






1
摘要
LLMs的快速扩展暴露了当前硬件架构在内存容量、计算效率和互连带宽方面的关键局限性。
在2048块NVIDIA H800 GPU 上训练的DeepSeek-V3展示了硬件感知的模型协同设计如何有效应对这些挑战,实现经济高效的大规模训练和推理。
本文对DeepSeek-V3/R1模型架构及其AI基础设施进行了深入分析,重点介绍了关键创新,如用于提高内存效率的MLA、用于优化计算-通信权衡的MoE架构、释放硬件能力的 FP8 混合精度训练,以及最小化集群级网络开销的多平面网络拓扑。
基于DeepSeek-V3开发过程中遇到的硬件瓶颈,与学术界和工业界同行广泛讨论了未来可能的硬件发展方向,包括精准低精度计算单元、Scale-Up与Scale-Out收敛架构,以及低延迟通信结构的创新。
这些见解强调了硬件与模型协同设计在满足 AI 工作负载不断增长的需求中的关键作用,为下一代 AI 系统的创新提供了实用蓝图。
2
背景
近年来,在模型设计、计算能力和数据可用性的迭代进步推动下,LLMs经历了快速发展。
2024 年,GPT4o、LLaMA-3、Claude 3.5 Sonnet等突破性模型展现了显著进展,进一步缩小了与AGI的差距。
根据Scaling Laws,增加模型规模、训练数据和计算资源可显著提升模型性能,凸显了扩展在推进 AI 能力中的关键作用。
随着推理模型(如 OpenAI 的 o1/o3 系列、DeepSeek-R1)的发展,提升推理效率(尤其是处理长上下文和深度推理)的需求日益迫切,这对计算资源提出了更高要求。
尽管阿里巴巴、谷歌等行业领导者部署了包含数万GPU/TPU的巨型训练集群,但高昂成本对小型团队构成了障碍。
开源初创公司如 DeepSeek 通过有效的软硬件协同设计,证明了低成本训练大型模型的可行性。
DeepSeek-V3 凭借 2048 块 NVIDIA H800 GPU 实现了先进性能,其实践和见解展示了如何充分利用现有硬件资源,为更广泛的 AI 和高性能计算(HPC)社区提供了宝贵经验
3
贡献
-
硬件驱动的模型设计:分析FP8低精度计算和Scale-Up/Scale-Out网络特性如何影响DeepSeek-V3的架构选择。
-
硬件与模型的相互依赖:研究硬件能力如何推动模型创新,以及LLMs不断演变的需求如何驱动下一代硬件的发展。
-
未来硬件发展方向:从DeepSeek-V3的实践中提炼见解,指导未来硬件与模型架构的协同设计,构建可扩展、经济高效的AI系统。
4
DeepSeek模型设计原则
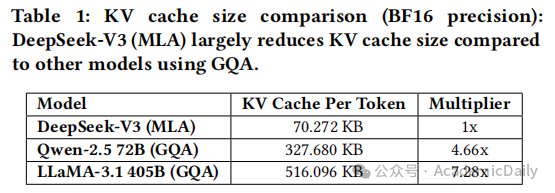
MLA:通过投影矩阵将多头注意力的KV缓存压缩为低维潜在向量,显著减少内存消耗。
例如,DeepSeek-V3的KV缓存仅为70 KB/token
远低于 LLaMA-3.1(516 KB/token)和 Qwen-2.5(327KB/token)(表 1)。
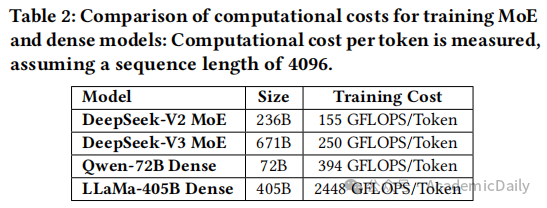
DeepSeek MoE:通过选择性激活专家参数降低计算成本。
DeepSeek-V3包含6710亿参数,但每token仅激活 370 亿参数,训练成本为 250 GFLOPS/Token,仅为同规模稠密模型的 10%(见表 2)。
FP8混合精度训练:权重和激活采用 FP8 精度,内存占用减半,计算效率提升,同时通过精细量化策略(如 1x128 分块量化)确保精度损失低于 0.25%。
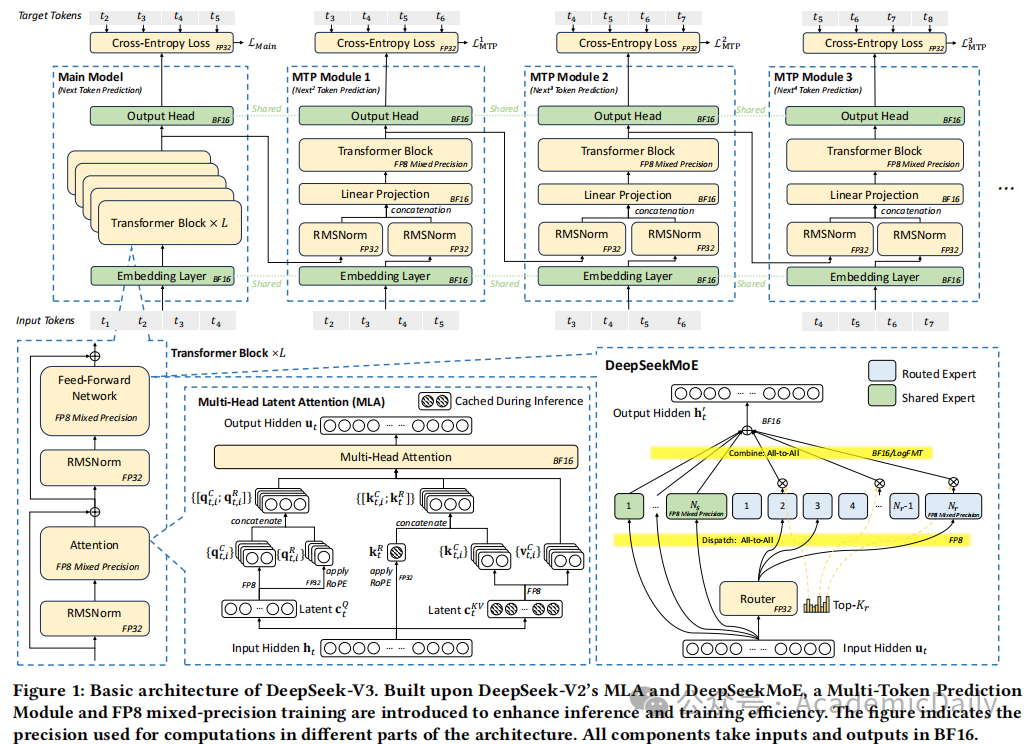
MTP:通过并行生成多个候选tokens(如预测未来2-3个tokens),推理速度提升1.8倍,生成吞吐量达 20 tokens/秒(见图 1 顶部结构)。
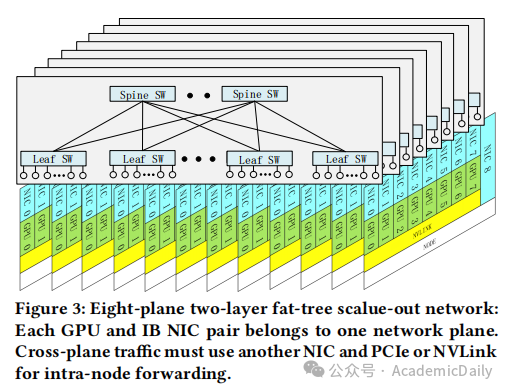
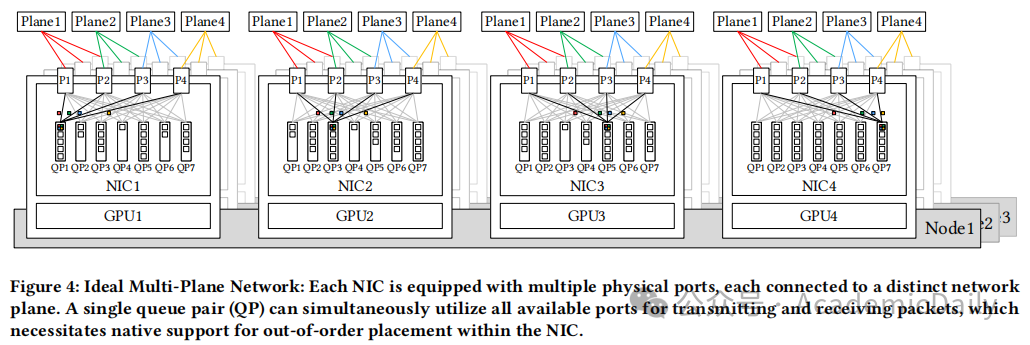
多平面两层 Fat-Tree 网络:替代传统三层拓扑,节点配备8个400G IB NIC,支持16384 GPU扩展,成本降低 50%,延迟减少 30%(见图 3、图 4)。
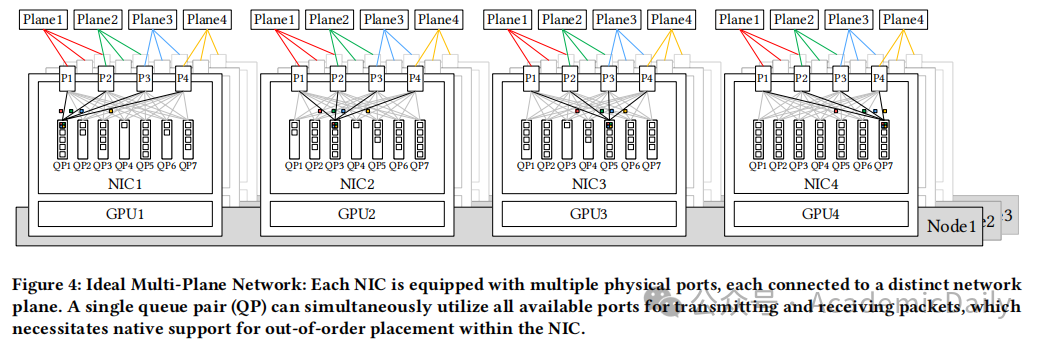
5
低精度驱动设计
5.1 FP8 混合精度训练
实现与优化:开发了兼容MoE模型的FP8训练框架,采用精细量化(权重128x128分块量化,激活1x128 分块量化),并开源FP8 GEMM实现(DeepGEMM)。
局限性:
-
FP8 累加精度不足:NVIDIA Hopper GPU的Tensor Core仅支持FP22累加,可能影响训练稳定性。
-
精细量化开销:分块量化导致数据搬运开销增加,降低计算效率。
-
优化建议:硬件应支持更高累加精度或可配置精度,并原生支持精细量化以减少数据搬运。
5.2 LogFMT 通信压缩
技术特性:采用LogFMT压缩激活值,在相同比特宽度下精度高于 FP8,但因 GPU 带宽限制和编解码开销未最终部署。
建议方向:未来硬件应集成原生压缩/解压缩单元,支持 FP8 或自定义精度格式,以减少通信带宽需求。
6
互联驱动设计
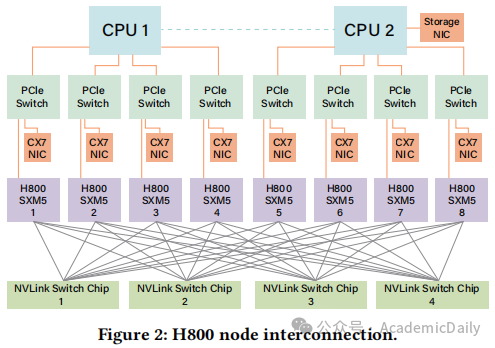
6.1 当前硬件架构(图 2)
架构特点:基于NVIDIA H800 GPU(Hopper 架构),采用SXM互联,单节点配备8块GPU和8个400Gbps IB CX7 NIC,NVLink带宽降至 400GB/s,依赖 IB 实现节点间扩展。
瓶颈:Scale-Up与Scale-Out带宽失衡,GPU的SM资源需兼顾计算与通信任务,影响效率。
6.2 硬件感知的并行策略
并行优化:
TP:训练阶段因 NVLink 带宽限制禁用 TP,推理阶段选择性使用以降低延迟。
PP:通过 DualPipe 技术重叠注意力/MoE计算与通信,减少流水线气泡。
EP优化:利用 8 个 IB NIC 实现超 40GB/s 全到全通信,开源 DeepEP 库提升 EP 效率。
6.3 节点限制路由策略
设计目标:平衡节点内(NVLink)与节点间(IB)带宽利用,减少跨节点通信开销。
实现方式:将 256 个专家分组至 8 个节点(32 专家 / 节点),确保单个token最多路由至 4 个节点,通过 NVLink 转发同节点内专家通信,降低 IB 传输次数(通信成本从 8t 降至 Mt,M≤4)。
6.4 Scale-Up 与 Scale-Out 收敛
现有挑战:
SM 资源竞争:H800 GPU 需用 20 个 SM 处理通信任务(如数据转发、类型转换),占用计算资源。
通信任务卸载需求:数据搬运、归约操作依赖 SM,需专用硬件加速。
未来硬件建议:
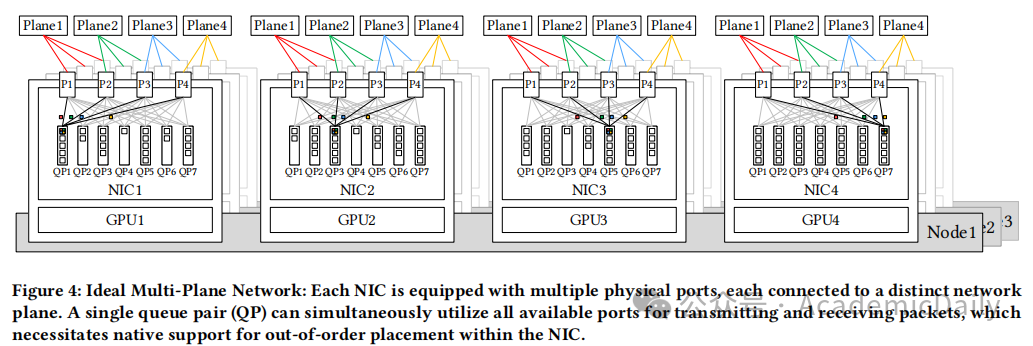
统一网络架构:集成 Scale-Up(NVLink)与 Scale-Out(IB),通过专用协处理器实现动态流量去重(如图 4 理想架构)。
硬件功能增强:支持统一网络适配器、专用通信协处理器及硬件级同步原语。
6.5 带宽竞争与延迟
瓶颈表现:
PCIe 带宽饱和:KV 缓存传输与 IB 通信竞争带宽,导致延迟波动。
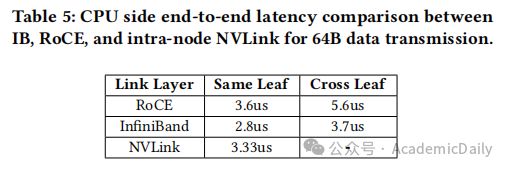
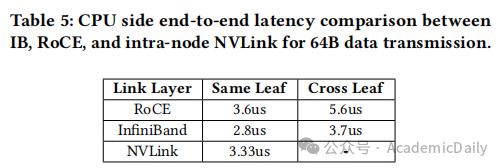
RoCE 局限性:跨叶节点延迟(5.6μs)高于 IB(3.7μs),自适应路由支持不足(表 5)。
优化方向:
动态优先级调度:按流量类型(如 EP、TP)分配 NVLink/PCIe 优先级。
I/O Die 集成:将 NIC 与计算单元通过 NVLink 直连,减少 PCIe 依赖。
7
大规模网络设计
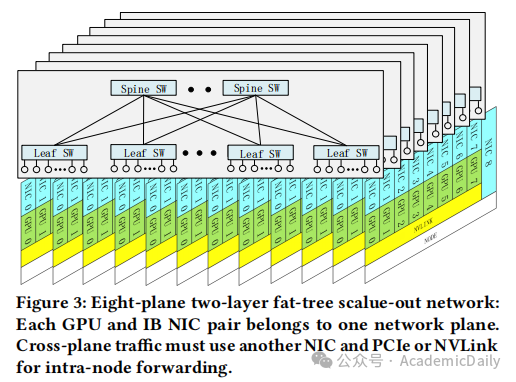
7.1 多平面 Fat-Tree 网络设计(图 3、图 4)
拓扑结构:
采用MPFT,单节点 8 个 GPU-NIC 对分属 8 个网络平面,额外配备存储网络平面。
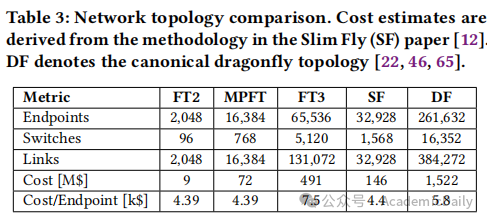
理论支持 16,384 GPU,成本较FT3降低 50% 以上,延迟减少 30%(表 3)。
优势:
成本效率:每节点成本 4.39 千美元,优于SF和DF拓扑(表 3)。
流量隔离:各平面独立运行,避免拥塞扩散,提升稳定性。
性能验证:
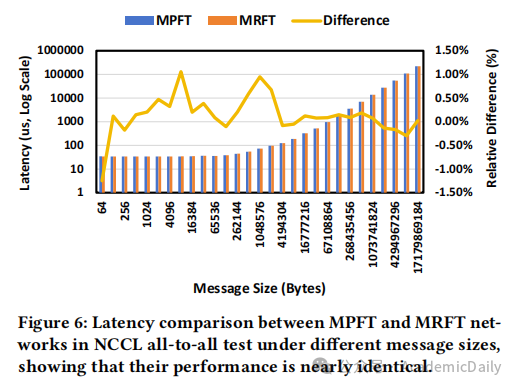
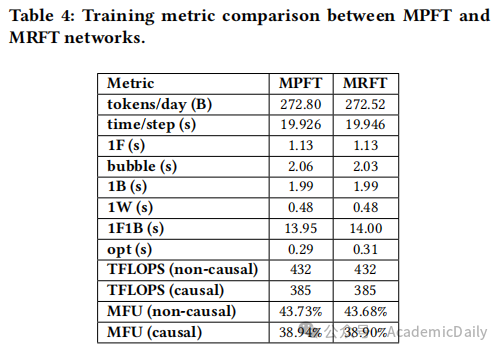
全到全通信性能与单平面MRFT接近,延迟差异<1.5%(图 5、图 6)。

DeepSeek-V3 在 MPFT 上的训练吞吐量与 MRFT 相当,MFU(模型利用率)达 43.73%(表 4)。
7.2 低延迟网络优化
IB 与 RoCE 对比:
IB 优势:延迟更低(跨叶节点 3.7μs vs. RoCE 的 5.6μs,表 5),适合延迟敏感型工作负载。
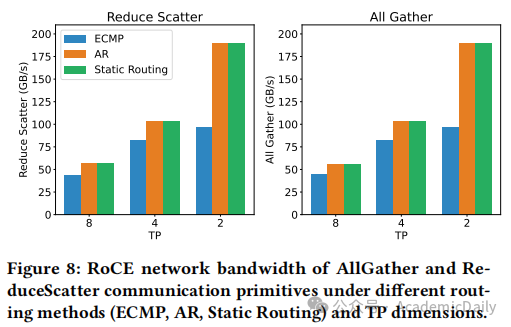
RoCE 挑战:成本低但自适应路由(AR)支持不足,ECMP 路由易导致流量拥塞(图 8)。
优化建议:
RoCE 增强:开发低延迟 RoCE 交换机(如借鉴 Slingshot 架构),支持动态自适应路由和虚拟输出队列。
IBGDA 技术:利用 GPU 直接操作RDMA地址,消除CPU代理线程开销,提升通信效率。
8
未来硬件架构
8.1 鲁棒性挑战
互联故障:IB/NVLink 间歇性断开影响通信密集型任务(如 EP)。
静默数据 corruption:ECC 未检测到的多比特错误可能导致模型质量下降。
解决方案:硬件集成校验和验证、冗余检查,提供诊断工具包检测静默错误。
8.2 CPU 瓶颈与互联优化
瓶颈:
PCIe 带宽限制:CPU-GPU间参数/KV缓存传输易饱和(需1TB/s内存带宽支持)。
单核性能需求:内核启动、网络处理需高频单核(≥4GHz)支持。
优化方向:
采用 NVLink/Infinity Fabric 直连 CPU 与 GPU,替代 PCIe。
提升 DRAM 带宽(如3D堆叠技术),满足高吞吐量需求。
8.3 智能网络技术
关键方向:
CPO:硅光子技术提升带宽并降低功耗。
无损网络与自适应路由:CBFC结合动态路径选择,避免拥塞(如 AR 算法)。
故障容错协议:支持链路层重试、冗余端口快速切换。
8.4 内存语义通信与排序
挑战:
fence操作增加 RTT 延迟,影响吞吐量。
消息语义RDMA的乱序问题需硬件级排序支持。
解决方案:
硬件提供acquire/release语义,通过区域获取/释放(RAR)机制确保数据一致性,减少软件同步开销。
8.5 网络内计算与压缩
优化场景:
EP 调度阶段:硬件支持数据包复制,减少多播通信开销。
EP 合并阶段:网络内聚合优化归约操作。
LogFMT 压缩:硬件原生支持对数浮点格式,提升通信效率。
8.6 内存中心创新
技术路径:
3D 堆叠 DRAM:如 SeDRAM,提供超高速内存带宽(135GBps),缓解 Transformer 的内存墙问题。
SoW:提升计算密度与内存带宽,支持超大规模模型。
9
结论
本文通过 DeepSeek-V3 的实践,揭示了硬件与模型协同设计在应对 LLMs 扩展挑战中的关键作用。
通过MLA、MoE架构、FP8 混合精度训练和多平面网络拓扑等创新,
DeepSeek-V3 在 2048 块 H800 GPU 上实现了高效训练与推理,证明了低成本大规模训练的可行性。
针对当前硬件在内存带宽、互连带宽和计算效率的瓶颈,提出未来硬件应重点发展精准低精度计算单元、Scale-Up/Scale-Out 收敛架构及低延迟智能网络,并强调通过硬件原生支持通信压缩、内存语义排序和故障容错机制提升系统鲁棒性。
这些成果为下一代 AI 系统的软硬件协同创新提供了实用蓝图,有望推动 AI 在复杂场景中的规模化应用。

大模型&AI产品经理如何学习
求大家的点赞和收藏,我花2万买的大模型学习资料免费共享给你们,来看看有哪些东西。
1.学习路线图

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
2.视频教程
网上虽然也有很多的学习资源,但基本上都残缺不全的,这是我自己整理的大模型视频教程,上面路线图的每一个知识点,我都有配套的视频讲解。


(都打包成一块的了,不能一一展开,总共300多集)
因篇幅有限,仅展示部分资料,需要点击下方图片前往获取
3.技术文档和电子书
这里主要整理了大模型相关PDF书籍、行业报告、文档,有几百本,都是目前行业最新的。

4.LLM面试题和面经合集
这里主要整理了行业目前最新的大模型面试题和各种大厂offer面经合集。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集***
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









