






2025深度学习发论文&模型涨点之——多尺度特征融合
视觉感知作为人工智能的核心领域之一,其目标在于赋予机器理解和分析视觉信息的能力。然而,现实世界中的视觉信息往往具有复杂的多尺度特性,例如图像中目标物体的大小、形状、纹理等特征会随着观察尺度的变化而呈现出不同的信息。传统的单一尺度特征提取方法难以充分捕捉这些多尺度信息,限制了机器视觉系统的性能。
多尺度特征融合技术应运而生,它通过有效地整合来自不同尺度的特征信息,突破单一尺度的局限,显著提升机器视觉系统在各种任务中的表现。近年来,多尺度特征融合已成为计算机视觉领域的研究热点,并在图像分类、目标检测、语义分割等任务中取得了显著成果。
我整理了一些多尺度特征融合【论文+代码】合集,需要的同学公人人人号【AI创新工场】发525自取。
论文精选
论文1:
Global-Local Path Networks for Monocular Depth Estimation with Vertical CutDepth
全局 - 局部路径网络用于单目深度估计与垂直剪切深度
方法
全局 - 局部路径网络架构:提出了一种新颖的全局 - 局部路径网络架构,通过构建连接多尺度局部特征与全局解码流的路径,整合全局和局部特征以恢复细节。
层次化 Transformer 编码器:采用层次化 Transformer 作为编码器,捕捉多尺度上下文特征,利用 Transformer 块构建全局路径,建模长距离依赖关系。
轻量级解码器:设计了一个轻量级且高效的解码器,通过上采样和卷积操作将瓶颈特征恢复为目标深度图大小,同时利用跳跃连接和特征融合模块保留局部结构细节。
选择性特征融合模块(SFF):提出 SFF 模块,通过估计注意力图来选择性地关注显著区域,将全局特征和局部特征进行融合,以低计算负担实现特征的自适应选择。
垂直 CutDepth 数据增强:改进了深度特定的数据增强方法,提出垂直 CutDepth,仅在水平轴上进行裁剪,保留垂直方向的几何信息,使模型能够更好地学习垂直长距离信息,从而提高深度估计的准确性。
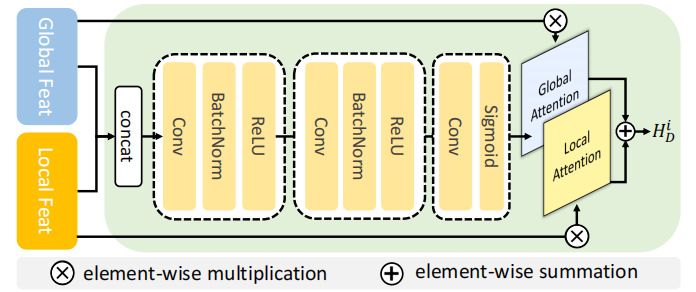
创新点
性能提升:在 NYU Depth V2 数据集上,该网络达到了最先进的性能,δ1、δ2、δ3 等指标均优于其他方法,例如与 Adabins 相比,δ1 提升了 0.012,AbsRel 降低了 0.005,RMSE 降低了 0.020。
模型效率:提出的解码器在保持高性能的同时,参数量仅为 0.66M,远低于其他方法如 MLP - decoder(3.19M)、BTS(5.79M)和 DPT(14.15M),证明了其在计算复杂度上的优势。
泛化能力:在 SUN RGB - D 数据集上进行测试时,该模型无需微调即可取得优异的性能,δ1、δ2、δ3 等指标均优于其他比较方法,展现了良好的泛化能力。
鲁棒性:在 NYU Depth V2 数据集的图像受到各种自然干扰的情况下,该模型的鲁棒性优于其他模型,例如在高斯噪声干扰下,δ1 为 0.775,远高于 BTS 的 0.223 和 Adabins 的 0.347;在对比度干扰下,δ1 为 0.860,高于 BTS 的 0.697 和 Adabins 的 0.654。
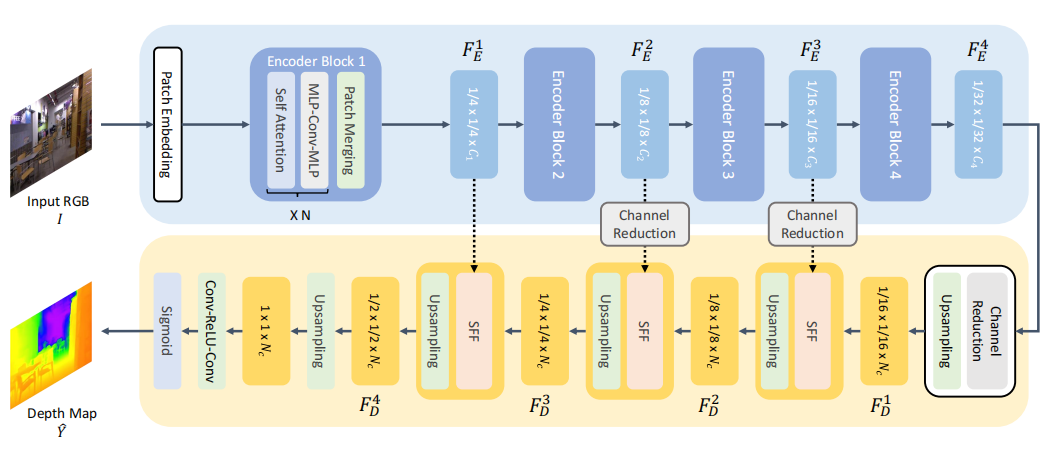
论文2:
UCTransNet: Rethinking the Skip Connections in U-Net from a Channel-wise Perspective with Transformer
UCTransNet:从通道角度重新思考 U-Net 中的跳跃连接与 Transformer
方法
通道 Transformer(CTrans)模块:提出 CTrans 模块替代 U-Net 中的跳跃连接,包含多尺度通道交叉融合 Transformer(CCT)和通道交叉注意力(CCA)两个子模块,用于融合多尺度通道信息并有效连接至解码器特征。
多尺度特征嵌入:将编码器输出的多尺度特征进行嵌入,将特征图划分为不同大小的 2D 块,保持通道维度不变,并将这些块映射到相同区域的编码器特征,以构建多尺度特征嵌入。
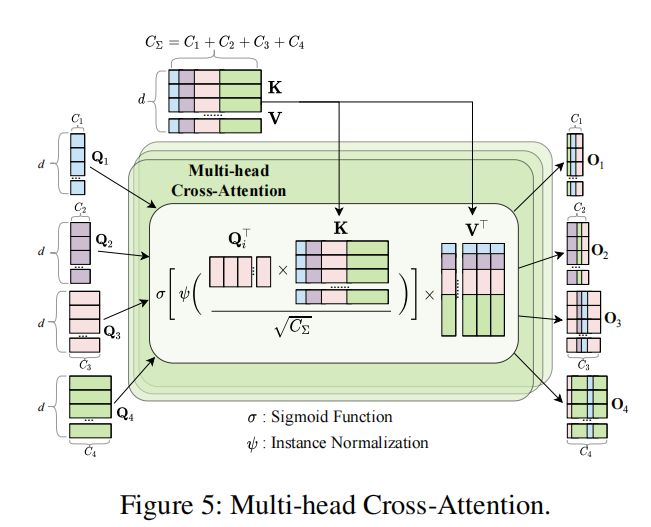
多头通道交叉注意力:通过多头通道交叉注意力机制,对嵌入后的特征进行处理,计算相似度矩阵并进行加权操作,从而捕捉通道间的依赖关系,增强特征的表达能力。
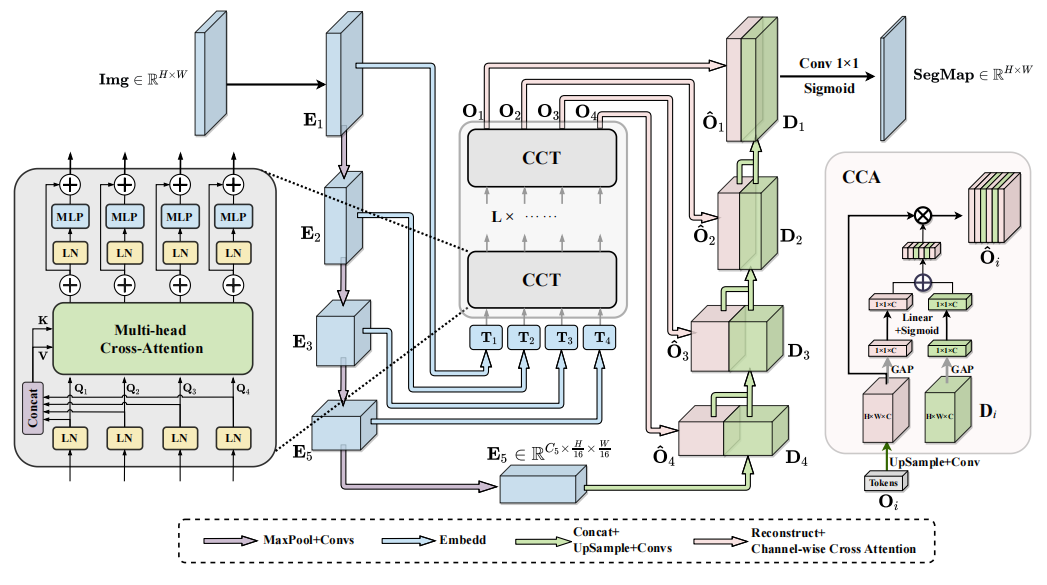
创新点
性能提升:在 GlaS 数据集上,Dice 指标从 U-Net 的 85.45% 提升至 90.18%,IoU 从 74.78% 提升至 82.96%;在 MoNuSeg 数据集上,Dice 指标从 76.45% 提升至 79.08%,IoU 从 62.86% 提升至 65.50%,显著优于其他方法。
特征融合改进:通过 CCT 模块,能够有效地融合多尺度通道信息,解决了传统 U-Net 中跳跃连接因语义差距导致的特征融合问题,提升了分割精度。
通道注意力机制:CCA 模块能够对不同通道的特征进行加权,突出重要通道的信息,进一步提高了特征的判别能力,增强了模型对复杂医学图像分割的适应性。
论文3:
You Only Look One-level Feature
你只需要看一层特征
方法
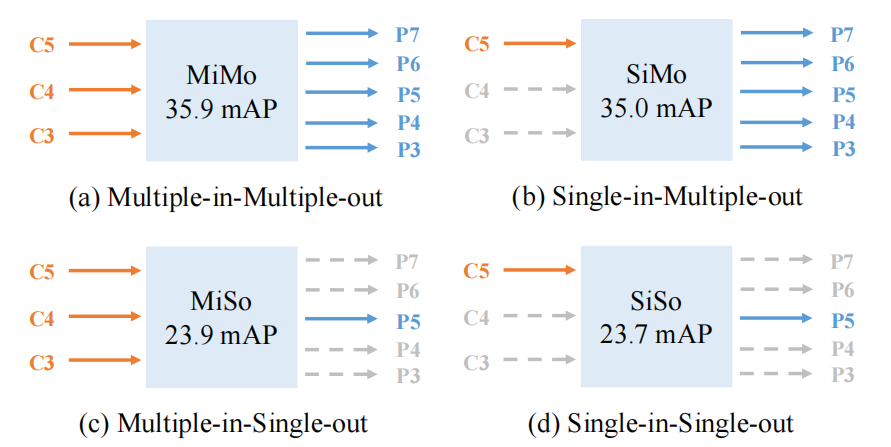
单层特征检测框架:提出了一种仅使用单层 C5 特征进行目标检测的框架 YOLOF,与传统的多尺度特征金字塔网络(FPN)相比,简化了检测流程。
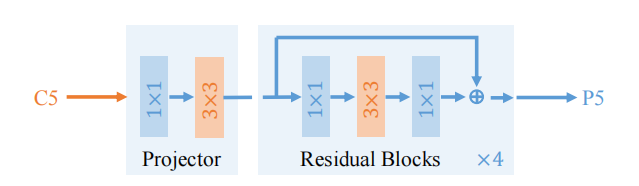
扩张编码器(Dilated Encoder):为了弥补单层特征在尺度范围上的不足,设计了扩张编码器,通过堆叠带有不同扩张率的残差块,生成具有多种感受野的输出特征,从而覆盖不同尺度的目标。
均匀匹配(Uniform Matching):针对单层特征中正样本锚点稀疏导致的不平衡问题,提出均匀匹配策略,为每个真实框均匀地分配相同数量的正样本锚点,确保所有真实框在训练中具有相同的贡献,解决了正样本锚点的不平衡问题。
检测流程简化:将检测流程划分为三个部分:骨干网络、编码器和解码器,其中编码器负责从骨干网络接收输入并为检测分配表示,解码器执行分类和回归任务并生成最终预测框。
创新点
性能提升:YOLOF 在 COCO 数据集上与 RetinaNet 相比,达到了相当的性能(37.7 mAP),但速度提高了 2.5 倍;与 DETR 相比,在单层特征检测方式下,YOLOF 的性能与 DETR 相当,但训练收敛速度提高了约 7 倍。
检测效率:通过简化检测流程,YOLOF 在保持较高检测精度的同时,显著提高了检测速度,降低了计算复杂度,使其更适合于实际应用中的快速目标检测任务。
单层特征的有效利用:证明了即使在单层特征的限制下,通过合理设计编码器和匹配策略,也能够实现与多尺度特征检测相当的性能,为单层特征检测提供了一种新的有效解决方案。
优化问题新视角:从优化问题的角度出发,重新审视了 FPN 在目标检测中的作用,提出了与传统 FPN 不同的解决方案,为后续目标检测方法的研究提供了新的思路和方向。

















 2093
2093

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









