







【深度学习|学习笔记】 Feed-Forward Neural Network(前馈神经网络,FFNN)详解,附代码
【深度学习|学习笔记】 Feed-Forward Neural Network(前馈神经网络,FFNN)详解,附代码
文章目录
欢迎铁子们点赞、关注、收藏!
祝大家逢考必过!逢投必中!上岸上岸上岸!upupup
大多数高校硕博生毕业要求需要参加学术会议,发表EI或者SCI检索的学术论文会议论文。详细信息可关注VX “
学术会议小灵通”或参考学术信息专栏:https://blog.csdn.net/2401_89898861/article/details/146957339
一、起源
前馈神经网络(Feed-Forward Neural Network, FFNN) 是最基础的神经网络结构。它源自 1943 年 McCulloch 和 Pitts 提出的人工神经元模型,后来由 Frank Rosenblatt 在 1958 年发展为感知机模型(Perceptron)。
发展脉络:
- 1943:神经元模型(McCulloch & Pitts)
- 1958:单层感知机(Perceptron)
- 1986:误差反向传播算法(Backpropagation)解决多层网络训练
- 2010s-至今:深层前馈网络广泛用于分类、回归、表示学习等
二、原理
1. 结构组成
前馈神经网络由多个层级结构组成,层与层之间是全连接(Fully Connected):
- 输入层(Input Layer)
- 隐藏层(Hidden Layer)
- 输出层(Output Layer)
每一层的神经元都与上一层的所有神经元相连,数据在网络中单向前传,无反馈。
2. 激活函数(非线性)
常用激活函数:
- ReLU(最常用)
- Sigmoid(适用于概率输出)
- Tanh(早期常用)
3. 前向传播过程(Forward Pass):
对于第 l l l 层的输出:
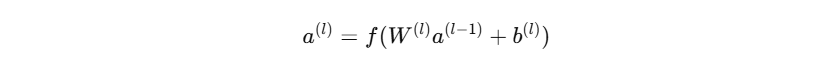
其中:
- W ( l ) W^{(l)} W(l):权重矩阵
- b ( l ) b^{(l)} b(l):偏置向量
- f f f:激活函数
4. 反向传播(Backward Pass):
- 通过链式法则计算梯度,并利用梯度下降算法更新参数。
三、发展

四、改进方向
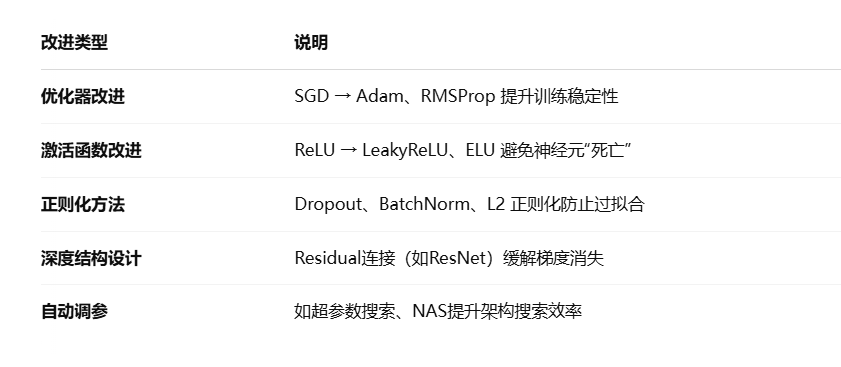
五、应用领域

六、PyTorch 实现示例
以下为一个简单的前馈神经网络,用于对 MNIST 手写数字进行分类。
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
# 定义前馈神经网络(FFNN)
class FeedForwardNN(nn.Module):
def __init__(self, input_size=784, hidden_sizes=[256, 128], num_classes=10):
super(FeedForwardNN, self).__init__()
self.fc1 = nn.Linear(input_size, hidden_sizes[0])
self.relu1 = nn.ReLU()
self.fc2 = nn.Linear(hidden_sizes[0], hidden_sizes[1])
self.relu2 = nn.ReLU()
self.fc3 = nn.Linear(hidden_sizes[1], num_classes)
def forward(self, x):
x = x.view(x.size(0), -1) # 展平
x = self.relu1(self.fc1(x))
x = self.relu2(self.fc2(x))
x = self.fc3(x)
return x
# 训练参数
batch_size = 64
epochs = 5
lr = 0.001
# 加载数据
transform = transforms.Compose([transforms.ToTensor()])
train_dataset = datasets.MNIST(root='./data', train=True, transform=transform, download=True)
train_loader = DataLoader(dataset=train_dataset, batch_size=batch_size, shuffle=True)
# 实例化模型
model = FeedForwardNN()
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=lr)
# 训练过程
for epoch in range(epochs):
for i, (images, labels) in enumerate(train_loader):
outputs = model(images)
loss = criterion(outputs, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if (i+1) % 100 == 0:
print(f"Epoch [{epoch+1}/{epochs}], Step [{i+1}/{len(train_loader)}], Loss: {loss.item():.4f}")
七、总结
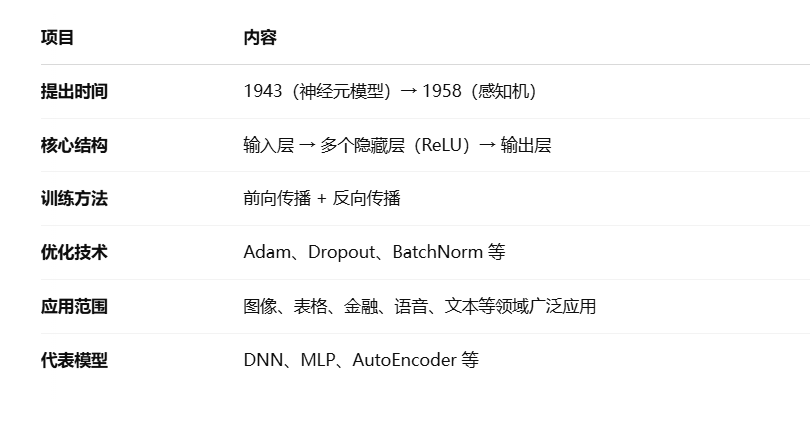


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











