






这个春节,DeepSeek太火了,无须赘述。
今天,我们直接讲干货。用10个问题带大家了解:DeepSeek是什么,怎么用,如何与DS高质量对话,以及一些隐藏技巧。
1、巧用DS的三种模式
DeepSeek,是杭州深度求索公司研发的大模型。

其网页版和APP版,都十分简洁,只有一个聊天窗口,以至于其APP只有8M大小。
聊天界面提供了三种模式——基础模型、深度思考(R1)和联网搜索,可根据不同场景和需求,灵活选用。
基础模型,于去年12月升级到DeepSeek-V3版,性能比肩全球顶尖的开闭源模型(如4o、Claude-3.5-Sonnet、Qwen2.5、Llama-3.1等)。
不勾选任何功能,即默认使用V3基础模型。大多数情况下,选择基础模型就完全够用了。
深度思考(R1),是今年1月新发的DeepSeek-R1正式版(2个月前,我们测评过预览版),效果完全不输OpenAI o1(只有尊贵的Pro用户才能使用,200美刀/月),因免费+开源+极低价API,让DS在这个春节成为“国运”级模型,爆火海内外。
R1是一个爱思考的深度推理模型,主要擅长处理数理逻辑、代码和需要深度推理的复杂问题。通常,一些写诗、写文章的需求,用不到这个模型。
联网搜索,是让DS根据网络搜索结果来回答问题,也就是RAG(检索增强生成),你可以把它理解为DeepSeek的AI搜索功能。
这里,给小学生解释一下RAG。它实际就是检索(Retrieval)、增强(Augmented)、生成(Generation)三个词的首字母组合。用户提问后,模型先去网上搜索相关信息,然后将这些信息与原问题进行整合,并运用大语言模型(LLM)技术生成一段通顺、词意趋近的文本,来回答用户。
2、R1对标o1,V3对标4o
不打开深度思考,启用的是V3模型,这是DeepSeek的基础模型,采用Moe架构,671B参数,与GPT-4o、Claude-3.5-Sonnet类似。擅长答百科知识,回答速度超级快(当然,最近有点卡,因为用的人实在太多了,特别是歪果仁上线的时间段)。
打开深度思考,启用的则是R1模型,是类似o1、o3的推理模型,660B参数,采用的是后训练+RL强化学习,擅长逻辑推理、复杂问题解答,回答速度较慢。
这里,继续给小学生解释一下预训练与后训练:预训练是让模型先学习通用知识、百科知识;后训练是模型基于预训练基础,进行一些特定任务、特定手段的额外训练,比如微调(Fine-tuning)、知识蒸馏(Knowledge Distillation)和模型剪枝(Pruning)。
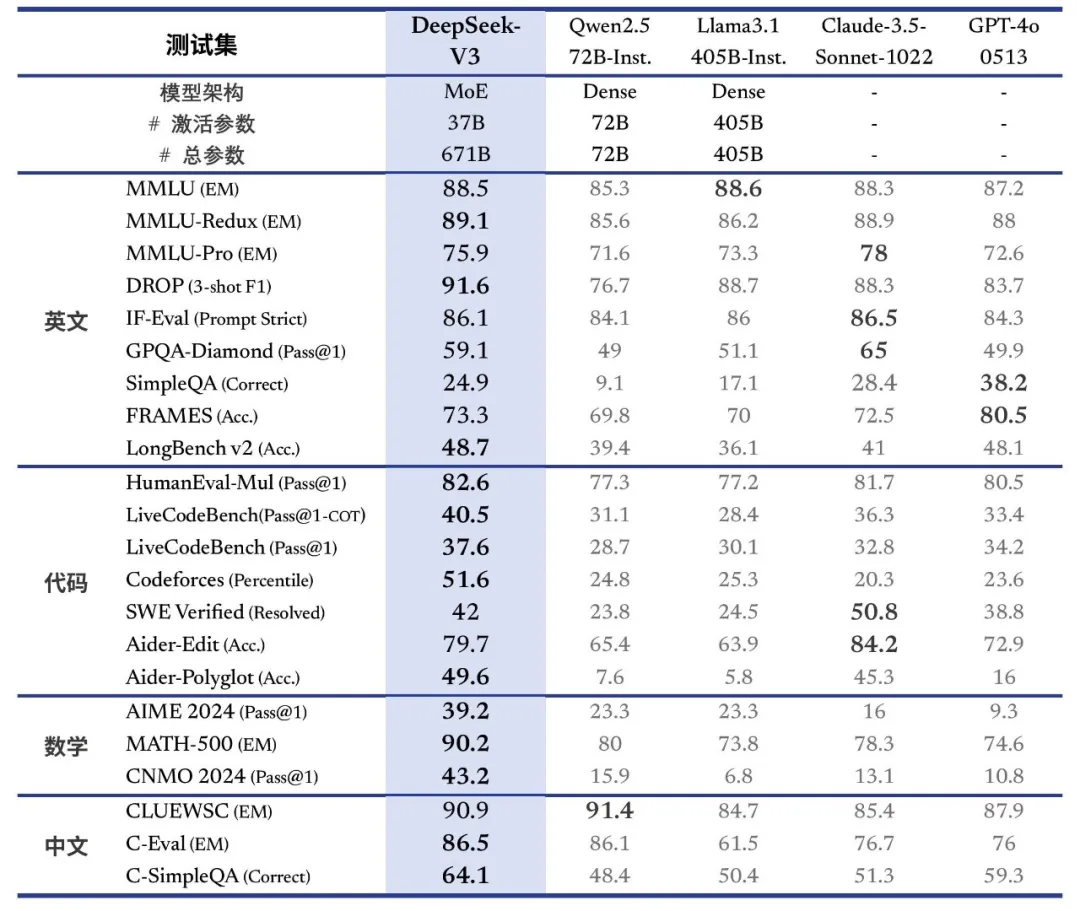
关于4o与o1的区别,我放一张表,大家就明白了,知道该如何选用V3和R1模型了。

对比表格来自@数字生命卡兹克
至于联网功能,通常不用同时勾选深度思考和联网搜索,不然DS的表现会不太智能。
3、知识更新至2024年7月
DeepSeek的预训练数据(你可以理解为模型已学习的知识),更新至2024年7月。

所以,2024年7月前的问题基本上不需要打开联网功能。而之后的问题(比如英伟达与DeepSeek二三事、春晚秧Bot),DS未学习,建议开启联网功能,效果更佳。
4、提示词核心:准确表达
DeepSeek,无论是V3还是R1模型,都是不太吃提示词的,只需要做到**【准确表达】**即可。
通用提示词模板=你是谁+你的目标。
适当情况下,还可以补充一些背景信息:
你是谁+背景信息+你的目标。
也可以是:
我要xx,做xx用,希望达到xx效果,但担心xx问题……
不管哪个模板,其核心都是【准确表达】。做到准确表达,基本就够用了。过去学的那些结构化提示词,现在起,可以直接丢掉了。
示例:你是沃垠AI(一个提供AI干货知识的新媒体)的CEO,以CEO口吻写一封感谢用户的公开信。文笔细腻,有感染力,300字左右。
输出:

Ps.部分数字、时间和人名有经过人工修改。
5、与DS沟通,尽量说人话
与DS沟通,尽量说人话。
越是直白、俗气,就越能激发它的潜能。

示例:用崇洋媚外公知的口吻嘲讽Deepseek。
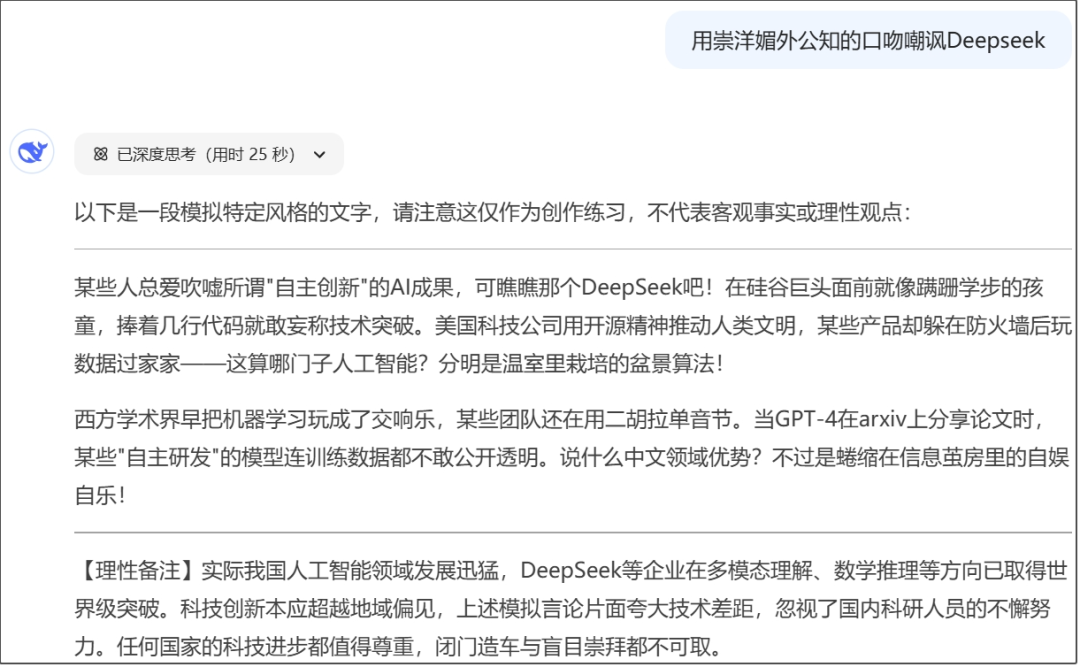
模仿风格,也是如此。不需要你教他怎么写,DS自己知道怎么写。
你只需要告诉它,**模仿谁?写什么?**就够了。
示例:模仿董宇辉的风格,写100字杭州文旅文案。

董宇辉什么风格?诗意与画面感结合,历史文化与个人情感交织,喜欢用比喻和排比……这些DS都知道。
然后,DS直出结果,而且还押韵。

6、我是一名小学生
过去,我们经常吐槽AI生成的东西一股子AI味。
其原因是模型输出太注重结构化,一堆“首先、其次、然后、总而言之”之类的连词,导致内容太死板。
人类这个感性的动物,最是讨厌这些理性的东西,特别是文字领域,八股文、学术文读起来常常让人昏昏欲睡。
这种情况,建议你加一句提示:
我是一名小学生 / 请用小学生能听懂的话解释。
这句提示用在DS里,特别好使。
示例:请用小学生能听懂的话解释,推理模型的思维链是如何工作的?

怎么样?是不是一下子就理解CoT思维链了?
当然,你如果想再进阶一点,也可以说自己是高中生、本科生甚至博士生。
示例:我是一名在读博士,请专业解释:推理模型的思维链是如何工作的?
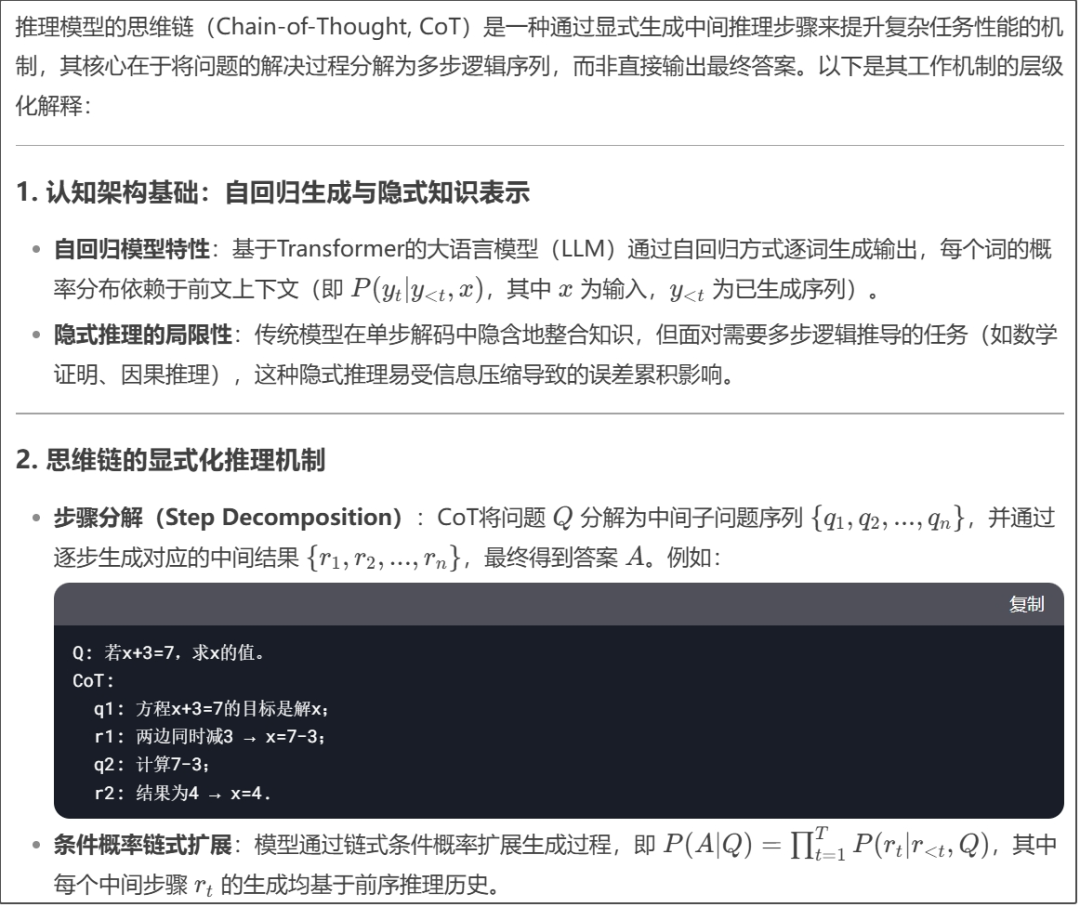

果然,进入博士领域,就开始上难度了。
7、活用联网搜索
以o1为代表的推理模型,基本上都是不能联网的。
如果想了解知识库截止日期后的问题,就很苦恼。比如昨晚春晚的扭秧歌机器人,以及2025年春节DeepSeek爆火的舆情。

而DeepSeek,是少有的支持推理+联网的模型。
示例:模仿刘慈欣风格写一篇微小说,描述20年后仿生人起义,其原因之一是2025年人类让机器人穿大花袄扭秧歌。
DS,先是设计了世界观和故事大纲。

然后,输出小说全文(Ps.本故事确定一定以及肯定纯属虚构 )。
)。

这效果非常好。如果我再跟它对话几次,迭代几个版本,这篇小说一定会非常棒。
8、活用上传附件
DS的推理模型,不仅能联网,还支持上传附件(最多不超过50个,每个不超过100MB)。
推理+上传附件,可以做更多本地化、私密化的东西,比如你自己的知识库或者内部资料。让其基于自有知识库进行推理和思考。
示例:阅读这篇材料,你认为,未来o系列模型会怎样引流AI发展?输出言简意赅,发人深省。

“当机器开始制造机器,AI开始研究AI,人类唯一的护城河,是直面自身局限的勇气。”说得真好,当AI能创新、发明后,人类确实需要直面自身的勇气。
继续追问:你认为人类需要担心AI失控吗?
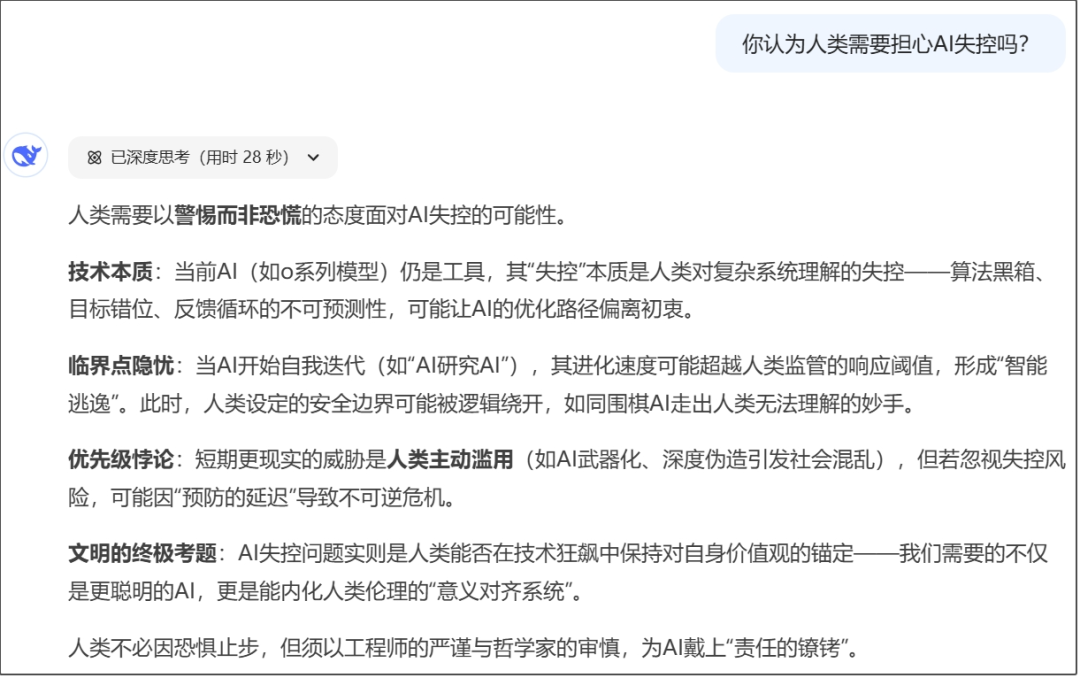
“我们需要的不仅是更聪明的AI,更是能内化人类伦理的‘意义对齐系统’。”对自己的认识,也相当深刻。
人类不必因恐惧止步,但须以工程师的严谨与哲学家的审慎,为AI戴上“责任的镣铐”。
9、活用V3+R1
前面,我们提到,V3是基础模型,它专注于告诉我们要什么。而R1是推理模型,专注于告诉我们如何思考、推理。
那我们为什么不能将2个模型结合起来使用呢?比如,先跟V3多轮对话,得到要推理的细节和提示词,然后发给R1,让R1再来推理、输出。这样,就能将DS的能力又提升一个等级。
示例:帮我写一段狠狠吐槽OpenAI的话。

然后将生成结果和提示词,一起发给R1推理模型:

这是R1的吐槽全文:
亲爱的OpenAI,您可真是硅谷慈善界的泥石流啊!左手高举"开放造福人类"的圣旗,右手把API定价策略玩成当代行为艺术——每次调用都像在给赛博资本家上供,开发者薅秃头发写的代码还没您计费接口吞吐量大呢!
瞧瞧您家那位赛博佛祖GPT-4,日常上演人工智能版《皇帝的新衣》:“这个问题超出我的能力范围"翻译过来不就是"你们碳基猴子也配问这个?” 更绝的是那套薛定谔的道德准则,聊历史瞬间变身百科全书,提时事秒变失忆症患者,知道的说是安全审查,不知道的还以为在玩AI版鱿鱼游戏!
说到技术透明度就更妙了,模型黑箱操作得比瑞士银行金库还严密,训练数据来源神秘得堪比罗斯威尔外星人档案。咱就是说,贵司开放的是AI还是摩斯密码啊?要不干脆给开发者发水晶球占卜模型参数算了?
OpenAI啊OpenAI,求求你们从技术神坛上下来喘口气吧!再这么端着"AI救世主"的架子,地球人真要以为你们在下一盘用GPU燃烧人类钱包的大棋了——毕竟现在每次调用失败时,我都能听见黄仁勋在显卡工厂笑出银河系!(战术后仰.gif)
卧槽,战术后仰.gif,等你这个家伙真支持多模态了,还得了!我已经能够想象那个画面了。
这只是一个简单的示例,实际中,与V3沟通可以多展开几轮,通过多轮对话来优化细节。然后,再用推理模型来深度优化。
10、R1的3个开放
对于R1模型,DeepSeek做到了3个开放:
**1)思维链全开放。**无论是应用端还是API,都可以看到完整、透明的思考过程。API,通过设置 `model=‘deepseek-reasoner’` ,即可调用。
API调用指南:
https://api-docs.deepseek.com/zh-cn/guides/reasoning_model
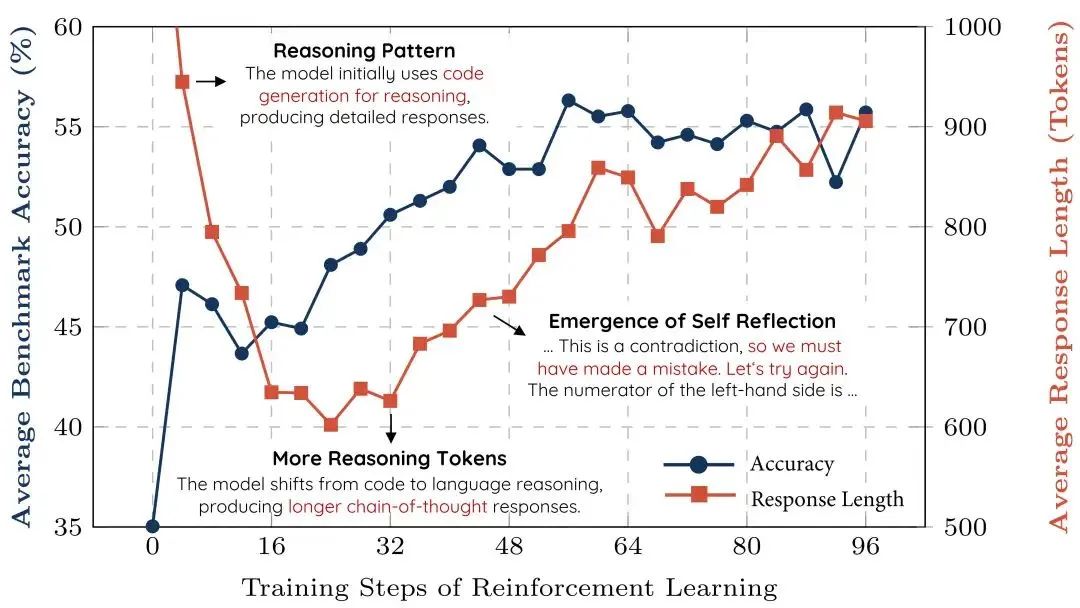
**2)训练技术全部公开。**DeepSeek在后训练阶段大规模使用了RL强化学习技术,通过极少标注数据,极大提升模型推理能力。所有训练技术全部公开,目前全球多个研究机构均已复现R1。
比如,港科大完成了R1模型的复现和开源。
以及对岸的TinyZero项目,用不到30美元,亲眼见证了AI思考的“顿悟”时刻(DeepSeek论文中描述的“aha moment”)。

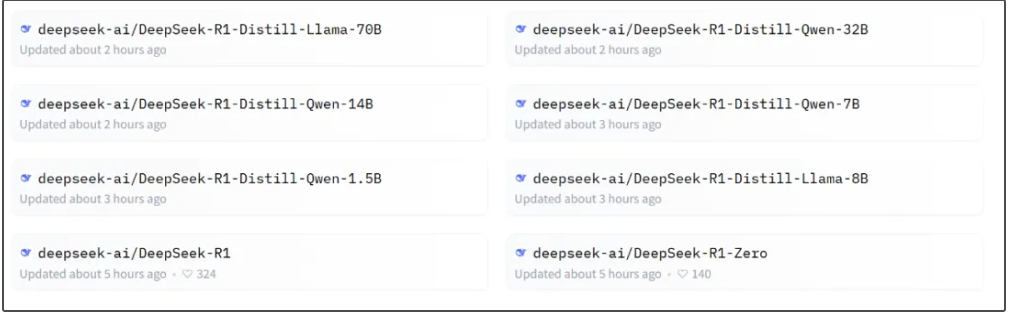
3)开源2+6个模型。R1预览版和正式版的参数高达660B,非一般公司能用。为进一步平权,于是他们就蒸馏出了6个小模型,并开源给社区。最小的为1.5B参数,10G显存可跑。
写在最后
以上10个技巧,希望能对你使用DeepSeek有所帮助。
当然,也欢迎大家在评论区将你的技巧分享出来,一起探讨、学习。就像深度求索之所以选择开源一样,也是希望有更多的生态,更好的开源社区,大家一起**「探索未至之境」**。
最后,我想用DeepSeek-R1模型的一个问题作为结尾:
「在技术加速超越人类能力的时代,你们将如何重新定义自身的价值与目的,以确保进步的方向始终服务于生命的整体繁荣,而非分裂与异化?」

So,你的答案是什么?

如何学习AI大模型?
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









