






随着人工智能的发展,语言模型和生成模型获得了大量的成功并且在设计模型的过程中,模型的参数量也越来越大。对于细粒度理解任务,模型参数量也同样在增加。然而目前现有的数据集存在规模和精度的矛盾,例如 SA-1B 数据集中 99.1% 的 mask 都是机器生成的,但没有赋予语义的标签,而其他一些公开数据集也同样存在精度问题并且这些数据集的规模一般都比较小。
近几十年来,视觉界在视觉识别方面取得了显著进展,部分原因是数据集基准的进步。值得注意的是,建立的COCO基准推动了现代检测和分割系统的发展。然而,在过去十年中,COCO细分基准的改善相对缓慢。最初为“事物”实例配备了粗略的多边形注释,后来逐渐将“事物”区域的粗略超像素注释合并,随后对其进行启发式合并,以产生全景分割注释。这些注释由不同的评分者组执行,不仅导致了粗略的分割掩码,而且导致了分割类型之间的不一致。
COCO数据集的出现推动了图像分类、目标检测、语义分割、字幕生成等多项任务的高速发展。但是使用过COCO数据集的朋友们可能都知道,该数据的标注中存在着大量的问题,以下是几个主要的标注问题:
-
不准确的边界线--COCO数据集中存在着大量的不准确边界线标注问题,如凳子、空调线、树叶、屋顶等。
-
大量丢失的掩码--由于很多目标间存在着大量的遮挡,COCO数据集中存在着大量丢失的掩码信息。
-
松散的多边形标注--COCO数据集中存在着一些松散的多边形语义标注,只是利用一个多边形框住该目标,并没有精细标注该目标的边缘。
-
错误的语义标注--COCO数据集中存在着一些错误的语义标注,而这些错误的标注信息会给模型带来很大的误导。
为了给大家提供一个数据量更大、功能更全面、标注更精准的数据集,近期字节跳动提出了新一代细粒度理解的数据集,针对当代深度学习模型的设计需求,给总量为 383K 的图片进行了全景分割的人工标注,最后达到了 5.18M 张 mask,是至今最大规模的带人工标签的全景分割理解数据集,命名为 COCONut。

标注方法
通常只采用人工标注是非常昂贵的,这也是目前现存的大多数公开数据集规模上不去的一个重要原因。还有一些数据集直接使用模型生成的标签,但往往这种生成的标签对模型的训练不会有太大的提高,本文也验证了这一点。所以,提出一种新颖的标注方式,结合人工的半自动标签生成,既能保证数据标注的精度又能实现人工劳动力的节省成本,同时还能加速标注过程。
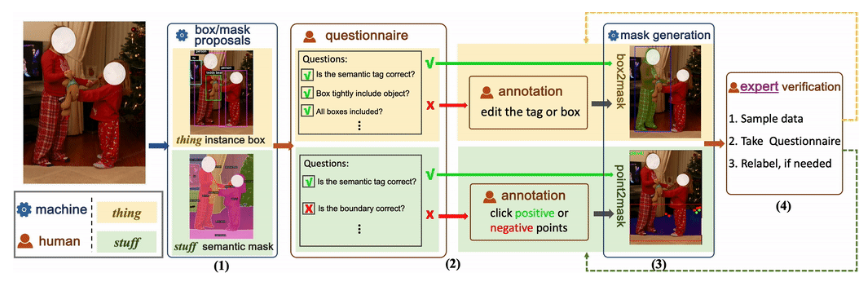
为了简化劳动密集型标记任务,该注释管道包括四个关键阶段:1)机器生成的伪标签;2)人工检查和编辑,3)掩模生成或细化;4)质量验证。承认“事物”类和“物质”类之间的内在区别,并在每个阶段系统地解决这些错综复杂的问题。
标注精度对比
把 COCONut 和 COCO 在同一张图上的标注进行对比。使用黄色虚线框描绘了来自COCO的错误注释,与COCONut更正注释并列。常见的COCO注释错误包括:注释过多(例如“人-人群”错误地扩展到“播放场”)、不完整的掩码片段(例如在小的隔离段中注释了“表合并”和“毯子”)、缺少注释(例如未注记“树合并”)、粗略分割(在由超级像素注释的“东西”区域和由松散多边形注释的“事物”区域中尤其明显)以及错误的语义类别(例如将“树合并的”错误地标记为“脏合并的”)。
通过观察可以发现,COCONut的部分标注结果在COCO的基础上面有了质的提升。从下图的对比可以看到本文提出的标注方法达到了和纯人工用 Photoshop 标注几乎一致的精度,但是在标注速度上提高了 10 倍以上。


COCONut 数据集详情
和已有的 COCO 数据集相比,数据集各个类别的分布比较相近,但是在每张图的 mask 总量上是超过 COCO 数据集的,尤其是有大量单张图片有超过100张 mask 的情况,由此说明了 COCONut 的标注更为精细,粒度分割更密集。
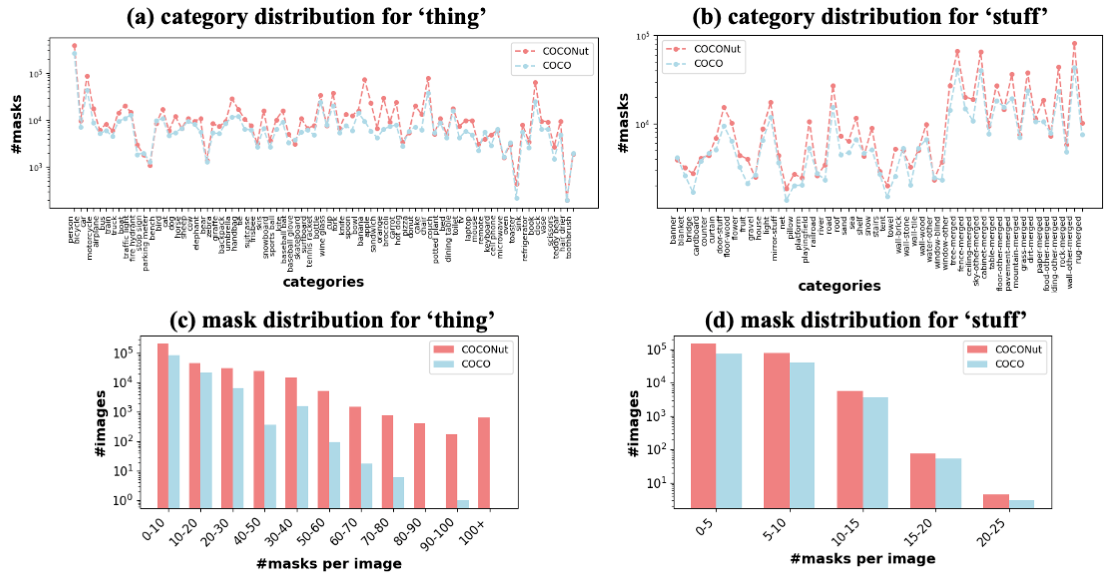
COCONut通过精心制作的高质量掩码,协调语义、实例和全景分割的分割注释,并为所有分割任务建立一个强大的基准。COCONut是第一个大规模通用分割数据集,由人工评分者验证,其发布将大大有助于社区评估新型神经网络进展的能力。
实验验证
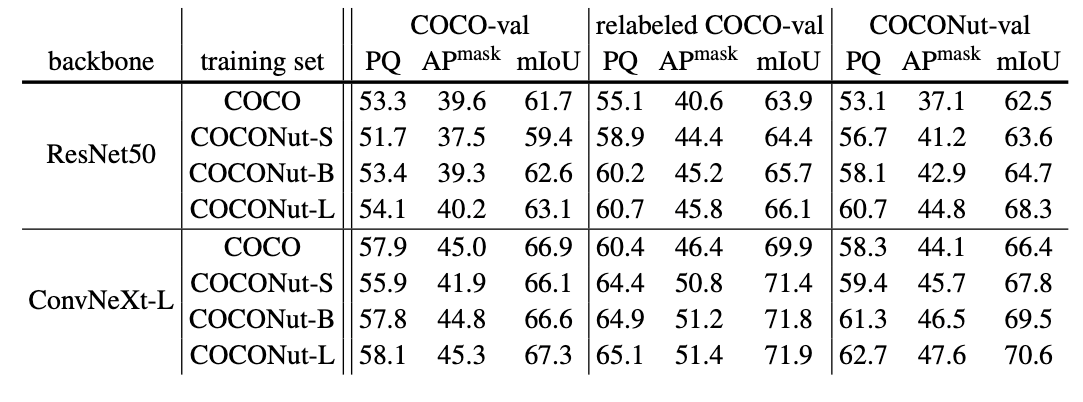
除了提出一个更好的训练集,研究者还发现现有的验证集不能很好的体现模型性能的提升,因此本文还提出了一个更加富有挑战性的、可以反映模型的提升的测试集,命名为 COCONut-val. 从下表可以看到,仅替换数据集,更高精度的训练集可以带来模型很大的提升,例如在全景分割上达到超过 4 个点的 PQ。然而当训练集的规模增加了之后,可以发现,用现有的测试集做测试并不能反映出模型的提升,而 COCONut-val 则能反映出模型在增加了训练集数据量之后仍然有明显的提升。
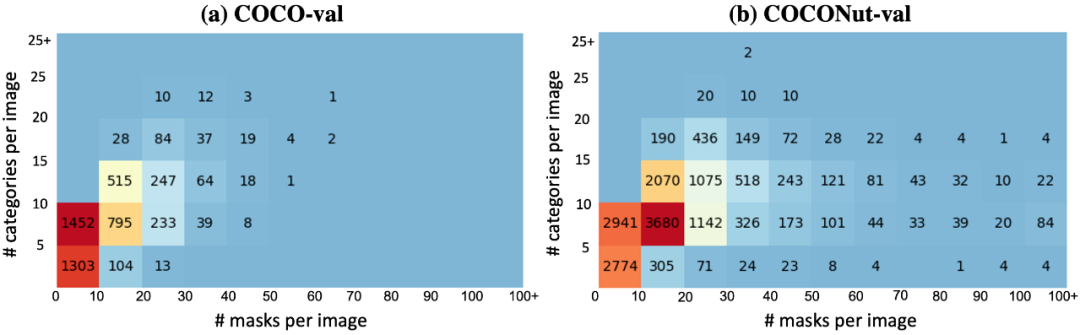
下图为验证集语义类别和 mask 密度的对比,可以看出新提出的验证集更具有挑战性,更能反映模型的提升。

















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









