








这张图片展示的是Qualcomm Snapdragon 845移动平台的芯片组布局。具体来说:
-
在中心位置有一个大的矩形模块,上面写着“Snapdragon X20 LTE modem”,这指的是高通的X20 LTE调制解调器,它是用于无线通信的组件。
-
在其下方,有一个较小的矩形模块,标记着“Wi-Fi”,这是处理无线网络信号的组件。
-
在左上角,有一个名为“Hexagon 685 DSP”的模块,这是高通的数字信号处理器,用于处理音频和视频信号。
-
在右上角,有一个标有“Adreno 630 Visual Processing Subsystem”的模块,这是高通的图形处理单元(GPU),负责图形渲染和一些计算任务。
-
在左下角,有一个“Aqstic Audio Codec”,这是高通的音频编解码器,用于处理音频输入和输出。
-
在右下角,有一个“Spectra 280 ISP”,这是图像信号处理器,用于处理相机传感器捕获的图像数据。
-
在中心偏下的位置,有一个“Kryo 385 CPU”,这是高通的自研CPU核心。
-
在右方,有一个“System Memory”,这是手机的系统内存。
-
在右下角还有一个“Secure Processing Unit”,这是安全处理单元,用于处理敏感信息和加密任务。
-
整体布局体现了SoC(System on Chip,片上系统)的设计理念,所有这些组件都集成在一个单一的芯片上,提高了效率和节省了空间。

这张图片介绍了数字信号处理(DSP)的一些特点和优势:
-
数字信号处理主要应用于特定的算法,比如点积、卷积和快速傅立叶变换(FFT)等。
-
它的特点是低功耗和高性能,相比移动GPU,DSP在某些特定任务上能够提供更快的速度,同时消耗更少的能量。
-
DSP采用VLIW(Very long instruction word,超长指令字)架构,一条指令可以完成上百次乘累加运算,这使其在处理数学密集型任务时非常有效。
然而,这也带来了一定的挑战:
-
VLIW架构的编程和调试相对困难,因为它要求程序员对硬件有深入的理解来编写高效的代码。
-
编译器的质量参差不齐,可能会对最终的性能产生影响。

这张图片介绍的是可编程阵列(FPGA)的相关内容:
-
FPGA拥有大量的可编程逻辑单元和可配置的连接,可以根据需求配置成不同的电路结构。
-
使用诸如VHDL和Verilog这样的硬件描述语言进行编程。
-
FPGA通常比通用硬件更加高效,因为它们是根据特定应用定制的。
然而,FPGA也有一些缺点:
-
相关工具链的质量参差不齐,可能会影响开发体验。
-
“编译”一个FPGA程序可能需要花费几个小时的时间,因为硬件的配置过程较为复杂且耗时。

这张图片讨论了AI ASIC的主题:
-
AI ASIC是指专门为人工智能(AI)设计的应用特定制(Application-Specific Integrated Circuit)芯片,这是一个深度学习领域的热门方向。
-
许多大公司如Intel, Qualcomm, Google, Amazon, Facebook等都在研发自己的AI芯片。
-
其中Google的TPU(Tensor Processing Unit)是一个标志性产品,它可以与Nvidia GPU相媲美。
-
Google已经在自家服务中大量部署了TPU,例如用于加速其云计算服务中的机器学习任务。
-
TPU的核心是systolic array,这是一种特殊的矩阵计算架构,特别适合于张量处理,也就是深度学习中常见的多维数组操作。
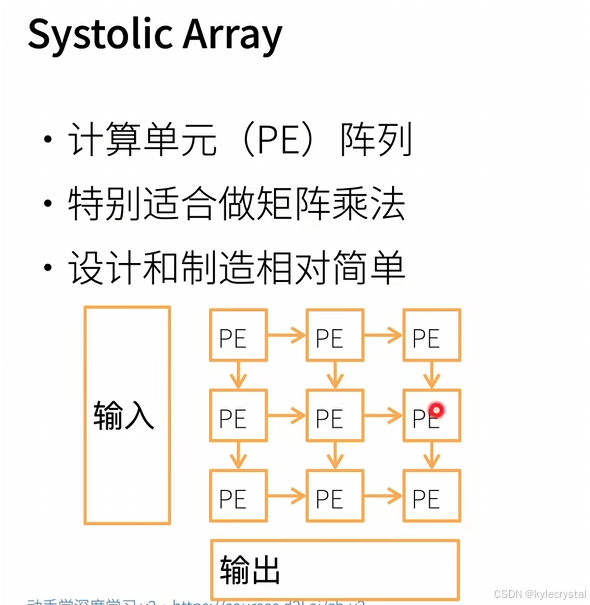
这张图片解释了systolic array的概念:
-
Systolic array是由一系列称为处理元素(Processing Element,PE)的计算单元组成的阵列。
-
这种结构非常适合做矩阵乘法,这是深度学习中常用的运算。
-
设计和制造systolic array相对简单,这也是为什么它成为AI ASIC的一个重要组成部分的原因。
图中显示了一个简单的systolic array示意图,其中每个框代表一个PE,箭头表示数据流的方向。这种结构通过相邻PE间的协同工作实现了高效的矩阵乘法运算。
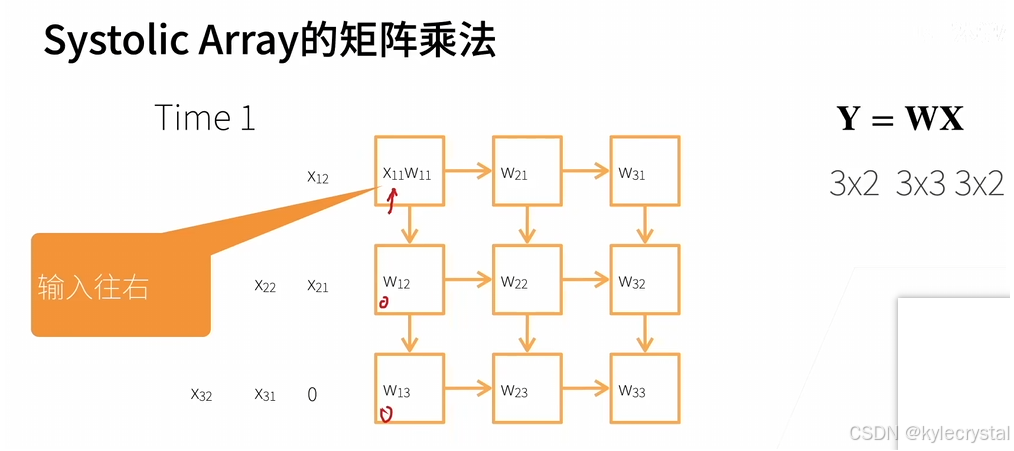
这张图片展示了Systolic Array如何实现矩阵乘法的过程:
-
图中显示了一个3x2的输入矩阵X和一个3x3的权重矩阵W相乘得到一个3x2的结果矩阵Y的过程。
-
时间轴从左至右,首先输入的第一个值X11会与第一行的三个权重W11、W12、W13相乘,然后将结果分别送到下面的PE中。
-
同一时刻,第二个输入值X21会与第二行的三个权重相乘并将结果送入对应的PE。
-
每个PE接收来自上方和左侧的输入,进行乘积累加操作,最后输出到右侧。
-
输入按照箭头指示的方向往右推进,直到所有的输入都被处理完毕。
-
最终,经过多个步骤后,输出矩阵Y会被构建出来,这就是矩阵乘法的基本原理。
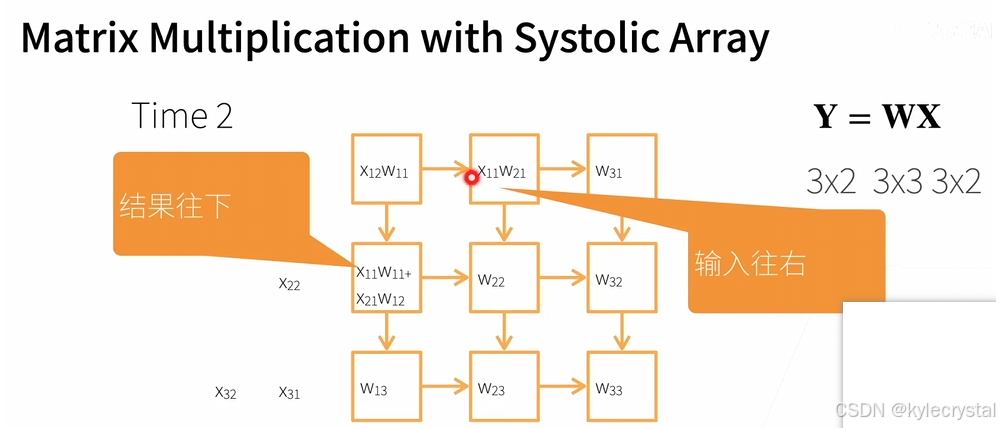
这张图片继续演示了Systolic Array执行矩阵乘法的过程:
-
在时间步2,新的输入X12到达并开始与权重相乘,而之前计算出的部分结果则向下流动。
-
PE之间的数据流是有序的,输入向右传递,结果向下传递。
-
这样,每个PE都可以连续地接收新的输入并产出部分结果,从而高效地完成整个矩阵乘法运算。
-
结果矩阵Y的值会在多个时间步之后逐渐形成,这是由于数据在Systolic Array内部的流动方式决定的。
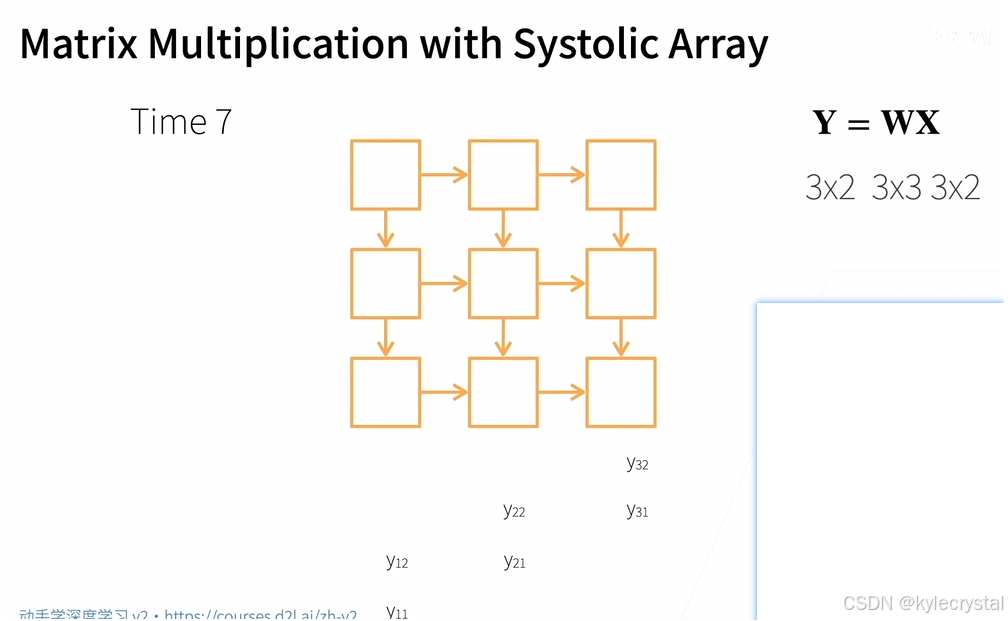
这张图片展示的是使用Systolic Array进行矩阵乘法的第七个时间步:
-
在这个时间步,所有输入都已经经过了Systolic Array,此时输出矩阵Y的值已经完全形成了。
-
输出矩阵Y的各个元素对应着Systolic Array的不同位置,每个位置上的PE都完成了相应的乘积累加操作。
-
这里可以看到,Systolic Array是如何通过流水线的方式逐步计算出矩阵乘法的结果的。
-
这种结构充分利用了硬件资源,并且避免了大量的数据传输,提高了效率。

这张图片进一步说明了Systolic Array在实际应用中的考虑因素:
-
对于一般的矩阵乘法,如果矩阵大小不适合Systolic Array的尺寸,可以通过切分和填充的方法来匹配SA的大小。
-
另外一种优化方法是批量输入,这样可以在一定程度上降低延迟,提高吞吐率。
-
虽然Systolic Array主要用于矩阵乘法,但在神经网络中还有其他的操作子,如激活层,这些通常由额外的硬件单元来处理。
-
这些额外的硬件单元可以与Systolic Array一起构成完整的神经网络加速器,以满足各种计算需求。

















 2198
2198

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









