






何恺明团队再出神作!提出了一种全新的异构预训练Transformer模型,解决了通用机器人模型中异构性难题,性能飙升20%+!
实际上,预训练Transformer是非常重要且热门的方向,诸多领域都离不开它。其通过在大规模语料上进行训练,学习到了丰富的语言知识和模式。具有强大的迁移学习效益和泛化能力,能够快速适应新任务!且相比从头开始训练一个全新的模型,能大大减少训练时间和计算资源。
但也面临模型复杂度较高、训练成本昂贵、应用于特定任务效果不佳等问题。
这些特性,便使得对其的研究成为迫切需求,也给我们的论文创新提供了机会!为方便大家获得更多idea启发,快速发出自己的顶会,我给大家梳理了10种创新思路,还提供了代码!
论文原文+开源代码需要的同学看文末
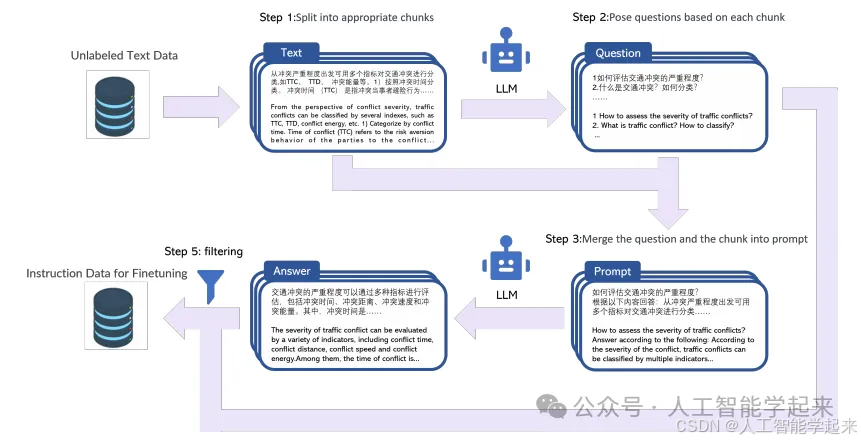
论文:TransGPT: Multi-modal Generative Pre-trained Transformer for Transportation
内容
该论文介绍了TransGPT,这是一个为交通领域设计的多模态大型语言模型,包含两个变体:TransGPT-SM(单模态数据)和TransGPT-MM(多模态数据),它在交通领域的单模态数据集上微调,在多个交通领域的基准数据集上超越了基线模型,推动了交通领域自然语言处理技术的发展。
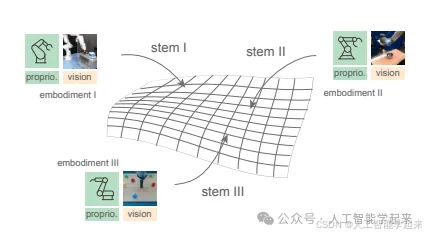
论文:Scaling Proprioceptive-Visual Learning with Heterogeneous Pretrained Transformers
内容
该论文介绍了Heterogeneous Pre-trained Transformers (HPT),这是一个用于机器人学习的框架,它通过在不同硬件和任务的机器人数据上进行异构预训练来学习策略表示,它利用特定的“茎”(stem)将不同机器人的专有感知和视觉信息对齐到共享的“语言”空间,然后通过共享的Transformer“躯干”(trunk)处理这些信息,最终通过任务特定的“头部”(head)输出动作
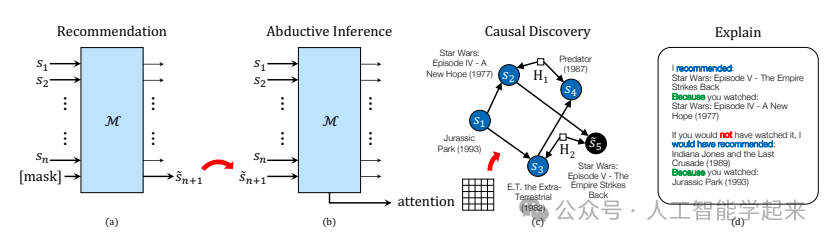
论文:Causal Interpretation of Self-Attention in Pre-Trained Transformers
内容
该论文提出了一种对预训练变换器(Transformer)模型中自注意力机制的因果解释,将其视为估计给定输入符号序列的结构方程模型的机制。该模型可以解释为输入符号在特定上下文中的因果结构,即使在存在潜在混杂因素的情况下也有效,通过计算最深层注意力层中相应表示之间的偏相关性,来估计输入符号之间的条件独立关系,从而使用现有的基于约束的算法学习输入序列上的因果结构。
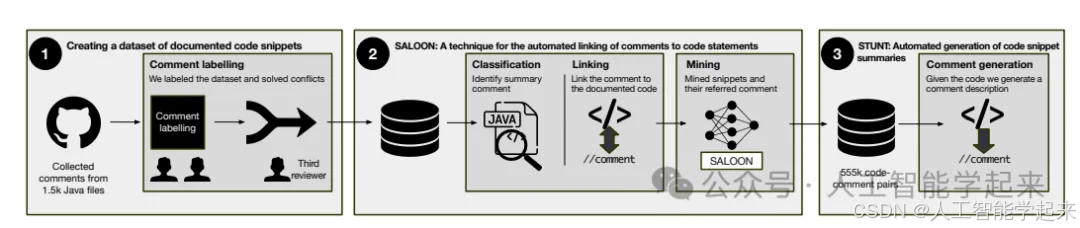
论文:Towards Summarizing Code Snippets Using Pre-Trained Transformers
内容
该论文介绍了一种使用预训练变换器(Transformer)模型来自动总结代码片段的方法,该方法首先手动构建了一个包含6.6k条评论的数据集,这些评论被分类并链接到它们所文档的代码语句,该模型能够识别代码摘要并对评论进行分类,以及将评论链接到相应的代码语句,然后将这个模型应用于10k个项目中,识别并链接代码摘要到文档化的代码,从而构建了一个大规模的数据集,用于训练新的深度学习模型STUNT,能够自动为代码片段生成文档。
关注下方《人工智能学起来》
回复“预训练T”获取全部论文+开源代码
码字不易,欢迎大家点赞评论收藏


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









