






今天给大家推荐一个好发顶会且不卷的方向:强化学习+注意力机制!
随着强化学习的火爆和应用的拓展,其诸多局限也在逐渐显现!而注意力机制的引入,则为克服缺陷,提升模型的决策精准度、加速学习进程、增强鲁棒性和可解释性提供了强大的助力。具体点说即是:注意力机制使智能体能够在复杂环境中聚焦于关键信息,忽略无关或干扰因素。这便使得智能体能作出更加精准的决策,同时也能更快地识别和利用环境中的关键特征,缩短训练时间。
目前在各顶会、顶刊都能看到其身影,光是NeurIPS就有多篇,热度可见一斑!为方便大家研究的进行,我给大家准备了12种前沿创新思路,原文和源码都有,一起来看!
论文原文+开源代码需要的同学看文末
论文:Ensemble-based Deep Reinforcement Learning for Vehicle Routing Problems under Distribution Shift
内容
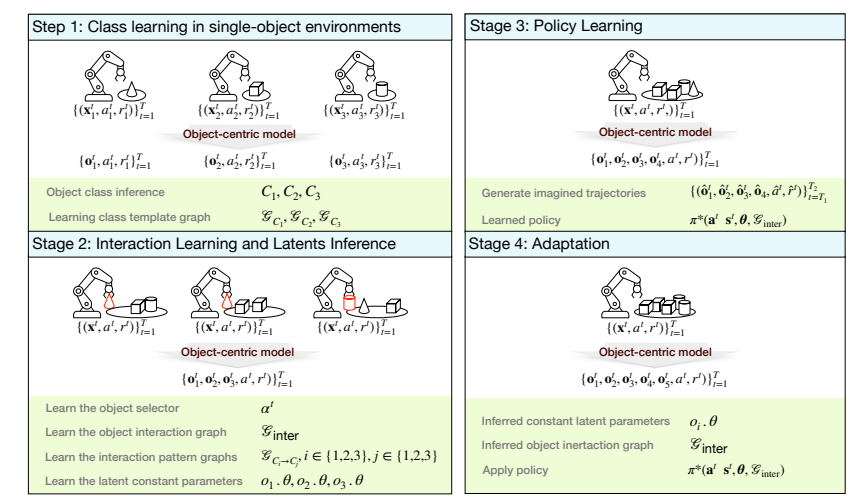
该论文介绍了一种名为动态属性分解强化学习(DAFT-RL)的新框架,旨在提高多物体强化学习任务中的样本效率和泛化能力。DAFT-RL通过学习物体的属性分解表示和动态图来建模物体间的交互,使得学习到的策略能够更好地适应新环境中不同属性和潜在参数的物体组合,以及之前学习任务的组合。
论文:Learning Dynamic Attribute-factored World Models for Efficient Multi-object Reinforcement Learning
内容
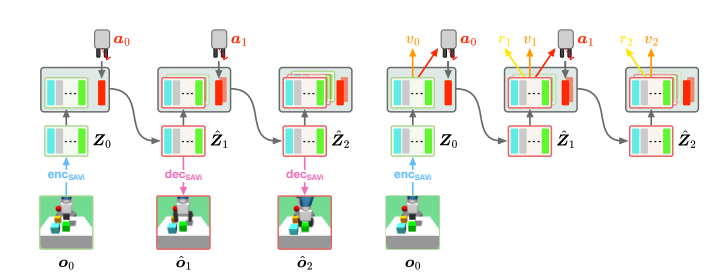
该论文介绍了一种名为SOLD的新型算法,它通过从像素输入中无监督地学习以物体为中心的动态模型来改进基于模型的强化学习。SOLD利用结构化的潜在空间不仅提高了模型的可解释性,还为行为模型提供了有价值的输入空间,使其能够在需要关系推理和低级操作能力的机器人环境中表现优于现有的最先进算法DreamerV3。
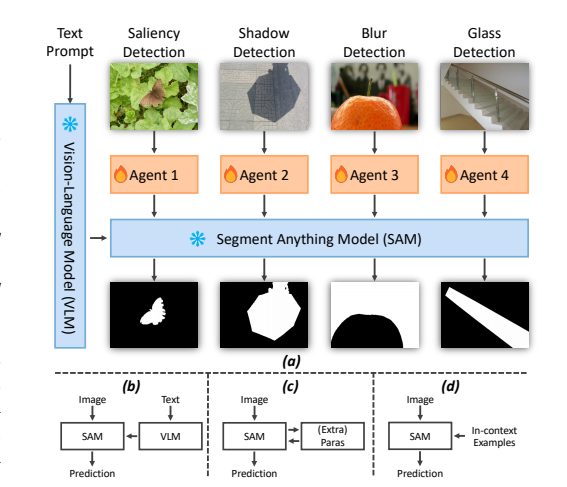
论文:AlignSAM: Aligning Segment Anything Model to Open Context via Reinforcement Learning
内容
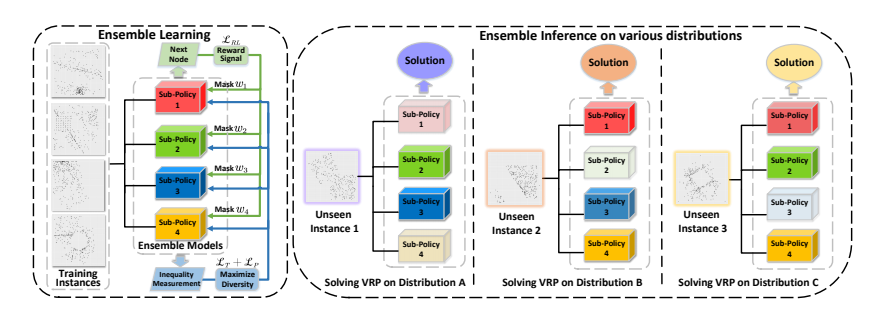
该论文提出了一种基于集成的深度强化学习方法来解决车辆路径问题(VRP),特别是在存在分布偏移的情况下。该方法通过学习一组多样化的子策略来应对不同实例分布,利用Bootstrap和随机初始化来增强子策略之间的多样性,并通过正则化项进一步促进多样性。
论文:SOLD: REINFORCEMENT LEARNING WITH SLOT OBJECT-CENTRIC LATENT DYNAMICS
内容
该论文介绍了一种名为AlignSAM的新框架,旨在通过强化学习自动提示来将Segment Anything Model(SAM)适应于开放上下文中的多样化任务。AlignSAM通过一个代理来与基础模型交互,逐步优化分割预测,并引入了一个语义校准模块来提供精确的提示标签,从而增强模型在处理显式和隐式语义任务时的能力。
关注下方《人工智能学起来》
回复“强化注意”获取全部论文+开源代码
码字不易,欢迎大家点赞评论收藏


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









