






注意力机制与多任务学习的融合已成为人工智能领域的重要研究方向。注意力机制能够让模型在处理多任务时,依据任务的重要性动态分配资源,聚焦关键信息,有效提升多任务学习的性能。
例如,TADFormer 将注意力机制巧妙融入多任务学习框架,精准捕捉任务特定特征,并以极少的参数实现了高精度的密集场景理解任务,充分展现了注意力机制在优化多任务学习方面的巨大潜力。
这些成果极大地推动了多任务学习技术的进步,为解决复杂场景下的多任务处理问题提供了高效的手段。我精心整理了 10 种【注意力机制 + 多任务学习】的相关论文,全部论文PDF版可以关注工棕号{顶会攻略}
回复 “注意任务” 即可领取
1.TADFormer:用于高效多任务学习的任务自适应动态 Transformer
文章解析:
论文提出 TADFormer,一种新型参数高效微调(PEFT)框架,通过任务提示条件(TPC)算子和动态任务滤波器(DTF),动态提取任务特定特征。在 PASCAL-Context 基准测试中,该方法在减少可训练参数的同时提升了密集场景理解任务的精度。
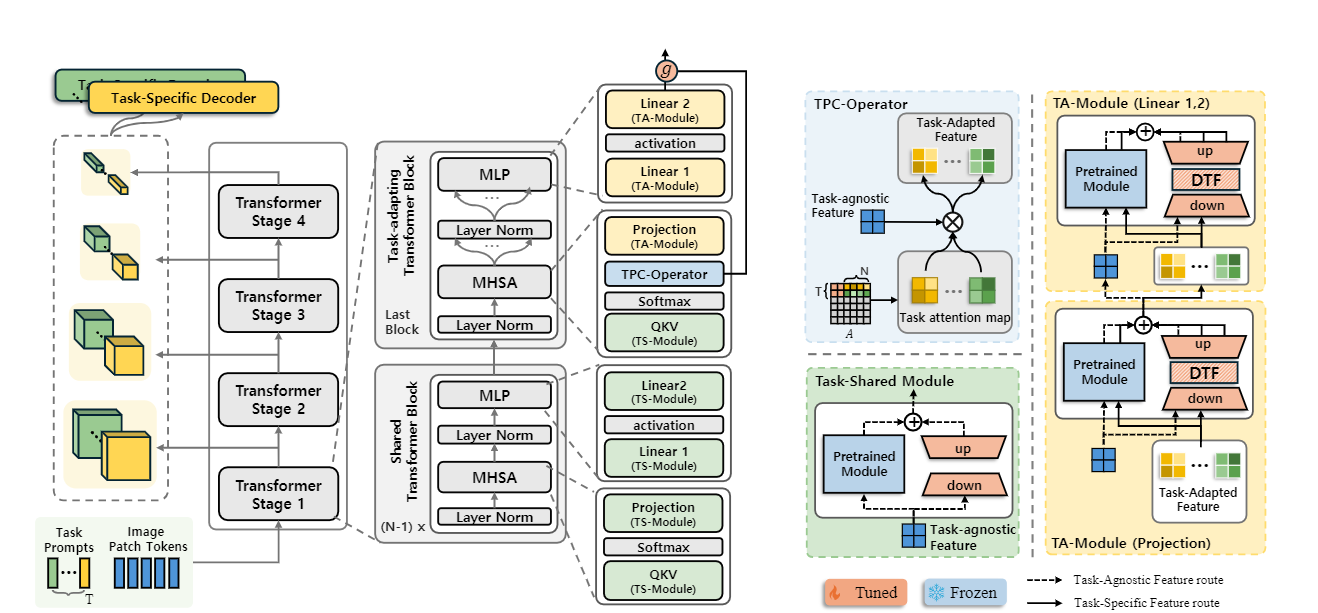
创新点:
1.利用 DTF,依据输入上下文动态提取任务特定的细粒度特征,增强模型对任务独特性的捕捉能力。
2.在编码器中引入基于提示的任务适配机制,减少参数数量的同时有效学习任务特定特征。
3.相比全模型微调及其他 PEFT 方法,TADFormer 以更少参数实现更高精度,参数效率更优。
研究方法:
1.构建由任务共享编码器和多个任务特定解码器组成的架构,在特定模块中融入 TPC 算子和 DTF。
2.在 PASCAL-Context 数据集上,与多种 PEFT 方法对比,评估指标包括平均交并比(mIoU)、均方根误差(rmse)等。
3.对 TADFormer 的关键组件进行消融实验,探究各部分对模型性能的影响。
研究结论:
1.在语义分割、人体部位分割等任务上,TADFormer 相比基线方法精度更高,相对改进值 Δm 更优。
2.TPC 算子和 DTF 对模型性能提升作用显著,任务注意力图在生成任务适配特征中意义重大。
3.TADFormer 适用于不同骨干网络、预训练数据集和解码器,还可扩展到基于适配器的方法。
2.通过多任务学习 Transformer 提升眼动追踪性能
文章解析:
论文提出将多任务学习与视觉 Transformer 相结合,引入 EEG 信号重建子模块,以提升 EEG 眼动追踪任务的模型性能。该方法在 EEGEyeNet 数据集上进行实验,结果表明其能有效提高特征表示能力,优于现有方法。
创新点:
1.创新地将多任务学习框架与 Transformer 结合,通过重建子任务增强模型特征提取能力。
2.EEG 信号重建子模块可集成到基于编码器 - 分类器的深度学习模型中,且能在无监督学习下工作,适用多种任务。
3.实验证明该方法能提升模型在眼动追踪任务上的表现,RMSE 达到 54.1mm,超越当前的 SOTA 模型。
研究方法:
1.设计包含表示模块、预测模块、重建模块的多任务学习 Transformer 模型,通过多任务学习框架整合各模块。
2.在 EEGEyeNet 数据集上,将模型与多种传统机器学习和深度学习算法进行对比,以 RMSE 为评估指标。
3.模型在 RTX 4090 GPU 上训练 15 个 epoch,设置初始学习率为\(10^{-4}\) ,并采用学习率衰减策略,在预测模块中使用两个 dropout 层。
研究结论:
1.模型在 EEG 眼动追踪任务上的 RMSE 为 54.1mm,优于之前的 SOTA 模型,证明了架构和方法的有效性。
2.重建子模块对模型性能提升有积极作用,但需合理调整其权重,以平衡与主任务的关系。
3.多任务学习模块具有通用性,可拓展到其他 EEG 数据集和任务,有助于推动 EEG 数据分析领域的发展。
全部论文PDF版可以关注工棕号{AI爱因斯坦}
回复 “注意任务” 即可领取
顶会投稿交流群来啦!
欢迎大家加入顶会投稿交流群一起交流~这里会实时更新AI领域最新资讯、顶会最新动态等信息~

















 722
722

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









