






题目:EarthMarker: A Visual Prompting Multi-modal Large Language Model for Remote Sensing
期刊:IEEE Transactions on Geoscience and Remote Sensing
数据/代码:https://github.com/wivizhang/EarthMarker

创新点
-
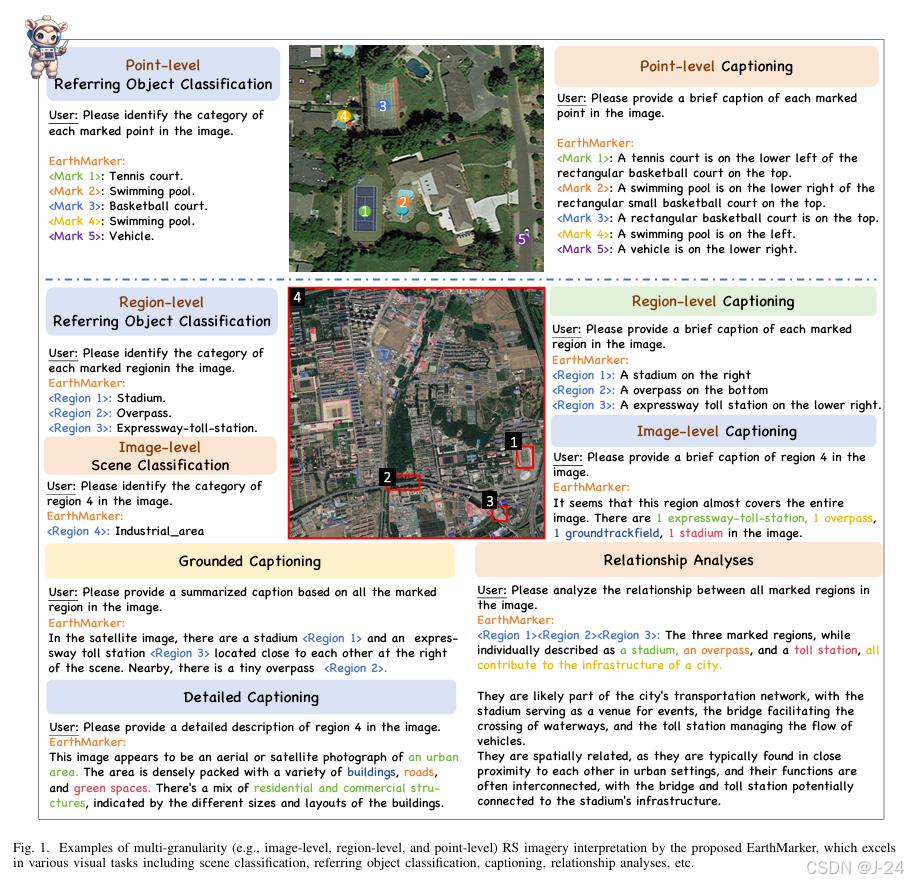
EarthMarker 是首个在遥感领域中基于视觉提示的多模态大语言模型 (MLLM)。其设计包括多尺度图像与视觉提示的联合解码,填补了现有模型在细粒度遥感图像解释方面的空白。
-
数据集:构建了第一个遥感视觉提示数据集 RSVP,包含365万多模态对话数据,支持多粒度任务(如图像级、区域级和点级任务)。
-
跨领域学习策略:提出了跨域学习训练,利用自然领域的知识迁移提升模型在遥感领域的性能,分为多域对齐、空间感知调优、遥感视觉提示调优三阶段。
数据
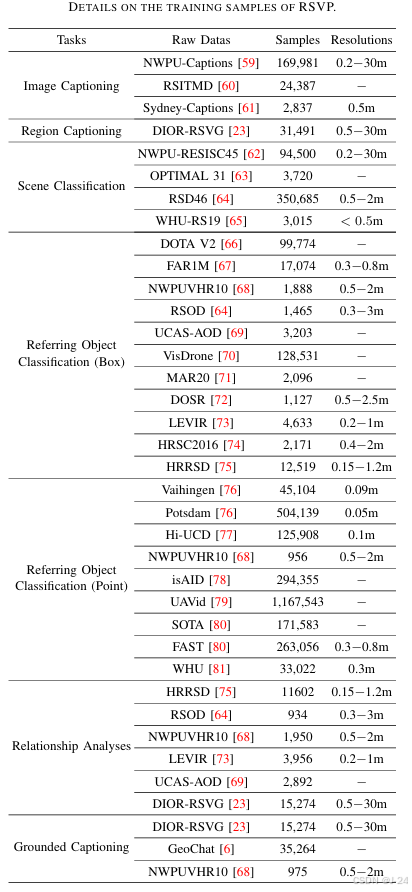
RSVP(Remote Sensing Visual Prompting Dataset) 是本文提出的第一个用于遥感视觉提示的大规模多模态数据集。
数据量与数据格式
-
数据量:大约 365万 条图像-点-文本和图像-区域-文本配对数据。
-
数据格式:
视觉提示:通过框(bounding boxes)或点(points)标注目标区域或目标点。
用户指令:提供的自然语言指令引导模型执行任务。
图像数据:遥感图像具有多种分辨率,涵盖从高分辨率到中低分辨率的数据类型。
数据来源与范围
-
公开数据集转换:从多个公开遥感数据集中重构和重新标注数据,涵盖广泛的视觉任务。
-
辅助生成:利用 GPT4V 模型生成复杂、精细的描述,以提升遥感数据的语义和空间表达质量。
-
数据类型覆盖:从图像分类、目标检测到关系分析,涵盖图像级、区域级和点级任务。
数据特点
-
全球覆盖:数据地理分布广泛,包含多样化的生态系统和地形类型。
-
分辨率多样性:包括从0.05米到30米的多种分辨率图像。
-
遥感特性:针对遥感图像的特定需求,数据标注注重区域和点的空间关系与语义联系。
方法
总体结构
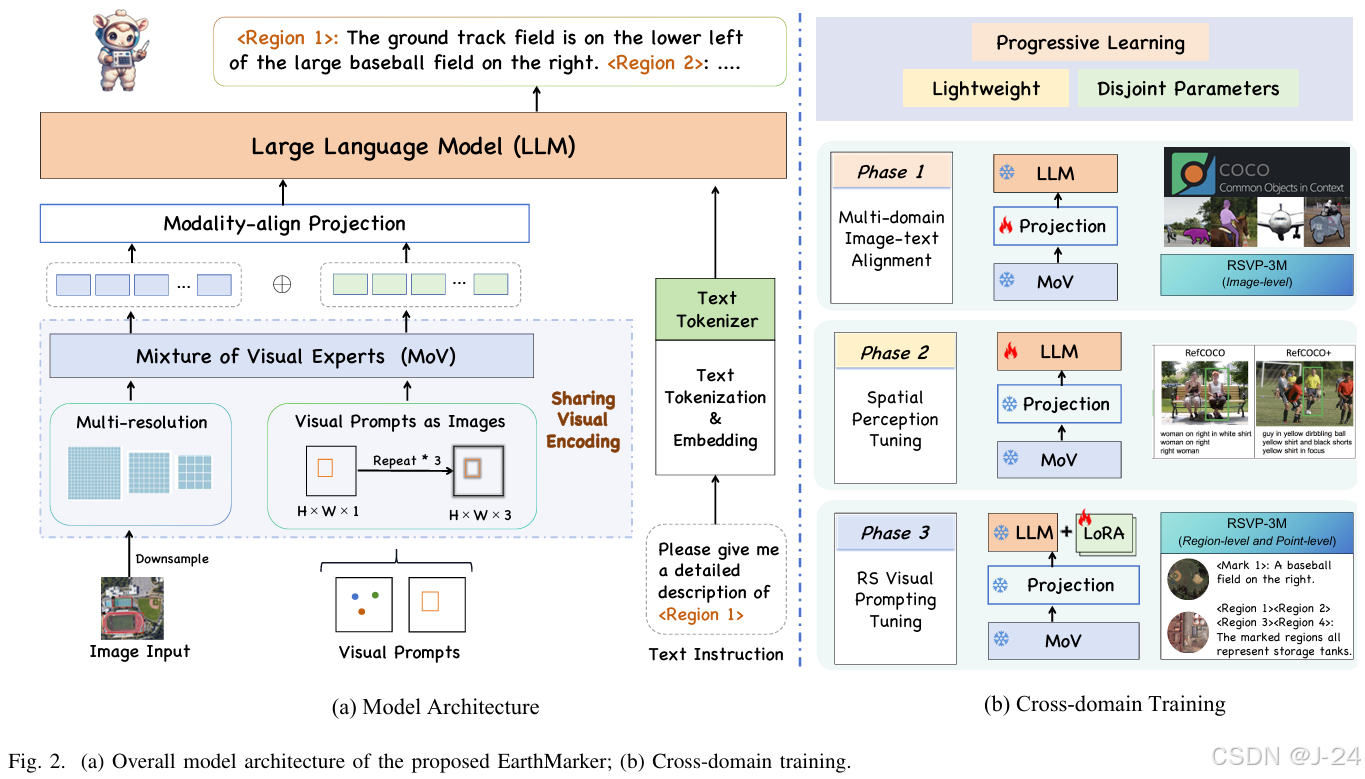
视觉提示共享编码
将遥感图像与视觉提示(如框或点)统一处理
-
共享编码器:遥感图像和视觉提示通过同一个视觉编码器提取特征,实现提示和图像的语义对齐。
-
多视觉专家模块:结合多个视觉编码器(如 DINOv2 和 CLIP),以应对遥感数据的复杂性,如分辨率差异和空间尺度变化。
-
多尺度特征融合:针对遥感图像的高分辨率特点,模型提取并融合不同分辨率的特征,确保既保留细节又关注全局信息。
模态对齐与统一表示
-
视觉与文本的对齐:模型通过特征投射模块,将图像特征、视觉提示特征与文本特征对齐到一个统一的语义空间,确保模态间的信息融合。
-
文本生成能力:利用大语言模型解码器,从图像和提示生成文本描述,支持从全图到局部的多粒度解释。
跨领域学习策略
-
多域预训练
目标:结合自然图像和遥感图像的数据,提升模型对图像内容的全局理解能力。
过程:冻结视觉编码器,仅对跨模态特征对齐模块进行训练,建立视觉与语言模态的初步联系。
-
空间感知优化
目标:增强模型对区域和点的感知能力,支持区域描述、目标检测等任务。
过程:解冻部分模型参数,优化视觉提示特征与文本描述的结合效果,提升模型对空间关系的捕捉能力。
-
遥感提示调优
目标:针对遥感图像的特点(如高分辨率、多目标分布)进行细化优化。
过程:利用 RSVP 数据集中的点级和区域级任务数据,进一步训练模型,使其在复杂场景中具有更高的准确性和鲁棒性。
实验与分析
实验使用构建的 RSVP 数据集,包含图像级、区域级和点级的任务数据。选择当前主流的多模态模型(如 CLIP、GeoChat)作为对比基准。
-
图像级任务:包括场景分类和图像描述。
-
区域级任务:目标区域的分类和描述。
-
点级任务:特定点目标的分类和描述。
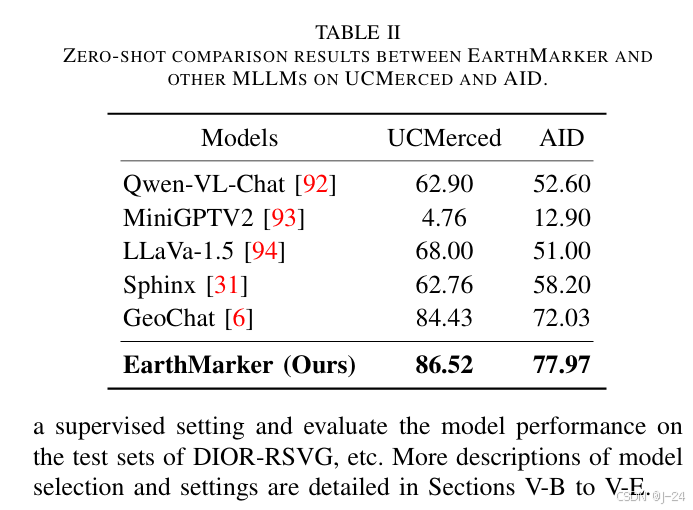
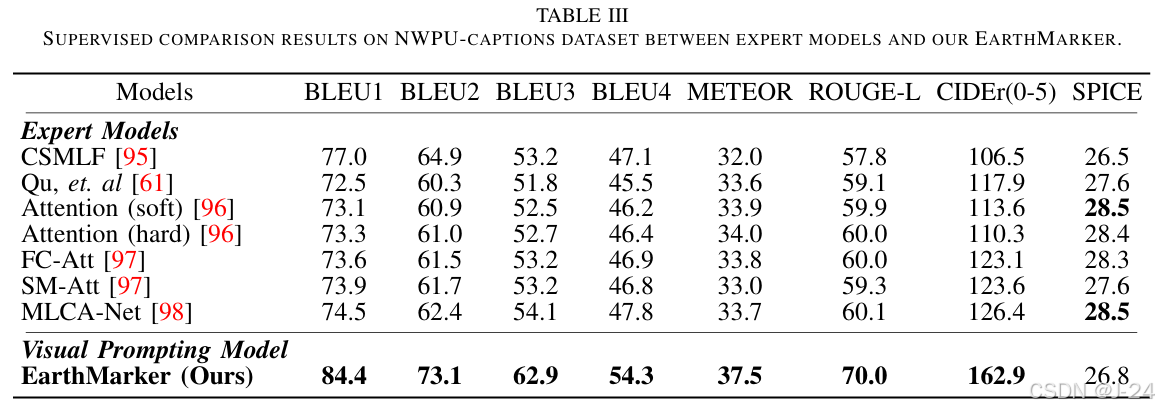
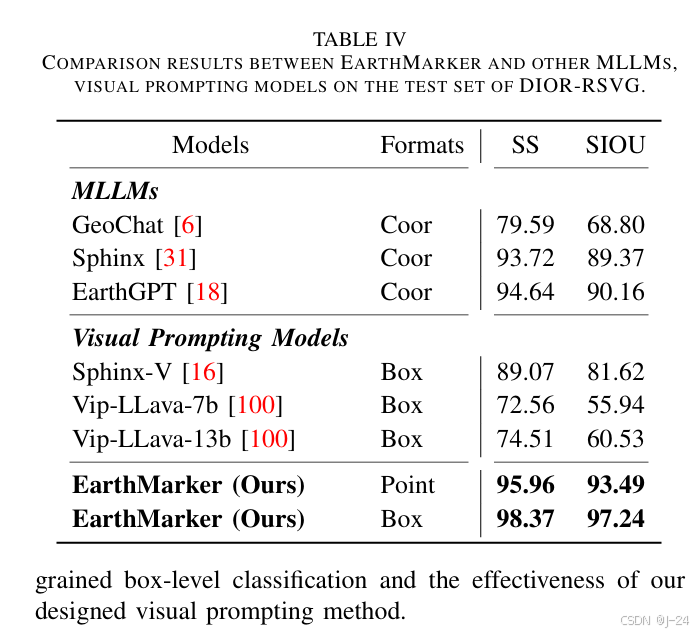
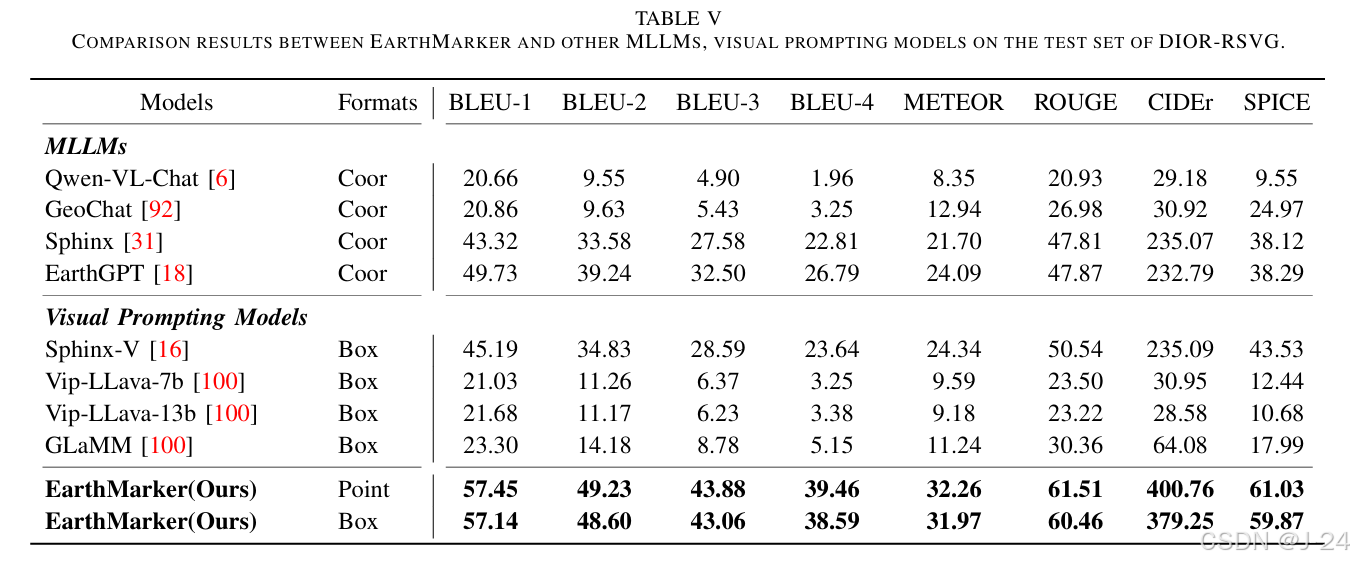
实验结果表明,EarthMarker 在多种遥感任务中均超越了现有模型,验证了其在多模态遥感图像理解中的有效性和鲁棒性。模型在零样本分类、区域描述、点级分类等任务上的卓越表现进一步凸显了其创新性设计的价值。
精度对比
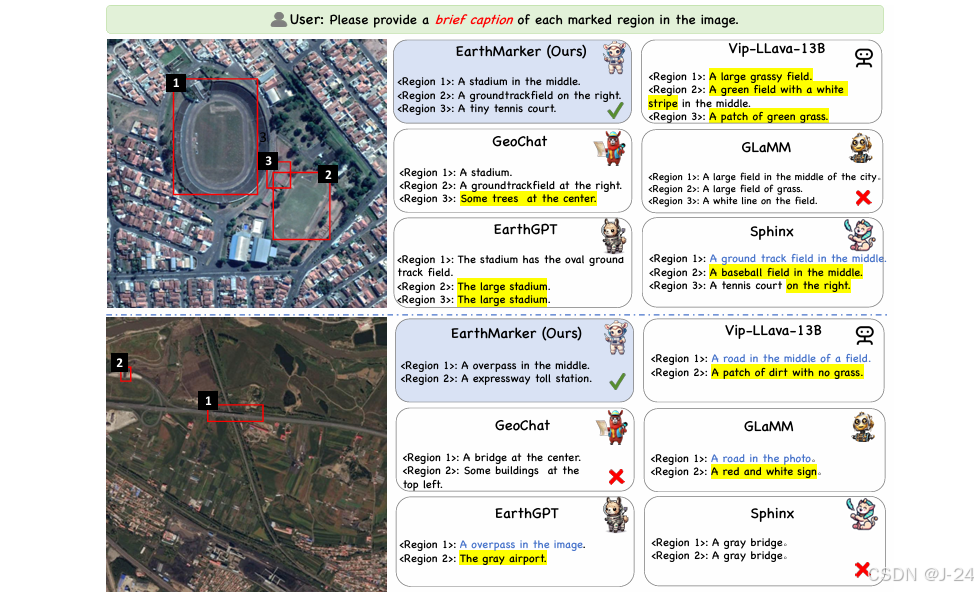
可视化



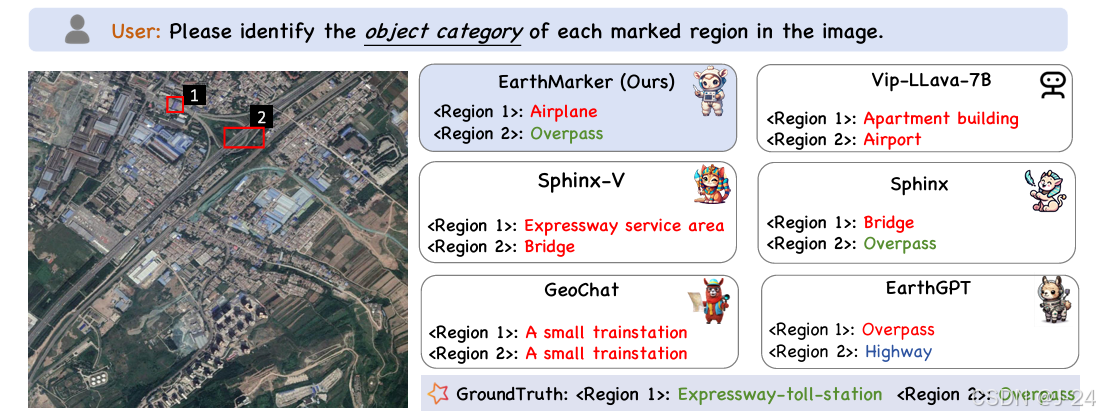
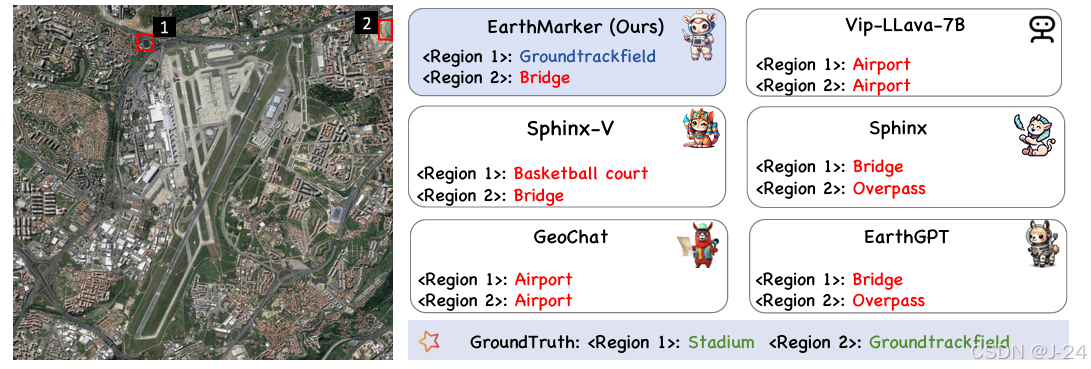
更多图表分析可见原文

















 1935
1935

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









