







【基本流程介绍】
使用YOLOv8训练自己的数据集是一个涉及多个步骤的过程,包括环境搭建、数据集准备、配置文件编写、模型训练等。以下是一个详细的流程指南:
一、环境搭建
- 安装Python:建议使用Python 3.8或更高版本。
- 安装PyTorch:确保安装了与CUDA兼容的PyTorch版本,以便利用GPU加速训练。
- 安装Ultralytics YOLOv8:通过pip安装Ultralytics YOLOv8库,以及用于监控训练过程的wandb库(可选)。
pip install ultralytics wandb
- 配置CUDA环境:如果计划使用GPU进行训练,需要确保已正确安装NVIDIA驱动和CUDA Toolkit。
二、数据集准备
-
收集图像:收集与目标检测任务相关的图像,并确保图像质量良好。
-
标注图像:使用标注工具(如Labelimg)对图像进行标注,生成YOLO格式的标签文件(.txt)。每个标签文件包含图像中每个目标的类别和边界框坐标。
- 安装Labelimg:在Python虚拟环境中安装Labelimg。
- 创建数据集文件夹:包括images(存放图像)和labels(存放标签)两个子文件夹。
- 使用Labelimg进行标注:打开Labelimg,选择images文件夹作为图像源,选择labels文件夹作为标签保存位置,然后进行标注。
-
数据集划分:将数据集划分为训练集、验证集和测试集(可选,但推荐)。通常的比例为8:1:1或类似比例。可以使用脚本或手动方式完成数据集划分。
三、配置文件编写
- 创建YAML配置文件:编写一个YAML配置文件,指定数据集的路径、类别数量和类别名称等信息。例如:
# data.yaml
path: ../datasets/MyDataSet # 数据集根路径
train: ./train # 训练集路径
val: ./val # 验证集路径
nc: 2 # 类别数量
names: ['class1', 'class2'] # 类别名称
四、模型训练
- 加载预训练模型:从Ultralytics提供的预训练模型中选择一个作为基础模型。例如,可以选择’yolov8n.pt’(YOLOv8 Nano版本)作为轻量级模型。
- 设置训练参数:包括训练轮数(epochs)、输入图像大小(imgsz)、批处理大小(batch_size)、数据加载器的工作线程数量(workers)以及使用的GPU编号(device)等。
- 开始训练:使用Ultralytics YOLOv8库提供的训练函数开始训练模型。例如:
from ultralytics import YOLO
# 加载预训练模型
model = YOLO('yolov8n.pt')
# 定义数据集配置文件路径
data_config = 'path/to/your/data.yaml' # 替换为你的data.yaml文件的实际路径
# 设置训练参数
epochs = 100
imgsz = 640
batch_size = 16
workers = 8
device = 0 # 使用GPU编号,如果使用CPU则设为None或'cpu'
# 开始训练
results = model.train(
data=data_config,
epochs=epochs,
imgsz=imgsz,
batch=batch_size,
workers=workers,
device=device,
name='yolov8_custom_train', # 模型保存名称
save=True, # 是否保存模型
exist_ok=True, # 如果存在相同命名的训练结果是否覆盖
cache=False # 是否缓存数据以加速训练
)
print("训练完成:", results.save_dir)
- 训练过程可视化(可选):使用wandb库查看训练过程中的损失、准确率等指标,以便及时调整训练参数或优化模型。
五、模型评估与测试
- 评估模型性能:在验证集上评估模型的性能,包括准确率、召回率等指标。
- 测试模型:使用测试集测试模型的泛化能力,并检查是否存在过拟合或欠拟合等问题。
- 优化模型:根据评估结果和测试反馈,调整模型结构、训练参数或数据集划分等,以提高模型性能。
六、模型部署与应用
- 导出模型:将训练好的模型导出为可用于推理的格式(如.pt文件)。
- 集成到应用程序中:将导出的模型集成到目标检测应用程序中,实现实时检测或批量检测等功能。
通过以上步骤,您可以成功地使用YOLOv8训练自己的数据集,并得到一个性能良好的目标检测模型。请注意,在实际操作中可能需要根据具体情况进行调整和优化。
【详细步骤介绍】
首先需要准备带有nvidia显卡笔记本电脑,如果没有独立显卡也行只不过训练会很慢。我们打开cmd输入nvidia-smi检查自己电脑显卡
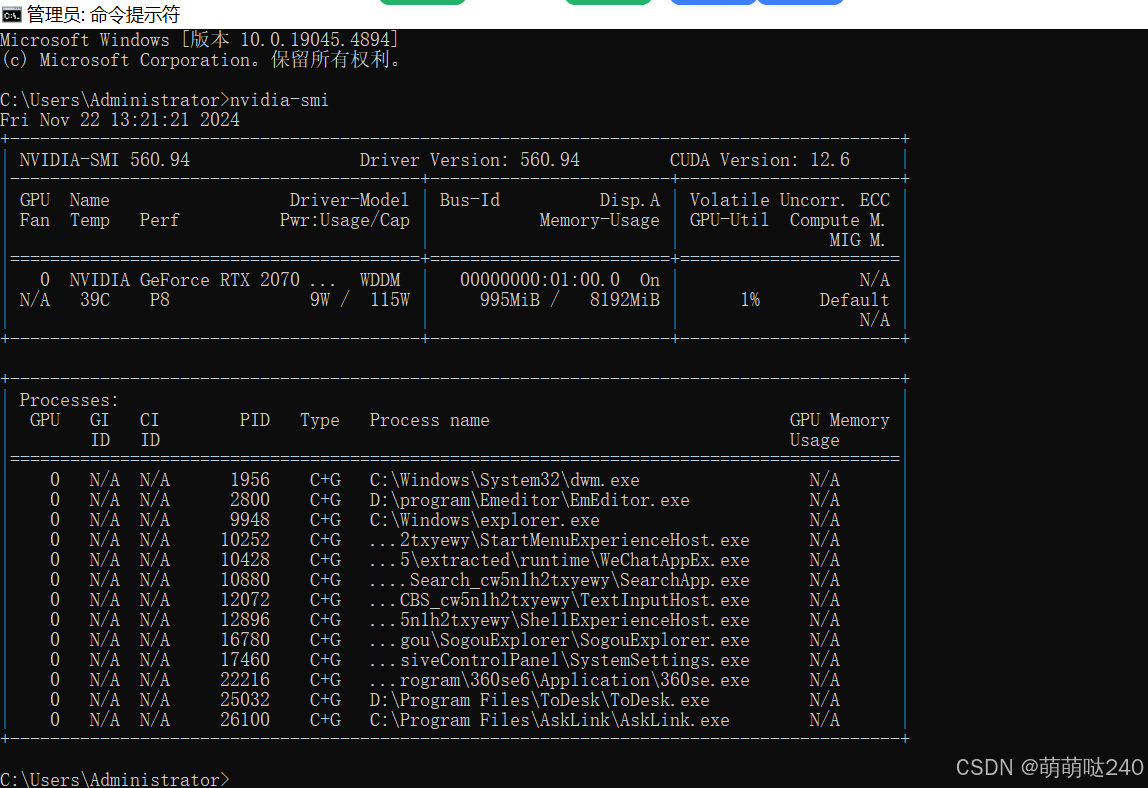
可以看到我电脑是RTX2070显卡非常适合训练模型。下面我们将需要安装好yolov8环境。首先如果我们电脑有独立显卡可以安装gpu版本的pytorch,若无独立显卡则安装CPU版本的pytorch.我们先安装anaconda3和pycharm,如果安装过可以跳过此步骤:
Anaconda3由于是国外网站下载较慢,推荐通过清华镜像源安装,打开网站mirrors.tuna.tsinghua.edu.cn/anaconda/archive/
找到自己适配的操作系统比如我是windows电脑可以下载Anaconda3-2021.05-Windows-x86_64.exe,不需要最新也不需要很老版本即可。
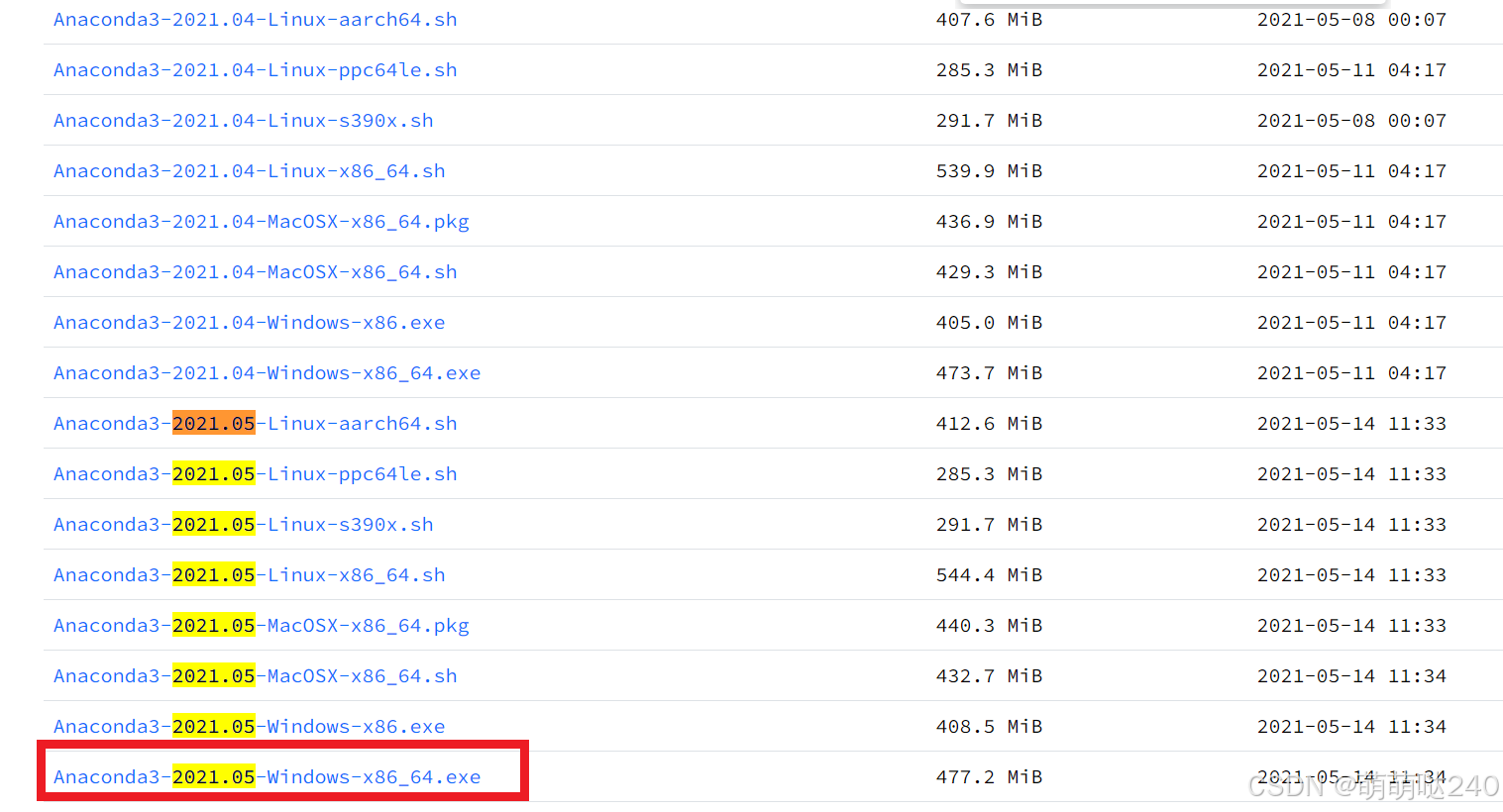
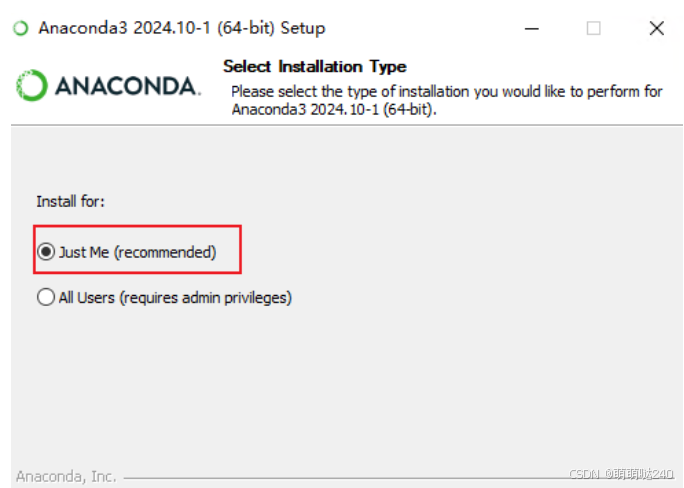
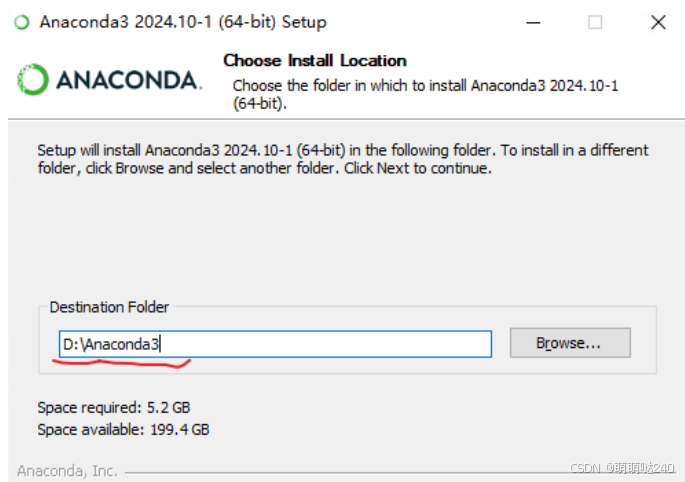
下载完成之后打开Anaconda3进行安装,一直点下一步,选Just Me,安装路径不建议安装到c盘,因为可能C盘会有权限,如果你只有C盘可以选择安装在C:\Users\你用的用户名下面,可以直接复制粘贴修改到 D:\Anaconda3 ,也可以修改到其他路径,最好纯英文路径连空格也不要有。
点击下一步后,需要选择添加到环境变量,如下图前三个一定要勾选,也可以按照我图中全选。
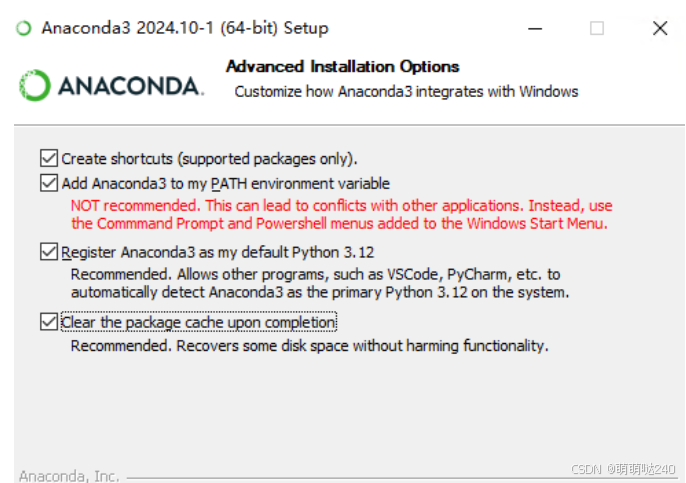
点击install安装后根据电脑性能安装完即可,快的话3分钟完成,慢的话25分钟完成。
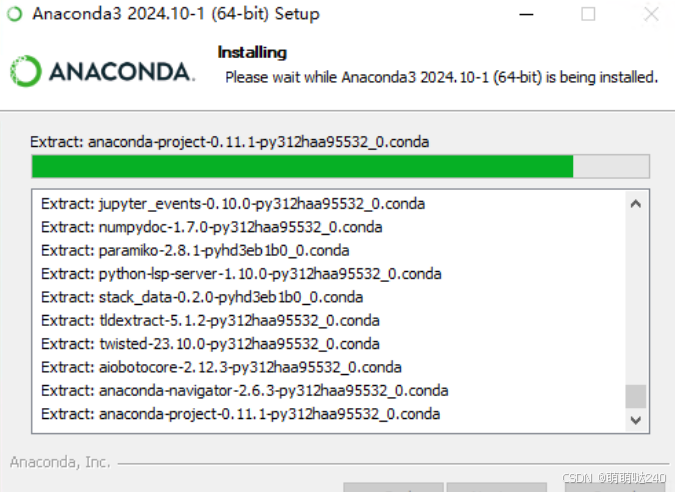
安装Pycharm可以直接去官网下载,速度较快。往下拉下载第二个Community Edition社区免费版就可以。
下载后得到exe文件双击安装即可,其他均选择默认即可,安装路径随便指定,建议下面选择适合全部勾选即可
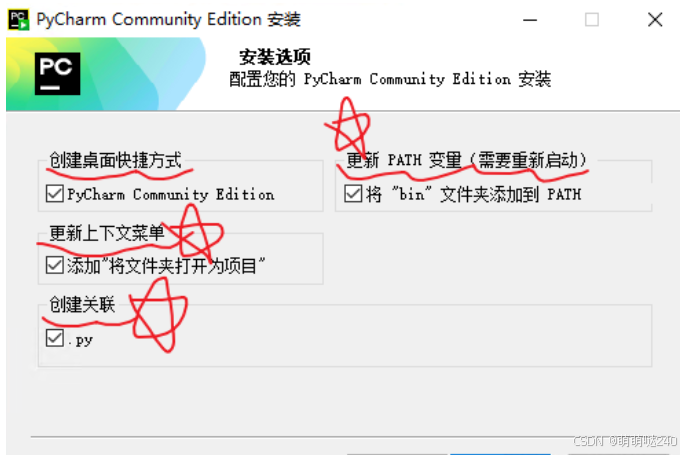
接下来开始安装yolov8环境我们打开anaconda prompt
这里创建一个名为yolov8,python版本为3.9的虚拟环境,也可以修改为其他名或者python版本,选择替换即可。
conda create -n yolov8 python=3.9 -y
然后安装pytorch
如果安装GPU版本可以用下面命令:
pip install torch2.0.0+cu118 torchvision0.15.1+cu118 --extra-index-url https://download.pytorch.org/whl/cu118
如果安装CPU版本pytorch可以用下面命令:
conda install pytorch torchvision torchaudio cpuonly -c pytorch
安装yolov8:
pip install ultralytics
验证环境:
去官方克隆源码:github.com/ultralytics/ultralytics/,当然也不需要。但是你必须要下载模型,在源码页面找到模型点击下载,推荐下载yolov8n.pt
下载完成后将文件复制到ultralytics根目录下,此时可以去网上下载一个jpg图片或者其它图片,根据自己喜好更改下,修改文件名为test.jpg。
检测环境是否有问题可以在prompt里yolov8环境下运行,如果你的路径有空需要用双引号引起来:
yolo predict model=yolov8n.pt source=test.jpg

至此上面环境安装完成,接下来开始准备数据集
数据集可以使用网上公开的跟自己研究需要的数据集,或者是搜索/拍摄自己研究所需要的图片进行标注制作成数据集,自制数据集需要先获取一定数量的目标图片,可以拍摄或者下载,图片足够之后使用标注工具Labelimg进行标注
使用Labelimg建议使用python3.9及其以下的环境,这里创建一个python3.8的虚拟环境
conda create -n labelimg python=3.8
这里创建完之后进入labelimg环境
conda activate labelimg
进入labelimg环境之后通过pip下载labelimg(需要关闭加速软件)
pip install labelimg -i https://pypi.tuna.tsinghua.edu.cn/simple
安装完成之后打开labelImg即可使用
在使用labelimg之前,需要准备好数据集存放位置,这里推荐创建一个大文件夹为data,里面有JPEGImages、Annotations和classes.txt,其中JPEGImages文件夹里面放所有的图片,Annotations文件夹是将会用来对标签文件存放,classes.txt里存放所有的类别,每种一行
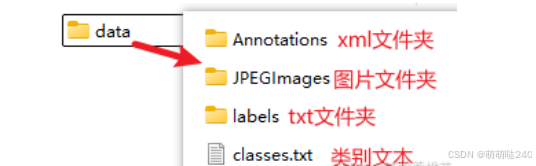
classes.txt里存放所有的类别,可以自己起名,需要是英文字母和下划线,其他不要有比如空格中文

上述工作准备好之后,在labelimg环境中cd到data目录下,如果不是在c盘需要先输入其他盘符+:
例如d: 回车之后再输入文件路径,接着输入以下命令打开labelimg
labelimg JPEGImages classes.txt
打开软件后可以看到左侧有很多按钮,open dir是选择图片文件夹,上面选过了
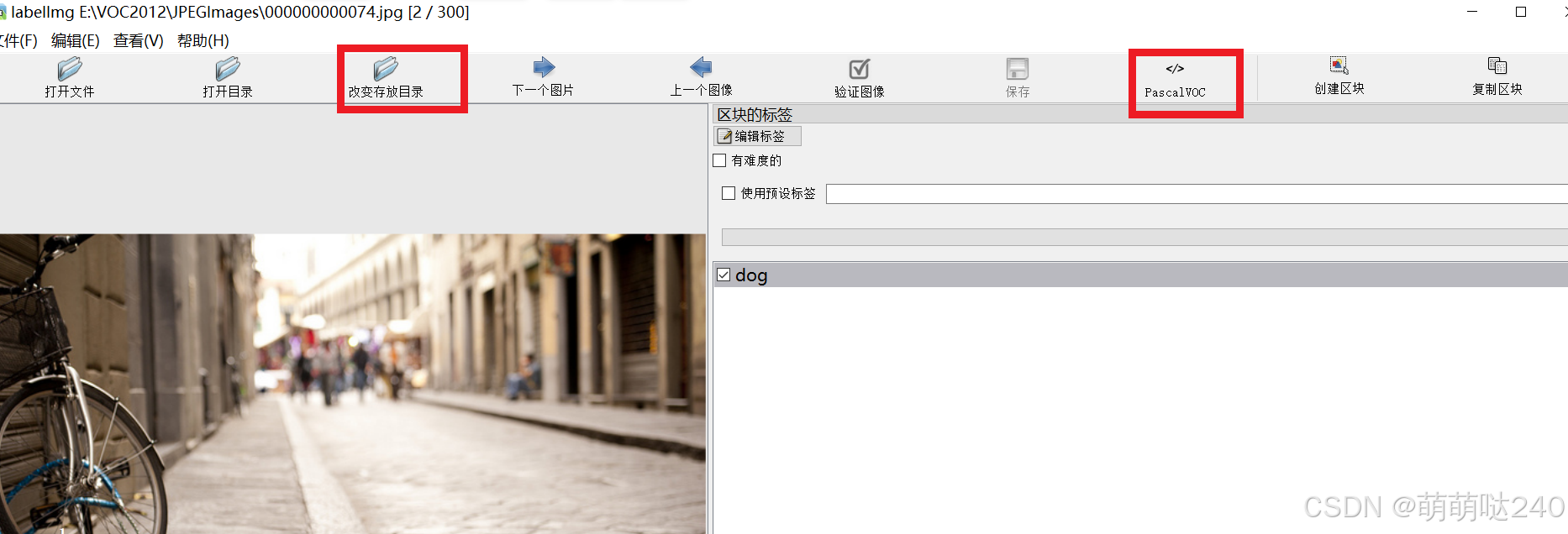
点击change save dir 切换到Annotations目录之中,点击save下面的图标切换到pascal voc格式
切换好之后点击软件上边的view,将 Auto Save mode(切换到下一张图会自动保存标签)和Display Labels(显示标注框和标签) 保持打开状态。
常用快捷键:
A:切换到上一张图片
D:切换到下一张图片
W:调出标注十字架
del :删除标注框
例如,按下w调出标注十字架,标注完成之后选择对应的类别,这张图全部标注完后按d下一张
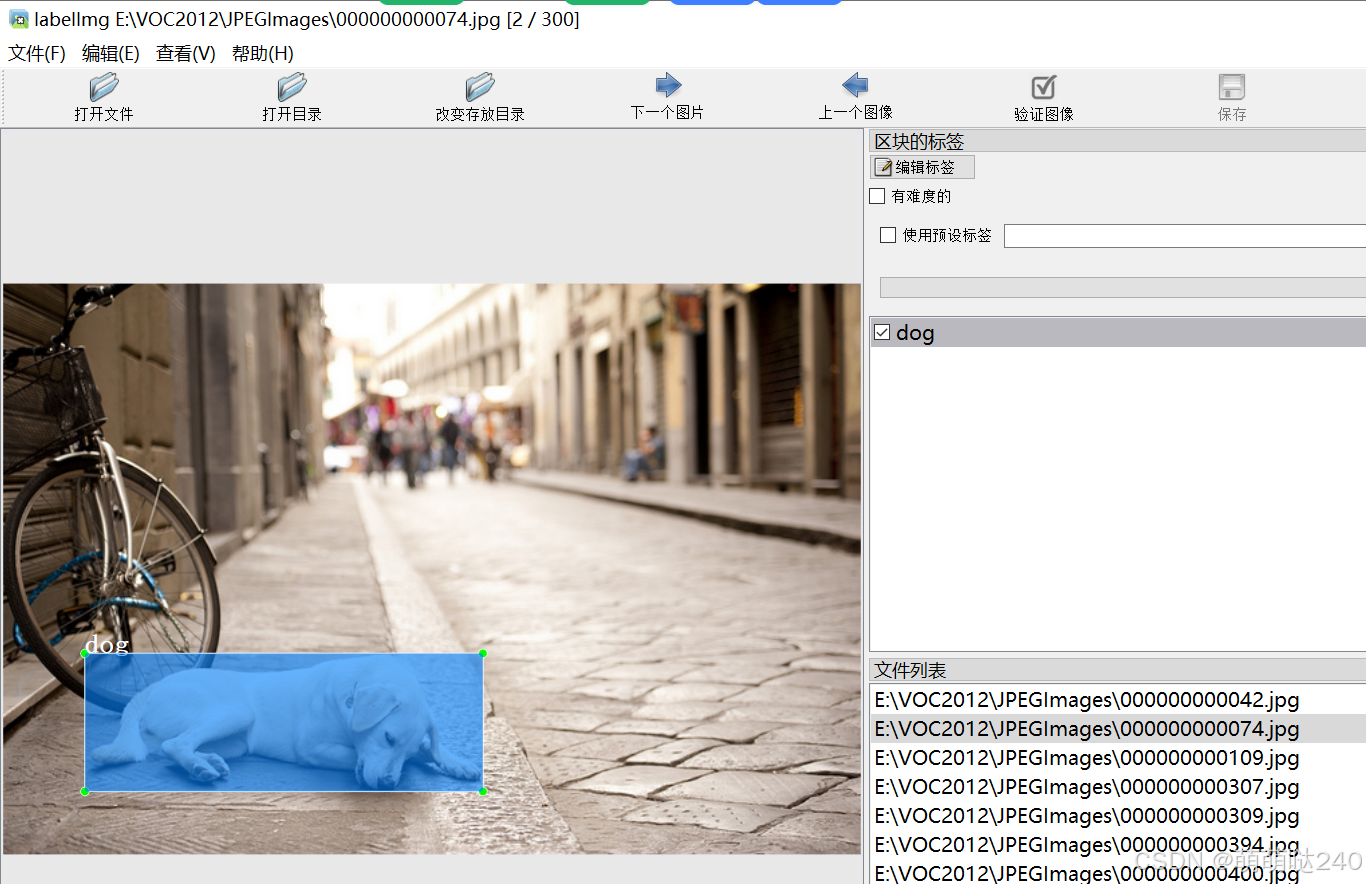
按照上面标注顺序完成标注即可。
接下来我们转换数据集格式
打开Annotations文件夹,如果看到文件后缀为.xml,则为VOC格式,如果文件后缀为.txt则为yolo格式,后缀名看不到请搜索 如何显示文件后缀名。yolov8训练需要转为yolo格式训练,转换代码如下:
import os
import shutil
import xml.etree.ElementTree as ET
# VOC格式数据集路径
voc_data_path = r'E:\DataSet\VOC2012'
voc_annotations_path = os.path.join(voc_data_path, 'Annotations')
voc_images_path = os.path.join(voc_data_path, 'JPEGImages')
# YOLO格式数据集保存路径
yolo_data_path = 'E:\\DataSet\\helmet-YOLO'
yolo_images_path = os.path.join(yolo_data_path, 'images')
yolo_labels_path = os.path.join(yolo_data_path, 'labels')
# 创建YOLO格式数据集目录
os.makedirs(yolo_images_path, exist_ok=True)
os.makedirs(yolo_labels_path, exist_ok=True)
# 类别映射 (可以根据自己的数据集进行调整)
class_mapping = {
'dog': 0,
'cat': 1,
# 添加更多类别...
}
def convert_voc_to_yolo(voc_annotation_file, yolo_label_file):
tree = ET.parse(voc_annotation_file)
root = tree.getroot()
size = root.find('size')
width = float(size.find('width').text)
height = float(size.find('height').text)
with open(yolo_label_file, 'w') as f:
for obj in root.findall('object'):
cls = obj.find('name').text
if cls not in class_mapping:
continue
cls_id = class_mapping[cls]
xmlbox = obj.find('bndbox')
xmin = float(xmlbox.find('xmin').text)
ymin = float(xmlbox.find('ymin').text)
xmax = float(xmlbox.find('xmax').text)
ymax = float(xmlbox.find('ymax').text)
x_center = (xmin + xmax) / 2.0 / width
y_center = (ymin + ymax) / 2.0 / height
w = (xmax - xmin) / width
h = (ymax - ymin) / height
f.write(f"{cls_id} {x_center} {y_center} {w} {h}\n")
# 遍历VOC数据集的Annotations目录,进行转换
for voc_annotation in os.listdir(voc_annotations_path):
if voc_annotation.endswith('.xml'):
voc_annotation_file = os.path.join(voc_annotations_path, voc_annotation)
image_id = os.path.splitext(voc_annotation)[0]
voc_image_file = os.path.join(voc_images_path, f"{image_id}.jpg")
yolo_label_file = os.path.join(yolo_labels_path, f"{image_id}.txt")
yolo_image_file = os.path.join(yolo_images_path, f"{image_id}.jpg")
convert_voc_to_yolo(voc_annotation_file, yolo_label_file)
if os.path.exists(voc_image_file):
shutil.copy(voc_image_file, yolo_image_file)
print("转换完成!")
划分数据集进行训练
import os
import shutil
import random
def make_yolo_dataset(images_folder, labels_folder, output_folder, train_ratio=0.8):
# 创建目标文件夹
images_train_folder = os.path.join(output_folder, 'images/train')
images_val_folder = os.path.join(output_folder, 'images/val')
labels_train_folder = os.path.join(output_folder, 'labels/train')
labels_val_folder = os.path.join(output_folder, 'labels/val')
os.makedirs(images_train_folder, exist_ok=True)
os.makedirs(images_val_folder, exist_ok=True)
os.makedirs(labels_train_folder, exist_ok=True)
os.makedirs(labels_val_folder, exist_ok=True)
# 获取图片和标签的文件名(不包含扩展名)
image_files = [f for f in os.listdir(images_folder) if f.endswith('.jpg')]
label_files = [f for f in os.listdir(labels_folder) if f.endswith('.txt')]
image_base_names = set(os.path.splitext(f)[0] for f in image_files)
label_base_names = set(os.path.splitext(f)[0] for f in label_files)
# 找出图片和标签都存在的文件名
matched_files = list(image_base_names & label_base_names)
# 打乱顺序并划分为训练集和验证集
random.shuffle(matched_files)
split_idx = int(len(matched_files) * train_ratio)
train_files = matched_files[:split_idx]
val_files = matched_files[split_idx:]
# 移动文件到对应文件夹
for base_name in train_files:
img_src = os.path.join(images_folder, f"{base_name}.jpg")
lbl_src = os.path.join(labels_folder, f"{base_name}.txt")
img_dst = os.path.join(images_train_folder, f"{base_name}.jpg")
lbl_dst = os.path.join(labels_train_folder, f"{base_name}.txt")
shutil.copyfile(img_src, img_dst)
shutil.copyfile(lbl_src, lbl_dst)
for base_name in val_files:
img_src = os.path.join(images_folder, f"{base_name}.jpg")
lbl_src = os.path.join(labels_folder, f"{base_name}.txt")
img_dst = os.path.join(images_val_folder, f"{base_name}.jpg")
lbl_dst = os.path.join(labels_val_folder, f"{base_name}.txt")
shutil.copyfile(img_src, img_dst)
shutil.copyfile(lbl_src, lbl_dst)
print("数据集划分完成!")
# 使用示例
images_folder = 'path/to/your/images_folder' # 原始图片文件夹路径
labels_folder = 'path/to/your/labels_folder' # 原始标签文件夹路径
output_folder = 'path/to/your/output_folder' # 存放结果数据集的文件夹路径
make_yolo_dataset(images_folder, labels_folder, output_folder)
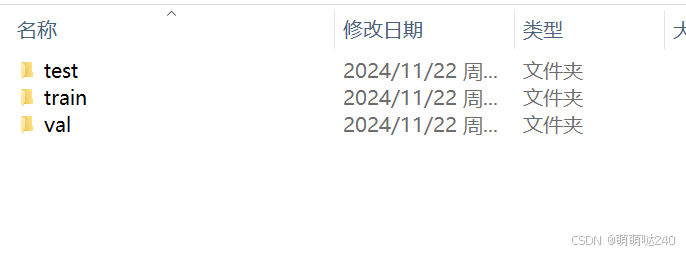
最后看到有train,val,test文件夹生成
开始训练模型
创建data.yaml
在yolov8根目录下(也就是官方源码的ultralytics-main目录下)创建一个新的data.yaml文件,也可以是其他名字的例如mydata.yaml文件,文件名可以变但是后缀需要为.yaml,内容如下
train: E:/VOC2012/train/images # train images (relative to 'path') 128 images
val: E:/VOC2012/val/images # val images (relative to 'path') 128 images
test: E:/VOC2012/test/images
nc: 2
# Classes
names: ['dog','cat']
其他路径和类别自己替换,需要和上面数据集转换那里类别顺序一致。
训练模型
这是使用官方提供的预训练权重进行训练,使用yolov8n.pt,也可以使用yolov8s.pt,模型大小n<s<m<l<x,训练时长和显存成倍增加。
新建个train.py文件
from ultralytics import YOLO
#多线程添加代码
if __name__ == '__main__':
model = YOLO('yolov8n.yaml').load('yolov8n.pt')
# # 训练模型
results = model.train(data='data.yaml', epochs=100, imgsz=640, device=0, workers=2, batch=16, optimizer='SGD', amp=False)
这里用哪个模型对应哪个yaml,如果使用yolov8s.pt则对应yolov8s.yaml
epochs是训练轮数,可以由少变多看训练效果,workers和batch根据电脑性能来,如果运行不起来则相应降低,最好为2的n次方。
也可以使用命令行执行训练
yolo task=detect mode=train model=yolov8n.yaml pretrained=yolov8n.pt data=data.yaml epochs=100 imgsz=640 device=0 workers=2 batch=16
训练完成后会在源码目录runs里面有模型生成,可以进去weights文件夹找到best.pt或者last.pt模型
模型测试
找到之前训练的结果保存路径,创建一个predict.py文件,内容如下
from ultralytics import YOLO
# 加载训练好的模型,改为自己的路径
model = YOLO('runs/detect/train/weights/best.pt')
# 修改为自己的图像或者文件夹的路径
source = 'test.jpg' #修改为自己的图片路径及文件名
# 运行推理,并附加参数
model.predict(source, save=True)
或者使用命令行指令进行预测,权重和图片路径自己修改。
yolo predict model=runs/detect/train/weights/best.pt source=test.jpg
之后会在runs文件夹生成预测结果打开里面图片查看预测结果即可。这样完整流程介绍完毕

















 1554
1554

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









