







引言
在自然语言处理(NLP)的完整流程中,文本预处理是决定模型性能的基础环节。其中,分词(Tokenization) 作为文本预处理的核心步骤,直接影响后续词向量化、特征提取等关键任务的质量。本文将从基础概念到前沿技术,系统解析分词的原理、方法、挑战与实践应用。
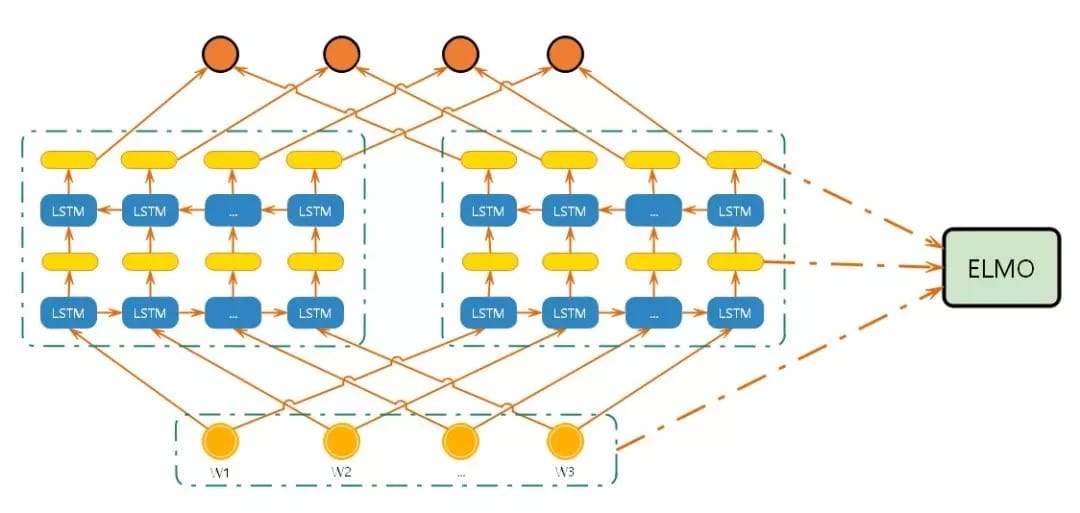
一、什么是分词?
1.1 基本定义
分词是将连续的自然语言文本切割成具有语义或语法意义的最小单元(Token)的过程。这些单元可能是:
-
英文中的单词("natural")
-
中文的词语("人工智能")
-
标点符号("!")
-
子词("un##break##able")
1.2 处理差异示例
-
英文:"Don't stop learning!" → ["Do", "n't", "stop", "learning", "!"]
-
中文:"我爱自然语言处理" → ["我", "爱", "自然语言处理"]
-
日文:"こんにちは世界" → ["こんにちは", "世界"]
二、为什么分词至关重要?
2.1 基础性作用
-
特征提取的基石:90%以上的传统NLP模型(如TF-IDF、Word2Vec)依赖分词结果
-
模型输入的标准化:将非结构化文本转化为结构化数据
-
跨语言处理的基础:处理不同语言的分词特性(如汉语无空格分隔)
2.2 错误分词的连锁反应
错误分词:"南京市长江大桥" → ["南京", "市长", "江大桥"]
将导致:
-
实体识别错误(误识别为职位)
-
情感分析偏差(错误组合情感词)
-
机器翻译失效(错误传递语义)
三、主流分词方法解析
3.1 基于规则的方法
3.1.1 空格分词
text = "Natural language processing"
tokens = text.split() # ["Natural", "language", "processing"]-
优点:处理英文简单高效
-
局限:无法处理复合词("New York")和粘着语(德语)
3.1.2 字典匹配法
中文经典算法流程:
-
构建百万级词典
-
正向最大匹配(FMM)
def FMM(text, word_dict): max_len = max(len(word) for word in word_dict) tokens = [] while text: word = text[:max_len] while word not in word_dict: if len(word) == 1: break word = word[:-1] tokens.append(word) text = text[len(word):] return tokens
-
缺点:无法处理未登录词(如新出现的网络用语)
3.2 统计学习方法
3.2.1 隐马尔可夫模型(HMM)
状态定义:
-
B:词语开始
-
M:词语中间
-
E:词语结尾
-
S:单独成词
示例:
"我爱NLP" → B E S S → ["我", "爱", "N", "L", "P"]
3.2.2 条件随机场(CRF)
特征模板示例:
-
当前字符是否为数字
-
前后字符组合是否在词典中
-
字符的偏旁部首组合
3.3 深度学习方法
3.3.1 BiLSTM+CRF 架构
import tensorflow as tf
model = tf.keras.Sequential([
tf.keras.layers.Embedding(vocab_size, 128),
tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(64)),
tf.keras.layers.Dense(64, activation='relu'),
tf.keras.layers.CRF(num_tags)
])3.3.2 Transformer 模型
-
使用BERT的WordPiece分词:
from transformers import BertTokenizer tokenizer = BertTokenizer.from_pretrained('bert-base-chinese') tokens = tokenizer.tokenize("自然语言处理") # ['自','然','语','言','处','理']
四、分词的六大挑战与解决方案
4.1 歧义消解
-
组合歧义:"发展中国家" → [[发展, 中国, 家], [发展中国家]]
-
解决方案:基于互信息(PMI)计算组合概率
4.2 未登录词识别
-
新词类型:网络用语("栓Q")、专业术语("抗PD-L1抗体")
-
识别方法:基于n-gram的新词发现算法
4.3 多语言混合文本
处理示例:
"Python的print函数很好用!"
→ ["Python", "的", "print", "函数", "很", "好用", "!"]
五、实践工具对比
| 工具库 | 语言支持 | 算法类型 | 特点 |
|---|---|---|---|
| NLTK | 英文 | 规则+统计 | 教学首选 |
| Jieba | 中文 | 混合 | 支持自定义词典 |
| spaCy | 多语言 | 深度学习 | 工业级流水线 |
| Stanza | 70+语言 | 神经网络 | 支持依存分析 |
| HuggingFace | 多语言 | Transformer | 支持子词分词 |
六、中文分词专项解析
6.1 核心难点
-
无自然分隔符
-
词边界模糊("结婚的和尚未结婚的")
-
领域特异性强(医学vs.金融)
6.2 领域自适应方案
-
加载领域词典
import jieba jieba.load_userdict("medical_terms.txt") -
调整HMM模型参数
-
使用领域语料微调模型
七、分词的未来演进
7.1 技术趋势
-
统一分词框架:处理多语言混合文本
-
动态分词:结合上下文实时调整
-
无监督分词:减少对标注数据的依赖
7.2 大模型时代的影响
-
GPT系列采用Byte-Pair Encoding(BPE)
-
中文LLaMA使用SentencePiece分词
-
分词与预训练目标的协同优化
结语
作为NLP的基石,分词技术的发展史映射着整个领域的演进轨迹。从早期的规则系统到如今的上下文感知模型,分词的智能化程度不断提升。

















 936
936

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









