







本文提出了一种参数空间对齐的多模态大模型范式,该范式将输入图像特征转换成LoRA权重并合并到LLM中,使LLM感知图像视觉信息。该范式避免了在LLM的输入序列中引入视觉标记,在训练和推理上都非常高效。论文已被 NeurIPS 2024 接收,论文链接和代码均已公开,欢迎交流~

前排提示,文末有大模型AGI-CSDN独家资料包哦!
1. 输入空间对齐范式
1.1 介绍
在进入正题之前,我们先简单回顾一下当前主流的MLLM范式。
以最具代表性的LLaVA[1]为例,

Figure 1. LLaVA的结构框图
对于输入的图像 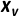 ,通过视觉编码器(Vision Encoder)和 映射模块(Projection)提取特征,得到一个由视觉标记(Visual Tokens)组成的视觉序列,然后将视觉序列和文本在序列维度上拼接,一同输入到LLM中进行训练。在训练过程中,视觉序列是在对齐LLM的输入空间以让LLM能够理解视觉信息,我们称这种范式为输入空间对齐范式。
,通过视觉编码器(Vision Encoder)和 映射模块(Projection)提取特征,得到一个由视觉标记(Visual Tokens)组成的视觉序列,然后将视觉序列和文本在序列维度上拼接,一同输入到LLM中进行训练。在训练过程中,视觉序列是在对齐LLM的输入空间以让LLM能够理解视觉信息,我们称这种范式为输入空间对齐范式。
输入空间对齐范式有2个特点:
1. 视觉信息序列化,和文本信息具有相同的表现形式 图像经过视觉编码器之后会变成视觉标记,然后通过映射模块映射到和文本标记(Text Tokens)相同的特征维度,最后形成了和文本信息相同的表现形式,即序列。
2. MLLM中视觉和文本的模态交互通过注意力机制进行 视觉信息序列化之后,会将视觉序列与文本序列在序列维度上拼接,然后同时输入给LLM。在前向传播的过程中,视觉与文本通过注意力机制产生模态交互。
目前主流MLLM遵从输入空间对齐范式,比如Qwen2-VL[2],DeepSeek-VL[3],和InternVL2[4],如Figure 2所示。
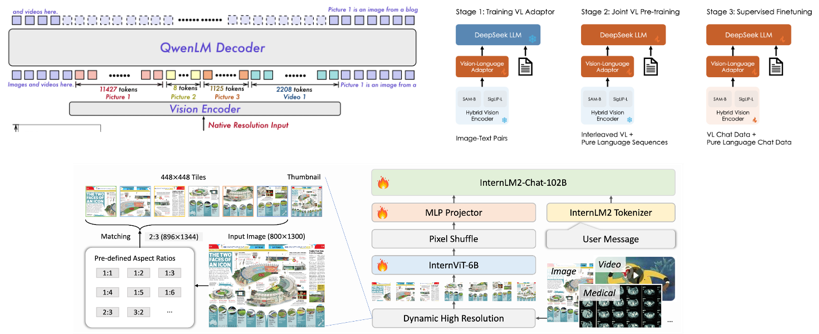
Figure 2. 输入空间对齐范式:Qwen2-VL, DeepSeek-VL 和 InternVL2
1.2 问题
输入空间对齐范式使用CLIP可以很容易将视觉特征对齐到LLM输入空间,因为CLIP的视觉特征预先和文本对齐过,本身具备丰富的语义信息,但是在训练和推理时计算效率低。
在输入序列达到一定长度的情况下,LLM的计算量集中在注意力机制部分,当输入序列长度为 n 时,计算复杂度为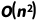 ,也就是说LLM的计算量随着输入序列长度而平方增长。LLaVA-v1.5的视觉编码器为ViT-L-14,对于单张图像,产生的视觉标记的数量为576。而考虑到高分辨率图像输入,一些工作会将图像切分成多个子图,分别转换成视觉标记,最后产生非常长的视觉序列。比如,Sphinx-2k[5]的视觉序列长度为2890,InternLM-Xcomposer2
,也就是说LLM的计算量随着输入序列长度而平方增长。LLaVA-v1.5的视觉编码器为ViT-L-14,对于单张图像,产生的视觉标记的数量为576。而考虑到高分辨率图像输入,一些工作会将图像切分成多个子图,分别转换成视觉标记,最后产生非常长的视觉序列。比如,Sphinx-2k[5]的视觉序列长度为2890,InternLM-Xcomposer2
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 637
637

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









