






一直以来,“RAG派”与“长上下文派”之间争论不休,然而二者各有优劣,如何选择?最佳答案来了:拒绝选择,全都要。今天实操一种GLM-4-Long加持的RAG新方法(金融领域研报数据),旨在实现更简洁架构,更精准、更全面的问题解答。
GLM-4-Long加持的RAG(参考LongRAG)
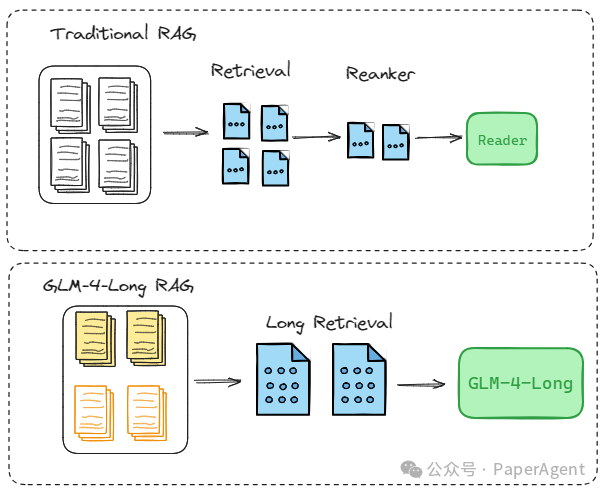
一、更简
GLM-4-Long加持的RAG框架通过简化设计,显著提升了效率。它由以下几个核心组件构成:
-
长检索单元:使用整个文档库或将多个相关文档组合成长检索单元,例如32K个token
-
长检索器:负责从大量文本中检索出与问题粗略相关的长文本单元,数量不用太多
-
长阅读器GLM-4-Long:处理检索到的长文本,提取和生成答案,最大支持1M上下文(约150-200万字),大约相当于2本红楼梦或者125篇论文
这种设计大大减轻了传统RAG中检索器的负担,因为它不再需要在海量的短文本中寻找答案,而是在较少的长文本单元中进行操作。
尽管“长阅读器”在处理长文本时可能会带来计算成本问题,GLM-4-Long以其极具竞争力的价格优势解决了这一难题:仅需0.001元/千tokens,使得即便是超长文本的处理也变得经济高效。
pip install --upgrade zhipuai
from zhipuai import ZhipuAI
client = ZhipuAI(api_key="") # 填写您自己的APIKey
response = client.chat.completions.create( model="glm-4-long", # 填写需要调用的模型编码
messages=[
{"role": "user", "content": "作为一名营销专家,请为智谱开放平台创作一个吸引人的slogan"},
{"role": "assistant", "content": "当然,为了创作一个吸引人的slogan,请告诉我一些关于您产品的信息"}
],
)
print(response.choices[0].message)
二、更准
GLM-4-Long加持的RAG在回答问题时表现出更高的准确性。利用GLM-4-Long接口,模型能够:
-
精确定位:在大量信息中精确找到与问题直接相关的内容。
-
深度理解:对长文本进行深入分析,确保答案的准确性。
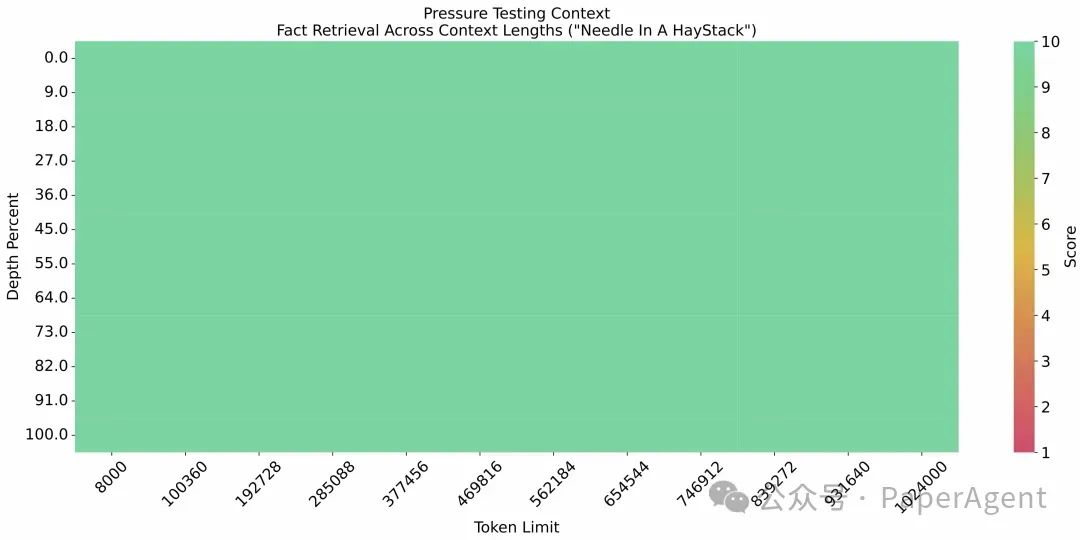
GLM-4-Long大海捞针效果
【案例说明】
检索粒度:Passage
以研报文件“中泰证券-贵州茅台(600519)茅台系列酒面面观2:多大单品蓄势待发,产能推动放量在即.pdf”,query=“茅台酱香系列酒加速增长的三大支撑?”为例:
GLM-4-Long RAG效果**:准确的回答出了三大支撑的内容-“战略支撑、产能支撑、现状支撑**”,而且回答的很有深度。

Traditional RAG效果:答案不正确,“市场与营销策略支撑”是编造出来的结果。****

原因是Traditional RAG会把“三大支撑”完整内容切分成多个小chunk(1.5K长度),检索召回的内容不完整导致。



三、更全
GLM-4-Long加持的RAG在全面性方面也表现出色。通过GLM-4-Long接口,模型能够:
-
全面分析:对检索到的长文本进行全面分析,确保答案覆盖所有相关信息。
-
多角度回答:从不同角度审视问题,提供更全面的答案。
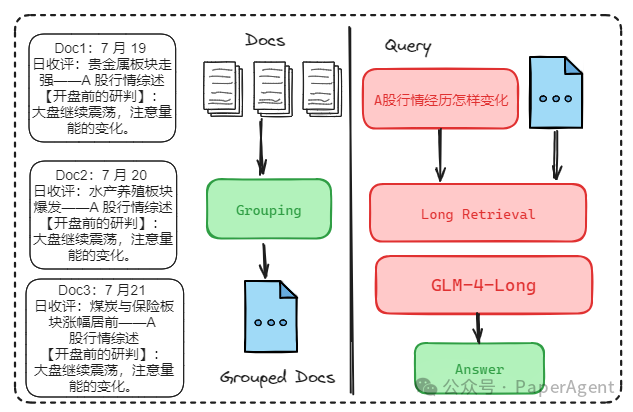
【案例说明】
检索粒度:Grouped Documents
以6天的A股市场行情研报为例:“7 月 19 日收评:贵金属板块走强.pdf”、“8月24日收评:水产养殖板块爆发.pdf”…“10月12日收评:能源金属板块大涨.pdf”,query=“A股行情经历了怎样的变化”为例。
GLM-4-Long RAG效果:包含了所有6天A股行情的数据,答案全面。

Traditional RAG效果:答案只包含3天A股行情数据,不全面。

读者福利:如果大家对大模型感兴趣,这套大模型学习资料一定对你有用
对于0基础小白入门:
如果你是零基础小白,想快速入门大模型是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
包括:大模型学习线路汇总、学习阶段,大模型实战案例,大模型学习视频,人工智能、机器学习、大模型书籍PDF。带你从零基础系统性的学好大模型!
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

👉AI大模型学习路线汇总👈
大模型学习路线图,整体分为7个大的阶段:(全套教程文末领取哈)

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
👉大模型实战案例👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉大模型视频和PDF合集👈
观看零基础学习书籍和视频,看书籍和视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。


👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓
















 11万+
11万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









