







“AI 的 iPhone 时刻到来了”。非算法岗位的研发同学’被迫’学习 AI,产品岗位的同学希望了解 AI。但是,很多自媒体文章要么太严谨、科学,让非科班出身的同学读不懂;要么,写成了科幻文章,很多结论都没有充分的逻辑支撑,是‘滑坡推理’的产物。这篇文章从底层讲起,却不引入太多概念,特别是数学概念,让所有人都能对大模型的核心概念、核心问题建立认知。文章末尾也为需要严肃全面地学习深度学习的人给出了建议。
关于以 ChatGPT 为代表的大语言模型(LLM),相关介绍文章、视频已经很多。算法部分,约定俗成地,还是先来一段贯口。当前我们说的 LLM,一般代指以 ChatGPT 为代表的基于 Generative Pre-trained Transformer 架构的自然语言处理神经网络模型。顾名思义,它是个以预训练技术为核心的模型,是个生成模型。同时它是Transformer这个编码-解码模型的解码部分。
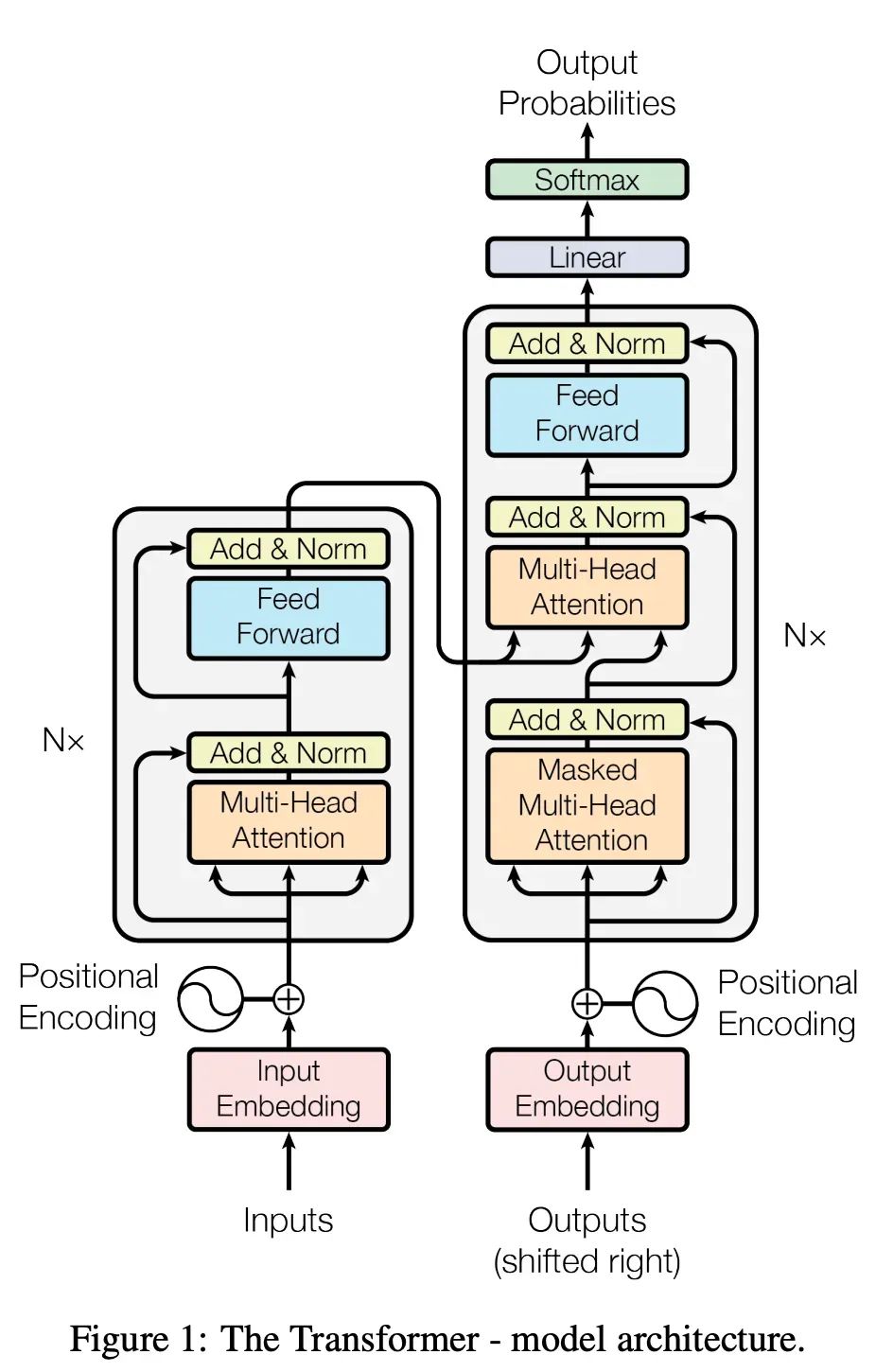
不管你能不能看懂,它就是这张图的右边部分。到了这里,非基础研究、应用研究的同学就开始在听天书了。读这篇文章的这一部分,大家是为了’学到‘知识,而不是为了’被懂算法的同学咬文嚼字扣细节给自己听,被秀一脸,留下自己一脸茫然‘。大家的目标是‘学习’为首,‘准确’为辅。那我就用不嗑细节的‘人话’跟大家讲一讲,什么是自然语言处理大模型。虽然,这些内容就仅仅是’毕业生面试应用研究岗位必须完全答对‘的档次,但是,‘知之为知之,不知为不知,是知也’,大家如果不懂,是应该看一看的。
前排提示,文末有大模型AGI-CSDN独家资料包哦!
1 编解码与表示学习
什么是自编码器(autoencoder,encoder-decoder model)?通俗地说,用拍摄设备,录制视频,录制成了 mp4 文件,就是采集并且 encode;你的手机视频播放器播放这个视频,就是 decode 视频并且播放。做 encode-decode 的模型,就是编码-解码模型。很明显,编码模型和解码模型是两个模型,但是,他们是配对使用的。你不能编码出一个.avi 文件,然后用只支持.mp4 的解码器去解码。
在深度学习领域里,下面这个就是最简单的编码-解码模型示意图。f 函数是编码器,把输入 x 变成某个叫做 h 的东西,g 是解码函数,把编码出来的东西,解码成输出 r。
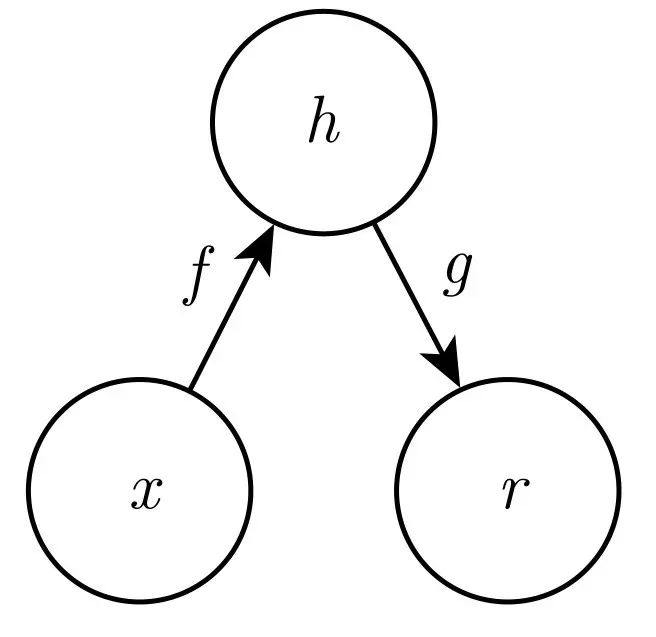
那么,最简单的编码器,就是什么都不干:f(x)=x,h=x,r=g(f(x))=h。输入‘Tom chase Jerry’,输出就是‘Tom chase Jerry’。显然,这样的字编码器不需要训练,并且,也没有任何用处。
如果,输入‘Tom chase Jerry’,输出是‘汤姆追逐杰瑞’,那么这个自编码器就完成了机器翻译的任务。我们人类可以做翻译,实际流程上,也跟这个差不多。那么,我们人类是怎么做到的呢?我们并不是以‘做翻译’为唯一的目标去学习语言的,我们会学习‘单词’、‘语法’、‘语言所表达的常识’这些语言之下最基础的‘特征’的‘表示’。当我们学会了被表达的事物和它在不同语言中的表示之后,我们就能做翻译这件事情了。我们仔细审视一下这个过程,我们至少做了两件事情:
1 ) 学会被各种语言所表示的‘东西’,这里我们称之为世界知识 (world knowledge),它包括事实性知识 (factual knowledge) 和常识 (commonsense)。其中包括,学会至少两门语言里表达世界知识的单词和语法。
2)学会按别人的要求去执行翻译这个任务。
那么,这两件事情的第一件,就是 GPT 的第二个单词,Pre-train(预训练)。我们就是要去学到‘Tom chase Jerry’这句话和其他无数句话在被拆解成世界性知识之后的‘表示’。
Transformer 就是一个专门用于自然语言处理的编码-解码器架构。编码器-解码器可以有很多不同的架构细节,就能得到不同的自编码架构,Transformer 是此刻看起来效果最好的,能很好地学到自然语言背后的特征,并且有足够大的模型容量。所谓模型容量,是指,有一些模型参数过多,就反而学不到特征,或者无法训练了,无法用于表示特别复杂的东西。
2 GPT
GPT 全称 Generative Pre-trained Transformer,前面讲了编解码,算是讲了一点点 Transformer,也讲了预训练、Pre-trained。那么,Generative 从何讲起?
我接着说人话。前面讲到了,编码器-解码器是两个不同的模型,就像你看视频,你的手机上并不需要视频录制、编辑软件,只需要一个解码-播放器一样。训练两个模型太麻烦,我们希望就围绕一个模型做研究,做训练。我们能不能不做编码,就围绕解码模型来达到一些目的呢?答案当然是可以的。
打个不严谨的比方。我现在想找人帮我画一幅肖像画。其实我并不懂怎么画画。于是,我请人给我画。我并不能从画工技艺、艺术审美方面去评判他画得好不好。但是,我是有能力去判断我请的人画出来的画是不是令我满意的。此时,我就是一个 decode-only 的模型。你会说,“你这个 decode-only 的模型必须要有一个懂 encode 的画师才能工作啊“。是的,我不懂画画。确实需要一个画师。
但是,你记得吗,OpenAI 训练 GPT3 的模型,就是给它海量的数据,让它去训练。那么
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1568
1568

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









