







论文: https://arxiv.org/html/2404.14327v1
代码:https://jchengai.github.io/pluto/
0. 摘要
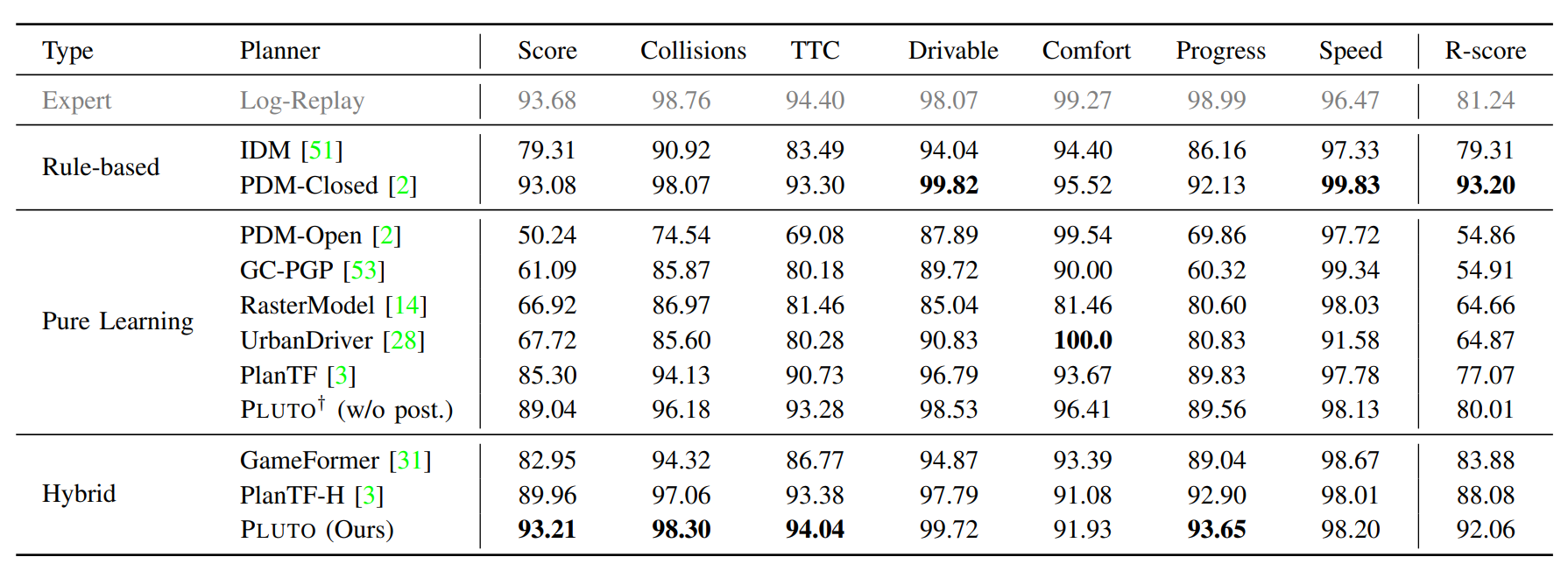
PLUTO(Pushing the Limit of Imitation Learning-based Planning for Autonomous Driving)是一个强大的框架,旨在通过模仿学习推动自动驾驶规划的极限。该框架的改进主要体现在三个方面:首先是纵向-横向感知模型架构,它能够使驾驶行为更加灵活多样;其次是创新的辅助损失计算方法,这种方法适用范围广泛且能够高效地进行批量计算;最后是新的训练框架,它利用对比学习,并结合一系列新的数据增强方法来调节驾驶行为,促进对底层交互的理解。PLUTO框架在大规模真实世界的nuPlan数据集上进行了评估,并展示了其卓越的闭环性能,首次超越了其他基于学习的方法和当前表现最佳的基于规则的规划器。
1. 创新点
-
query-based模型架构:PLUTO提出的纵向-横向感知模型架构,有效融合了纵向和横向控制,提高了模型在复杂交通场景下的适应性和决策能力。
-
辅助损失计算方法:基于可微分插值的辅助损失计算方法,为模型提供了显式的行为约束,增强了模型的安全性和泛化能力。
-
对比学习与数据增强:CIL框架和数据增强技术的应用,提升了模型对环境交互的理解,增强了模型的鲁棒性和适应性。
2. PLUTO框架
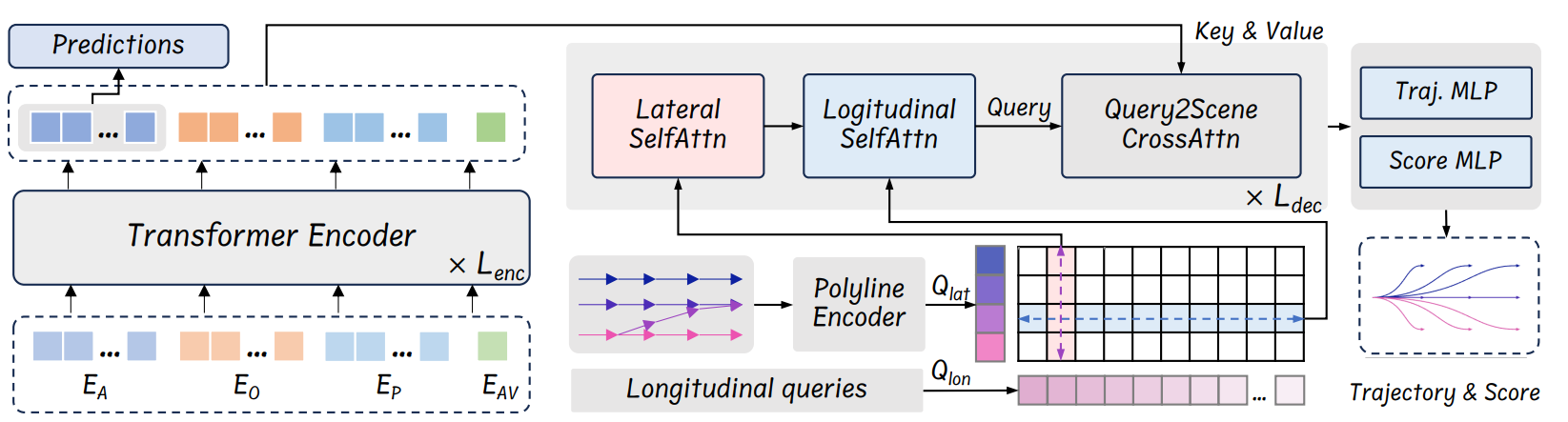
2.1 框架的三个关键改进方向
PLUTO框架,即“Pushing the Limit of Imitation Learning-based Planning for Autonomous Driving”,旨在通过三个关键改进方向来提升自动驾驶规划的性能和效率。这些改进方向包括模型架构的创新、辅助损失计算方法的优化以及训练框架的革新。
模型架构的创新:
PLUTO框架提出了一种纵向-横向感知模型架构,这种架构能够使模型展现出灵活多样的驾驶行为。根据[7]的研究,传统的模仿学习规划器在纵向任务(如车道保持)上表现良好,但在横向任务(如变道或绕障)上存在不足。PLUTO通过融合纵向和横向查询的查询式架构,生成多样化的规划方案,从而增强了模型在处理复杂交通场景时的能力。这种架构的改进使得PLUTO在[8]的nuPlan数据集上实现了前所未有的封闭环路性能,超越了现有的基于规则的规划器。
辅助损失计算方法的优化:
PLUTO框架引入了一种基于可微插值的辅助损失计算方法,这种方法不仅适用于广泛的辅助任务,而且能够在现代深度学习框架中实现批量计算,提高了效率。如[9]所述,传统的辅助损失方法要么受限于特定的输出分辨率,要么需要不同的可微光栅化器,这些限制影响了模型的性能和适用性。PLUTO的新方法通过在训练阶段施加显式约束,尤其是在自动驾驶的安全关键领域,有效地指导模型学习期望的驾驶行为。
训练框架的革新:
PLUTO框架采用了一种新颖的训练框架,即对比模仿学习&#
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 764
764

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









