 处理文本输入并检索相关文本信息,而 Visual RAG 则处理图像(有时还附带文本),并检索视觉数据或图像-文本对。
编码过程从文本编码器转变为视觉编码器(有时使用诸如 CLIP [6] 的基础模型来实现此目的),并且知识库(即矢量数据库)成为视觉信息而非文本文档的存储库。
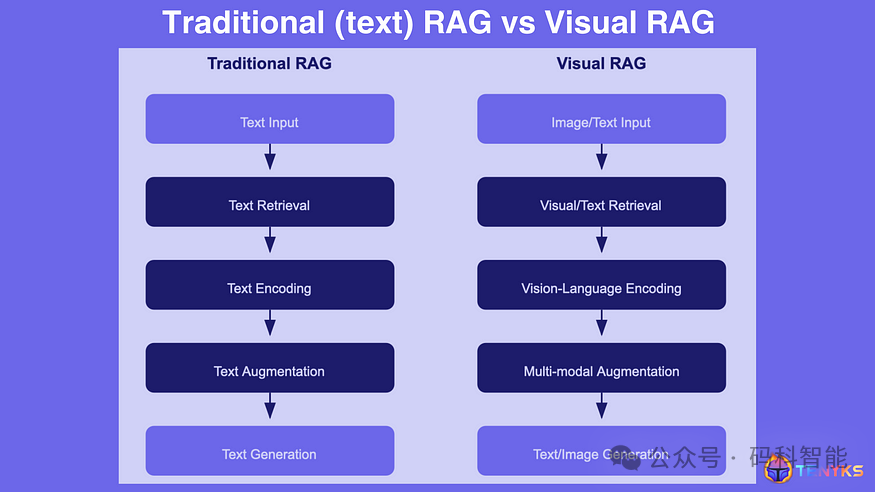
图 3. 语言模型的 RAG 与视觉模型的 RAG 比较
最后,Visual RAG 的增强功能将检索到的视觉数据与输入相结合,使其能够生成包括文本描述、修改后的图像或多模式内容在内的多种输出。Visual RAG 对于需要将视觉理解与外部知识相结合的任务特别强大。例如,它可以通过从知识库中检索这些边缘情况的相关视觉和文本信息来帮助视觉系统识别稀有物体。
2.2 视觉 RAG 或微调
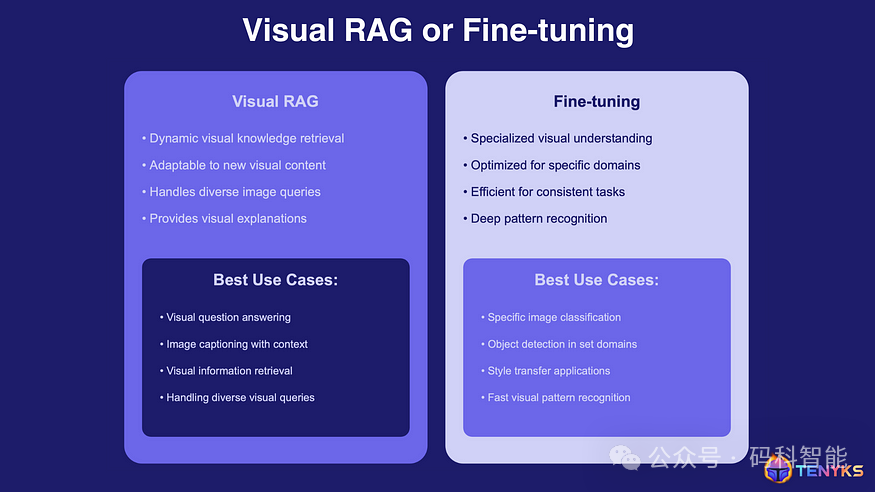
图 4. 何时使用 RAG 而不是微调
在生产中构建视觉系统时,一个常见的问题是在 RAG 和微调之间做出选择 [7]。根据经验,RAG 是一种理想的入门策略。之后,如果模型的任务变得太狭窄或太具体,那么下一步可能是进行微调。但如图 4 所示,答案不是二元的,而是取决于许多因素,例如:
-
预算:微调涉及重新训练模型,这更加昂贵。
-
推理: RAG 在推理过程中需要更多的计算。
-
时间:由于权重已更新,微调在开始时需要投入更多的时间,但从长远来看可能会减少时间投入。
对于某些用例,可以结合使用这两种方法:
-
具有核心任务的不断发展的领域:例如,在医学成像领域,有标准的诊断程序(通过微调处理),但也有快速发展的研究和新的案例研究(由 Visual RAG 处理)。
-
电子商务和产品识别:微调模型可以识别产品类别,而 Visual RAG 可以从动态库存中检索最新的产品信息或类似物品。
-
内容审核系统:微调可以处理常见的违规类型,而 Visual RAG 可以适应新兴趋势或与上下文相关的违规行为。
3. 多模态 RAG
3.1 用于视频理解的多模态视觉 RAG
用于视频理解的多模态 Visual RAG 管道的具体实现(如图 5 所示)。此示例演示了这些技术如何协同工作以从视频数据中提取有意义的见解。
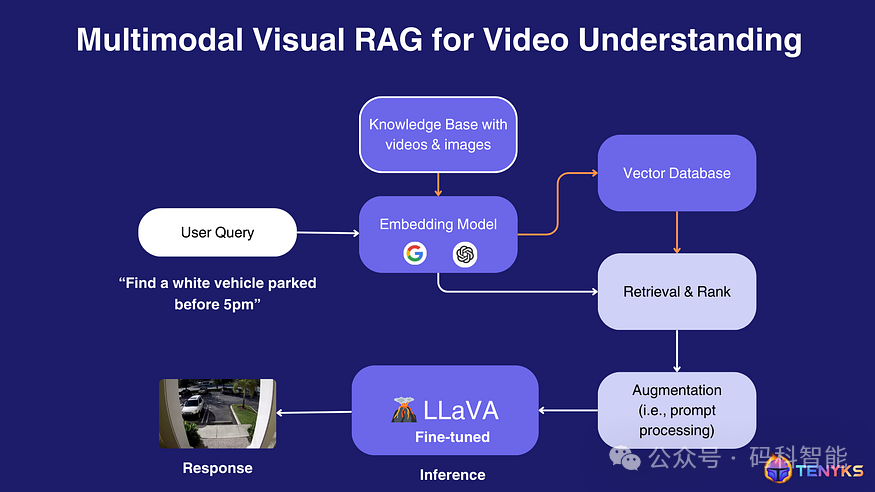
图 5. Visual RAG 应用于视频理解系统
来分解一下系统组件及其相互作用:
-
1. 知识库:系统从包含视频和图像的知识库开始。这是理解视觉内容的基础。
-
2. 嵌入模型:使用嵌入模型(例如 CLIP(对比语言-图像预训练))将知识库内容和用户查询转换为公共向量空间。这允许对不同模态(文本和视觉数据)进行比较。
-
3. 向量数据库:知识库的嵌入表示存储在向量数据库中,从而实现高效的相似性搜索。
-
4. 用户查询:用户输入查询,例如“查找下午 5 点之前停放的白色车辆”。
-
5. 查询处理:用户的查询经过嵌入模型,转换为与知识库内容相同的向量空间。
-
6. 检索和排序:系统根据查询嵌入和存储嵌入之间的相似性从向量数据库中检索相关信息。然后对结果进行排序以找到最相关的匹配。
-
7. 增强:检索到的信息经过快速处理或增强,以完善上下文并为语言视觉模型做好准备。
-
8. LLaVA 微调: LLaVA(大型语言和视觉助手)的微调版本处理增强信息。LLaVA 是一种能够理解文本和视觉输入的多模态模型。
-
9. 推理: LLaVA 模型对处理后的数据进行推理,以生成解决用户查询的响应。
-
10. 响应:最终输出是一个视觉响应——在本例中,是一张显示一辆停在街道上的白色汽车的图像,这与用户的查询相匹配。
4. 下一步处理
虽然上述的系统为视频理解提供了一个令人印象深刻的框架,但实际上,上图描述的是一个原型。对于生产级 Visual RAG 系统,为了成功部署,应该考虑一些事项:
-
可扩展性:系统必须能够有效地处理大量视频数据和并发用户查询。
-
错误处理和边缘情况:管道应该能够很好地管理视觉内容模糊或查询不清楚的情况。
5. 参考文献
[1] Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
[2] Large Language Models for Information Retrieval: A Survey
[3] Exploring Visual Prompts for Adapting Large-Scale Models
[4] An embarrassingly simple approach to zero-shot learning
[5] Visual Instruction Tuning
[6] Learning Transferable Visual Models From Natural Language Supervision
[7] Fine-tuning Language Models for Factuality
[8] Written by The Tenyks Blogger
如何系统的去学习大模型LLM ?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高
针对所有自学遇到困难的同学们,我帮大家系统梳理大模型学习脉络,将这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓
👉[CSDN大礼包🎁:全网最全《LLM大模型入门+进阶学习资源包》免费分享(安全链接,放心点击)]()👈
















 749
749

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}