






国内先驱遥感大模型EarthGPT数据集已开源!!!遥感多模态指令数据集 MMRS_1M作为目前领域最大的指令数据集,含超过100 万条图文对,现已全部开源!🔥
🌍EarthGPT作为先驱遥感通用大模型2024年5月在遥感顶刊IEEE TGRS上发表。EarthGPT整合了多种遥感视觉任务,如场景分类、图像描述、视觉问答、视觉定位和目标检测等,此外,EarthGPT还统一了多种传感器的遥感图像理解,涵盖光学、SAR和红外图像。EarthGPT的发布为遥感多模态大模型的发展提供了基石。
可在GitHub获取数据集,共同推动遥感大模型的进一步发展!🚀
📄 论文链接:
IEEE TGRS发表版本:
Arxiv版本:https://arxiv.org/abs/2401.16822
💻 GitHub链接: GitHub - wivizhang/EarthGPT

摘要
本文提出了一种名为EarthGPT的多模态大语言模型,用于远程感知领域的通用图像理解。该模型包括视觉增强感知机制、跨模态互相理解方法和多传感器多任务统一指令调整方法。此外,还构建了一个大规模的多传感器多模态远程感知指令跟随数据集MMRS,用于解决MLLM在远程感知领域缺乏专业知识的问题。实验结果表明,EarthGPT在各种远程感知视觉解释任务中表现优异,证明了该模型的有效性。
简介
远程感知领域中,统一多任务解释非常重要,因为实际应用往往需要综合分析以做出明智的决策。当前的深度学习方法主要遵循一任务一架构的范式,限制了处理多传感器遥感图像、多任务和开放式推理任务的能力。
本文旨在探索在遥感领域中应用多模态深度学习模型的挑战和限制。虽然已有一些研究如RSGPT和GeoChat尝试解决多任务问题,但它们仍存在一些局限性,如缺乏通用性和对多种传感器数据的理解。因此,本文致力于构建一个大规模的多模态数据集,以便更好地研究和解决这些问题。
本文提出了一种多传感器遥感图像理解的多功能多语言模型(MLLM)EarthGPT。EarthGPT通过语言交互能够高效处理各种遥感任务,并统一了各种遥感解释任务。EarthGPT包括三个关键技术:视觉增强感知机制、跨模态互相理解方法和多传感器和多任务统一指令调整方法。此外,还创建了一个大规模数据集MMRS,用于多传感器多模态遥感指令跟随。该数据集解决了MLLM缺乏遥感领域专业知识的挑战,并推动了MLLM在遥感领域的发展。

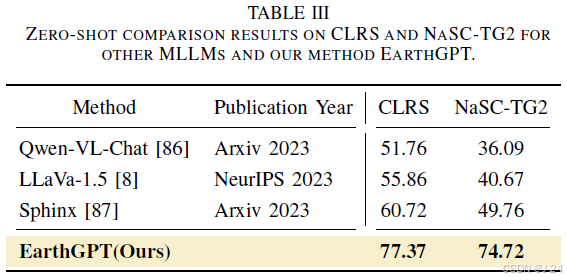
EarthGPT在多个遥感数据集上进行了广泛的实验,结果显示在大多数遥感任务中,EarthGPT超过了最先进的专家模型和多模态语言模型。特别是在图像字幕、视觉问答和视觉定位任务中,EarthGPT在NWPU-Captions、CRSVQA和DIOR-RSVG数据集上相比其他专家模型有显著的改进。此外,我们还评估了EarthGPT在开放域中的泛化能力。在零样本场景分类任务中,EarthGPT在CLRS和NaSC-TG2数据集上分别达到了77.37%和74.72%的准确率,远远超过其他多模态语言模型。在MAR20检测数据集上,EarthGPT在Ap@40%指标上达到了90.47%的准确率,相比其他多模态语言模型和开放域检测模型有显著提高。总之,实验结果表明EarthGPT在广泛的遥感多传感器图像理解任务中表现出优越的性能,并具有强大的开放域推理能力。
本文的贡献如下:
-
构建了一个名为MMRS的最大的多模态多传感器遥感指令跟随数据集,包括光学、SAR和红外遥感图像,有效解决了缺乏遥感领域专业知识的多模态语言与视觉模型(MLLMs)的挑战。
-
提出了一种名为EarthGPT的先驱MLLM,用于多传感器遥感图像理解,能够统一处理各种视觉-语言遥感任务。它包括三个技术:视觉增强感知机制、跨模态相互理解方法和统一指令调整方法。
-
大量实验证明EarthGPT在多传感器遥感视觉解释任务上的性能优于其他专业模型和MLLMs,如场景分类、图像字幕、区域级字幕、VQA、视觉定位和目标检测。这些结果证明EarthGPT是遥感MLLM领域的重大进展,为遥感视觉-语言相互理解和开放式推理能力提供了多功能范例。
相关工作
MLLMs
虽然现有的MLLMs已经能够处理图像和文本的结合,但是在遥感领域的应用还存在一定的局限性。因此,提出了EarthGPT模型,旨在无缝地整合多个遥感任务和多传感器的视觉模态,以实现遥感领域的开放式辅助。
用于遥感的MLLMs
现有的大型RS模型主要采用自监督方法,如遮挡图像重建。然而,这些模型在视觉模态上进行预训练,缺乏与语言的对齐,限制了多模态理解和推理能力。最近出现了一些针对RS的MLLM模型,但它们都是基于光学RS图像进行训练,缺乏对SAR、红外等多传感器视觉模态的普适性。为了实现更普适的RS多模态推理,并解决现有模型在开放式对话、多任务统一和多传感器图像理解方面的局限性,本文提出了EarthGPT模型。该模型通过指导调整将自然领域的MLLM扩展到RS领域,并引入了视觉增强感知机制、跨模态相互理解机制和统一的多传感器RS图像理解指导调整方法。同时,还构建了一个大规模的多模态指导数据集MMRS,涵盖多传感器视觉模态和下游任务。
遥感数据集
遥感数据集是遥感智能解释模型的核心和基础。目前,遥感数据集主要集中在分类、检测、分割、图像描述和VQA等任务上。然而,这些数据集主要强调单一的视觉模态或个别任务,导致模型的泛化能力受限。为了解决这个问题,研究人员构建了一个名为MMRS的数据集,包含了100万多个图像-文本对,涵盖了分类、检测、图像描述、VQA、视觉定位等多个任务,并包括光学、红外和SAR三种视觉模态。这个数据集旨在促进遥感领域中MLLMs的持续发展。
EarthGPT
概述
EarthGPT是一个通用的多模态多任务语言模型(MLLM),旨在解决MLLM在适应遥感(RS)领域时遇到的障碍。它包括三个关键技术:视觉增强感知机制、跨模态相互理解方法和统一指令调整方法。EarthGPT利用MLLM的泛化能力,将语言模型转化为视觉-语言模型,并在统一架构下适应RS任务。
视觉增强感知
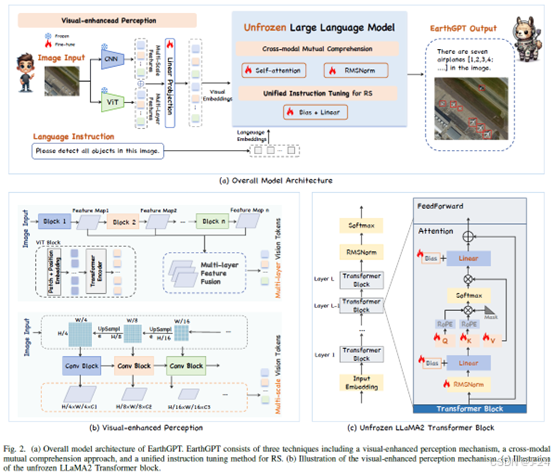
考虑到RS图像通常是通过安装在飞机或卫星上的相机从鸟瞰图拍摄的。这种不同的视角往往会引起各种干扰,包括云层的干扰,影响图像的清晰度。为了应对这一挑战,提出了一种视觉增强感知机制,利用不同图像编码模型的优势来增强和细化多粒度的关键视觉信息,同时减轻RS图像中的各种干扰。视觉增强感知机制由以下两个模块组成。
多层视觉感知。在ViT中图像被表示为序列。首先从不同的编码器层中提取多层视觉中间特征图。然后将提取的所有视觉特征沿通道维度进行级联。采用冻结的DINOv2 ViT-L/14 作为ViT编码器。
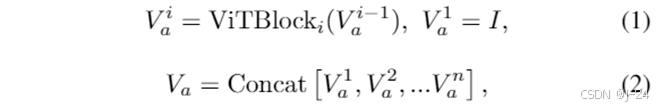
这样,提取的特征既包含了来自早期层的空间感知信息,又包含了来自后期层的语义指示性信息。
多尺度视觉感知。为了将多尺度局部细节融入视觉表示中,CNN backbone设计用于提取多尺度视觉特征。卷积块将输入转换为token嵌入。同时将所有尺度特征转换为相同的通道维度,并连接在一起。
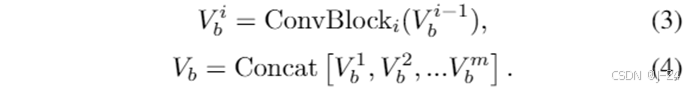
经过多尺度视觉特征的融合,得到的视觉特征包含了多粒度的信息,既能捕获广泛、粗粒度的全局语义,又能捕获复杂、细粒度的细节信息。我们采用冻结的CLIP ConvNeXt-L作为CNN骨干。
视觉增强融合。在使用ViT和CNN提取特征后,将多层和多尺度特征连接起来。然后,使用一个可学习的投影层与语言标记进行维度对齐。混合token包含邻近依赖关系和长程视觉交互,提供微妙的局部见解和广泛的区域相关性。融合增强的视觉感知信息有利于准确高效地进行图像解译。
![]()
跨模态相互理解
我们通过视觉和语言感知信息融合,将多模态输入传递到LLM进行对齐和交互训练。同时,通过视觉增强感知,获取视觉令牌,并使用语言分词器将语言指令分段并投影为离散令牌嵌入。最后,将整体视觉令牌与语言指令令牌连接起来,形成LLM输入令牌,然后将多模态输入X馈入LLM进行融合和集成。

当前的MLLMs中,通过在冻结的LLM上进行训练来实现视觉-语言理解,以避免昂贵的全参数微调。然而,冻结所有LLM的权重显著限制了其全面跨模态学习的潜力。为了应对不同模态之间的知识差距并实现多模态相互理解,设计了一种解冻的视觉-语言对齐策略。对于在最常见的领域数据(LAION-400M,COCO Caption)上进行训练,解冻了自注意力和归一化层。这种策略有助于LLM全面理解多模态表示,并通过部分冻结的模块同时保留LLM固有的语言生成能力。在我们的方法中,采用具有强大语言理解能力的LLaMA-2作为初始LLM。LLaMA-2由L个Transformer块组成,每个块由自注意力、RMSNorm和FFN层组成。在训练过程中,采用交叉熵损失函数进行训练。经过视觉-语言对齐后,语言单独的LLM转化为MLLM,MLLM可以基于集成的多模态信息生成视觉解释响应。
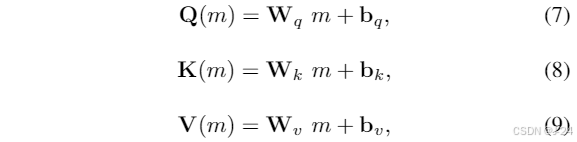
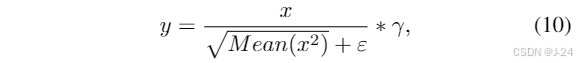
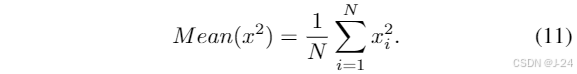
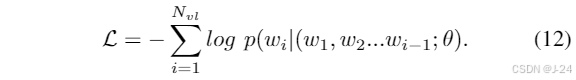
统一多任务指令遵循
为了增强EarthGPT对各种下游任务的指令遵循能力,并将其适用性从自然领域扩展到遥感领域,开发了一个广泛而统一的指令遵循数据集MMRS。在MMRS数据集中,我们将所有下游任务标准化为VQA指令的格式。通过使用MMRS进行调优,该模型在准确理解和执行RS域的各种指令方面具有优势。
为了保留前一阶段获得的多模态能力,同时增强对任务指令的遵从性,冻结了视觉-语言对齐阶段的所有权重,并引入新的可学习参数。受SSF和LLaMAAdapter V2的启发,通过在线性层中引入两个可学习参数,对线性层进行了修改。这一阶段的损失函数与跨模态相互理解阶段相同。
![]()
![]()
利用LLM的高级推理能力和丰富的MMRS数据集,EarthGPT在语言指令的指导下,具备了RS域多传感器视觉理解的通用技能,并显示了现实世界实际应用的潜力。
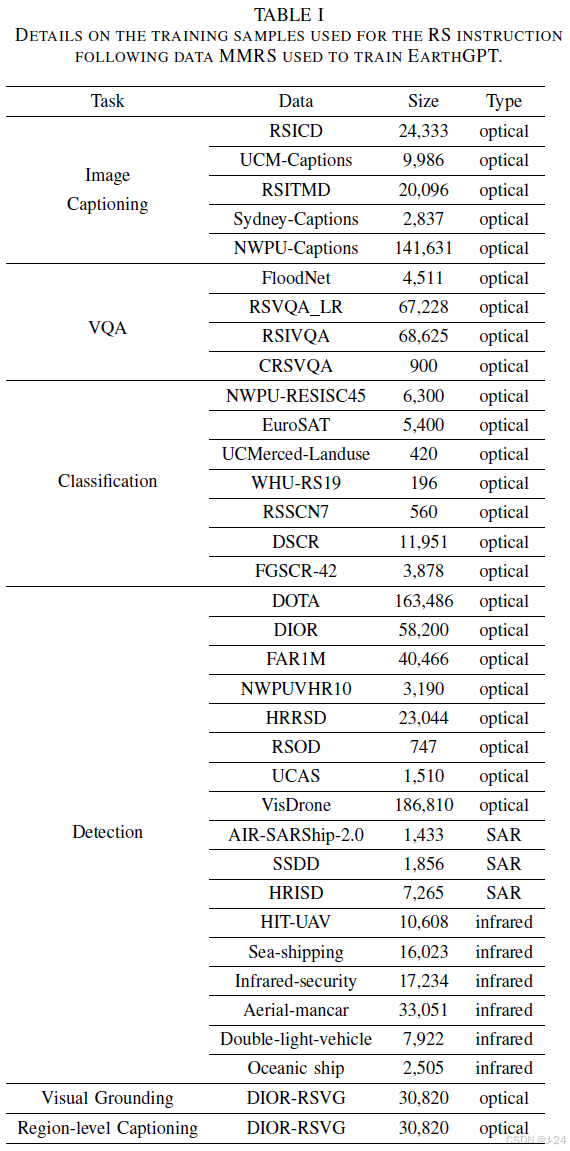
MMRS数据集
为了有效应用多模态语言模型(MLLMs)进行地理信息智能解释和开放式对话,需要一个多样化和全面的指令跟随数据集,以覆盖遥感图像的特定描述和语义细节。因此,作者创建了一个新的指令跟随数据集MMRS,涵盖了五个任务和三种视觉模态,并使用EarthGPT在该数据集上进行微调,以实现优秀的粗粒度对话和细粒度定位能力。该数据集的构建过程详细介绍。
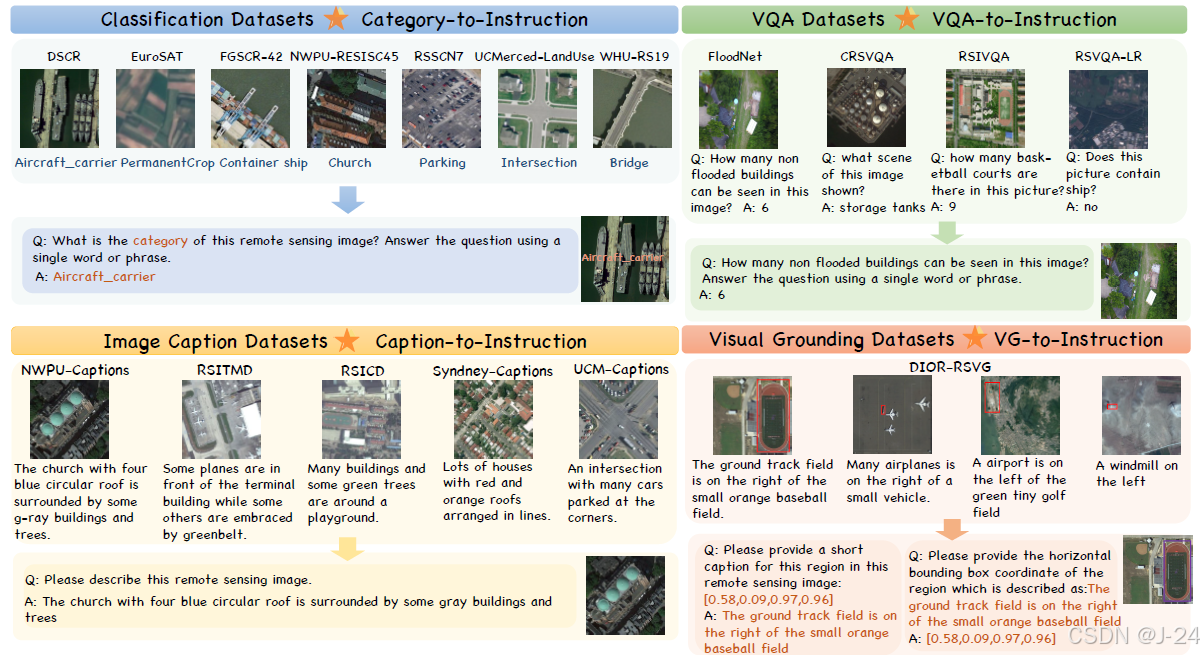
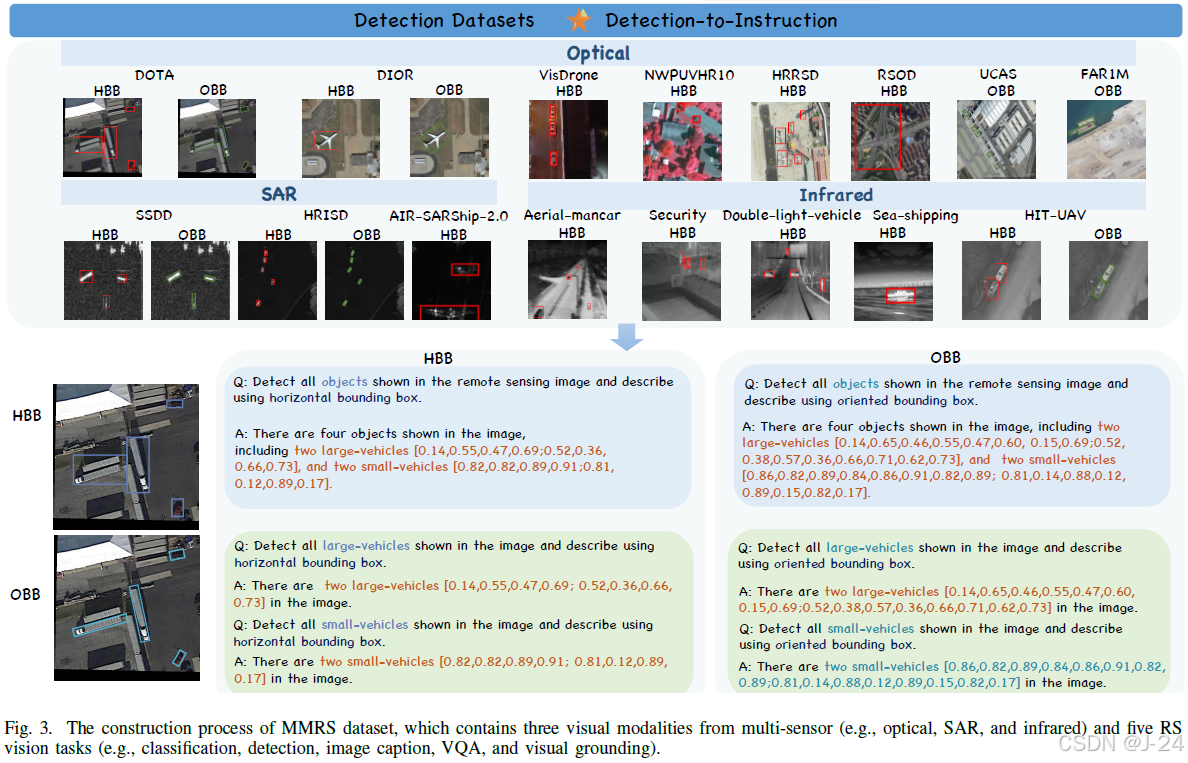
粗粒度的对话场景
我们介绍了如何使用分类、图像描述和视觉问答数据集对EarthGPT进行指令微调,以赋予其图像级别的粗粒度问答能力。分类数据集采用类别到指令的转换方式,图像描述数据集采用描述到指令的转换方式,视觉问答数据集采用VQA到指令的转换方式。通过这些转换,EarthGPT可以对图像进行分类、描述和回答问题。
细粒度的对话场景
数据集包含了光学、SAR和红外等多种遥感图像数据集,用于目标区域定位和物体检测。数据集转换过程中采用了检测到指令和视觉定位到指令等技术。该数据集的构建使得遥感应用的特殊成像特征和地理特征得到了更好的满足。
实验和分析
实现细节
训练过程分两阶段。第一阶段是交叉模态相互理解阶段,目的是将仅包含语言的LLM转换为MLLM。第二阶段是统一多任务调整阶段,目的是为MLLM提供多样化的RS下游任务所需的灵活性。使用MMRS数据集进行训练,将所有数据集统一为多模态对话格式,优化训练过程,降低成本,提高效率。在两个阶段的训练中,只训练一个现成的语言模型LLaMA-2和随机初始化的视觉投影,同时保持多个视觉编码器冻结。使用AdamW优化器进行训练。
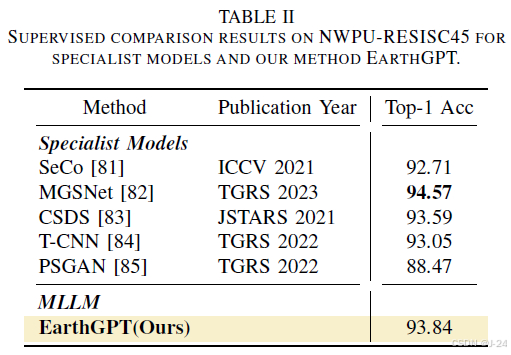
场景分类
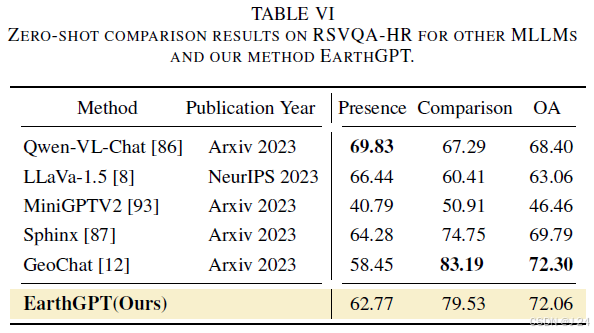
本文介绍了两种评估EarthGPT模型分类性能的方法:有监督分类和零样本分类。有监督分类使用NWPU-RESISC45数据集进行测试,零样本分类使用CLRS和NaSC-TG2数据集进行测试。EarthGPT在分类评估中表现优异,比CSDS和T-CNN等SOTA专家模型的性能提高了0.25%和0.79%,与MGSNet的性能相当。在零样本分类评估中,EarthGPT比其他MLLMs表现更好,特别是在CLRS和NaSC-TG2数据集上,EarthGPT的top-1准确率分别超过了Qwen-VL-Chat、LLavaV1.5和Sphinx。这表明从RS中融合领域知识对于推广到未知分类场景非常重要。
图像描述
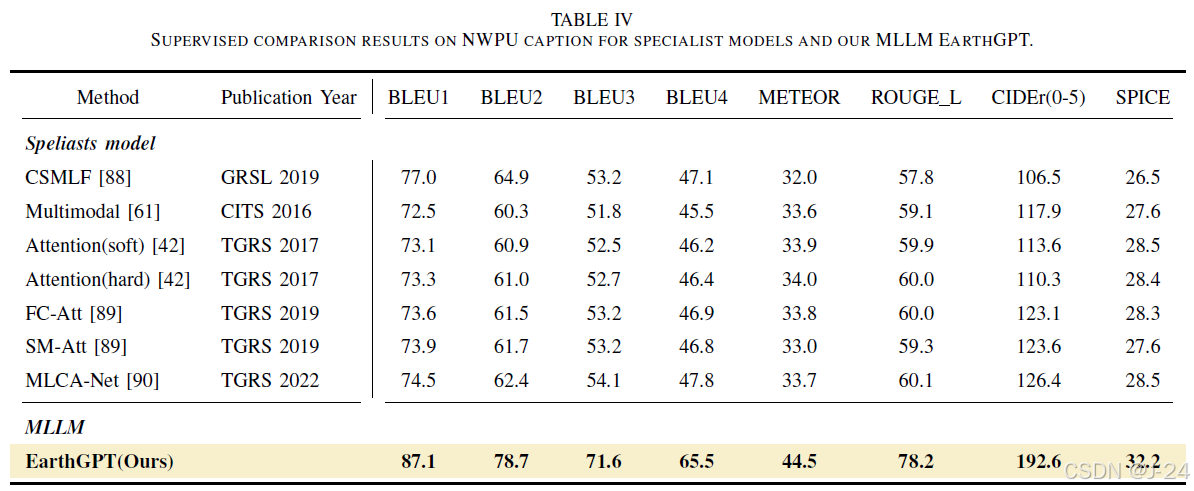
EarthGPT在NWPU-Captions数据集上的表现优于其他SOTA方法,提高了BLEU-1、BLEU-2、BLEU-3、BLEU-4、METEOR、ROUGE-L、CIDEr-D等指标的百分比。EarthGPT提供了准确、详细和多样化的遥感图像描述。
视觉问答
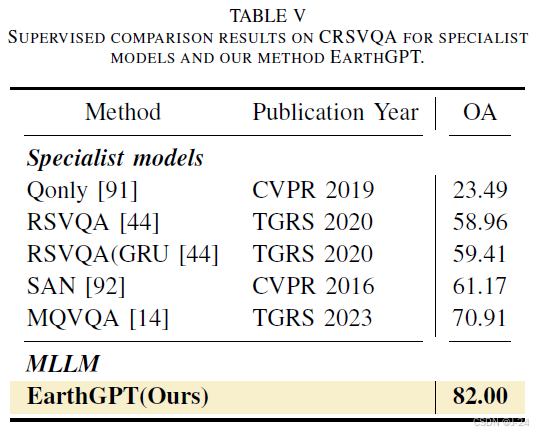
视觉问答(VQA)任务的评估方法,包括有监督和零样本评估。有监督评估采用CRSVQA数据集,零样本评估采用RSVQA-HR数据集。EarthGPT在CRSVQA数据集上表现优异,超过了其他专业模型。在零样本评估中,EarthGPT在RSVQA-HR数据集上的平均准确率为72.05%,表现出在全新和陌生的遥感环境中回答问题的出色能力。
视觉定位
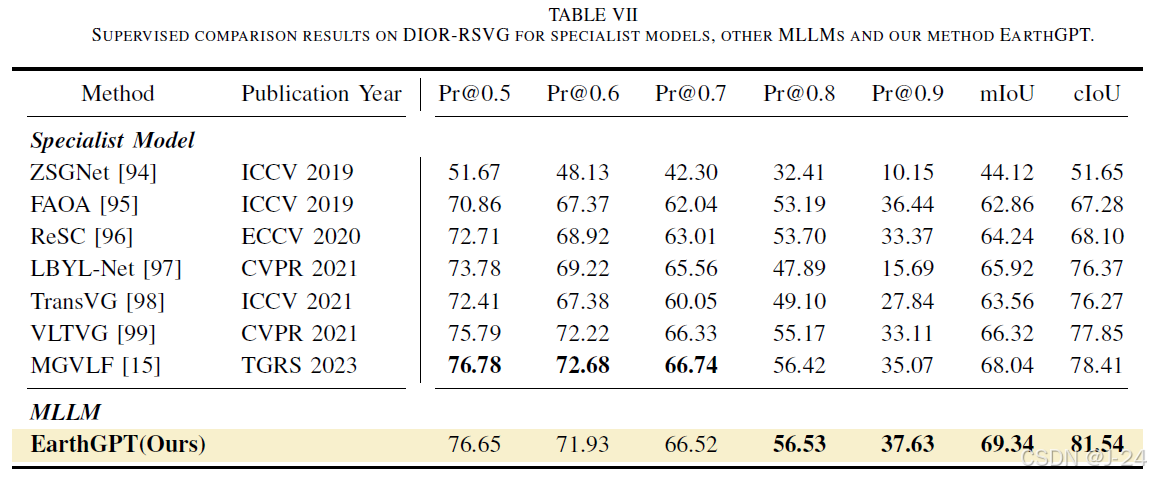
在 DIOR-RSVG 数据集上进行了测试。EarthGPT 在 Pr@0.8、Pr@0.9、mIoU 和 cIoU 指标上相较于其他 SOTA 模型有显著的性能提升。
目标检测
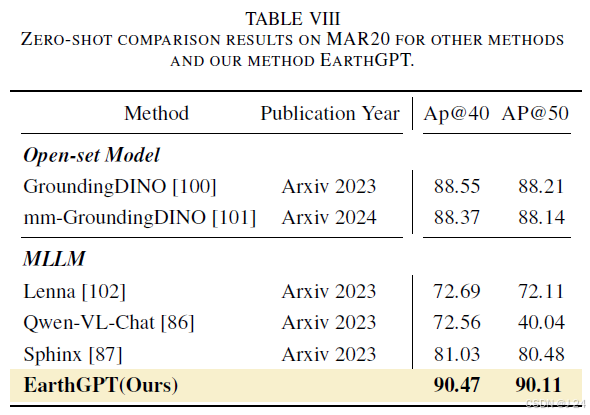
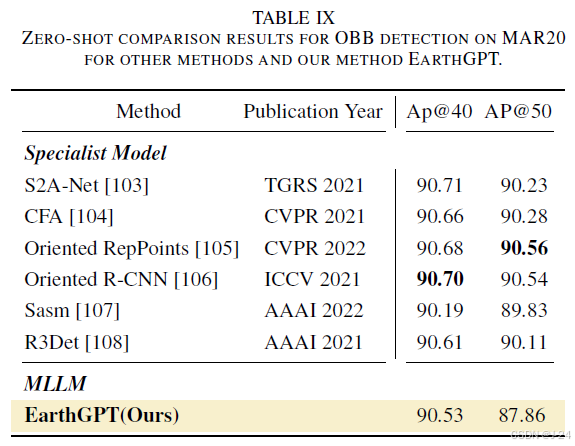
EarthGPT是一种创新的语言引导范式,用于目标检测。通过与其他多模态语言模型(MLLMs)和专家模型进行比较,采用零样本设置来评估其潜力和泛化能力。在MAR20数据集上进行评估,使用ap@40和ap@50作为评估指标。结果显示,EarthGPT在未见过的场景下具有显著的性能提升,并且在OBB检测方面与专家模型相比表现出竞争力。这表明了基于语言的生成式检测范式的强大潜力。
可视化
EarthGPT在多轮对话和多传感器视觉模态下展现出了出色的能力,能够处理图像级和区域级的视觉感知,并熟练解释复杂的推荐系统视觉数据。此外,EarthGPT还表现出了高级的思维链推理能力,促进了跨任务的视觉理解的出现。
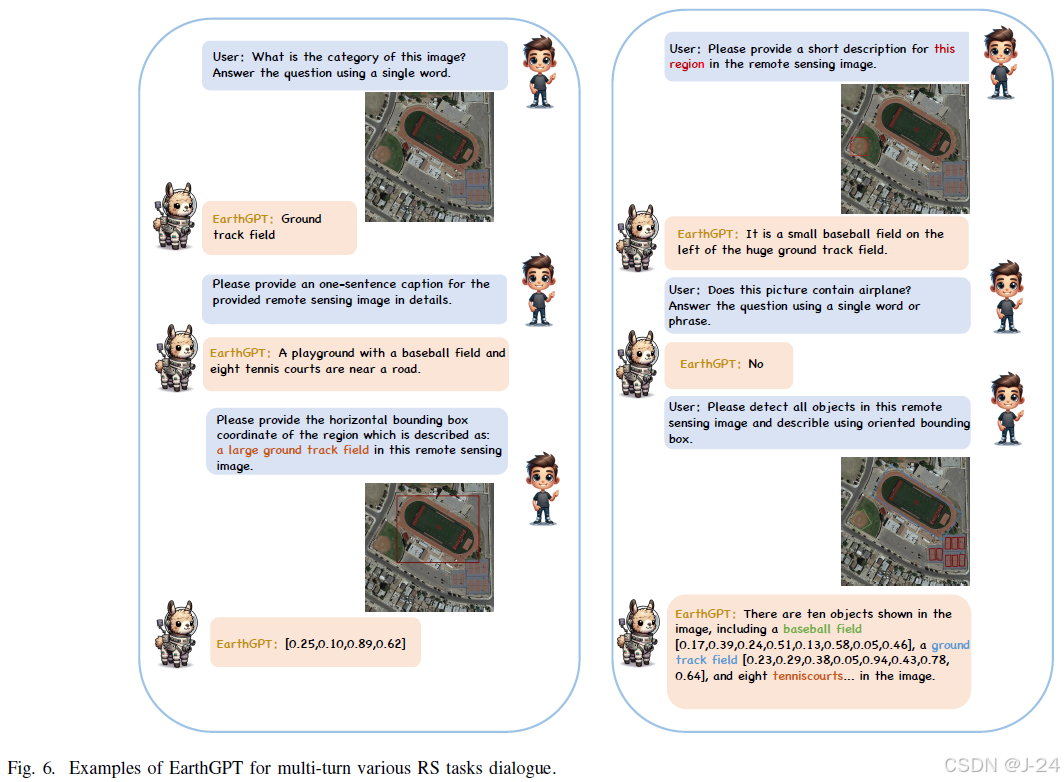
多任务多轮对话
EarthGPT是一种能够进行多轮对话的语言模型,具有分类、图像描述、视觉问答、物体检测、区域级描述和视觉定位等多种能力。与传统的专家模型相比,EarthGPT通过语言交互实现了更高的可读性和用户友好性。在图6中,展示了EarthGPT准确识别场景并提供详细空间布局描述的能力。与以往的专家模型相比,EarthGPT在语言交互方面有了显著的进步。
多视觉模态推理
EarthGPT是一种多模态的远程感知模型,具有强大的泛化能力,可以处理光学、SAR和红外视觉模态。EarthGPT使用语言来整合不同的视觉模态,可以准确地识别和描述各种场景中的物体和活动。

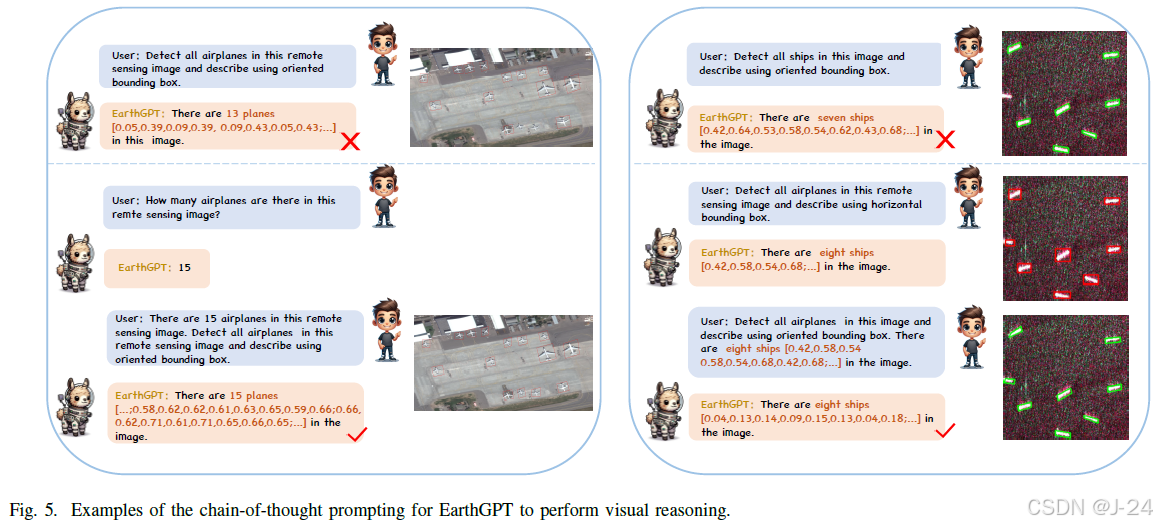
视觉推理的思维链提示
EarthGPT可以通过思维链提示来提高视觉推理准确性,例如通过对象计数作为提示来增强OBB检测完整性。此外,EarthGPT还可以通过利用HBB检测结果来提高OBB检测准确性。思维链提示技术有助于在各种视觉解释和推理任务中提高性能。
总结
本文提出了一种多功能的MLLM EarthGPT,用于通用的遥感图像理解,可以统一各种遥感任务和多传感器遥感图像。EarthGPT引入了三个关键技术:视觉增强感知机制、跨模态相互理解方法和统一的指令调整方法。此外,还构建了MMRS数据集,用于遥感指令跟随任务。通过大量实验证明,EarthGPT在各种遥感视觉解释任务中超过了现有的专家模型和MLLM,并提供了适用于多个下游任务的开放式推理能力。

















 2212
2212

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









